Table reorganization
I have a question on how to reorganize a table. I've also attached an example suggested by NEITHER, but it holds only for 4 ghosts. I am also attaching a simple example of a table to reorganize (testa.lmv)
Summary:
Several voltage-current spectra are stacked on each other in 2 columns (as in the example simple "testA.lmv", where 4 spectra with 11 points each are stacked one on the other).
I need to turn this table in ' N (in the example N = 4) times 2 columns of the Np (in example 11) points of each.
The number of Spectra and the number of points for each spectrum are known but vary from one experiment to another.
In an experiment, the number of Np points by spectrum is identical for all ghosts stacked in 2 columns.
For 4 spectra, it is easy to use tool "table under" and include 4 times the subarray tool to extract each spectrum.
But because N is different for each experience, I'm not going to change every time the vi and so I tried to combine the tool "table under" a for (or in while loop) with N cycles, 1 for each spectrum.
Unfortunately what it does not
Anyone have an idea how to deal with such a combination of the subarray and loop For (or during)? or there is a better solution?
Thank you
Here is a code snippet that should help you!
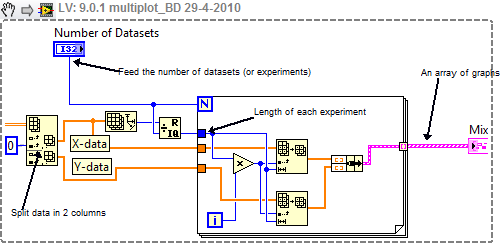
This should work for the data as your original data. However I could not test it because I miss a valid dataset.
Tone
Tags: NI Software
Similar Questions
-
Partition of table reorganization
Hello
I have a pretty large table with the partition of the range. The person who ran a database before me, left huge amount of data in the default partition as existing partitioned filled and he did not create the new partition. Now, I'm putting together this table. The default partition has about 70 million lines. I want to know what will be the most effective way to carry out this exercise? the table has a primary key, foreign key, and also some other indexes on that.
In the test environment, I created new partitions. Data copied from the default partition in 6 temporary tables. Copy takes about 8 hours. Now, I'm debating if I should truncate data from default partition and move the lines of time tables created back into the new partitions by writing insert query? I know it's easier way out, but not the most effective way.
Another option I'm considering is, use datapump to export the data from the partition and then import, but I have not tried this? Can you show me or direct me to an example where the datapump is used to export and import a partition.
Oracle version: 11.2.0.3
Operating system: SUN Solaris 10
In the test environment, I created new partitions. Data copied from the default partition in 6 temporary tables. Copy takes about 8 hours. Now, I'm debating if I should truncate data from default partition and move the lines of time tables created back into the new partitions by writing insert query? I know it's easier way out, but not the most effective way.
We cannot help you if you SHOW us what you have done rather than simply say.
What is the table the original table DDL?
What is the DDL of the new test table?
What data is in each of 6 temporary tables?
If each of 6 temporary tables has data belonging to a single NEW partition then just use EXCHANGE PARTITION.
1. create 6 new partitions in the table
2 make a swap partition between each of the 6 new partitions and the corresponding temporary table is not partitioned.
Trade is expected to take less than a second because they are updates only data dictionary.
See my response and code example in this thread
-
Changing the definition of table PS_TXN use SECUREFICHIERS
Fusion Middleware Version: 11.1.1.7
WebLogic: 10.3.6.0
JDeveloper Build JDEVADF_11.1.1.7.0_GENERIC_130226.1400.6493
Project: Custom Portal Application WebCenter integrated with ADF custom workflows.
During our ADF application performance tests, we noticed that a lot of contention on the LOB segments for the table PS_TXN (supports transactions State passivation/activation).
Movement of the LOB segment to use Oracle SECUREFICHIERS, most other tweaks to the definition of the table showed significantly reduce the contention as providing a much higher throughput for read and write operations.
To implement these changes, we would like to modify the ADF internal script that creates the table in the first place rather manually, dropping the table or by using the online table reorganization.
This approach is documented, and suggests that this can be done my edit script "adfbc_create_statesnapshottables.sql" located under the directory MIDDLEWARE_HOME/oracle_common/sql $. We tried it, but after letting off the table in a test environment, ADF is re - create the table using the original definition when the application is done after the operation first move.
The same scenario can also be found under $MIDDLEWARE_HOME/oracle_common/modules/oracle.adf.model_11.1.1/bin however edit this file also makes no difference.
Does anyone know what script ADF uses to create the table, or if this is now coded in a class file or some other mechanism?
Automatic creation of table PS_TXN is hardcoded in the oracle.jbo.pcoll.OraclePersistManager class. Have a look at the statements at the end of the OraclePersistManager.createTable () method (in line 904 according to my decompiler). Other SQL statements (for example to drop the table, to the updates/insertions/deletions in the table, etc.) are defined inside the class oracle.jbo.pcoll.TransactionTableSqlStrings. You can find these classes within $MIDDLEWARE_HOME/oracle_common/modules/oracle.adf.model_11.1.1/adfm.jar.
If your database is not Oracle, but DB2 or MS SQL Server, then you should look at the classes oracle.jbo.pcoll.pmgr.DB2PersistManager and oracle.jbo.pcoll.pmgr.SQLServerPersistManager respectively.
You can override the default value PersistManager (create a new class that extends oracle.jbo.pcoll.OraclePersistManager and override/change the createTable() method), and then specify the new class in the AOS "jbo.pcoll.mgr" configuration property CreateTable() method has a package-level visibility, it would be very easy to do. This approach is delicate and the efforts needed to make does not, in my opinion. If I were you, I would be to pre-create the necessary tables in PS_TXN updated the manually.
Dimitar
PS Scripts SQL "adfbc_create_statesnapshottables.sql" aims to be used by advanced users who want to create their paintings previously manually. These scripts are not used by the infrastructure when it automatically creates the necessary tables.
-
Question about the fast display element
I'm playing with the new features and have found something I thought was weird/unfinished. In the item Quick View, you can rearrange your html quite easily by drag-and - drop tags in other areas of the list and moves of a given element in the code. It seems quite interesting for those who have a little sloppy with Cut and Paste and/or are not really all that only familiar with the code.
All this seems to work, except in tables well.
I can't move a table tag related to a table in the quick view of the item. I do not understand is not able to move a < tr > or < td > out < table > which causes a few problems of validation, but that move a < tr > in the < table > reorganize your lines appear as obvious as well as usefulness goes. Only one < td > leaving the front of < b > all the way to rearrange the order of the cells also seems that it would be a "given".
Was there a reason moving the table rows in the table or cells in the row is not possible within EQV or is supposed to be possible and I need to take a look at my cache or Pref?
The tables are quite surprisingly complex considering the addition of colspans and rowspans in your way of thinking. I'm pretty sure that tables were left out of the thing slide / move because of this complexity and their rare use for page layout.
-
Move the table in same tablespace is not reorganize the data
Hello.
I am facing a problem that I have not used to have. First of all, a description of our envorinnement:
We have a few large tables partitioned and performance optimization, our ETLs use bluk, add notes, parallelism and so on. This create several holes of unused space in tablespaces/data files as well a kind of leak of space on our drives.
A complete correction would re-create the tablespaces move everything is of opposes another. It would be impratical, because there are about 15 who are top of 100 GB; the time and effort to recreate everything is not affordable for the Business.
Instead, we have a single proc that comes to calculate the actual amount of used space (converted to blocks) and makes a move of all objects above this block_id. Just after this operation, there is a dynamic shrink based on the new HWM (given that the objects have been moved) on the data file freeing disk space. As we have a datafile by tablespace and a tablespace by schema, we would like to keep this body, if we make a single movement for objects, like 'ALTER TABLE' | owner: '. ' || nom_segment | "MOVE; "(the complete query works with all types of data such as partitions of table objects, the index partitions and the subpartions). This will move the object in the same space for the first freespace on the tables and free up space at the end of the file to shrink. In theory.
This unique proc used to work properly. In a 650 GB GB 530 tablespace in use moving about 20 that Go (the amount of data beyond the HWM 530 GB) is simpler than to create a new file/TBS and the displacement of 20 GB is faster than Go 530.
But suddenly things changed when some TBS refused to be narrowed. What I found out: the command move doesn't fail, it works very well and Oracle really moves the object. But for reasons that I don't know, he's not moving it at the beginning of the file, it keeps the object at the end. So the da calculates the new HWM, but because some objects that were in the tail of the queue, the shrink is done with a very high HWM, if no real space is reclaimed.
So, the main question: How does the ALTER TABLE FOO MOVE really works? I thought that it would be always to move the object to the beginning of the file thus reorganize, but I analyzed the last objects that gave me this problem (block_id before and after the move, compared to block_ids empty and everything) and actually, I see that they were moved at the end of the file, although there is enough space to accommodate initially.
Okay, I think I found the problem. Before that I just pulled the script as posted, but then I had the good idea to improve its performance with parallelism, so I added:
ALTER SESSION FORCE PARALLEL QUERY 16 PARALLELS;
ALTER SESSION FORCE PARALLEL DDL PARALLEL 16;
ALTER SESSION FORCE PARALLEL DML PARALLEL 16;
Returning to prallel not running, that I could reuse the freespace on the beginning of the file, and then narrow it down.
Obviously, each writing data in parallel mode reuse freespace, I just forgot that a TABLE ALTER MOVE is also a data write operation. I fell a bit ridiculous, caught in the same trap that I was trying hard.
Thank you all for the comments and advice.
-
Reorganize the table WF_JAVA_DEFERRED
Hi all
OS: OUL5x64
EBS 12.1.3
DB 11.2.0.3
I rearrange workflow (WF) and FND tables every 1 or 2 months (rearrange tables, rebuild indexes run fnd_stat) but never include this table WF_JAVA_DEFERRED
Question: I have to reorganize the table (no queue). the size of this table is more and don't know everything reorganize it or not.
Can someone please give me and advice or a note of oracle for this question.
Thanks in advance.
Please see:
Rebuild WF_JAVA_DEFERRED queue and Table queue preserving Transactions not processed - 11i. ATG_PF. H RUP3 and above (Doc ID 804876.1)
How Dequeue Messages old WF_JAVA_DEFERRED without rebuild it? (Doc ID 1495799.1)
Thank you
Hussein
-
Questions about the reorganization of the rows in the table by drag-and - drop feature
I am referring to the demo: 106. Drag-and-drop the reorganization of the rows of the table in aCorner of Code DF to implement my case.
I am facing some problems:
1. the view object (bound to the table) is read only and it is created directly by very complex SQL queries, without entity objects. When it is run the code: dragRow.removeAndRetain () in the method: DnDAction processDrop (DropEvent dropEvent), it throws the error so that a guest view object is read-only. I want to know if there is another way to delete the moved collection line?
public DnDAction processDrop(DropEvent dropEvent) { ... CollectionModel collectionModel = (CollectionModel) table.getValue(); JUCtrlHierBinding treeBinding = (JUCtrlHierBinding) collectionModel.getWrappedData(); //get access to the ADF iterator binding used by the table and the underlying RowSetIterator. //The RowSetIterator allows us to remove and re-instert the dragged row DCIteratorBinding departmentsIterator = treeBinding.getDCIteratorBinding(); RowSetIterator rsi = departmentsIterator.getRowSetIterator(); int indexOfDropRow= rsi.getRangeIndexOf(dropRow); //get access to the oracle.jbo.Row instance represneting this table row Row dragRow = (ViewRowImpl)table.getRowData(draggedRowKey); //remove dragged row from collection so it can be added back dragRow.removeAndRetain(); rsi.insertRowAtRangeIndex(indexOfDropRow, dragRow); ... }2. When you click on a button, I need to save the command results in the database using the command update # of each rank. Here it is the handler method for the event of the action (in MB) button.
I want to use RowSetIterator table for encode it from all ranks and update the value # order of each rank. I call a data control method to run sql update. is it ok? any suggestion?
public void processSaveOrder(ActionEvent actionEvent) { CollectionModel collectionModel = (CollectionModel) mytable.getValue(); JUCtrlHierBinding treeBinding = (JUCtrlHierBinding) collectionModel.getWrappedData(); //get access to the ADF iterator binding used by the table and the underlying RowSetIterator. //The RowSetIterator allows us to remove and re-instert the dragged row DCIteratorBinding iterator = treeBinding.getDCIteratorBinding(); RowSetIterator rsi = iterator.getRowSetIterator(); Row row =rsi.first(); System.out.println(0+"="+ row); int i = 1; while(rsi.hasNext()){ row = rsi.next(); System.out.println(i+"="+ row.getKey()); i++; } }A workaround solution was found:
In ADF 12 c, it can be solved by changing Updatable "Always" in the details tab of each attributes to read-only view object without entity object.
-
Hello
in another 9i of export/import, is there another way to reorganize the tables?
Thank yuou.
PS: how about 10g?rather than ask, why can't do a simple search in google?
Why not read the docs of the oracle of http://tahiti.oracle.com?9i
(1) export / import
(2) move the table command30%
(1) exp/imp or expdp/impdp
(2) move the table
(3) retractable in orderbut before taking any action be sure ask you a few questions as
is a performance impact? or I simply do it all? -
Hello
How can I re organize the elements of a 1 d array? for example, A B C D E F G H---> A B C D E F G H
Thank you!
Just use the "remove table" and "Insert table" see attachment screws.
-
reorganization of the data in the table
This has probably been asked and answered before, but I can't seem to find it anywhere.
I'm saving a bunch of data in a file of lvm in the form of a 1 d table. When I open the worksheet the data appears in this format
0 2.525174 1 0.390727 2 4.00143 3 0.020132 0 2.525174 1 0.390727 2 4.00143 3 0.020132 0 2.525174 1 0.390727 2 4.00143 3 0.020132 0 2.525174 1 0.390727 2 4.00143 3 0.020132
0-3 is my four analog channels. I want the data to look like this when I open the file in excel:
0 2.525174 2.525174 2.525174 2.525174 1 0.390727 0.390727 0.390727 0.390727 2 4.00143 4.00143 4.00143 4.00143 3 0.020132 0.020132 0.020132 0.020132 This way I can easily see which data points belong to which channel.
Otherwise, it would be even better:
0 1 2 3 2.525174 0.390727 4.00143 0.020132 2.525174 0.390727 4.00143 0.020132 2.525174 0.390727 4.00143 0.020132 2.525174 0.390727 4.00143 0.020132 I'm pretty new to LV and can't seem to find a way to re - format the data before moving my "write.vi".
Just in case this is helpful somehow, I enclose my vi.
Thanks in advance!
EDIT: accidentally attached the wrong file. This is the one.
Hello.
You can use the Decimate array with 4 outputs function to automatically create a single table for each channel, you can then use build array to merge all channels as an array of unique 2D (which would look like the second picture you posted). Finally, you can convert the table to format as in your third example. I hope that helps!
Best regards.
-
All,
I found a few tables are very fragmented in our database of production and continues to re - organize. I intend to use 'change the method of displacement of the table '.
Database version: 11.2.0.3
Name of the table: Test Tablespaces: users, tools - they already have enough space for the move.
During the race, this database of impact will this order? This will allow DML and DDL operations? Please let me know what has be to consider other things.
SQL> alter table test move tablespace tools; Table altered. SQL> select status from dba_objects where object_name='TEST_INDX'; STATUS ------- VALID SQL> alter table test move tablespace users; Table altered. SQL> select status from dba_objects where object_name='TEST_INDX'; STATUS ------- VALID
Thank you
Why do you feel compelled to do something?
If you regularly remove 'huge', and then nothing else to do.
If "SHRINK you" the size of the table, you force only Oracle to expand yet; before the next deletion.
What you propose would be similar to replace the gas tank on your car you consume gasoline in order to eliminate all the space as 'wasted' in there.
The problem arises when you want to fill. You develop the tank; just to keep more gasoline.
-
I'm new to numbers but were mainly use it to organize only a simple way to display the cases that arise in a criminal background check. So for a table, I can type driving while license revoked (DWLR) as the load and from there on the charge will fill itself or offer similar responses after typing a single key. A well appreciated time saver but problems I can sort and summarize the criminal history for 10 people or more at a time and need to do it urgently often. However when I opened a new table I have to cross and type a new the precise wording of a charge, its disposal (Guilty, voluntary dismissal etc.) and just know that there is an easy way for the numbers to know in a new table that, if finished it is a list annoyingly long term broken criminal code list and do not have to do that in each new table so that it can take. I know I'm missing something very basic, but any help would save hours for me and the other poor interns who spend twice as long just to undestand the case and troubleshoot. Thanks for all the ideas!
David
Hi D,
The AutoComplete feature provides suggestions picked on data entered in the cells above the one you are working in. You can automate the process by preparing a "full menu" table containing ALL the possible inputs for each column in the rows below the header lines.

The checkbox in cell A1 is a switch, is used to insert the word HIDE in the cell that contains the list of AutoComplete terms. Cells in this area are filled with bright red to draw attention to them when indicated.
A rule to reorganize (shown and applied below) hiding these lines when the box is checked.

Hide the lines does not affect the operation of auto-complete, as shown in the table below:

When the form is competed, action depends on how the result will be recorded and filed.
If there is no need to edit/modify the file, it can be converted to a PDF using the print dialog. This produces a copy of the displayed part of the document only.
If the document will require more editing, you can remove the lines containing AutoComplete suggestions. Clear the check box, select all the red lines filled, click the triangle in the row reference tabs and choose Remove.
Formula in A2 - A10: = IF(A$1,"HIDE","")
Kind regards
Barry
-
Mobile based on the size and the position of the other table
I have the impression that there is an easy solution for this... or it there is no solution at all... but here goes:
I want to use table 2 to indicate 'total time' as the sum of all time in table 1. Table 1 is set to automatically filter some lines (basically, it creates a dynamic playlist based on certain criteria). What I wish is to table 2 'float' a certain number of Table 1 below, so that as table 1 grows or shrinks according to the filtered content, table 2 remains the same distance from the bottom of table 1. Is - this unreasonable? It seems I've seen tables 'hustles' other tables according to size changes (not the desired effect in these cases, but what I DO want to here).
Hi mikey,.
This seems to be the default behavior in Numbers ' 09, but the function may not have been included in 3 numbers. I'm sure someone will test and report on it before long.
Demo below is in Numbers ' 09.

Coffee table is a double to the top. After positioning the lower level of the original table, I inserted two rows in the original and watched 'push' that the lowest low, keeping the space between them.
I reformatted the cells in column B, CheckBox and verified that a few of them.
Then I opened the Reorganize pane. and the filter rule (see the lines "... ") displayed the value:
By clicking on "see the lines...". "box produces this result:

Note: I had selected all the header cells in column B before starting the filter. The first image was captured after unchecking the checkbox 'display lines... '. "developing the table and leaving only the cells in the (previously) selected filtered lines.
As mentioned, the example is in Numbers ' 09 / numbers 3 behavior may be different.
Kind regards
Barry
-
Issue of table + write to the file
Hello, I am using USB-6009 with Labview 8.5
I searched and passed tutorial table and still confused about acquisition of data...:)
So here's what I'm doing (simple)
I have two tension analog (AI0 AI1) returns through the DAQ assistant
and I would like to follow up respectively and finally want to write them in lvm format or csv format...
Question 1.
Can I have an example of table VI with the DAQ assistant? all the tutorials I went on
they are only about numbers--not the dynamic data...
I think of... convert data into DBL and reorganize somehow to each table to the graph of the monitor
Question 2.
so I cut the data by using the table to display the monitor, then I will add both the value of the data in table
to write to the file? or... is it possible to write in the file directly from the Daq Assistant, write on the file VI?
Quesetion 3.
If so, could you tell me how this writing on a file to save the data? 1st column with odd rank-> AI0
1st column with the same line-> A1... something like that?
Thanks, I spent about 3 hours of that, google them, read the help of labview and helped a lot
1. you should be able to double-click the convert to Dynamic Data and convert the waveform in a table.
2. just connect the output of the VI DAQmx Express write it on the Express VI of LVM.
-
request (?) featured: matrices or tables for a particular column sort
Hello all-
This may be a stupid question, because I'm always still not quite clear on what are the differences between the matrixes and 2D arrays in LabView. So far the only distinction I seemed to find, it is that certain features of table return errors when the matrices are entered and vice versa.
Anyway, here's my question.
Suppose I have a matrix where the first column represents the 'values' that have been measured and the second column 'account'. I would like to take a unordered matrix (i.e., the value column is not ordered) and recover a matrix that has had its lines re-arranged according to the values in the first column.
For example, if my matrix:
[5-1;
0 11;
1-5;
3-10]
I would like to as labview to return:
[0-11;
1-5;
3-10;
1 of 5]
When I was trying to find a way to do it (without writing my own sorting routine which, admittedly, wouldn't be too bad, but I'm a lazy programmer
 ), the only thing I found that came close was the 'matrix of D 1 sort' Subvi. However, even if I had to store the values in a table and charges in another table, I'd be able to do is sort the table values. I wouldn't be able to tell what labview reorganization, I would need in order to perform the same reorganization charges.
), the only thing I found that came close was the 'matrix of D 1 sort' Subvi. However, even if I had to store the values in a table and charges in another table, I'd be able to do is sort the table values. I wouldn't be able to tell what labview reorganization, I would need in order to perform the same reorganization charges.I'm a little surprised that there isn't a quick and intuitive way to do this (at least that I can find). A LabView feature addition that could help with this problem would be if the "1 D Array sort" routine returned a second output - a vector with the mapping of the index used - similar to MATLAB. MATLAB help for the function 'out ':
"[There, I] = SORT(X,DIM,MODE) also returns a matrix of index I.. «If X is a vector, then Y = x.»
Of course, there may be a quick fix for what I'm missing...
Take a look at this post. I don't know that you can change for your particular type of data.

(in contrast to the first colum, create the sort key, table 2D reconstructed according to key)





Maybe you are looking for
-
Hi- I try to print a photo of an estate inventory. I have the pictures in a folder on the Photo. When I open the folder and select the photos you want to print, I will file and down to print, which is grayed out. I have no idea how to do that, and
-
How can you find your old messages?
I used to be able to shoot to the top of the list of all my old posts throughout these incredibly useful support communities. However, I seem more to be able to do. Is it still possible to get back a list of all your previous posts? Advice on how to
-
Photos rotate from Portrait to landscape mode when em
I discovered that all the photos I take orientation portrait once sent to someone, they are reversed for the landscape. The photos cannot be turned to the correct orientation with opening program Paint and rotate manually. Is there any solution for t
-
I tried since 15:20 it is now 20:25, 06:05 hours, it is * to the top.
-
Change file Association by default for the Edit action (but not the Open action)
When I right click on a jpg file and choose the EDITING command, it opens up the PAINTING. How can I change the default EDIT to jpg in Photoshop instead? I don't want to change the default OPEN association for Windows Photo Viewer jpg files. I wan