The match regular expression or pattern
I'm in big trouble to the extraction of results of a string of serial port.
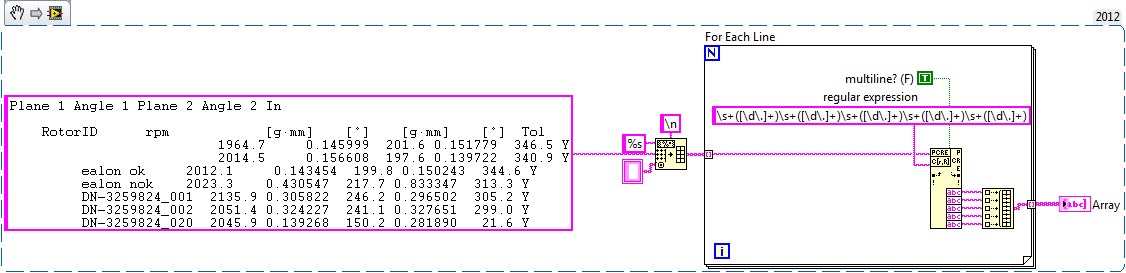
I get a report through connectio series of some devices. It looks like this:
Plane 1 Angle 1 Plane 2 Angle 2 In
RotorID rpm [g·mm] [°] [g·mm] [°] Tol
1964.7 0.145999 201.6 0.151779 346.5 Y
2014.5 0.156608 197.6 0.139722 340.9 Y
ealon ok 2012.1 0.143454 199.8 0.150243 344.6 Y
ealon nok 2023.3 0.430547 217.7 0.833347 313.3 Y
DN-3259824_001 2135.9 0.305822 246.2 0.296502 305.2 Y
DN-3259824_002 2051.4 0.324227 241.1 0.327651 299.0 Y
DN-3259824_020 2045.9 0.139268 150.2 0.281890 21.6 Y
I can't separate the data with spaces, because sometimes there is no "RotorID" so that all data is moved to the left.
There are still 7 columns. RotorID is sometimes empty sometimes that he composed characters and numbers. I never know its length. Other data are still present and separated with space.
Can you help me please.
If you want to use a regular exprission.
Tags: NI Software
Similar Questions
-
"Matches regular Expression" and "Model match" vi behaves differently
Hello
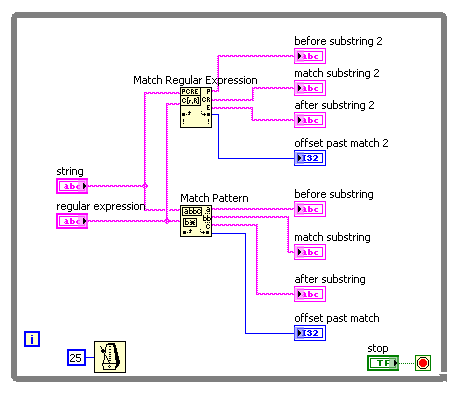
I need a simple matching chain and experimenting that found the "Regular Expression Match' and 'Correspondence model' vi behave a little differently. I guess that the entries of the regular expression on the two the same behavior. It's a difference that I discovered that the "|" character ("vertical" character, commonly used as an operator 'or') is recognized as such in the regex to Match vi, but not in the match vi model (where it is taken to the letter). Furthermore, I can't find any document using (online or in LabVIEW) on the ' | ' usage in regular expressions of character. Is - this documented anywhere?
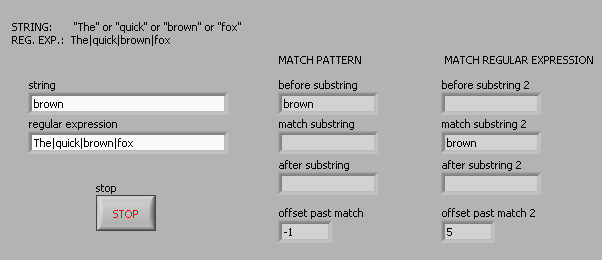
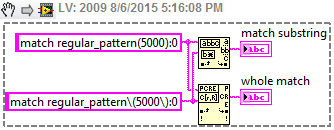
For example, suppose I want corresponding to one of the following 4 words: 'The' or 'fast' or 'brown' or 'fox '. The regular expression ' the | fast | Brown | Fox' (without the quotes) works for the vi Regular Expression Match but not the match pattern vi. Here is a photo of the block diagram and the results of the façade:
The Help explains that the vi Regular Expression Match performs a little more slowly the match vi pattern, so I started with the latter. But since he does not work for me, I'll use the old. But does anyone have an idea of the speed difference? I guess that's negligible in a simple example.
Thank you!

Thank you, Jeff. That's what I was looking for. BUT my version of LabVIEW 8.5, does NOT say "functionfor example, the Match model does not support the parenthesis or vertical bars (|) characters.«» !
See: http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_pattern/
and http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_regular_expression/
It is not mentioned in the help of special characters used for the match pattern : http://zone.ni.com/reference/en-XX/help/371361D-01/lvhowto/specialcharformatchpatt/
The only place | has 'talked', it is in the sentence: "some regular expressions that use alternating (such as (. |))". \s)*) require significant resources to deal with when it is applied to the large input strings. "But I'm not processing a large chain.
It seems that NEITHER fixed this omission. What version is your help?
Ed
-
Matches regular expression in the collection
Hello
I need to do the following:
I have a long string with repeated similar data. I would like, by using a regular expression, to excerpts from all matches in a collection. Is there a way to perform this task?
I look through the owa_pattern package, but as far as I saw, I can extract only a single match. Here's an exact quote:
"" If the regular expression can match several strings that overlap, this function is the longest game."- http://download.oracle.com/docs/cd/B28359_01/appdev.111/b28419/w_patt.htm
So what can I do if I want to get all the games?
Thank you in advance. Any help would be appreciated.
Best regards
beroetzMaybe this will help:
SELECT REGEXP_SUBSTR ('{A1:5} {BB:10}
{CC:5}', ' (<.*?>) |) () {. *?})', 1, LEVEL) token
OF THE DOUBLE
CONNECT REGEXP_INSTR ('{A1:5} {BB:10}{CC:5}', ' (<.*?>) |) () {. *?})', 1, LEVEL) > 0
ORDER BY CSA LEVEL;If you want to eliminate the unwanted characters <> {} then use REGEXP_REPLACE in addition:
SELECT REGEXP_REPLACE (REGEXP_SUBSTR ('{A1:5} {BB:10}
{CC:5}', ' (<.*?>) |)) () {. *?})', 1, LEVEL), "[<>{}]') token.
OF THE DOUBLE
CONNECT REGEXP_INSTR ('{A1:5} {BB:10}{CC:5}', ' (<.*?>) |) () {. *?})', 1, LEVEL) > 0
ORDER BY CSA LEVEL;See you soon
Edited by: Nuerni the 17.10.2008 at 11:02
-
the simple regular expression problem
Hello
I need assistance with regular expressions. I have a situation when I need to get data from one table to the other and I think that my problem can be solved using REG EXP, but I don't know how to use them properly.
I need to separate fileld varchar2 which is basically number/number in 2 separate number fields
I need to get the code in the co and po columns. I think the result should look something like this, but:CREATE TABLE tst (CODE VARCHAR2(10)); INSERT INTO tst VALUES('10/15'); INSERT INTO tst VALUES('13/12'); INSERT INTO tst VALUES('30'); INSERT INTO tst VALUES('15'); CREATE TABLE tst2 (po NUMBER, co NUMBER);
Any help appreciatedINSERT INTO tst2 SELECT regexp_substr(CODE 'something here to get the number before /') AS po, regexpr_substr(CODE 'something here to get number after') AS co FROM tst;Agree with the above,
However, if you really want to know how to do with regular expressions you can do it like this...
SQL> select regexp_substr('10/15','[^/]+',1,1) from dual; RE -- 10 SQL> select regexp_substr('10/15','[^/]+',1,2) from dual; RE -- 15 -
meaning of the given regular expression
Hi all
I want to know how the regular expression in the following query.
SELECT UNIQUE REGEXP_REPLACE (catalog_url, ' http:// (\ [^ /-] +). * ', '\1')
OF oe.product_information;
Here I put spaces for ease of understanding.
Soni
Published by: sonidba on February 5, 2010 12:28
Published by: sonidba on February 5, 2010 12:30sonidba wrote:
Thanks for your reply. I am knowing the answer only. But not how. What does '\1' referred to here in the request. Someone at - it the answer?Published by: sonidba on February 5, 2010 13:04
\1 is a backreference.
In the REGEXP_REPLACE function (catalog_url, ' http:// ([^ /] +). * ', '\1') there is a section of the chain of research in parentheses. \1 refers to the found value that corresponds to that subexpression. If you had several subexpressions in parentheses then you may have several backreferences.
-
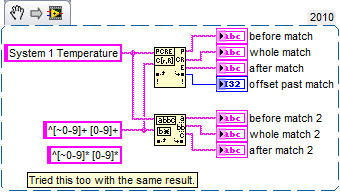
Regular expression matching is not what matches Pattern
I read a lot of posts on how match model does not match what match regular expressions will be due some characters does not.
However, I found a problem with the other way. A simple Reg - Ex who works in the match pattern but not regular Expression match.
What I have here is just an example. I want to use regular Expression Match then I can specify some matches under.
The reg - ex's: one or more non-numeric characters, a space, one or more numeric characters. At the beginning of the string.
How can I get this to work in regular expression matching? I work in LabVIEW 2010f2 32 bit. Here is the code snippet and the results:
Rob
One of the subtle differences is the operator of negation for the character classes. In match pattern is ~, but for the Match RegEx is ^.
-
Analyze the Mac address with the regular expression matching
Hello world
I have a problem with the function of regular expression matching,
I try to analyse the response both a query arp - a 192.168.0.15 to retrieve the MAC address of the remote IP address, I used the following regular expression: ^ ([0-9a-fA-F]{2}[:-]){5}([0-9a-fA-F]{2})$
I wonder why should I do a subset of the first string to extract only the part of the MAC address. The regular Expression function is not able to recognize the regular expression directly in the middle of a string?
I only works when I extracted the subset of tring right as in the picture below.
Thanks for your replies.
Get rid of the "^" at the beginning of your regular expression. You are ordering him to find the model at the beginning of the string.
-
Use matching of regular expressions to search for parentheses
Hi all
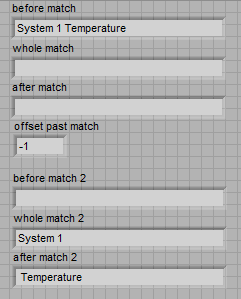
I am currently looking for a particular pattern in a string, I can't display the exact string, but say its something like that. corresponds to regular_pattern (5000): 0
I'm also looking for the a different model at the same time, so I have to use the corresponding regular expression and the | function. I can't understand how to match this model because the regular expression function allows parentheses unless I put them in the legs, and that does not help me for this.
Any advice?
Thank you
Matt
Have you tried to escape the bracket?
-
Multiline - Regular Expression Match string
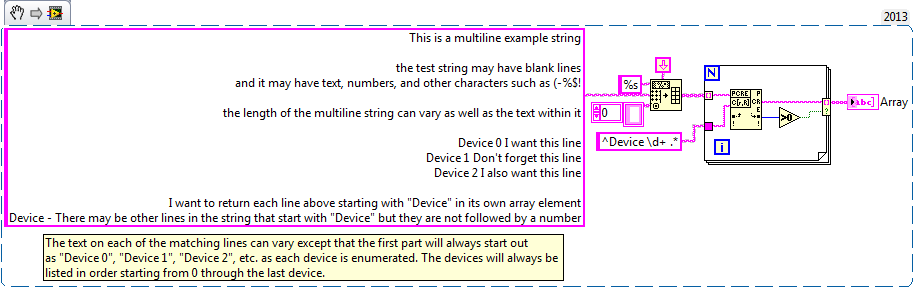
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
aaronb wrote:
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
Corresponding regular expression works well for this.
Ben64
-
Looking for the character "$" in a regular expression
I try to use the vi "Regular Expression to Match", but what I'm trying to find is a dollar sign followed by a space.
Using the slash codes allows me to specify a whitespace character (\s) but I can't find how to specify the $.
I tried \x24 and \36 try hex and decimal ASCII representations, but no luck, I tried to put the $ hooks - but which doesn't work either.
Everything I try, the $ is interpreted as a command rather than the search term.
I used to use model game (legacy code) and the search term "$\s*$ ' worked - now need to use regex that I need to feed in some other matches this regex only can do - except for the dollar (if only I worked in the good old UK £!)
Any ideas out there?
Thank you
I think that we must work...
\\$\s[\n\r]
seems to do the trick
-
Regular expression help please. (extraction of a subset of the string between two markers)
I haven't used regular expressions before, and I can't find a regular expression to extract a subset of the string between two markers.
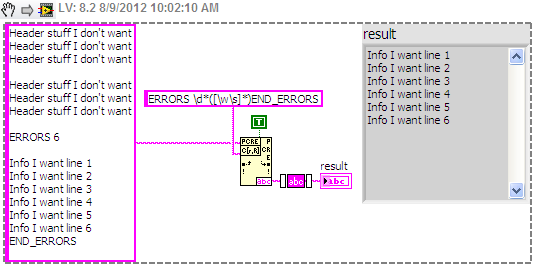
The chain;
Stuff of header I want
Stuff of header I want
Stuff of header I wantStuff of header I want
Stuff of header I want
Stuff of header I want6 ERRORS
Info I want to line 1
Info I want line 2
Info I want line 3
Info I want to line 4
Info I want to line 5
Info I want line 6
END_ERRORSFrom the string above (it is read from a text file), I try to extract the subset of string between ERRORS 6 and END_ERRORS. The number of errors (6 in this case) can be any number from 1 to 32, and the number of lines I want to extract will correspond with this number. I can provide this number of a caller VI if necessary.
My current solution, which works, but is not very elegant;
(1) using Match Regular Expression for the return of the string after you have synchronized the 6 ERRORS
(2) uses the Regular Expression matches to return all characters before game END_ERRORS of the string returned by (1)
Is there a way this can be accomplished using 1 Regular Expression Match? If so someone could suggest how, as well as an explanation of the work of the given regular expression.
Thank you very much
Alan
I used a character class to catch any word or whitespace characters. This put inside parentheses a substring matching the criteria that you can get by developing the node for regular expression matching. The \d matches the numbers and the two * s repetition of the previous term. So, \d* will find the '6', as well as "123456".
-
The regular expression problem
Dear friends,
In my script I have some sections that test the contents of an edit field before it is processed further.
Perfectly things like the following:
var re_Def = /#[A-Za-z][A-Za-z0-9_]+/; // valid variable name ? items = ["#correct", "notcorrect", "#This_is4", "#thisIs", "@something", "#ALLOK", "", ]; // search 0 -1 -1!! -1!! -1 -1!! -1 <--- incorrect method // test true false true true false true false <--- correct method for (var j = 0; j < items.length; j++) { var item = items[j]; alert ("'" + item + "' ==> " + item.search(re_Def) + "\n" + re_Def.test(item)); } var re_Def = /(\[ROW +\d+\]|\[COL +\d+\]|\[CELL +\d+, +\d+\]|Left *\(\d*\)|Right *\(\d*\)|Above *\(\d*\)|Below *\(\d*\))/; items = ["[ROW 17]", "[Row n]", "[ROW n]", "[CELL 3, 9]", "[CELL 3 9]", "Abbove()", "Right(3)"]; // result true false false true false false true for (var j = 0; j < items.length; j++) { alert ("'" + items[j] + "' ==> " + re_Def.test(items[j])); }But what follows always returns false, independly of the content of the string element:
var re_Def = /{[EFJ]\d*}|{I}/; // valid format def? var item = "{E27}"; var result = re_Def.test(item); alert (result); // false !!RegEx buddy told me, that
-l' REGULAR expression is correct
-the result must be true, not false-The verbose definition of the RegEx is:
Match is the following regular expression (attempting the next alternative only if this one fails) "{\d* [EYF]}."
Match the character "{" literally "{}".
Match a single character present in the list "J" "[EYF]."
Match a single digit 0. 9 paper"\d*»
Between zero and unlimited times, as many times as possible, giving as needed (greedy) «*»
Match the character "}" literally "}".
Or match number 2 below (the entire match attempt fails if it cannot match) regular expression "{i}".
Match the characters "{i}" literally "{i}".Typo unrecognized? Test the faulty method?
Results are fake, as soon as I use the list of characters []] - but look at the first block of code: there are also lists of character they are treated properly.
The braces in the regular expression must be escaped to be taken literally:
var re_Def = /\{[EFJ]\d*\}/;Kind regards
JoH
-
regexp_substr: a regular expression for the separate comma operator of witn of string literals IN
The following regular expression separates simple values separated by commas (SELECT regexp_substr (: pCsv,'[^,] +', 1, level) FROM DUAL CONNECT BY regexp_substr (: pCsv, ' [^,] +', 1, level) IS NOT NULL); Exampple: 300100033146068, 300100033146071, 300100033146079 returns 300100033146068 300100033146071 300100033146079
This works very well if we use the regex with SQL IN operator select * from mytable where t.mycolumn IN (SELECT regexp_substr (: pCsv,'[^,] +', 1, level) FROM DUAL CONNECT BY regexp_substr (: pCsv, ' [^,] +', 1, level) IS NOT NULL);
But this query does not work if the comma-separated value is a single literal string 'one', 'two', 'three '.
Thanks for your reply. my request was mainly on regexp_substr. Need to request was simple: any table with a column of varchar type can be used. Next time I'll give you an example.
All ways working answer for my question is is SELECT regexp_substr (: pCsv,'[^, "] +', 1, level) FROM DUAL CONNECT BY regexp_substr (: pCsv, ' [^,"] +', 1, level) IS NOT NULL
-
Form validation helps with the regular Expression [a-zA-Z]
I'm trying to use the regular expression [a-zA-Z] to allow only upper or lowercase WITHOUT SPACES. With the help of [a-zA-Z] allows space and numbers.
Could someone give me a point in the right direction?
Thank you!
RGNelson wrote:
I'm trying to use the regular expression [a-zA-Z] to allow only upper or lowercase WITHOUT SPACES. With the help of [a-zA-Z] allows space and numbers.
Could someone give me a point in the right direction?
Please try with the following regular expression, which should work for text entry fields 'a line' well standard.
^ [A-Za-z] + $
See you soon,.
Günter
-
Regular expressions in the APEX
I am using the following regular expression ^ [\w\s]+?$, but it does not work in APEX.] I want to validate a field for not accepting anything but the line of underscores, spaces and alphabetic characters.Try to use POSIX character classes:
^[[:alpha:][:space:]_]+?$Note that you must always provide at least the following information when you ask a question:
-APEX version
-Edition and version DB
-Web server architecture (EPG, SST or APEX listener)
-The browsers used
-Theme used
-Models
Maybe you are looking for
-
No picture but sound using WMP and Real Player after update 8.1 Win
Also good windows media player and real player does not display a video but will play sounds (from the video) after the upgrade. Microsoft not interested in the problem and real cannot advise on the issue once the configuration ompatibility option di
-
Re: Equium U400-145 PSU42E - light does not
Hey everybody, I just reinstalled the operating system on this laptop, and managed to find most of the drivers, yet something is still baffling me.The keys do not work, and don't turn off the lights under them (and other lights on the logo of satelli
-
The temperature of Thermocouple on Labview
In our project, we try to get different values of different thermocouples connected to our NI DAQ temperatures. When we execute the program, we get the values of different temperature of .xls file but we can not control these values of different temp
-
How do disable you scrolling faade LV?
Is there a way programmatically or via the menu of properties for the Panel before the LV disable scrolling of a VI active? It seems not be all selections for this nodes invoke or property.
-
Original title: Please help The Application or DLL C;\program~1\Google\Google~1\Google62~1.DLL is not a valid Windows image. Please check this against your installation diskette. I get this message all the time that I can still use my computer, but