Tricky Regexp and string of SQL column row
Hi allI am trying to build a SQL that can convert a string passed as
HP|250 GB * 2 + 80 GB * 3 + 100 GB | SATAHP | 250 GB | SATA
HP | 250 GB | SATA
HP | 80 GB | SATA
HP | 80 GB | SATA
HP | 80 GB | SATA
HP | 100 GB | SATAWITH T AS
( SELECT q'[HP|250 GB * 2 + 80 GB * 3 + 100 GB | SATA]' str FROM DUAL
),
t2 AS
(SELECT trim(regexp_substr(str,'[^|]+',1,level)) val
FROM T
CONNECT BY level <= LENGTH (str)-LENGTH(REPLACE(str,'|'))+1
),t3 AS
(SELECT DISTINCT trim(regexp_substr(val,'[^+]+',1,level)) val
FROM t2 WHERE VAL LIKE '%*%' OR VAL LIKE '%+%'
CONNECT BY level <= LENGTH (val)-LENGTH(REPLACE(val,'+'))+1
),t4 as
(SELECT VAL,ROWNUM RN FROM T2 A1
WHERE VAL NOT LIKE '%*%' OR VAL NOT LIKE '%+%'),
t5 as
(SELECT A.VAL MK, T3.VAL CONFG, B.VAL TYP
FROM T3, (SELECT VAL FROM T4 WHERE RN = 1)A,(SELECT VAL FROM T4 WHERE RN = 2) B)
SELECT *
FROM T5;MK CONFG TYP
----------------------------------------- ----------------------------------------- -----------------------------------------
HP 80 GB * 3 SATA
HP 250 GB * 2 SATA
HP 100 GB SATA BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production
PL/SQL Release 11.2.0.1.0 - Production
CORE 11.2.0.1.0 Production
TNS for 32-bit Windows: Version 11.2.0.1.0 - Production
NLSRTL Version 11.2.0.1.0 - Production * 009 *.
with t1 as (
select 'HP|250 GB * 2 + 80 GB * 3 + 100 GB | SATA' str from dual union all
select 'INTEL|40 GB + 55 GB| IDE' from dual
),
t2 as (
select regexp_substr(str,'^[^|]+') mk,
trim(regexp_substr(replace(str,'|','+'),'[^+]+',1,column_value + 1)) element,
regexp_substr(str,'[^|]+$') typ
from t1,
table(
cast(
multiset(
select level
from dual
connect by level <= length(regexp_replace(str || '+','[^+]'))
)
as sys.OdciNumberList
)
)
)
select mk,
trim(regexp_replace(element,'\*.*$')) val,
typ
from t2,
table(
cast(
multiset(
select level
from dual
connect by level <= substr(regexp_substr(element,'\*.*$'),2)
)
as sys.OdciNumberList
)
)
/
MK VAL TYP
---------- ---------- ----------
HP 250 GB SATA
HP 250 GB SATA
HP 80 GB SATA
HP 80 GB SATA
HP 80 GB SATA
HP 100 GB SATA
INTEL 40 GB IDE
INTEL 55 GB IDE
8 rows selected.
SQL>
SY.
P.S. Message your version. If 11.1, it can be simplified. If 11.2 can be even simpler.
Tags: Database
Similar Questions
-
Involuntary and moving the hidden columns after correction in the SQL
Hello
I am very new to the APEX and created an interactive report. I was to adjust manually using SQL column name in the Source of the region box and noticed one of my columns moved to the right of the report.
When I unstapled "column_name" AS "column 1" disappeared from the column of the report.
I cannot find any setting where it is specified as hidden, and when I click to filter the report via the Actions button, it appears under the section 'Other' under the section 'displayed '.
Is there an easy way to display this column?
Thank you very much
Matthew
1135826 wrote:
Please update your forum profile with a recognizable username instead of "1135826": Video tutorial how to change username available
Always include the information referred to in these guidelines when you post a question: How to get the answers from the forum
I am very new to the APEX and created an interactive report. I was to adjust manually using SQL column name in the Source of the region box and noticed one of my columns moved to the right of the report.
When I unstapled "column_name" AS "column 1" disappeared from the column of the report.
I cannot find any setting where it is specified as hidden, and when I click to filter the report via the Actions button, it appears under the section 'Other' under the section 'displayed '.
Is there an easy way to display this column?
After adding new columns or change the names of columns in an existing IR, you must select them for display as developer and Save the new report as the default main.
-
concatenate the strings from a column into a single row?
How to concatenate strings from a column into a single line?
Color
------
Red
Orange
Blue
Green
And return a set of results as follows:
Colors
-------------------------
Red, orange, blue, greenVarious ways can be found here:
http://www.Oracle-base.com/articles/10G/StringAggregationTechniques.php -
Hello Experts,
I have a problem that is a little tricky. Requirement is if 2 columns (region and Code in the tables below) match exactly, then it is Best Fit, if one of the columns match while it is average in shape, if the two columns do not match then it's worse to adapt.
Create Table Table1 (varchar2 (10), varchar2 (10) of the filter region, Code varchar2 (10), revenue Number (15), owner varchar2 (5));
Table1:
Insert into Table1 values ('Test1', 'Midwest', '0900', 3000286, 'P1')
Insert into Table1 values ('Test1', 'Midwest', '0899', 36472323, 'P2')
Insert into Table1 values ('Test1', 'Midwest', '0898', 22472742, "P3")
Insert into Table1 values ('Test1', 'West', '0901', 375237423, 'P1')
Insert into Table1 values ('Test1', 'West', '0700', 34737523, null)
Insert into Table1 values ('Test1', 'West', '0701', 95862077, "P3")
Insert into Table1 values ('Test1', 'South', '0703', 73438953, 'P4')
Insert into Table1 values ('Test1', 'South', '0704', 87332089, 'P1')
Insert into Table1 values ('Test1', 'South', '0705', 98735162, 'P4')
Insert into Table1 values ('Test1', 'South', '0706', 173894762, "P9")
Insert into Table1 values ('Test1', 'South', '0902', 72642511, 'P6')
Create Table Table2 (filter varchar2 (10), region varchar2 (10), Code varchar2 (10), plafond1 Number (15), Limit2 Number (15));
Table2
Insert into Table2 Values ('Test1', 'ALL', ' 0902', 15000, 10000)
Insert into Table2 Values ('Test1', 'ALL', 'ALL', 20000, 12000)
Insert into Table2 Values ('Test1', 'Midwest' ' 0900', 10000, 5000)
Insert into Table2 Values ('Test1', 'Midwest', 'ALL', 18000, 8000)
Insert into Table2 Values ('Test1', 'West', 'ALL', 16000, 6000)
Insert into Table2 Values ('Test1', 'West', '0901', 10000, 5000)
Final output
Filter the income Code region owner plafond1 Limit2
Test1 0900 3000286 P1 10 000 5 000 - Best Midwest (region because both Code Matches)
Test1 0899 36472323 P2 Midwest 18 000 8 000 - way (because the region corresponds to only), we consider 'ALL' for the Code
Test1 0898 22472742 P3 Midwest 18 000 8 000 - way (because the region corresponds to only), we consider 'ALL' for the Code
Test1 West 0901 375237423 10 000 5 000 - Best P1 (region because both Code Matches)
Test1 West 0700 34737523 16 000 6 000 - medium (because the area corresponds to only), we consider 'ALL' for the Code
Test1 West 0701 95862077 P3 16 000 6 000 - way (because the region corresponds to only), we consider 'ALL' for the Code
Test1 South 0703 73438953 P4 20 000 12 000 - worse (because region both Code DON T Match ' "), we consider option as worst 'ALL', 'ALL '.
Test1 South 0704 87332089 P1 20 000 12 000 - worse (because region both Code DON T Match ' "), we consider option as worst 'ALL', 'ALL '.
Test1 South 0705 98735162 P4 20 000 12 000 - worse (because region both Code DON T Match ' "), we consider option as worst 'ALL', 'ALL '.
Test1 South 0706 173894762 P9 20 000 12 000 - worse (because region both Code DON T Match ' "), we consider option as worst 'ALL', 'ALL '.
Test1 South 0902 72642511 P6 15 000 10 000 - way (because the Code corresponds to only) we consider 'ALL' for the region
In the final result, we should have row count equal to Table1, and as soon as there's game (best first, then middle, then the worst), then if is once again, that we should ignore.
There are other columns in the tables as well.
Thank you very much!
As you wish...
select filter, region, code, region2, code2, revenue, owner, limit1, limit2, match from ( select filter, region, code, region2, code2, revenue, owner, limit1, limit2, match, row_number() over( partition by filter, region, code order by match ) priority from ( select a.filter, a.region, a.code, a.revenue, a.owner, b.region region2, b.code code2, b.limit1, b.limit2, case when (a.region, a.code) = ((b.region, b.code)) then 'Best' when a.region = b.region or a.code = b.code then 'Medium' else 'Worst' end match from table1 a join table2 b on a.filter = b.filter and (b.region, b.code) in ( (a.region, a.code), (a.region, 'ALL'), ('ALL', a.code), ('ALL', 'ALL') ) ) ) where priority = 1 order by region, code; -
How to extract repeated the pair key / value of string in a column values?
Dear Experts,
I have this value stored in a cell as a string value for all rows
[ {"id":"1666","issueId":"ezsats:10000:1418145284747","sapId":"1101854","name":"INDIRA DEVU MD PC","createdBy":"Someone, Adam","dateAdded":"2014/12/09"}, {"id":"1667","issueId":"ezsats:10000:1418145284747","sapId":"1125031","name":"IL INDIRA DEVU MD PC","createdBy":"Someone, Adam","dateAdded":"2014/12/09"} ]I am updating a stringvalue who's name to a different format.
Old Format
[{'id': "1666", "issueId": "ezsats:10000:1418145284747", "SAPID": '1101854', 'name': 'INDIRA DHORDAIN MD PC,' "createdBy": 'Someone, Adam', "dateAdded": "2014/12/09"}, {'id': '1667', "issueId": "ezsats:10000:1418145284747", "SAPID": '1125031', 'name': 'IL INDIRA DHORDAIN MD PC,' "createdBy": 'Someone, Adam', "dateAdded": "2014/12/09"}]
New Format
INDIRA DHORDAIN MD PC. INDIRA DHORDAIN MD PC
How can you do with sql and plsql function?
Can you please help me.
Thank you and best regards,
Hello
Maybe you want something like this:
SELECT REGEXP_REPLACE (REGEXP_REPLACE (str
, '(^|"). *?" Name":"([^"]*)'"
, '\2;'
)
, ';". *'
) AS the target
FROM table_x
;
-
Hi all
I have a table with columns, rows and data mentioned below.
col1 col2
2B
1 B
2 C
1 g
3A
3B
3 C
I want the data as
col1 col2 col3 col4
1 A AND B
2 C D
3 C
But the data can be added up to 100 or 200 (dynamic)
I tried with pivot, but doesn't work for dynamic values. Is it possible to do with queries or procedure. Please suggest.
Thanlks
VermorelA typical pivot is done something like this (pre 11g)...
SQL> ed Wrote file afiedt.buf 1 with t as (select 1 as col1, 'A' as col2 from dual union all 2 select 1, 'B' from dual union all 3 select 2, 'C' from dual union all 4 select 2, 'D' from dual union all 5 select 3, 'A' from dual union all 6 select 3, 'B' from dual union all 7 select 3, 'C' from dual) 8 -- 9 -- end of test data 10 -- 11 select col1 12 ,max(decode(rn,1,col2)) as val1 13 ,max(decode(rn,2,col2)) as val2 14 ,max(decode(rn,3,col2)) as val3 15 from (select col1, col2, row_number() over (partition by col1 order by col2) as rn from t) 16 group by col1 17* order by col1 SQL> / COL1 V V V ---------- - - - 1 A B 2 C D 3 A B CThe number of columns in the output, must be known at the time where the query is analyzed. If you cannot easily base the number of columns on the data itself, without writing dynamic code.
Dynamically, you can change your procedure like that...
SQL> create table t as (select 1 as col1, 'A' as col2 from dual union all 2 select 1, 'B' from dual union all 3 select 2, 'C' from dual union all 4 select 2, 'D' from dual union all 5 select 3, 'A' from dual union all 6 select 3, 'B' from dual union all 7 select 3, 'C' from dual) 8 / Table created. SQL> ed Wrote file afiedt.buf 1 create or replace procedure data_1( p_cursor in out sys_refcursor ) is 2 l_stmt varchar2(32767); 3 l_cnt number; 4 begin 5 select max(count(*)) into l_cnt from t group by col1; 6 l_stmt := 'select col1 '; 7 for x in 1..l_cnt 8 loop 9 l_stmt := l_stmt||',max(decode(rn,'||x||',col2)) val_'||x; 10 end loop; 11 l_stmt := l_stmt||' from (select col1, col2, row_number() over (partition by col1 order by col2) as rn from t) group by col1 order by col1'; 12 open p_cursor for l_stmt; 13* end; SQL> / Procedure created. SQL> var rc refcursor; SQL> exec data_1(:rc); PL/SQL procedure successfully completed. SQL> print rc; COL1 V V V ---------- - - - 1 A B 2 C D 3 A B C SQL> -
get the length of each string in a column
Hi all
Is there a way to get the length of each string in a column:
for example:
If the table contains lines like below:
Select 'test test1 test31' col1 of double
Union of all the
Select 'sectest1 sectest234' double col1
The output should be as below:
col1
------------
4 5 6
8 10
That is to say get the count of each separated from the chain of space in a column. Is this possible using regexpr_substr?
Thanks in advance.
Roy.
Try the below
SELECT LISTAGG(val1,' ') IN ONE GROUP)
New_val ORDER BY lvl)
Of
(SELECT LENGTH (REGEXP_SUBSTR (col1,'[^] +', 1, LEVEL)) val1,)
RN,
LEVEL lvl
Of
(SELECT col1,
ROWNUM rn
Of
(SELECT 'test test1 test31' col1 OF double)
UNION ALL
SELECT 'sectest1 sectest234' double col1
)
)
CONNECT BY LEVEL<= regexp_count(col1,'="">
AND PRIOR rn = rn
AND PRIOR DBMS_RANDOM. VALUE IS NOT NULL
)
GROUP BY rn;
OUTPUT:-
=======
col1
----
4 5 6
8 10
Thank you
Ann
-
Compare and insert into SQL unique
Hello
I want to insert data to table from a source based to a line does not exist in the destination table based on a column in the destination table filter. Is it achievable using only SQL. ?
MERGE statement cannot be used because there is no unique key in the source table and the destination table.
Here's the data and tables.
-----------------------------------
create the table test_source
(
number of x_id
report_sent_flag varchar2 (30),
Number of the year
);
---------------------------------
insert into test_source
choose 10, 'Y', double 2013
Union of all the
Select 20, 'Y', double 2013
Union of all the
Select 30, 'Y', double 2013
Union of all the
choose 10, 'Y', double 2013
Union of all the
Select 20, 'Y', double 2013
Union of all the
Select 30, 'Y', double 2013;
------------------------------------
create the table test_dest
(
number of x_id
report_sent_flag varchar2 (30),
Number of the year
);
insert into test_dest
choose 10, 'Y', double 2013
Union of all the
choose 10, 'Y', double 2013;
------------------------------------------------------------
Select * from test_source;
10 Y 2013
10 Y 2013
20 Y 2013
20 Y 2013
30 Y 2013
30 Y 2013
Select * from test_dest;
10 Y 2013
10 Y 2013
Now, I need compare test_source and table test_dest on column (x_id, report_sent_flag year) and since 10, Y, 2013 is present in test_dest, it will be ignored. Rest should get inserted in the test_dest test_source table.
Can do by SQL only?
Please help
Thank you
Please help
Of course, you can use an INSERT statement. Try the following query.
INSERT INTO test_dest
SELECT *.
OF s test_source
WHERE THERE IS NO
(SELECT 1
OF test_dest t
WHERE s.x_id = t.x_id
AND s.report_sent_flag = t.report_sent_flag
AND s.year = t.year
);
Hope this fixes your condition.
-
How do I rotate my result of a query from a line to a SQL column?
Hey, guys:
Is it possible that I can rotate my result of a query from a line to a SQL column?
It's a certain type of pivot example
Instead of
DEPTNO DNAME
-------- ---------------
10 accounting
It would be
DEPTNO: 10
DNOM: ACCOUNTINGHello
When you have N columns to rank 1 and you want to display in the form of 1 column on several lines, it's called Unpivoting . Here's a way to do it:
WITH cntr AS ( SELECT LEVEL AS n FROM dual CONNECT BY LEVEL <= 2 -- number of columns to be unpivoted ) SELECT CASE c.n WHEN 1 THEN 'DEPTNO' WHEN 2 THEN 'DNAME' END || ':' AS label , CASE c.n WHEN 1 THEN TO_CHAR (d.deptno) WHEN 2 THEN d.dname END || ':' AS val , d.deptno -- PK, if needed FROM cntr c CROSS JOIN scott.dept d WHERE deptno = 10 -- or whatever ;The query above works in Oracle 9.1 or more.
From Oracle 11.1, you can also use the SELECT... Function of the UNPIVOT operator. -
How to search and replace only tag values XML and tag not the columns?
Hello
I'm new to xml db, and I have a scenario where I need to find and replace the xml content. The search is based on a clear text and not on any column.
I have a table as follows:
ID VARCHAR2 (32 BYTE),
MESSAGE_TYPE, VARCHAR2 (64 BYTE),
XMLTYPE OF the MESSAGE_CONTENT,
REJECTED_REASON VARCHAR2 (256 BYTE)
And XML in the form of the sample:
<? XML version = "1.0" encoding = "US-ASCII"? >
< MessageEnvelope >
< header >
Renault < partner > < / partners >
< MessageType > release < / MessageType >
S74 < PartnerMessageType > < / PartnerMessageType >
< MessageTime > 2001-12-17T 09: 30:47.0Z < / MessageTime >
String of < LinkToRawMessage > < / LinkToRawMessage >
< / header >
< body >
< version >
< address >
< DealerDestAddr > ABCD < / DealerDestAddr >
< DestAddr > ABCD < / DestAddr >
< NextDestAddr / >
< StartAddr / >
< / book >
< assignment / >
< ClientStatus / >
< dates / >
< HoldInfo >
< HoldCode > HoldTest < / HoldCode >
< / HoldInfo >
< message / >
< partner >
< OrderGiverCode > CMR00BCV < / OrderGiverCode >
< / partners >
< ToDo / >
< transport / >
< vehicle >
W0LGDM9A_Ran11115 < WINE > < / WINE >
< / vehicle >
< / Statement >
< / body >
< / MessageEnvelope >
I'm running the query of foll:
UPDATE t_xml D SET D.MESSAGE_CONTENT = replace (D.MESSAGE_CONTENT, "ABCD", "Chennai")
(WHERE d.MESSAGE_CONTENT.existsNode('//*[*="ABCD"]') = 1;
This works very well and replaces the two ABCD < DealerDestAddr > < / DealerDestAddr > and < DestAddr > ABCD < / DestAddr > tag values in Chennai. But the problem I encounter is if there is that a node with the name of the < ABCD > tag is also changed to < Chennai >. Please help me to fix this problem.
Kind regards
SprighteeWhat happens if I need to select and update a node that has the value null. Who doesn't have any value to it.
You can test if the partner has a child text() node:
existsNode( d.message_content , '/MessageEnvelope/Header[not(Partner/text())]' , 'xmlns="http://www.groupecat.com/CLV2/MessageEnvelope/20120501"' ) = 1 -
The extract number and String and replace with space
Hello
I need to extract number and string of a data table. I use Oracle 8i
For example: 001FI025A, 001PDIT002, 001UXSV029AA
I want to separate as follows
001 025 A FI
001 002 RESULTED
USXV 029 A 001
How can I achieve this? Any help is very useful.
Thank youHello
Welcome to the forum!
You must change "001FI025A" to the name of the column. Example:
SELECT '001FI025A', SUBSTR(TRANSLATE('001FI025A', '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ', '0123456789 '), 1, INSTR(TRANSLATE('001FI025A', '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ', '0123456789 '), ' ')) AS ELEMENT_1, SUBSTR(LTRIM(TRANSLATE('001FI025A', '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ', ' ABCDEFGHIJKLMNOPQRSTUVWXYZ')), 1, INSTR(LTRIM(TRANSLATE('001FI025A', '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ', ' ABCDEFGHIJKLMNOPQRSTUVWXYZ')), ' ')) AS ELEMENT_2, LTRIM(SUBSTR(TRANSLATE('001FI025A', '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ', '0123456789 '), INSTR(TRANSLATE('001FI025A', '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ', '0123456789 '), ' '))) AS ELEMENT_3, LTRIM(SUBSTR(LTRIM(TRANSLATE('001FI025A', '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ', ' ABCDEFGHIJKLMNOPQRSTUVWXYZ')), INSTR(LTRIM(TRANSLATE('001FI025A', '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ', ' ABCDEFGHIJKLMNOPQRSTUVWXYZ')), ' '))) AS ELEMENT_4 FROM DUAL;Kind regards
-
Compare and update the same column
Hello
SQL & gt; Select * from
version of v$.
BANNER
-----
Oracle Database 10g Express
Edition Release 10.2.0.1.0 - product
PL/SQL Release 10.2.0.1.0-
Production
CORE 10.2.0.1.0 Production
AMT for 32-bit Windows:
Version 10.2.0.1.0 - Production
NLSRTL Version 10.2.0.1.0-
Production
I'm having a problem to update the column in a Table...
What I'm trying to do is... .compare 2 column and then update one column by report...
Table 1 name: TEST1 _
Bq. LNID------NEW_AN8------OLD_AN8------OLD_DESC------2--------123002------100001------C2370------125846------CS24 100001------123024------100028------C2392------125868------CS25 100028------123025------C2393 100036------125869------100036 123026 CS26------100116------C2394------125870------100116------CS
_ Test2
SZAN8 SZAN82 SZAN86 SZAT1
123 002 100 001 100 001 C
125 846 CS 100 001 100 001
123 024 100 028 100 028 C
125 868 100 028 100 028 CS
125 869 100 036 100 036 CS
123 025 100 036 100 036 C
125 870 CS 100 116 100 116
123 026 100 116 100 116 C
I wanted to update the table SZAN82 of TEST2... based on the value of SZAT1...
I shud be able to choose the record type CS first, then the C type registration and the value of SZAN82 and check if it is present in the TEST1 table if she then I shud update the 82 value updated.
UPDATE LPLSCHEMA. LPL_F0101Z2_CUSTOMER C SET (SZAN82) =
(SELECT NEW_AN8 FROM LPL_CROSS_CUSTOMER B, LPL_F0101Z2_CUSTOMER C WHERE 'C.SZAT1 =' CS AND B.OLD_DESC = 'CS' and C.szan82 = B.old_an8);
I tried like tis... I received a request to void error more than a ranks...
Thanks in advance!
Ananda
Published by: Ananda on January 2, 2009 18:30
Published by: Ananda on January 2, 2009 18:30
Published by: Ananda on January 2, 2009 18:34
Published by: Ananda on January 2, 2009 18:37UPDATE LPLSCHEMA.LPL_F0101Z2_CUSTOMER C SET SZAN82 = ( SELECT NEW_AN8 FROM LPL_CROSS_CUSTOMER B WHERE C.SZAT1='CS' AND B.OLD_DESC='CS' AND C.szan82=B.old_an8 ) WHERE EXISTS ( SELECT 1 FROM LPL_CROSS_CUSTOMER B WHERE C.SZAT1='CS' AND B.OLD_DESC='CS' AND C.szan82=B.old_an8 );SY.
-
I did my browser Bing and it was working fine until today. When I open Firefox I get a message: Ref, then a long string of characters. I click on the Home icon and string changes. After doing this several times, I get the Bing search page. I don't get the startup of Firefox bookmark with the toolbar that has my book, history etc.. I can't clear the cache, if I can't the history tab. If I'm going to the mozilla firefox program folder and open it, there are a tool bar but can't erase recent history, etc. it. I don't have an administrator and a password on my home desktop. It's just me. I tried to follow your suggestions, but they do not apply to my situation. I don't really know if it is a firefox problem or bing. I've used google before bing and had no problems; I just wanted to try bing.
You can attach a screenshot?
- http://en.Wikipedia.org/wiki/screenshot
- https://support.Mozilla.org/KB/how-do-i-create-screenshot-my-problem
Use a type of compressed as PNG or JPG image to save the screenshot.
Start Firefox in Safe Mode to check if one of the extensions (Firefox/tools > Modules > Extensions) or if hardware acceleration is the cause of the problem (switch to the DEFAULT theme: Firefox/tools > Modules > appearance).
- Do NOT click on the reset button on the startup window Mode safe or make changes.
-
How to take a column of duplicate names and fill a different column with the same names, excluding duplicates?
I find easier to use this copy separate Automator Service (download Dropbox).
To install in your numbers > Services, double-click menu just the package downloaded .workflow and if necessary give permissions in system preferences > security & privacy.
To use, just:
- Select the cells in the column with duplicate names.
- Choose separate copy in numbers > Services menu.
- Click once in the upper cell where you want the deduplicated values appear.
- Command-v to paste.
SG
-
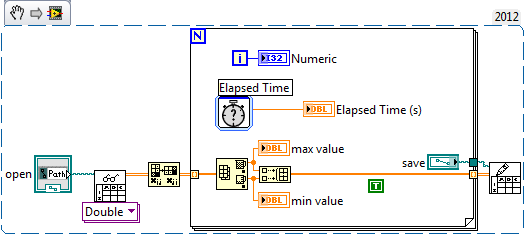
read the max and min of each column value
Dear qudoe
I'm doing a program in labview that challenge me to fight with a time.
Here, I enclose my labview code in which I have a data file, which includes 500 columns that I need to find the values min and max of each column.
I tried my best, but it takes 30 seconds to find the min and max value of each column.
I want to do this in less than a second.
so can anyone suggest me any necessary correction that can stimulate my program.
You don't have to open and close the file in a loop all the time and also you don't really need some time for this. Check the related code.
Of course, you can still optimize it for best performance, I just did a quick project to show how simple it is.
Maybe you are looking for
-
Cannot play youtube videos unless on youtube.
Recently my system seems to not being able to play youtube videos, at least on youtube. any other site that the video can be integrated into it just lies at 00:00 on the loading of the file. I've tried disableing all the addons. and videos refuse eve
-
Hi, I have a Toshiba laptop thast does not. His message brnging "file Windows is missign or corrupted, insert the installation discs and press r to try to recover." I did it and nothing happens at all. Any help or advice for me? I'm afraid, I'm a lit
-
Ecition Linux on Portege M400 Tablet
Just I was wondering if there is any Linux (free or not) desinged tablet edition or can stay in the Toshiba Portege M400 (3G)...
-
A satellite - not enough video memory for DVD player
When executing my windvd Invtervideo player, I get an error message that says "Not enough MΘmoire for dvd player" which is the benchmark for this? also the sound experience of parts multimedia player dvd but no video Please help!
-
I use the SMU 4140 to measure the curves of voltage/current for the transistors - it sets a voltage & I read (not necessarily on the same channel). But I noticed a peculiarity in the data according to the current limit. First of all, I get different