Understanding CPU % WAIT counter
Hey all,.
I was doing a little rummage in resxtop on our ESXi 4.1 U1 guests and noticed on the screen of cpu that all VMs on a given host had % queue time in hundreds (anywhere from 200 to 400). We have not received any complaints of the virtual machine is slow and time RDY % was less than 1 on all virtual machines. Make sure that it wasn't an IO issues I checked the disk and network performance and everything looks good there. The ESX host in question has 8 logical cores (dual quad core) and is running 9 vCPU unique of the virtual computer. I guess the question is, a queue time high % is a problem in our environment?
Thanks for any help,
-Jason
I think that the below document explained better
http://communities.VMware.com/docs/doc-9279
Tags: VMware
Similar Questions
-
ESX3.5 CPU waiting performance counter
After watching several virtual machines on multiple ESX hosts, I noticed that the waiting CPU meter always hovers around 95-100%. Is this normal? I can't find many good resources about this counter.
Thanks in advance.
Welcome to the forums!
Check out these links:
http://communities.VMware.com/docs/doc-9279 (WAITING % and a high value so that it is explained here)
http://communities.VMware.com/docs/doc-5240
AWo
VCP 3 & 4
Author @ vmwire.net
\[:o]===\[o:]
= You want to have this ad as a ringtone on your mobile phone? =
= Send 'Assignment' to 911 for only $999999,99! =
-
Hello world
I have a doubt: cpu events (for example "logical reading of cache bytes") enter trace files when tracing with level 12?
Thanks in advance
Laughing out loud
This isn't a wait event "what I expect."
It is a ' what I'm working on ' while the processor.
Source is statistics of session.
Session/state event tells you what you're doing.
Session statistics will tell you why you are doing something.
Or, actually, "logical reading of cache bytes" are more a summary measure. Other session statistics will contribute to this and you say why you read this for hiding, for example if it is a complies then the different categories of uniform get reasons, etc.
-
Waiting for CPU: what exactly does that mean?
Hi all
I worked on this database (11.2.0.3 on AIX 6.1) try to improve the performance of certain lots of an ERP system developed by my company. These are all processes that work very well in other environments, but here the clock times are horrible for the load and I was seeing 10% CPU, 90% CPU waiting for almost every process. This is the last section of a very long trace file where you can see the invisible "wait."
I know not how to do this: if I run something in the OS with a higher priority than to Oracle, what I will get. "Lack of processor" according to me, is the name for it. My question is: what else can cause this? If the OS say that nothing was on the computer, how can I study the root cause?
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 762529 3.24 16.60 0 3 0 0 Execute 8334641 5593.35 51349.14 344238 2115862 12349440 1341634 Fetch 7048666 1142.66 5978.90 385152 58108531 2068 7944263 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 16145836 6739.25 57344.65 729390 60224396 12351508 9285897 Misses in library cache during parse: 734 Misses in library cache during execute: 731 Elapsed times include waiting on following events: Event waited on Times Max. Wait Total Waited ---------------------------------------- Waited ---------- ------------ db file sequential read 620864 0.62 4858.21 Disk file operations I/O 42 0.00 0.00 latch: shared pool 8 0.04 0.06 asynch descriptor resize 6 0.00 0.00 direct path write temp 2 0.01 0.01 direct path read temp 94 0.03 0.57 db file scattered read 2129 0.44 23.90 log file switch completion 15 0.12 0.98 latch: cache buffers lru chain 2 0.00 0.00 resmgr:cpu quantum 15 0.00 0.03 latch: object queue header operation 2 0.00 0.00 8180 user SQL statements in session. 609 internal SQL statements in session. 8789 SQL statements in session. 288 statements EXPLAINed in this session. ******************************************************************************** Trace file: dbkpv_ora_811258_ARREC_BXA_AUTOMATICA.trc Trace file compatibility: 11.1.0.7 Sort options: prsela fchela exeela 1 session in tracefile. 8180 user SQL statements in trace file. 609 internal SQL statements in trace file. 8789 SQL statements in trace file. 754 unique SQL statements in trace file. 288 SQL statements EXPLAINed using schema: KIPREV.prof$plan_table Default table was used. Table was created. Table was dropped. 25357662 lines in trace file. 57345 elapsed seconds in trace file.marcusrangel wrote:
don't you think that it is possible that tracing would cause such a huge head?Your trace file contains 25 million lines, that is a significant amount of write operations, to be compared with the information that reads one-piece 620K consume dry 4858.
It is necessary to note that writing in the trace file leads to loss of time only when it is caused between measure of elapsed time from a visit to the database. But even if the write operation is due to the outside to measure the time of the call for a database (for example, information about a call, as FETCH #) it can be inside some call parent and will be included in the duration of the call of the mother.
If you are interested in the details of this process, I prepare an article on this topic in my blog.I would therefore recommend to reproduce a similar load without follow-up.
Published by: Alexander Anokhin on 12.07.2012 22:07
-
CPU wait time is the time a virtual machine did get on demand, but the processor has
Nothing in the process and so the CPU to simply waiting for then the time scheduled for the virtual
machine clicks by.
CPU Ready is the time that the virtual machine is ready, but could not get scheduled to run on the physical processor.
Bascially ready cpu the prompt is queued on the host computer, waiting for cpu means that the host is queued on the prompt.
-
I'm trying to find a definition of the time of latency (measured in percent) found in the CPU graph options in ESXi 5.0.
The "description of counter" suggests "the percent of the time, the virtual machine cannot run because it is suitor for access to the physical CPU", which sounds very similar to the CPU Ready description that suggests the "percentage of time that the virtual machine was ready, but could not get scheduled to run on the physical processor.
However, in my remarks, the latency of the CPU and CPU Ready move together.
Any help much appreciated.
Thanks, Liam.
There are 4 States of CPU. At least according to the white paper of vSphere CPU scheduler 5.1 :-)
Here is my understanding. Correct me if I'm wrong.
4 States above gives 100%.
100% = RUN + READY + % % WAIT CSTPWhen adding first, a virtual machine is RUN or in a READY State according to the availability of a physical CPU at the level of the ESX layer.
A virtual machine in the READY State is distributed by the vmkernel CPU scheduler and goes into State of EXECUTION. In the executing State, the virtual machine is served by the hypervisor and can do what it is supposed to do. Latency of loan & CPU CPU are similar
Latency: % of the time the VM cannot run because it's supported for access to the physical processor.
Loan: % of the time that the virtual machine was ready, but could not get scheduled to run on the physical processor. [e1: this is the total of all virtual machines in the ESX]
So it seems that the loan is after the latency time. Latency will go up first, as the favorite NUMA kernel might not be available, ready will follow when it has no basis available to all.It can be later off planned by vmkernel and enters a State LOAN or COSTOP. Co Stop happening if the virtual machine has > 1 vCPU and one of them is waiting for the other. Waiting happens because ESXi has insufficient physical CPU to serve. That's why you should right the size of the virtual machine. RDY % include % MLMTD, which is VM was ready to run, but has not been scheduled for time CPU due to the limit. You should not use Limit.
The VM has stopped is launched jointly by the suite and enters the READY State, which is ready for use. So ready time does not include the time to stop Co. You need to measure them both.
A virtual machine in the executing State may enter a WAIT state. Normally, it is because he is waiting for a resource and woke up later once the resource is available. It is normally the work of IO, such as waiting for a disc to return control of the table.
When a virtual machine is idle, not to intervene, between WAIT_IDLE, a particular type of the WAIT state. So it's not actually not waiting for what it is. A world of slow motion is awoken whenever it is interrupted.
WAITING also includes % SWPWT, which is CPU waits VMKernel swap memory
-
Unable to wait 30 seconds and then call the TCL Script as Action?
Hello and good afternoon all!
I was browsing through different threads and did some research and I am unable to get my applet to wait 30 seconds and then call a script TCL to a succession of 'action '. Here is the Basic script I am trying to run:
Event Manager applet track-loopback1
Event track 10 down state
command action 1.0 cli 'enable '.
Action 1.1, «config t» cli command
Action 1.3 cli command "event manager applet-counting backwards.
action 1.4 cli command 'event timer countdown 30 '.
action 1.5 cli command "action 1.0 wait 30.
Action 1.6 cli command "end".
Action 1.7 cli command "tclsh Loopback1 - Notification.tcl.The goal of this applet is simply wait interface Loopback1 go down, and then launch the applet "-Countdown ' which waits 60 seconds before calling end my TCL script. The pattern of ' countdown time 30 "and the" action 1.0 wait 30 "is my (lack of?". :-)) understand that after counting 30 I need to a trial of the action - but I'm not 100% clear on this? Ironically, he does, in fact, call the TCL script, it does not wait 30 seconds. My current workaround is to simply throw a statement "after 30000' in the TCL script, but I'm really curious to know why it does not work as expected (well, as I expected to work anyway!). Any help would be GREATLY appreciated. Thank you very much!
See you soon,.
Travis
See my response to https://supportforums.cisco.com/discussion/13009231/eem-applet-wont-fire... . What you do not work, so you should not call tclsh to EEM anyway.
-
Hi, I'm relatively new on VMs, but have been playing with them for about the last 6 months. I have an ESXi host that is running 4 comments VM, and I can't understand how the host allocates CPU on the host servers.
One of the guests is a newly installed Exchange 2010 Server 2008 R2. In this guest operating system, the windows Task Manager showed that the CPU was at least a little. However, when I look at the contents of the host tab, it shows the use of the processor as the half. I thought that the host was supposed to allocate as much as necessary, but it seems to me that the host has more that's not give at the prompt. So after I saw that I configured the client to have a 2nd virtual processor, but then I read that this is not recommended. I put also the actions of CPU high for this customer. I did not have a reservation, but I was wondering if I should? I booked it 8 GB of memory, which doesn't seem to be a problem. Even with the 2nd CPU virtual, always double virtual processors poster Task Manager get maxed out sometimes, and the server can act quite slow when I'm trying to set it up, but the usuage on the host still seems low.
I guess I'm confused, I thought the host was supposed to automatically extend the amount of resources needed a guest so that you shouldn't ever Miss unless the host itself is maxed out. Can someone explain to me the best way to set this up so this exchange area gets all CPUS, that he needs?
Thank you!
Hello
The way it works is that you have a server with 1 quad not core cpu no hyper threading. This would have 4 cores to vmware to use. 4 cores is 4 virtual cpu to use at a relaxed pace. If you were to add it is 4 virtual cpu for all your virtual machines, you should be oversubscription and basically your VMs will begin waiting for the long time available CPU. You can measure with the KPI of time CPU waiting.
When you set a reserve, say 1000 Mhz to a virtual machine, which means that there is always 1000 Mhz available on this computer from the total pool of available CPU MHz.
1 virtual processor for a machine of Exchange 2010 is by far not enough cpu power. You do not want to give a little.
But why you are seeing in the guest computer use at 100% is because you have allocated only 1 vcpu virtual machine, so it is only using 1 core of the CPU. If you have a quad core cpu you would probably see the ESXi host around 25% usage
Hope this clears for you
-
Count multiple responses in a single cell
I have a spreadsheet with data in an investigation. Some questions have more than one valid answer. In these cases the data were entered in the same cell. So, I have a column that looks like this:
Green, blue, Red
Blue, Orange
Yellow, green, blue
Black, green, red, Orange
And so on...
I can't understand how to count the number of 'Green' for example.
In excel I use this formula:
= SUMPRODUCT (-IsNumber (Search (text_to_find, within_text)))
I try to convert it to changing number ISNUMBER (for NOT (ISERROR (but does not work.))
What I am doing wrong?
I would solve you the problem like this:

Make sure that the table has two header lines by selecting the table, then using Table formatter:

Now add the colors all row 2 of the table, as shown.
B3 = if (a3≠"", Len ($a3) ≠Len (Substitute($a3,B$2,) "", namely "))," ")
It's shorthand dethrone select cell B3, and then type (or copy and paste it here) the formula
(= IF (A3≠"", LEN ($A3) ≠LEN (SUBSTITUTE($A3,B$2,) "", namely "))," ")
Select cell B3, copy
Select cells B3 at the end of the G column, paste
now to count the occurrences of each color:
B1 = COUNTIF (B, TRUE)
Select cell B1, copy
Select cells B1 to G1, dough
-
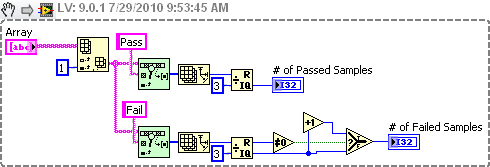
Question of pass/fail counter. [Help]
Hello! Can someone help me please understand how to count the number of Passed and Failed samples below? Each test samples must go through the series of test procedure (Test - 1, 2, 3 &) and I need determine if the sample has passed or failed based on the test procedures...
Thank you!
Jim solution will give the number of events Pass and the number of events Fail. I think the OP wants a number of examples of success or failure, not a success/failure count. Look at the two indicators in his image on the front. A sample only passes if it passes the three tests, otherwise it fails. I modified the code of Jim to return the number of samples that passed and failed, rather than a simple pass/fail County.
-
How to evaluate the impact of the removal of the CPU?
One of my clients must remove three (of four) CPU in order to respect the license agreement with Oracle.
To avoid problems and also for any problems remove the CPU can bring the list, I want to do a study on the possible impacts, especially in the performances, which can cause the removal.
How can I get this information?>
I really want to do all the tests and get concrete data on what is the real impact. The customer uses about 20% of his salary (cpu + cpu wait) but I know that this does not mean that it can simply cut their treatment at 25% safely.Yes, my client has a test environment, but does not have a database of the replay, so it is not possible to perform tests on the workload precisely.
How can I test without this tool, or at least the collection of data that will give me more specific that CWA information? It should open a SR on MOS?
>
There is nothing to open an SR for.The type of system change, you're talking about can only be tested on a system that best matches the production system. It has too many interactions between the CPU, memory, cache and external (disk) storage systems to be able to use a system of unpaired test and extrapolate the results.
You will have to do equivalent performance in order to obtain meaningful results, but these tests should be done on similar systems.
If I were you I would start by contacting your Oracle support person and identify the actual costs to continue to use your system for 4-processor and costs associated with maybe a 2 - cpu system.
Then I estimated costs of the work in question in any change of your test system to make it as nearly equivalent to the possible production system and add in the costs of running actually load tests and a fudge factor to take account possible downtime or a financial loss due to the degradation of the system if your estimates are erroneous.
You find it's cheaper and less risky, to pony just upward at least a 2-processor license. Who would buy at least your client enough comfort and time to design a more reliable long term solution.
-
Count the number of clips to children?
I have buttons which create specific videos such as a library object named "Clip_1":
function b_Add_Clip_1(event:MouseEvent):void
{
var b:MovieClip = new Clip_1();
b.Name = 'Clip_1 ";
container.addChild (b);
}And so on, I can add much Clip_1, Clip_2 by their corresponding buttons. I can't understand how to count the number of those that exist on the stage, however.
I would like the number of instances of Clip_1 to display in a text field.
For example: If there are 20 on the stage, the text field should display 20, if it is deleted, it should display 19.
I would be grateful for helpful tips, thank you.(Root [this_part + "_count"] .text) object = String (v_this_part); generates this error: 1105: target of assignment must be a reference value
You cannot assign a string to an object.
Try
Object (root [this_part + "_count"]). Text = String (v_this_part)
-
I have a need to collect data from performance of my bunches.
I understand cpu.usagemhz.average & mem.usage.average very well.
What I can't do, is bring together the cpu.usage.min, the cpu.usage.max, the mem.usage.min and the mem.usage.max for clusters.
In the reference of VI-Kit cmdlet to tools is watch the "cpu.usage.min" in detailed descriptions. So I guess that this is possible.
Can someone give me an example of how together these mini/maxi measures?
Min/max metrics require at least level 3 statistics.
You have at least one of the four historical intervals seams at least level 3?
If so, you can get the metrics of min/max for that specific interval with the cmdlet Get-Stat.
-
Hello world
I read an article about a measure of viscosity (http://www.seomoz.org/blog/tracking-browse-rate-a-cool-stickiness-metric). It's basically a way to measure how well you attract people to your Web site.
Viscosity for the last 7 days: (County of different users today) / (number of distinct users for the last 7 days)
Viscosity for the last 30 days: (County of different users today) / (number of distinct users for the last 30 days)
I have a table called WC_WEB_VISITS_F that is in the grain of the user's visit to one of my web sites.
Is there a way I can use OBIEE to calculate values above?
I can get the numerator. I create a logical column called count of separate to everyday users and aggregation set to Distinct Count on USER_ID and then I pivot my report to the Date of visit.
I can't understand how Distinct Count for X days. If there were separate count for this month, I just copy the count of distinct daily users and set the content to the month level, however, it is a floating range, I can't do that.
Does anyone have an idea of Cleaver for this?
Thank you!
-Joe11g is the function PERIODROLLING, which is the answer to all these requirements. The PERIODROLLING function allows you to perform an aggregation on a specified set of periods of grain of query rather than a grain of fixed time series. The most common use is to create rolling averages, as "13-week Rolling average." With 10 all we will get is a feature limited according to solutions...
-
Hello
According to my understanding CPU patches are released every quarter for each version & the realease of oracle database.
I use Oracle 10.2.0.3 on IBM - AIX 5.3 (64-bit).
I checked the link to metalink below.
Patches and updates-> Oracle Server/tools-> last Patchsets-> latest version of the Oracle/tools Patchsets-> server then selected oracle database and OS version-> Patch Type selected as all-> ranking selected under high security-> Go
But the above gives me a list of CPU patches!
So it is not mandatory that each and every six months we will have a new patch oracle CPU? Or I make a mistake in the selection above?
Thanks in advance.
Best regards
oratestHello
Patches of CPU Oracle releases for currently taken versions support only.
And the latest patch of CPU to 10.2.0.3 was Jan 2009 CPU-7592354
I hope this helps...



Maybe you are looking for
-
Everyone knows the high battery consumption after iOS 9.3.5
-
2450deskjet wireless printer: same message each time I try to download the software for dj2540
I tried several times to get the software downloaded to set up a wireless printer. I do not have a pc cannot use the cd delivered
-
How to charge the battery if the power input is damaged?
The decision-making power on my 4070CDT satellite was damaged and the laptop will no longer take power or charge the battery from this socket. (Attempts to re - solder the joint damaged power detection circuits!) Does anyone know if I can feed the ap
-
Satellite A100 PSAAR - the hail its Windows 7
Hey guys,. I have a Satellite A100 (PSAAR) that I was running a beta version of Windows 7 on (I had updated to Vista). When I decided to format it and install a new version of Windows 7, audio has become really intestine. Is there a driver Toshiba I
-
Update FAIL! Windows Server 2008
Hi all for some unknown reason, I am unable to install "Windows6. 0-KB2117917-french-x 64.msu. I get the same error: 0 x 80070020 normally, I don't like, but since I tried to install this update I lost the ability to view/edit my server with this err