Unexpected results - unique Triple returns 2 results using SEM_MATCH
Hi, I have a prototype that I build. I start with a very simple triple store that says:(<http://ihc.com/drik/concept#clinical_cohort>, <http://www.w3.org/2000/01/rdf-schema#subClassOf>, <http://ihc.com/drik/concept#cohort>)select
object
from
table(sem_match('{ <http://ihc.com/drik/concept#clinical_cohort> <http://www.w3.org/2000/01/rdf-schema#subClassOf> ?object . }',
sem_models('Prototype'),
sem_rulebases('RDFS'),
sem_aliases(sem_alias('rdfs','http://www.w3.org/2000/01/rdf-schema/')),
null
))http://ihc.com/drik/concept#cohort
http://ihc.com/drik/concept#clinical_cohort
http://www.w3.org/2000/01/rdf-schema#ResourceScript to reproduce is:
CREATE TABLE DRIK.RDF_DATA
(
ID NUMBER,
TRIPLE MDSYS.SDO_RDF_TRIPLE_S
)
COLUMN TRIPLE NOT SUBSTITUTABLE AT ALL LEVELS
TABLESPACE RDF_USERS
;
-- Staging Table
CREATE TABLE DRIK.RDF_STAGING
(
RDF$STC_SUB VARCHAR2(4000 BYTE) NOT NULL,
RDF$STC_PRED VARCHAR2(4000 BYTE) NOT NULL,
RDF$STC_OBJ VARCHAR2(4000 BYTE) NOT NULL,
RDF$STC_SUB_EXT VARCHAR2(64 BYTE),
RDF$STC_PRED_EXT VARCHAR2(64 BYTE),
RDF$STC_OBJ_EXT VARCHAR2(64 BYTE),
RDF$STC_CANON_EXT VARCHAR2(64 BYTE)
)
TABLESPACE RDF_USERS
;
begin SEM_APIS.CREATE_RDF_MODEL('Prototype', 'RDF_DATA', 'TRIPLE', 'RDF_USERS'); end;
grant insert on rdf_data to mdsys;
Insert into DRIK.RDF_STAGING
(RDF$STC_SUB, RDF$STC_PRED, RDF$STC_OBJ)
Values
('<http://ihc.com/drik/concept#clinical_cohort>', '<http://www.w3.org/2000/01/rdf-schema#subClassOf>', '<http://ihc.com/drik/concept#cohort>');
COMMIT;
begin SEM_APIS.BULK_LOAD_FROM_STAGING_TABLE('Prototype', 'DRIK', 'RDF_STAGING'); end;
select id, a.triple.GET_TRIPLE() from drik.rdf_data a;
begin SEM_APIS.CREATE_ENTAILMENT('PROTOTYPE_RB_IDX', SEM_Models('Prototype'), SEM_Rulebases('RDFS')); end;Hello
What is expected. Rule RDFS10 in the following W3C SPECIFICATION dictates this behavior.
http://www.w3.org/TR/rdf-mt/
If you don't like (or wants to) this rule, then you can turn it off.
SEM_APIS. CREATE_ENTAILMENT ('PROTOTYPE_RB_IDX',
SEM_Models ('Prototype'),
SEM_Rulebases ('RDFS'),
SEM_APIS. REACH_CLOSURE,
"RDFS10 -"
);
There are a few other rules, you may want to disable (turn off).
"RDFS12-, RDFS4A-, RDFS4B-, RDFS6-, RDFS8-, RDFS10-, RDFS13 -"
Thank you
Zhe Wu
Tags: Database
Similar Questions
-
Table query result using prepared as a parameter in the prepared statement later
Hi all
Very new to PHP. A series of 3 prepared statements (see code below), I'm trying to sink. This page is triggered from a link on a page that lists the individual and all candidates which works well. Prepared statement 1 works and displays the data in the columns line wanted specific, bottom access so I would call it record and areas, but I think it is called line and columns here. Prepared Statement 2 which hands on a table of cross references (we have a many-to-many relationship between candidates and positions, therefore for the table of cross references) works and I can say the $selected_positions charges table, because I can see position_id data in the < body > of the file using this:
<? PHP
foreach ($selected_positions as $item) {}
echo $item. "< br / > ';
}
? >
Can't take this $selected_positions table and use it as parameter in the prepared statement 3, at least not how I try to do. So obviously he manages not prepared statement 3 no way is a table that I called $the_positions which is supposed to contain the ID of the post, position of securities and to position the position_id numbers that are in the array $selected_positions. I can say that 3 of prepared statement is a failure because there is no indication in this table that is in the < body > of the file:
< table class = "stripes table" >
< b >
Identification of the Position < /th > < th >
< /Th > < th > post number
Title < th > < /th >
< /tr >
<? PHP while ($stmt-> fetch()) {? >}
< b >
< td > <? = $position_id;? > < table >
< td > <? = $position_number;? > < table >
< td > <? = $title;? > < table >
< /tr >
<? PHP}? >
< /table >
Here is the PHP script:
<? PHP
require_once '... /includes/session_timeout_db.php';
? >
<? PHP
require_once '... /includes/Connection.php';
initialize the flag
$OK = false;
$conn = dbConnect ('read');
initialize statement
$stmt = $conn-> stmt_init();
If (isset($_GET['candidate_id'])) {}
$sql = ' SELECT candidate_id, last_name, first_name, society, mas_number, last_modified, notes
CANDIDATES WHERE candidate_id =?'; }
If ($stmt-> {prepared ($sql))}
bind the query parameter
$stmt-> bind_param ('i', $_GET ['candidate_id']);
run the query and fetch the result
$OK = $stmt-> execute();
bind the results to variables
$stmt-> bind_result ($candidate_id, $last_name, $first_name, $company, $mas_number, $last_modified, $notes);
$stmt-> fetch();
free resources for the second query database
$stmt-> free_result();
}
get the associated positions candidate
$sql = 'SELECT position_id FROM pos2cands WHERE candidate_id =?';
If ($stmt-> {prepared ($sql))}
bind the query parameter
$stmt-> bind_param ('i', $_GET ['candidate_id']);
run the query and fetch the result
$OK = $stmt-> execute();
$stmt-> bind_result ($position_id);
Browse the results to store in a table
$selected_positions = [];
While ($stmt-> fetch() {)}
[] $selected_positions = $position_id;
}
}
find data on the position of the table
$sql = ' SELECT position_id, position_number, title
FROM place WHERE position_id =?';
If ($stmt-> {prepared ($sql))}
bind the query parameter
$stmt-> bind_param ('i', $_GET [$position_id]);
run the query and fetch the result
$OK = $stmt-> execute();
bind the results to variables
$stmt-> bind_result ($position_id, $position_number, $title);
Browse the results to store in a table
$the_positions = [];
While ($stmt-> fetch() {)}
[] $the_positions = $position_id;
}
}
Get the error message if the request fails
If (isset ($stmt) & &! $OK) {}
$error = $stmt-> error;
}
If (! $stmt) {}
$error = $conn-> error;
} else {}
$numRows = $stmt-> num_rows;
}
? >
Thank you in advancel
You want to use the value of request 1 or query2 as a parameter in the query 3, right? Rather than build a table, you can simply use the value returned by each line that the query returns. I use PDO, no MySQLi, so I can't knock out quickly the MySQLi example for you.
While ($result = $sql-> fetch (PDP::FETCH_ASSOC)) {}
$field = $result ['domain'];Now we can use the value of $field as parameter for the next query.
The brace that closes the while loop is placed after the last query
so no need to fill an array with values
}
Your approach is doable with a few changes to the way in which you go through the table, but it is unnecessarily complicated.
You might be able to use a single query to get all the data if you use left joins. With this approach, you start with the table that SHOULD return a result or which requires no dependencies to other tables. The structure is like this:
SELECT field1, Field2, field3 FROM (SELECT * FROM table1 WHERE field3 = param1) has
LEFT JOIN (SELECT * FROM table2 WHERE A.field4 = table2.field4) B
LEFT JOIN table3 ON table3.field5 = B.field5 ORDER BY Field1
A and B above are aliases for subsets of the table. You can image a (tacit) sign = equal A
-
How can we make the Partition on the result using only sql?
Hello
How to make the partition on sql result using the query.
sample
I want to create the partition column using the queryBPREF_NO BILL_MONTt AVG_IND partition Q12345 1/31/2009 2 part1 Q12345 2/28/2009 2 part1 Q12345 3/31/2009 2 part1 Q12345 4/30/2009 2 part1 Q12345 5/31/2009 2 part1 Q12345 6/30/2009 1 part1 Q12345 7/31/2009 2 part1 Q12345 9/30/2009 1 part2 Q12345 10/31/2009 2 part2 Q12345 11/30/2009 2 part2 Q12345 1/31/2010 1 part3 Q12345 2/28/2010 2 part3 Q12345 3/31/2010 2 part3 Q12345 11/30/2011 2 part4 Q12345 2/29/2012 2 part5 Q12345 3/31/2012 2 part5 Q12345 4/30/2012 2 part5 Q12345 5/31/2012 2 part5 Q12345 7/31/2012 2 part6
from the logic below
If bill_month is the sequence then it must create a partition and if the breaks we need to introduce the new partition.
just for example...
January 31, 2009 to July 31, 2009 is called part1
August 30, 2009 to November 30, 2009 called part2
like wise...
is it possible to make the partition of the query itself.
Please guide me in this regard
Thanks in advance
Iqbalwith testdata as ( select 'Q12345' BPREF_NO, to_date('1/31/2009','MM/DD/YYYY') BILL_MONTt,2 AVG_IND from dual union all select 'Q12345', to_date('2/28/2009','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('3/31/2009','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('4/30/2009','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('5/31/2009','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('6/30/2009','MM/DD/YYYY'),1 from dual union all select 'Q12345', to_date('7/31/2009','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('9/30/2009','MM/DD/YYYY'),1 from dual union all select 'Q12345', to_date('10/31/2009','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('11/30/2009','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('1/31/2010','MM/DD/YYYY'),1 from dual union all select 'Q12345', to_date('2/28/2010','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('3/31/2010','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('11/30/2011','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('2/29/2012','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('3/31/2012','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('4/30/2012','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('5/31/2012','MM/DD/YYYY'),2 from dual union all select 'Q12345', to_date('7/31/2012','MM/DD/YYYY'),2 from dual ) select BPREF_NO , AVG_IND , BILL_MONTt , 'part'|| sum (partition) over (partition by BPREF_NO order by BILL_MONTt) partition from ( select BPREF_NO , AVG_IND , BILL_MONTt , case when months_between (BILL_MONTt, lag(BILL_MONTt) over (partition by BPREF_NO order by BILL_MONTt)) = 1 then 0 else 1 end partition from testdata ) BPREF_NO AVG_IND BILL_MONTT PARTITION Q12345 2 01/31/2009 part1 Q12345 2 02/28/2009 part1 Q12345 2 03/31/2009 part1 Q12345 2 04/30/2009 part1 Q12345 2 05/31/2009 part1 Q12345 1 06/30/2009 part1 Q12345 2 07/31/2009 part1 Q12345 1 09/30/2009 part2 Q12345 2 10/31/2009 part2 Q12345 2 11/30/2009 part2 Q12345 1 01/31/2010 part3 Q12345 2 02/28/2010 part3 Q12345 2 03/31/2010 part3 Q12345 2 11/30/2011 part4 Q12345 2 02/29/2012 part5 Q12345 2 03/31/2012 part5 Q12345 2 04/30/2012 part5 Q12345 2 05/31/2012 part5 Q12345 2 07/31/2012 part6 -
I wish to cancel my account, do not use the product. Awaiting return. I use a MAC
I wish to cancel my accountdoes not use the product. Awaiting return. I use a MAC
Hello
In order to cancel the order, please contact customer service
You can check: http://helpx.adobe.com/x-productkb/global/phone-support-orders.html
For more information on cancellation: cancel your creative cloud membership
Hope this helps!
-
Qyery return empty results using dbms_xmlgen does not work as expected
Hi group.
I use the following code in a procedure PSQL
procedure selectXML (consulted in varchar2, xmlout on clob) as
context dbms_xmlquery.ctxtype;
Resultado clob.
integer from Tam.
context_gen dbms_xmlgen.ctxHandle;
Start
IF useDBMS_XMLGEN THEN
BEGIN
context_gen: = DBMS_XMLgen.newContext (consulta);
DBMS_XMLgen.usenullattributeindicator (context_gen, true);
result: = DBMS_XMLgen.GetXml (context_gen);
TAM: = DBMS_LOB. GetLength (result);
DBMS_LOB. Copy (XMLout, resultado, Tam, 1, 1);
DBMS_XMLgen.closecontext (context_gen);
ON THE OTHER
Context: = DBMS_XMLQUERY.newContext (consulta);
DBMS_XMLQUERY.usenullattributeindicator (Context, true);
result: = DBMS_XMLQUERY. GetXml (Context);
TAM: = DBMS_LOB. GetLength (result);
DBMS_LOB. Copy (XMLout, resultado, Tam, 1, 1);
DBMS_XMLQUERY.closecontext (Context);
END IF;
end;
If the query used returns nothing (for example ' SELECT * FROM dual WHERE rownum = 0') using the DBMS_XMLQUERY code, the function getxml() method returns
<? XML version = "1.0"? >
< ROWSET / >
but using the DBMS_XMLGEN code, the function getxml() method returns nothing.
This behavior is normal or I do something wrong?
I'm testing the code in Oracle9i Enterprise Edition Release 9.2.0.7.0 but must also be run, Oracle 8 and 10
Thanks in advance
JavierThis behavior is normal or I do something wrong?
This seems to be a normal behavior by design:
SQL> select 1 id, dbms_xmlgen.getxml('select * from dual where 1=0') xml from dual union all select 2, dbms_xmlquery.getxml('select * from dual where 1=0',0) xml from dual union all select 3, dbms_xmlquery.getxml('select * from dual where 1=0',1) xml from dual union all select 4, dbms_xmlquery.getxml('select * from dual where 1=0',2) xml from dual ID XML --- ---------------------------------------------------------------------------------------------------- 1 23 ]> 4 -
Using variables in sql, unexpected results queries coldfusion.
I came across a somewhat embarrassing problem. I'd be interested to see if the following works for other people:
< cfset sql_var "'something', 'something'" is >
< = 'test' datasource cfquery name = "db" >
Select id from table where unnom (#sql_var #)
< / cfquery >
Because it is that which produces a sql error - coldfusion tries to run the query in the form
Select id from table where unnom in ("something", "thing")
It is with the double quotes around each of the strings, even if it has not been specified in the sql_var variable.
So I tried this:
< cfset sql_var = "something","something else" > ".
< = 'test' datasource cfquery name = "db" >
Select id from table where unnom in (' #sql_var # ')
< / cfquery >
Where the sql_var variable has that single quotes between the two strings, and I added the quotes to the select statement. It produces no error, but no results either. Running sql is
Select id from table where unnom ('something', 'something')
Which is exactly as it should. I copy and paste the exact same query into the database and it produces results - but when coldfusion runs the query it doesn't. Executes the query with without product quotes a sql error, which is what I expect wopuld.
Which leaves me somewhat at a loss. Anyone got any ideas?
Running CF 6.1 (I think) using a database MySQL, if that makes a difference to anything.
It is with the double quotes around each of the strings, even if it has not been specified in the sql_var variable.
In Coldfusion, 'something' and 'something' are the same thing. You should expect that Coldfusion could pass from one to the other.
Where the sql_var variable has that single quotes between the two strings, and I added the quotes to the select statement. It produces no error, but no results either. Running sql is
Select id from table where unnom ('something', 'something')I don't think that it is running the query. Before moving on to the string, "something", "something else" to the Coldfusion query will automatically escape the single quotes on either side of the comma. This is the default behavior. The resulting query is
Select id from table where unnom in (' something "," something else "")
To avoid these complications, use the PreserveSingleQuotes() function. Therefore,.
Select id from table where unnom in (#preservesinglequotes (sql_var) #)
-
Unexpected result in efficieny comparson of Hashtable and ArrarList
I learned that Hashtable is much more efficient than ArrayList. To convince my self, I did the following:
(a) create a file of 100000 channels acii range of 65 to 122 3 random letters. Foll. is the code I used.
import java.util.Random;
import java. IO;
Class RandomStrToFile {}
Public Shared Sub main (String [] args) {}
Random rnd = new Random();
long I, imax = 100000;
cNL tank;
String sFileName = "myrandom_strings.txt";
String sBuffer ="";
try {}
FileWriter fw = new FileWriter (sFileName);
BufferedWriter BW = new BufferedWriter (fw);
for (i = 0; i < imax; i ++) {}
sBuffer = "" + (char) (65 + (int) ((rnd.nextDouble ()) * 57)) + (char) (65 + (int) ((rnd.nextDouble ()) * 57)) + (char) (65 + (int) ((rnd.nextDouble ()) * 57));
BW. Write (sbuffer);
bw.newLine ();
System.out.println (sbuffer);
}
BW. Close();
FW. Close();
} catch (IOException e) {}
}
}
b. timed to create a unique valielist of the file above, nuer ArrayList and Hashtable respectively. Here is my code:
import java. IO;
Import Java.util;
public class test2 {}
Public Shared Sub main (String [] args) {}
String Slithe.
int iVal;
long startTime, endTime;
< String > ArrayList al = new ArrayList < String > ();
Hashtable ht = new Hashtable (4999); Use a prime number
try {}
////////////////////////////////////
FileReader fr = new FileReader("C:\\Home\\MyJava\\eclipse_proj\\MyFirst\\bin\\myrandom_strings.txt");
BufferedReader br = new BufferedReader (en);
startTime = System.currentTimeMillis ();
iVal = 0;
While ((mean = br.readLine ())! = null) {}
System.out.println (William);
iVal iVal = + 1;
If (! ht.contains (William)) {}
HT.put(iVal,sLine);
System.out.println (William);
}
}
endTime = System.currentTimeMillis ();
System.out.println ("elapsed time in the Hashtable is:" + (endTime-startTime));
Br. Close();
Fr. Close();
/////////////////////////////////////////
en = new FileReader("C:\\Home\\MyJava\\eclipse_proj\\MyFirst\\bin\\myrandom_strings.txt");
BR = new BufferedReader (en);
startTime = System.currentTimeMillis ();
iVal = 0;
While ((mean = br.readLine ())! = null) {}
System.out.println (William);
iVal iVal = + 1;
If (! al.contains (William)) {}
Al. Add (William);
System.out.println (William);
}
}
endTime = System.currentTimeMillis ();
System.out.println ("elapsed time of ArrayList is:" + (endTime-startTime));
Br. Close();
Fr. Close();
} catch (IOException e) {}
}
}
To my surprise Hashtable approach has been much slower Quen ArrayList approach. Am I missing something here?user10035918 wrote:
OK, here we go. I can't get rid of the fileYes, you can. You're not a file need to compare the performance of the list relative to the map. Since you don't get rid of it, I don't look at your test.
Here is the result of my test. Card is more than 10 000 times faster than the list here.
list took 20,828 ms to find 500 items map took 16 ms to find 5,000 itemsHere's the code.
package scratch; import java.util.List; import java.util.ArrayList; import java.util.Map; import java.util.HashMap; public class MapVList { static Listlist = new ArrayList (); static Map -
VLOOKUP gives incorrect/unexpected results
HI guys
I used to think I had this spreadsheet thing down pat, but I find myself place after midnight with a VLOOKUP problem struggle! I really hope that you can show me the error of my ways...
I'm a convert from Excel so I can be taken in a mind control thing. I built a fairly large things relating of worksheet to do a lot of hobbies. I give it to the people who do the same kind of thing I do. It calculates the SOAP making tips, but I just found out that he gets things wrong - that is potentially dangerous.

I have a version simplified that what is happening in the picture above. In the F2 cell I: VLOOKUP (E2, values: results, 2, the search by proximity-match).
Now, I expect the numbers look down column B to find the value in cell E2 (1.90) and return the corresponding value of the C column (19.0). However, it does not. Instead, it provides the value of the cell above as if it could not find a match.
I tried every setting I can think of nothing doesn't. I put all the cells in the table above to a number to 2 decimal places. I even changed the exact match and close match but that just made things worse.
I know it's going to be something that will make me to get started me, but I need to fix no will not hurt. Any help gratefully received.
Cheers, Grant
PS I think I should mention that I do this on an iPad 2 air which is a bit new for me. And I just noticed I have write in figures for Mac. I'm sorry for that but I think that the versions are supposed to have the same capabilities?
I suspect that you use calculated values, rather than hand is entered in your "Search values" column, and even if you have formatted the column to display two decimal places, due to approximations that occur when doing calculations decimal on a computer using binary mathematics, the actual values using the VLOOKUP function differ slightly as many additional decimals on any line. If you wrap each calculation in a function to change the actual value with 2 decimal places, if the cell contains exactly what your put poster in the form, you will get the desired result.
-
Unexpected results after calculation
Hello.
I have 3 databases of production which have worked successfully until Thursday.
FARM sales for the whole company per month.
EB2. Sale of a specific division a week.
EB3. Sale of a specific division and top ranges, per day.
Thursday.
The problem is that after calculation of EB3, the totals I see in the validation reports are incorrect when compared with the totals in the EB1.
The whole story is the display of incorrect results, not only the data for the current month, which is that I charge per day. I'm doing an incremental loading of the current and previous month only.
I took a backup and loaded in the EB3 and performed the calculation... once again the totals were incorrect.
Friday
When I compare the validation reports, totals in EB3 were as expected when checking against the EB1.
I did nothing for the outline, the backup is the same.
EB1 and EB2 were ok.
Saturday (today)
When I see the validation report today I noticed that EB3 has the same behavior; incorrect results.
And EB2 also contains unexpected values after calculation.
Have you encountered this problem before? Is there something specific I should review to determine and solve this problem?
Log files reflect not any message "error" or "fail".
Any comment is welcome.
Kind regards
JC
Difficult to clarify the question without knowing what actually do the calculations. Just a suggesiton wild as you see error every day replacing when you see good results just make a backup of contour and then use the problematic day contour compare to compare 2 contours. May be there are some jobs that you are not aware of the evolution of the sketch, thus destabilizing the whole of the data!
-
Different results using Matcher.replaceAll on a literal type of update
I expect the results for all of the following scenarios would have been the same:
public class {PatternMatcher
Public Shared Sub main (String [] args) {}
Model p;
Matcher m;
duplicates
p = Pattern.compile ("(.*)");
m = p.matcher ("abc");
If (m.matches ()) System.out.println (p + ":" + m.replaceAll ("xyz"));
unique
p = Pattern.compile ("(.+)");
m = p.matcher ("abc");
If (m.matches ()) System.out.println (p + ":" + m.replaceAll ("xyz"));
WTF
p = Pattern.compile ("(.*?)");
m = p.matcher ("abc");
If (m.matches ()) System.out.println (p + ":" + m.replaceAll ("xyz"));
duplicates
p = Pattern.compile ("(.*+)");
m = p.matcher ("abc");
If (m.matches ()) System.out.println (p + ":" + m.replaceAll ("xyz"));
unique
p = Pattern.compile ("^(.*)");
m = p.matcher ("abc");
If (m.matches ()) System.out.println (p + ":" + m.replaceAll ("xyz"));
duplicates
p = Pattern.compile ("(.*) $");
m = p.matcher ("abc");
If (m.matches ()) System.out.println (p + ":" + m.replaceAll ("xyz"));
unique
p = Pattern.compile ("^(.*) $");
m = p.matcher ("abc");
If (m.matches ()) System.out.println (p + ":" + m.replaceAll ("xyz"));
unique
p = Pattern.compile ("(.)) (. *).)");
m = p.matcher ("abc");
If (m.matches ()) System.out.println (p + ":" + m.replaceAll ("xyz"));
}
}
But the results vary depending on the type of update:
(. *): xyzxyz
(. +): xyz
(.*?) : xyzaxyzbxyzcxyz
(. * +): xyzxyz
^(.*): xyz
(. *) $: xyzxyz
^(.*) $: xyz
(. (.*).) : xyz
Because all models have a capturing group that covers everything, but the replacement string has no references of group, I expect that in any case the replacement string would simply be returned unchanged (so just "xyz").
I discovered a bug in the main library? or am I misunderstood how it should work?
Now for a real answer.
(. *) will produce two matches "abc" and "" (the end of the string) because the * means we can have zero. Idk if this is a standard regex, but it is this that java is. So let's replace it with "xyz" and produce "xyzxyz".
(. +) only has a game and works as expected
(.*?) is lazy and weird and will be 4 groups to capture anything. To see, ' | ' which is a capture ' |. ' a | b | c | ». so we will produce "xyzaxyzbxyzcxyz".(.*+) Idk what it should even do lol
so on, etc.
All of this has to do with the fact that regex. * seems to act funny.
-
Oracle 12 c - unexpected result with the insertion of the DBA_VIEWS view
Hello
I try inserting the DBA_VIEWS fields in a table belonging to a common C a PDB file ##SA user:
(a) the PDB PDBORCL using user C ##SA connection:
SQL * more: Production of liberation 12.1.0.1.0 kills him Sep 10 16:21:39 2013
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Enter the password:
Last successful login time: kills Sep 10-2013 16:18:26 + 02:00
Connected to:
Database Oracle 12 c Enterprise Edition Release 12.1.0.1.0 - 64 bit Production
With the options of partitioning, OLAP, advanced analytics and Real Application Testing
C##SA@pdborcl 10.09.2013 > see the con_name
CON_NAME
------------------------------
PDBORCL
C##SA@pdborcl 10.09.2013 > see the con_id
CON_ID
------------------------------
3
(b) I create the table user SA_VIEWS_V
C##SA@pdborcl 10.09.2013 > select count (*) in the dba_views;
COUNT (*)
----------
6220
1 selected line.
C##SA@pdborcl 10.09.2013 > create table sa_views_v (owner varchar2 (128), view_name varchar2 (128));
Table created.
(c) the insertion in the table SA_VIEWS_V gave me only 65 rows at the same time lines of content 6220 dba_views:
C##SA@pdborcl 10.09.2013 > INSERT INTO SA_VIEWS_V (OWNER, VIEW_NAME) SELECT MASTER, VIEW_NAME DBA_VIEWS;
65 lines were created.
C##SA@pdborcl 10.09.2013 > commit;
Validation complete.
C##SA@pdborcl 10.09.2013 > SELECT MASTER, VIEW_NAME DBA_VIEWS;
...
IX
IX
IX
SH
6220 selected lines.
(d) you will find above the executed plan of the insert and the single select statement:
C##SA@pdborcl 10.09.2013 > select * from table (dbms_xplan.display_cursor ('aj3vkggtvv9d9'));
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------
SQL_ID, aj3vkggtvv9d9, number of children 0
-------------------------------------
INSERT INTO SA_VIEWS_V (OWNER, VIEW_NAME) SELECT VIEW_NAME, MASTER OF
DBA_VIEWS
Hash value of plan: 1585970530
-----------------------------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
-----------------------------------------------------------------------------------------------------
| 0 | INSERT STATEMENT. | | | 136 (100) | |
| 1. LOAD TABLE CLASSIC | | | | | |
|* 2 | FILTER | | | | | |
|* 3 | HASH JOIN | | 65. 6045. 136 (0) | 00:00:01 |
|* 4 | HASH JOIN | | 65. 4875. 132 (0) | 00:00:01 |
| 5. NESTED LOOPS | | | | | |
| 6. NESTED LOOPS | | 65. 3315 | 131 (0) | 00:00:01 |
| 7. INDEX SCAN FULL | I_VIEW1 | 65. 325. 1 (0) | 00:00:01 |
|* 8 | INDEX RANGE SCAN | I_OBJ1 | 1. | 1 (0) | 00:00:01 |
| 9. TABLE ACCESS BY INDEX ROWID | OBJ$ | 1. 46. 2 (0) | 00:00:01 |
| 10. INDEX SCAN FULL | I_USER2 | 131. 3144 | 1 (0) | 00:00:01 |
| 11. TABLE ACCESS FULL | USER$ | 131. 2358. 4 (0) | 00:00:01 |
| * 12 | TABLE ACCESS FULL | USER_EDITIONING$ | 1. 6. 2 (0) | 00:00:01 |
| 13. SEMI NESTED LOOPS. | 1. 29. 2 (0) | 00:00:01 |
| * 14 | INDEX SKIP SCAN | I_USER2 | 1. 20. 1 (0) | 00:00:01 |
| * 15 | INDEX RANGE SCAN | I_OBJ4 | 1. 9. 1 (0) | 00:00:01 |
| * 16. TABLE ACCESS FULL | USER_EDITIONING$ | 1. 6. 2 (0) | 00:00:01 |
-----------------------------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
2 filter (((IS NULL AND "O". ("TYPE #" <>88) OR BITAND ("O". ("" FLAGS ", 1048576) = 1048576 OR
BITAND ("U". "" SPARE1»(, 16) = 0 OR (((SYS_CONTEXT ('userenv', 'current_edition_name') = ' ORA$ BASE ", AND)))"
"U"." TYPE #"(<>2) OR ('U'." ' TYPE # '= 2 AND 'U'. "SPARE2" = TO_NUMBER (SYS_CONTEXT ('userenv ',' current_e)) "
dition_id'))) or IS NOT NULL) AND IS NOT NULL)))
3 - access("O".") SPARE3 '=' U '. ("" USER # ")
4 - access("O".") "OWNER # '=' U '. ("" USER # ")
8 - access("O".") ' OBJ # '=' V '. (' ' OBJ # ")
12 filter (("TYPE #" =: B1 ET "UE".)) "THE USER #" =:B2))
14 - access("U2".") TYPE # "= 2, AND"U2"." SPARE2 "= TO_NUMBER (SYS_CONTEXT ('userenv ',' current_editi))"
on_id')))
filter (("U2". "TYPE #"= 2, AND "U2"."" SPARE2 "= TO_NUMBER (SYS_CONTEXT ('userenv ',' current_edit))"
ion_id')))
15 - access("O2".") DATAOBJ #"=: B1 AND 'O2'." ' TYPE # '= 88 AND 'O2'. "OWNER #"= "U2". ("" USER # ")
16 filter ((' EU'. "TYPE #" =: B1 AND 'EU '. "THE USER #" =:B2))
47 selected lines.
C##SA@pdborcl 10.09.2013 > select * from table (dbms_xplan.display_cursor ('bc4f1jh1snwdp'));
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------------
SQL_ID, bc4f1jh1snwdp, number of children 0
-------------------------------------
SELECT THE OWNER, DBA_VIEWS NOM_DE_VUE
Hash value of plan: 1508506130
--------------------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Pstart. Pstop |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 1 (100) | | |
| 1. PARTITION LIST ALL | | 10000 | 1289K | 0 (0) | 1. 2.
| 2. TABLE FIXED FULL | X$ COMVW$ 5885ef62 | 10000 | 1289K | 0 (0) | | |
--------------------------------------------------------------------------------------------
14 selected lines.
You have an idea about this result?
Thank you in advance,
Arnaud.
Arnaud,
This has a fairly simple explanation.
In 12cR1, there are common objects, and there are local objects. The definition of a common object is stored in the ROOT, and only a stub for the object is stored in the PDB. The definition of a local object is stored in the PDB.
When DBA_VIEWS is questioned in a PDB file, so we must return to lines of views both as common as the result of the query. If views Commons are not returned, then several views that a client is used to see in the result of a query DBA_VIEWS to 11.2 and earlier versions not will be seen in paragraph 12.1. For example, ALL_TABLES, DBA_OBJECTS, etc.
When DBA_VIEWS is questioned in a PDB file, then we extraction of lines for local opinions of PDB and common views of ROOT lines. The first has value ORIGIN_CON_ID equal to the ID of the container of the PDB to which you are connected, and they value ORIGIN_CON_ID equal to the ID of the ROOT container. Given that the recovery of these lines should be done in two different containers, we go through a fixed table X$ COMVW$ *.
The gap that you are experiencing is because this fixed table based assessment is used only to SELECT and not for etc. SELECT, INSERT AS SELECT, CREATE TABLE AS.
Let me know if that makes sense.
Thank you
Thomas
-
waveform, with an average of results using labview to O-scope
Hello fellow engineers! I'm a first-yeargraduatestudent in CHEE at the University of Houston. Basically, I know nothing about labview. I am trying to program an application that looks like this - I collect a waveform of the signal of O-scope. This waveform does not change its characteristic shape. I need to find the wave form average of waveforms of N (100 for example). Thus, the slight changes (or noise) in the feature of form during the period mustbeaveraged out and I need to have a resultant waveform that represents the average waveform over a period. So, basically, I'm collecting the wave several times (for example 100) on a single period. The O-scope that I use now is Tektronix TDS 2024 B. It communicates with the computer via USB. The version of labview is 8.5. For now, I am able to communicate with the computer using our o-scope through labview. I already downloaded the driver of instruments of your Web site. It turns out that the program can give me only the average result I can get directly from o-scope manually. I need to have more say on average (100) using labview. I wrote a program that relies on the instrument driver that is downloaded on your website (for loop part is average, the waveform). The program that I modified and an instrument driver are attached. The program cannot be fully open, if the driver is not put in the right place in the labview (under lib inst.) When I run the program, the average waveform does not appear on the front panal and signal waveform file is not saved correctly. Is there someone can find where I did wrong and it develop for me? Because I barely know Labview, it will be even better if you can add an image or program that you have changed. I'm waiting for your creative ideas.
With the best regards,.
--
Weiye
-
DAQmxReadAnalogF64 gives unexpected results with 9239 of Ni - DAQmx
Hi all
I use a NI 9239 with a laser sensor, and I would like to acquire some pressure readings of the probe which measures the height. It works very well with Ni Max, but not in C + c++ / MFC app I am developing. I get something that looks like amplidied noise:
1 reading scale doesn't seem fair (pressure readings I get from range - 2E9 to 2E9)
2 changes in what the sensor is supposed to measure does not appear in my measurements at all, there is nothing other than the noise (as if I were acquires bad chain - this I double checked)
I would like to get the same result as in Ni Max, but may not know what wrong with my code (below).Thanks for your help,
Ben
DAQmx Configure Code
DAQmxErrChk (DAQmxCreateTask ("LaserReading", & taskHandle));
DAQmxErrChk (DAQmxCreateAIVoltageChan(taskHandle,"cDAQ1Mod1/ai0","",DAQmx_Val_Diff,-10,10,DAQmx_Val_Volts,));
DAQmxErrChk (DAQmxCfgSampClkTiming(taskHandle,,10000,DAQmx_Val_Rising,DAQmx_Val_FiniteSamps,5000));Starting code DAQmx
DAQmxErrChk (DAQmxStartTask (taskHandle));Reading DAQmx code
DAQmxErrChk (DAQmxReadAnalogF64(taskHandle,NUM,-1,DAQmx_Val_GroupByChannel,data,5000,&read,));TRACE sends the readings to the debug output
TRACE ('%d points\n acquis', read);
for (i = 0; i<5000;>
{
TRACE("%d\n",data[i]);
}DAQmxStopTask (taskHandle);
DAQmxClearTask (taskHandle);Found the answer to this problem, the problem was in the function TRACE which data acquired to the debugger output. %D %f for the float to TRACE("%f\n",data[i values changed]) - things are great now.
Thank you
Ben
-
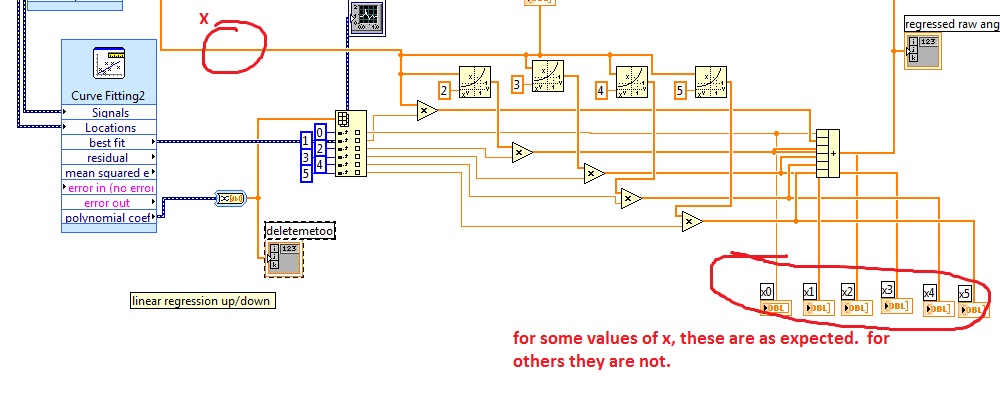
Multiplying by output of small polynomial coefficients on vi trendline and get unexpected results
I'd appreciate it if someone could shine any light on this problem for me.
I'm performing a polynomial regression with the VI express Curve Fitting. The express VI itself works very well. I used the polynomials it generates for the graph of a function in Excel and it looks perfect.
When I convert the signal to an array and then multiply by other values things start to go south.
The results of multiplications are wrong when some 'x' values are used. The strange thing for me, is that it does not work for all values of x.
Not sure if this is useful, but the expected values for x 0 through x 5 (bottom right, below) are:
x 0:-1,14
x 1: 16.11
x 2:6-3-19
x 3:-3.39E - 4
x 4: 6.76E - 7
X 5:-2.08e - 7
and the values displayed when the routine is running:
x 0:-1,14
x 1: 16.11
x 2: 25.57
x 3:-925.06
x 4: 104.25
x 5:-2017.87
Any ideas? I think a data type must be changed since the expected values are very small and the problem is only present for certain values of x.
If this is the case I don't know how to change the data type. The table contains double the conversion of the shape of the signal.
Thanks for any help,
Dave
Hi TCPlomp,
I just realized that I had x and is reversed in my entries "power x" function.
Thanks for letting me know about polynomial screws. Add those who should be more pleasant than to try to clean it.
Kind regards
Dave
-
How do Parameters.Result used as a reminder? How is it different from Parameters.Step.Result?
Hello
I searched reference manuals TestStand, help and the forums, and I have not yet found exactly how Parameters.Result should be used in callbacks (if at all).
I am trying to find a way to take a step that normally is not registered in the list of results and force it to appear on the rare occasions that it will fail. I think I should use the result, but I don't know how. If I set Parameters.Step.RecordResult = True, then the step attaches to record results, but which seems to be permanent in the sequence file, and AFTER THAT failure becomes declared.
Thank you for your expert help!
-Gizmogal
By browsing the SequenceFilePostResultListEntry I finally discern the difference between Parameters.Step.Result and Parameters.Result, which is visible at run time:
Parameters.Result has a TS container, which refers to the stage, giving information such as StepGroup, StepName, StepType, among others. Its results-oriented properties are identical to the Parameters.Step.Result properties, I can say.
Parameters.Step.Result has a container TS large type TEInf that seems to be the test information administration.
There seems little back than I expected, but that's it.
I'm partially through to shift my paradigm - save all the results and then throw those no interest. I ended up adding a status string 'RecordAlways' to force certain steps to record each time, and I throw any which are not equal to or 'Pass', 'Fail', 'Error' or 'done '. It works pretty well so far.
Thanks again for your help!
-Gizmogal

Maybe you are looking for
-
How can I remove my outgoing emails facebook picture?
The people I send emails to tell me that my Facebook photo is now attached to the email they receive.
-
My buttons 'Remove Cookie' and 'Remove all Cookies' do not work.
My 'Remove Cookie' button does not work. When I click on 'Remove all Cookies', it seems that it removes cookies, but when I click on "show Cookies... "the cookies back.
-
How to download a personal dvd for my mac?
How can I download a personal dvd on my mac?
-
Problem with connection for ePrint
HelloToday, I brought a new printer - all in one, HP Deskjet INK Advantage 3520. All functions are OK, but I have a problem with ePrint.In practice, the printer is connected to my wifi at home and I can print without USB cable with no problems. But w
-
Hard disk crash installed the new drive and reinstalled windows 7 64 bit it works but cannot receive all updates error code 800b0100. I've tried everything. Need all the help I can get.