unused cluster error
I have a new HP Pavilion 23 F250 touchsmart
When creating an image file it came with a
cluster, run error unused cluster found in the cluster, run the error code = 10 run chkdsk /f
don't know if I should call tech support or learn how to run a dos command window?
Larry
I set chkdsk to run at startup as an administrator and it took about 3 hours. OK, some on the forums said to
27% and stayed there so they got out of it.
He ran very well using Windows 8 Pro.
don't know how to cancel this post or the mark it solved.
Larry
Hi, sorry to hear that you are having problems with your Pavilion. I did some research and I found a Microsoft document that I think can help you. Please click on the link I provided.
If you have any other questions, please write back and I'll be more than happy to help you.
Thank you
Waterboy71
Tags: HP Desktops
Similar Questions
-
How to set the cluster error in postexpression?
Hello
I created a c language #-driver that returns a 0 for the pass or - 1 for failure in the functions 'int MyFunction().
Now I use this function for teststeps.
Question is: How can I use this returnvalue to set the cluster error?
So that one - 1 causes an error.
I think it can be done somehow in the post expression.
How can I put a
If (returnvalue == - 1).
{
Result.Error.Code = 10100
Result.Error.Msg = "an error has occurred."
Result.Error.Occured = True
}
Thanks for help
Hi OnlyOne,
Check out this example (stored in TS4.0)
The tower is done using a breakets conditional and literal.
Locals.nReturnValue is-1? {Step.Result.Error.Code = 10100, Step.Result.Error.Msg = "Error occurred", Step.Result.Error.Occurred = True}: {}
Concerning
Jürgen
-
Cannot use the references in Subvi cluster (error 1055, invalid references)
Hello
I'm going through a lot of that through a cluster to a Subvi.
The idea here is to manipulate objects in the MainVI in the nodes property thorugh Subvi, which gains the reference number of the cluster.
In the Subvi, I use unbunling by name to access the references I need. However, I get an error 1055 (invalid references) every time I try to access the object by using the node property.
What I am doing wrong?
Attached you will find three files:
The mainVI: Main.vi
The Subvi: Single_Cam_RefBased.vi
The def of the type for the cluster: RefClusterTypeDefinition.ctl
Thanks in advance,
Marcel
SteveChandler wrote:
The constant you have wired to the bundle is not the same as the cluster of type defined wired to your Subvi.
I was going to say the same thing. This should be the first thing to try. (I haven't studied the Subvi, but it seems buggy too...)
COMMENT: Again something is screwed in the current VI which makes no sense. Hovering above the terminal should tell us information about the corecion, but in this case it is said that the terminal is something like a cluster of error. This might just be a cosmetic bug...

-
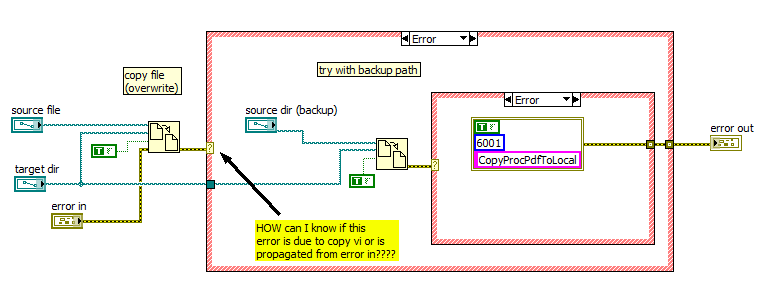
Spread for the Cluster error problem
Consider the following diagram:
This VI is intended to be used in a chain of the screws.
This VI copy a file to a folder and error, try it with a different path of the file (located in a location of "backup")
Because of the intrinsic data flow programming model, how to handle the error instead of the arrow?
The behavior I want is this:
If (error in == true)--> ignores everything and spreads from error_in to error_out
else {try copy and try with the backup error. If mistakes once again, then report the error (error code custom)}
Is this possible?
Thank you
Add an if-error-frame around all this. Then it is not started if a mistake happens first. Link the output of the copy of record for the cluster of error.
-
Warning of the managed servers in Cluster errors prevents complete startup script
Hi all
I've implemented a cluster oracle with two servers, one with Admin and Managed-1 and other accommodation managed 2, followed step by step guide EndecaServerInstall. However when I run the startManagedWeblogic the 'Running' State reached Server scripts but the script hangs at an infinite loop under the warning. On Weblogic Admin, I can see all the servers in a State of 'Running', but if I close the command prompt or trying to complete the script from the server stops. Any ideas on how to solve this problem?
WARNING: An instance of the interface oracle.wsm.policymanager.IUsageTracker bea
n for the local repository at the path "" was not available for the configuration of the orac
accessor repository le.wsm.policymanager.accessor.BeanAccessor for the context "Reso".
urcePattern [= DOMAIN/weblogic/Endeca_UAT pattern, subjectType = MANAGED_DOMAIN, ter
MS = {PLATFORM = weblogic, SUBJECT_TYPE = MANAGED_DOMAIN, Endeca_UAT = DOMAIN}]. "
INFO: Failure in the search component EJB. The EJB JNDI name is "DocumentManager #
oracle.wsm.policymanager.bean.ejb.IRemoteDocumentManager", is the URL of the provider.
NULL '...
Thank you
Just to confirm that this is the expected behavior of all. Namely:
You should keep open command line. In addition, should the infinite loop of alerts and warnings are printed to the console every 10 minutes of Weblogic. Consider this answered and please indicate the Forum tha this has answered, to help others who might encounter the same issue in the future.
Thank you
JM
-
Does anyone have the Windows trial version of PS CC 2014 unusable message error number?
Can someone help with this problem? TIA
I was counting on the use of the trial version until I got my subscription for Christmas, but is not be able to use the program at all worried.
After you download PS installation and start of trial, opening PS results in a pop-up window asking me if I want to import predefined settings from a previous version of PS. By clicking 'Yes', 'No' or are still waiting ends with the same result.
Within 5 seconds of the opening of PS, the Windows error message: Adobe Photoshop CC 2014 has stopped working / check online for a solution and close the program / close the program
whenever
I tried to open a photo directly from bridge and another from Lightroom. Photo opens, followed by a pop up window... same result
I have uninstalled and reinstalled PS CC and tried everything again; same result
I use Windows 7 sp1
And here are the details of the problem in the windows error message
Signature of the problem:
Problem event name: BEX64
Application name: Photoshop.exe
Application version: 15.2.2.310
Application timestamp: 5480338c
Fault Module name: amdocl64.dll
Fault Module Version: 2.4.650.9
Timestamp of Module error: 4e1153bb
Exception offset: 00000000003a6fec
Exception code: c0000417
Exception data: 0000000000000000
OS version: 6.1.7601.2.1.0.768.3
Locale ID: 1033
Additional information 1: c547
More information 2: c547d3e81c0e23a196200563a1d41f0f
Additional information 3: 200f
Additional information 4: 200f2557c177e8bb3ea53983e9aad8e2
As noted in the crash - your outdated video card driver crashes. You need to update your video card driver from the website of the manufacturer of the GPU (AMD/ATI in this case).
-
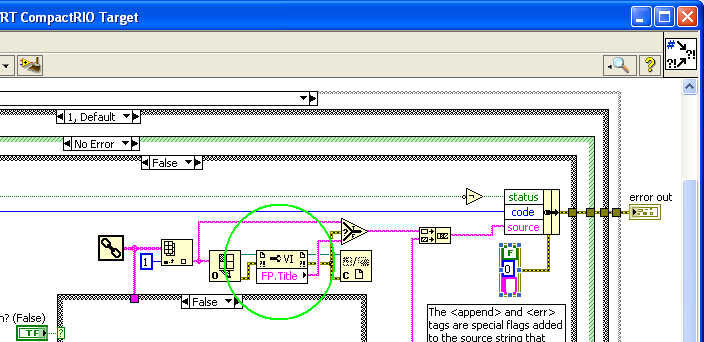
The 'cluster of error code.vi error' is available to be included in an application of the RT, but it contains a 'FP. Node Title property"VI and a RT application contains all of the panels before, except when running in debug mode. This vi.lib VI will work properly in an application of the RT running on a cRIO?
The Cluster error error Code VI works fine on the objectives of the RT, but the behavior is slightly different when the appellant VI has a front title which differs by its qualified name. Note that there is a selection function that checks the mistakes coming out of the public Service. Node title. If there is no title of façade, then simply will use name of the VI instead, so this VI certainly works on RT.
Keep in mind that opening a VI reference and a property of reading is relatively a lot of time, so there is a significant performance impact when you call this VI on RT. This attention to performance has been reported to R & D in 384767 car, but it can usually be avoided by ensuring to call only this VI when there is an error that must be reported to the user.
Chris M
-
Hi all, when I try to update some columns that don't have the data I receive ORA-02000: lack of UNUSED keyword error. Can someone explain to me how to overcome this error?
Any help is appreciated,1 alter table regal.regal_cust_allowance_det_tab 2 set percentage = 0.2, 3 range_type = 'Goods', 4 range_from = 1000, 5 range_to = 5000 6* where CUSTOMER_NUMBER = 1020 7 / set percentage = 0.2, * ERROR at line 2: ORA-02000: missing UNUSED keyword
Thanks in advance!Hello
Need the UPDATE statement. How is it, you update the values of the columns using ALTER table statemennt? Serious error
-
Injection of error in error of type entry / exit system
Hi I'm just starting in Labview and to this day, I've been joining void screws with Out error connecting to error in the next sub VI so I can capture errors at the end of the line of screws that are up of my program.
It occurs to me that sometimes there are errors that occur that are not lifted by the system, but rather the dice indicate, for example, during a test product, when a test parameter is not a valid range. I wonder how to convert say a Boolean value for test pass / fail, an error with a message, that I can put in my path of the error. -What is in general?
Some setting in context, I want to be able to test the two devices manufactured in a single sequence. If we fail a test sup, say a voltage is out of range, I want to inject than as a mistake and blow it at the end of this trial where he would be treated, and perhaps a group of experts on the GUI shows then in case of FAILURE or something similar. But enforcement should then immediately move on to the second device and start this test, without waiting for an acknowledgement so that when the tester returns, both have been tested and can determine what to do with them, according to the State of SUCCESS or FAILURE.
I guess I asked how to remove a custom error and caught him? I've read a few articles about the error handling which doesn't really answer my question. Thanks for the tips!
You can use the package by name to create the cluster error yourself with a Boolean value of True for the error (false is a warning), a number (0 for no error, a positive number of alert, negative number for an error) and a string for a message.
If you must use the cluster of error in this way is a different matter. I would recommend against it. I consider the cluster of the error to be there for clerical errors and program errors. Basically if your program runs correctly and that you have no hardware problems, and then a mistake should never appear on the cluster of error. For the case where you are dealing with outages of a unit under test, pass/fail results, I consider that it is a normal part of the program, and that the data should be treated separately as part of your test data and not forced in the cluster of error data. Check the condition of the success/failure of data to determine whether to execute all Subvi who should or should not run because a previous test failed.
-
error code message appears not
Hello
I tried to create a set of labview error codes codes using the tools-> edition of error codes. Has created some test errors and saved the file
C:\Program NIUninstaller Instruments\LabVIEW 2009\user.lib\errors
The file called test - errors.txt appears as follows:
First file of Sean error code
Unstable device
Unstable critical apparatus
Press Stop or device will begin the countdown to destruction
Destruction began the countdown, all organic life will be destroyed with a radius of 2 miles in t - 10 minutes


 Then, I designed a simple VI to test the error codes, see the attachment. However, the error message do not appear in the error on the source area.
Then, I designed a simple VI to test the error codes, see the attachment. However, the error message do not appear in the error on the source area.Does anyone know why LabVIEW is not recognizing my error codes?
Rgds,
Sean
David,
The data cluster error type may not contain the actual description of an error. When an error is generated, only the cluster of error data will be the error code, status and source. The source must contain the path calling of the VI that generated the error, not the description of the error. It is recommended to use the VI Simple or General Error Handler to programmatically display the short description of the error. If you want to interactively view the description you can right-click on a cluster of error control or indicator and select 'explain the error.
Chris M
-
Fix the system keeps poping up and then I get a system error. How to buy that?
It seems that when we returned from vacation our computer has downloaded something that took over the computer. The screen is black and it keeps giving a message that there is a system, damage of cluster error and if a search through their program of $79.00 it will fix. No idea how to remove? I tried to do a system restor, but it won't let me. Most of my info Office has gone... Tried to boot in safe mode and that didn't work either.
Any help would be great!
Thank you again...
Hi EdSchillig,
Are you able to boot to the desktop?
If you able to boot to the desktop, follow these steps: check to see if it helps
(a) I recommend you run a virus scan online from the link given below and check if the problem persists:
Also, make sure that you have the latest update of the software antivirus installed on your computer, so that it works correctly.
(b) you can also download & run Microsoft Security Essentials on your computer.
Reference: beware of fake virus alertsHope the helps of information.
-
Is it normal to find errors when running Check Disk manually with Vista?
For some time my computer would not start without automatically run the disk check. It now starts and works well, but Check Disk find errors every time I have manually run the disk check. Is it normal to find some cluster errors when you run Check Disk? It runs today, he finds and replaced two bad clusters. Two is not much, but I ran as a few days ago. Thanks for any information, that everyone has.
It would be wise now to test the hard drive. Test the hard drive with a diagnostic utility downloaded from site of the disc mftr. or use SeaTools for BACK of Seagate. You create a bootable CD with the files you download. You will need a third party burning software to do as the free ImgBurn, Nero or Roxio. Burn as an image, not in the form of data.
http://www.Seagate.com/www/en-us/support/downloads/SeaTools/seatooldreg
http://Seagate.custkb.com/Seagate/CRM/selfservice/search.jsp?docid=201271 (how-to)Boot with the CD that you have done and do a full test of the reader. The physical tests fail, replace it. MS - MVP - Elephant Boy computers - don't panic!
-
I get error CLR20r3 when I work in a program.
original title: CLR20r3 errorHello
I had used this program well, but after a few days unused this error and I don't know how to solve this problem, I thought it was due to the net framework but I worked so I could help, I would be happyProblem event name: CLR20r3
Signature of the problem 01: megui.exe
Signature of the problem 02: 0.3.5.0
Signature of the problem 03: 4c1e0f5b
Signature of the problem 04: mscorlib
Signature of the problem 05: 2.0.0.0
Signature of the 06 problem: 4ef6c7cc
Signature of the problem 07: f50
Signature problem 08:7
Signature of the problem 09: N3CTRYE2KN3C34SGL4ZQYRBFTE4M13NB
OS version: 6.1.7601.2.1.0.256.1
Locale ID: 3082Hello
1 are. what program you referring?
2 did you change on your computer?
3. when exactly you receive this error message?
I also suggest you perform the clean boot and check.
How to troubleshoot a problem by performing a clean boot in Windows Vista or in Windows 7
http://support.Microsoft.com/kb/929135
Note: After troubleshooting, make sure the computer to start as usual as mentioned in step 7 in the above article.
-
vCAC 5.2: Service Manager of treatment response data collection error
Hello
I have a problem with the 5.2 vCAC. Currently, each data collection on vCenter failed (inventory, State, performance, POSSIBLE). I have a multiple as error:
DC: 1eaa57d7 - 33d 7-41 c 4-ab5b-05adc6b46d4f: inventory: vcenter LAB: LAB-Cluster: error response treatment data collection, StatusID = 959cacac-d8bc - 44d 8-9718-fab88b75fc7c, exception: object reference not set to an instance of an object.
In the machines of the group, some VM have State "missing." This is because users are asking for virtual machines on the vCACSelfService portal, then the startup process or approval of provisioning and vCAC service crash (because less than 5 percent of free memory). Some virtual machines are not complete provisionned years are another State 'pending approval '.
So I think that I have to clean my database? , but how? What table?
Any help will be much appreciated.
EDIT: To clean up the application, I have bleed the lines on DataCollectionStatusID = > OK
But always KO for the collection (vCenter and VCloud) examples:
Workflow "vCloudDisposeVM" failed with the following exception:
System.InvalidOperationException: Could not find the virtual machine with the id: 04c1e280-391a-4e9e-99a7-34e0a5c2947f
DC: 8b60dd14 - 09b 5 - 40 c 2-9fb4-83d2da34014f: inventory: vcenter LAB: LAB-Cluster: error response treatment data collection, StatusID = 20783c 93-3d2d-4efe-af71-9d92346699ce, exception: object reference not set to an instance of an object.
This message was edited by: trailx
Problem solved.
On vCenter, the problem was with the element 'successful' in dbo.virtualmachine. I have modified the status missing information and managed = OK
About vCloud, the problem was the network on the orgVdc, I deleted all and created a very simple again (external direct) => OK
-
Installation problem of local cluster of consistency with the WKA (well-known-address)
Hello - I started using WKA local consistency with single node cluster, but when I launch CacheFactory (coherence.cmd) with the same configuration, he throws after error message.
Any help is appricicated.
Startup JVM Arrgument
-Dtangosol.coherence.override =cluster.xml
cluster. XML
<? XML version = "1.0" encoding = "UTF-8"? >
" < consistency xmlns =" http://xmlns.Oracle.com/coherence/coherence-operational-config "" xmlns: xsi = " http://www.w3.org/2001/XMLSchema-instance " xsi: schemaLocation = " http://xmlns.Oracle.com/Coherence/Coherence-Operational-config http://xmlns.oracle.com/coherence/coherence-operational-config/1.1/coherence-operational-config.xsd" > ""
<>cluster-config
unicast-listener <>
< well-known-address >
< code socket-address = "1" >
< address >171.193.103.25< / address >
< port >8088< / port >
< / socket-address >
< / well-known-address >
< / unicast earphone >
< / cluster-config >
<>logging-config
stdout < destination > < / destination >
> < 9 severity level < / severity level >
< / operational forest-config >
< / coherence >
Cluster Message startup
WellKnownAddressList (size = 1,
WKA {address = 171.193.103.25, Port = 8088}
)() MasterMemberSet
ThisMember = member (Id = 1, Timestamp is 2013-10-24 11:07:18.603, address = 171.193.103.25:8088, MachineId = 9041, location = site:, machine: FD4C9EF534D5D, process: 16704, role = CoherenceServer)
OldestMember = member (Id = 1, Timestamp is 2013-10-24 11:07:18.603, address = 171.193.103.25:8088, MachineId = 9041, location = site:, machine: FD4C9EF534D5D, process: 16704, role = CoherenceServer)
ActualMemberSet = MemberSet (Size = 1
Member (Id = 1, Timestamp is 2013-10-24 11:07:18.603, address = 171.193.103.25:8088, MachineId = 9041, location = site:, machine: FD4C9EF534D5D, process: 16704, role = CoherenceServer)
)
Member ID | ServiceVersion | ServiceJoined | Member State
1. 3.7.1. 11:07:48.843 2013-10-24 | JOINING
RecycleMillis = 1200000
RecycleSet = MemberSet (Size = 0
)
)TcpRing {connection = []}
IpMonitor {AddressListSize = 0}2013-10-24 11:07:48.869/31.794 Oracle coherence GE 3.7.1.0 < D5 > (thread = Invocation: management, Member = 1): service management joined the cluster with the senior members of the service 1
2013-10-24 11:07:49.058/31.983 Oracle coherence GE 3.7.1.0 < D5 > (thread = DistributedCache, Member = 1): Service DistributedCache joined the cluster with the senior members of the service 1
2013-10-24 11:07:49.077/32.002 Oracle coherence GE 3.7.1.0 < D6 > (thread = DistributedCache, Member = 1): Service DistributedCache: PartitionConfig ConfigSync sending at all
2013-10-24 11:07:49.121/32.046 Oracle coherence GE 3.7.1.0 < D5 > (thread = ReplicatedCache, Member = 1): Service ReplicatedCache joined the cluster with the senior members of the service 1
2013-10-24 11:07:49.128/32.053 Oracle coherence GE 3.7.1.0 < D5 > (thread = OptimisticCache, Member = 1): Service OptimisticCache joined the cluster with the senior members of the service 1
2013-10-24 11:07:49.131/32.056 Oracle coherence GE 3.7.1.0 < D5 > (thread = Invocation: InvocationService, Member = 1): Service InvocationService joined the cluster with the senior members of the service 1
2013-10-24 11:07:49.132/32.057 Oracle coherence GE 3.7.1.0 < Info > (thread = main, Member = 1):
Services
(
ClusterService {name = Cluster, status = (SERVICE_STARTED, STATE_JOINED), Id = 0, Version = 3.7.1 OldestMemberId = 1}
InvocationService {name = management, State (SERVICE_STARTED), Id = 1, Version 3.1 = =, OldestMemberId = 1}
PartitionedCache {Name = DistributedCache State = (SERVICE_STARTED), LocalStorage = active, PartitionCount = 257, BackupCount = 1, AssignedPartitions = 257, BackupPartitions = 0}
ReplicatedCache {Name = ReplicatedCache, State = (SERVICE_STARTED), Id = 3, Version = 3.0, OldestMemberId = 1}
Optimistic {Name = OptimisticCache, State = (SERVICE_STARTED), Id = 4, Version 3.0, OldestMemberId = 1}
InvocationService {Name = InvocationService, State = (SERVICE_STARTED), Id = 5, Version = 3.1, OldestMemberId = 1}
)DefaultCacheServer started...
CacheFactory error message
C:\Users\Zk5rjg8 > C:\coherence37\bin\coherence.cmd
* From storage off the console *.
Java version "1.6.0_51".
Java (TM) SE Runtime Environment (build 1.6.0_51 - b11)
Java for 64-bit Server VM (build 20, 51 - b01, mixed mode)2013-10-24 11:13:22.851/0.392 Oracle coherence 3.7.1.0 < Info > (thread = main Member, = n/a): responsible operational configuration of "jar:file:/C:/coherence37/lib/coherence.jar!/tangosol-coherence.xml".
2013-10-24 11:13:22.920/0.462 Oracle coherence 3.7.1.0 < Info > (thread = main Member, = n/a): responsible for operational substitutions of "file:/C:/coherence37/cluster.xml".
2013-10-24 11:13:22.924/0.465 Oracle coherence 3.7.1.0 < D5 > (thread = main Member, = n/a): configuration optional override "/ custom - mbeans.xml ' is not specified
2013-10-24 11:13:22.924/0.465 Oracle coherence 3.7.1.0 < D6 > (thread = main Member, = n/a): loaded data edition of "jar:file:/C:/coherence37/lib/coherence.jar!/coherence-grid.xml".Oracle Version 3.7.1.0 Build 27797 consistency
Grid edition: development Mode
Copyright (c) 2000, 2011, Oracle and/or its affiliates. All rights reserved.2013-10-24 11:13:23.722/1.263 Oracle coherence GE 3.7.1.0 < D4 > (thread = main Member, = n/a): TCMP linked to /171.193.103.25:8090 using SystemSocketProvider
2013-10-24 11:13:54.001/31.542 Oracle coherence GE 3.7.1.0 < WARNING > (thread = Cluster, Member = n/a): this Member(Id=0, Timestamp=2013-10-24 11:13:23.762, Address=171.193.103.25:8090, MachineId=9041, Location=site:,machine:FD4C9EF534D5D,process:17192, Role=CoherenceConsole) tried to joi
2013-10-24 11:13:54.001/31.542 Oracle coherence GE 3.7.1.0 < WARNING > (thread = Cluster, Member = n/a): delay the formation of a new cluster. waiting for well known address nodes
2013-10-24 11:14:24.402/61.943 Oracle coherence GE 3.7.1.0 < WARNING > (thread = Cluster, Member = n/a): delay the formation of a new cluster. waiting for well known address nodes
2013-10-24 11:14:54.805/92.346 Oracle coherence GE 3.7.1.0 < WARNING > (thread = Cluster, Member = n/a): delay the formation of a new cluster. waiting for well known address nodes
2013-10-24 11:15:25.207/122.748 Oracle coherence GE 3.7.1.0 < WARNING > (thread = Cluster, Member = n/a): delay the formation of a new cluster. waiting for well known address nodes
2013-10-24 11:15:55.610/153.151 Oracle coherence GE 3.7.1.0 < WARNING > (thread = Cluster, Member = n/a): delay the formation of a new cluster. waiting for well known address nodes
2013-10-24 11:16:26.012/183.553 Oracle coherence GE 3.7.1.0 < WARNING > (thread = Cluster, Member = n/a): delay the formation of a new cluster. waiting for well known address nodes
2013-10-24 11:16:56.414/213.955 Oracle coherence GE 3.7.1.0 < WARNING > (thread = Cluster, Member = n/a): delay the formation of a new cluster. waiting for well known address nodes
2013-10-24 11:17:26.817/244.358 Oracle coherence GE 3.7.1.0 < WARNING > (thread = Cluster, Member = n/a): delay the formation of a new cluster. waiting for well known address nodes
2013-10-24 11:17:57.219/274.760 Oracle coherence GE 3.7.1.0 < WARNING > (thread = Cluster, Member = n/a): delay the formation of a new cluster. waiting for well known address nodes
2013-10-24 11:17:58.271/275.812 Oracle coherence GE 3.7.1.0 < error > (thread = Cluster, Member = n/a): detected soft timeout) of {WrapperGuardable {Daemon = IpMonitor} Guard Service = ClusterService {name = Cluster, status = (SERVICE_STARTED, STATE_ANNOUNCE), Id = 0, Version = 3.7.1}}
2013-10-24 11:17:58.273/275.814 Oracle coherence GE 3.7.1.0 < error > (thread = thread of recovery, Member = n/a): Full Thread DumpThread [PacketListener1, 8, Cluster]
java.net.PlainDatagramSocketImpl.receive0 (Native Method)
java.net.PlainDatagramSocketImpl.receive (unknown Source)
java.net.DatagramSocket.receive (unknown Source)
com.tangosol.coherence.component.net.socket.UdpSocket.receive(UdpSocket.CDB:22)
com.tangosol.coherence.component.net.UdpPacket.receive(UdpPacket.CDB:1)
com.tangosol.coherence.component.util.daemon.queueProcessor.packetProcessor.PacketListener.onNotify(PacketListener.CDB:20)
com.tangosol.coherence.component.util.Daemon.run(Daemon.CDB:42)
java.lang.Thread.run (unknown Source)Thread [PacketReceiver, 7, Cluster]
java.lang.Object.wait (Native Method)
com.tangosol.coherence.component.util.Daemon.onWait(Daemon.CDB:18)
com.tangosol.coherence.component.util.daemon.queueProcessor.packetProcessor.PacketReceiver.onWait(PacketReceiver.CDB:2)
com.tangosol.coherence.component.util.Daemon.run(Daemon.CDB:39)
java.lang.Thread.run (unknown Source)Thread [attach auditor, 5, System]
Thread [PacketPublisher, 6, Cluster]
java.lang.Object.wait (Native Method)
com.tangosol.coherence.component.util.Daemon.onWait(Daemon.CDB:18)
com.tangosol.coherence.component.util.daemon.queueProcessor.packetProcessor.PacketPublisher.onWait(PacketPublisher.CDB:2)
com.tangosol.coherence.component.util.Daemon.run(Daemon.CDB:39)
java.lang.Thread.run (unknown Source)Thread [Cluster |] STATE_ANNOUNCE | [Member (Id = 0, Timestamp is 2013-10-24 11:13:23.762, address = 171.193.103.25:8090, MachineId = 9041, location = site:, machine: FD4C9EF534D5D, process: 17192, role = CoherenceConsole), 5, Cluster]
sun.nio.ch.WindowsSelectorImpl$ SubSelector.poll0 (Native Method)
sun.nio.ch.WindowsSelectorImpl$ SubSelector.poll (unknown Source)
sun.nio.ch.WindowsSelectorImpl$ SubSelector.access$ 400 (unknown Source)
sun.nio.ch.WindowsSelectorImpl.doSelect (unknown Source)
sun.nio.ch.SelectorImpl.lockAndDoSelect (unknown Source)
sun.nio.ch.SelectorImpl.select (unknown Source)
com.tangosol.coherence.component.net.TcpRing.select(TcpRing.CDB:11)
com.tangosol.coherence.component.util.daemon.queueProcessor.service.grid.ClusterService.onWait(ClusterService.CDB:6)
com.tangosol.coherence.component.util.Daemon.run(Daemon.CDB:39)
java.lang.Thread.run (unknown Source)Thread [reference Manager 10, System]
java.lang.Object.wait (Native Method)
java.lang.Object.wait(Object.java:485)
java.lang.ref.Reference$ ReferenceHandler.run (unknown Source)Thread [finalizer, 8, System]
java.lang.Object.wait (Native Method)
java.lang.ref.ReferenceQueue.remove (unknown Source)
java.lang.ref.ReferenceQueue.remove (unknown Source)
java.lang.ref.Finalizer$ FinalizerThread.run (unknown Source)Thread [dispatcher Signal, 9, System]
Thread [PacketSpeaker, 8, Cluster]
java.lang.Object.wait (Native Method)
com.tangosol.coherence.component.util.queue.ConcurrentQueue.waitForEntry(ConcurrentQueue.CDB:16)
com.tangosol.coherence.component.util.queue.ConcurrentQueue.remove(ConcurrentQueue.CDB:7)
com.tangosol.coherence.component.util.Queue.remove(Queue.CDB:1)
com.tangosol.coherence.component.util.daemon.queueProcessor.packetProcessor.PacketSpeaker.onNotify(PacketSpeaker.CDB:21)
com.tangosol.coherence.component.util.Daemon.run(Daemon.CDB:42)
java.lang.Thread.run (unknown Source)Thread[logger@1457155060 3.7.1.0,3,main]
java.lang.Object.wait (Native Method)
com.tangosol.coherence.component.util.Daemon.onWait(Daemon.CDB:18)
com.tangosol.coherence.component.util.Daemon.run(Daemon.CDB:39)
java.lang.Thread.run (unknown Source)Thread [PacketListener1P, 8, Cluster]
java.net.PlainDatagramSocketImpl.receive0 (Native Method)
java.net.PlainDatagramSocketImpl.receive (unknown Source)
java.net.DatagramSocket.receive (unknown Source)
com.tangosol.coherence.component.net.socket.UdpSocket.receive(UdpSocket.CDB:22)
com.tangosol.coherence.component.net.UdpPacket.receive(UdpPacket.CDB:1)
com.tangosol.coherence.component.util.daemon.queueProcessor.packetProcessor.PacketListener.onNotify(PacketListener.CDB:20)
com.tangosol.coherence.component.util.Daemon.run(Daemon.CDB:42)
java.lang.Thread.run (unknown Source)Thread [main, 5, main]
java.lang.Object.wait (Native Method)
com.tangosol.coherence.component.util.daemon.queueProcessor.Service.start(Service.CDB:18)
com.tangosol.coherence.component.util.daemon.queueProcessor.service.Grid.start(Grid.CDB:6)
com.tangosol.coherence.component.net.Cluster.onStart(Cluster.CDB:56)
com.tangosol.coherence.component.net.Cluster.start(Cluster.CDB:11)
com.tangosol.coherence.component.util.SafeCluster.startCluster(SafeCluster.CDB:3)
com.tangosol.coherence.component.util.SafeCluster.restartCluster(SafeCluster.CDB:10)
com.tangosol.coherence.component.util.SafeCluster.ensureRunningCluster(SafeCluster.CDB:26)
com.tangosol.coherence.component.util.SafeCluster.start(SafeCluster.CDB:2)
com.tangosol.net.CacheFactory.ensureCluster(CacheFactory.java:427)
com.tangosol.coherence.component.application.console.Coherence.run(Coherence.CDB:25)
com.tangosol.coherence.component.application.console.Coherence.main(Coherence.CDB:3)
sun.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
sun.reflect.NativeMethodAccessorImpl.invoke (unknown Source)
sun.reflect.DelegatingMethodAccessorImpl.invoke (unknown Source)
java.lang.reflect.Method.invoke (unknown Source)
com.tangosol.net.CacheFactory.main(CacheFactory.java:827)Thread [recovery Thread, 5, Cluster]
java.lang.Thread.dumpThreads (Native Method)
java.lang.Thread.getAllStackTraces (unknown Source)
com.tangosol.net.GuardSupport.logStackTraces(GuardSupport.java:810)
com.tangosol.internal.net.cluster.DefaultServiceFailurePolicy.onGuardableRecovery(DefaultServiceFailurePolicy.java:44)
com.tangosol.coherence.component.util.daemon.queueProcessor.service.Grid$ WrapperGuardable.recover (Grid.CDB:1)
com.tangosol.net.GuardSupport$ Context$ 1.run(GuardSupport.java:653)
java.lang.Thread.run (unknown Source)2013-10-24 11:17:58.273/275.814 Oracle coherence GE 3.7.1.0 < WARNING > (thread = thread of recovery, Member = n/a): attempt to retrieve custody {Daemon = IpMonitor}
Exception in thread 'hand' 2013-10-24 11:18:24.025/301.566 Oracle coherence GE 3.7.1.0 < error > (thread = main Member, = n/a): Start cluster error: com.tangosol.net.RequestTimeoutException: timeout during the startup of the service: ServiceInfo (Id = 0, name is Cluster, Type = Cluster
Set of members = MasterMemberSet)
ThisMember = null
OldestMember = null
ActualMemberSet = MemberSet (Size = 0
)
Member ID | ServiceVersion | ServiceJoined | Member State
RecycleMillis = 1200000
RecycleSet = MemberSet (Size = 0
)
)
)
at com.tangosol.coherence.component.util.daemon.queueProcessor.service.Grid.onStartupTimeout(Grid.CDB:3)
at com.tangosol.coherence.component.util.daemon.queueProcessor.Service.start(Service.CDB:28)
at com.tangosol.coherence.component.util.daemon.queueProcessor.service.Grid.start(Grid.CDB:6)
at com.tangosol.coherence.component.net.Cluster.onStart(Cluster.CDB:56)
at com.tangosol.coherence.component.net.Cluster.start(Cluster.CDB:11)
at com.tangosol.coherence.component.util.SafeCluster.startCluster(SafeCluster.CDB:3)
at com.tangosol.coherence.component.util.SafeCluster.restartCluster(SafeCluster.CDB:10)
at com.tangosol.coherence.component.util.SafeCluster.ensureRunningCluster(SafeCluster.CDB:26)
at com.tangosol.coherence.component.util.SafeCluster.start(SafeCluster.CDB:2)
at com.tangosol.net.CacheFactory.ensureCluster(CacheFactory.java:427)
at com.tangosol.coherence.component.application.console.Coherence.run(Coherence.CDB:25)
at com.tangosol.coherence.component.application.console.Coherence.main(Coherence.CDB:3)
at sun.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke (unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke (unknown Source)
at java.lang.reflect.Method.invoke (unknown Source)
at com.tangosol.net.CacheFactory.main(CacheFactory.java:827)
java.lang.reflect.InvocationTargetException2013-10-24 11:18:24.025/301.566 Oracle coherence GE 3.7.1.0 < D5 > (thread = Cluster, Member = n/a): Service de Cluster left the cluster at sun.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke (unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke (unknown Source)
at java.lang.reflect.Method.invoke (unknown Source)
at com.tangosol.net.CacheFactory.main(CacheFactory.java:827)
Caused by: com.tangosol.net.RequestTimeoutException: timeout during the startup of the service: ServiceInfo (Id = 0, name is Cluster, Type = Cluster
Set of members = MasterMemberSet)
ThisMember = null
OldestMember = null
ActualMemberSet = MemberSet (Size = 0
)
Member ID | ServiceVersion | ServiceJoined | Member State
RecycleMillis = 1200000
RecycleSet = MemberSet (Size = 0
)
)
)
at com.tangosol.coherence.component.util.daemon.queueProcessor.service.Grid.onStartupTimeout(Grid.CDB:3)
at com.tangosol.coherence.component.util.daemon.queueProcessor.Service.start(Service.CDB:28)
at com.tangosol.coherence.component.util.daemon.queueProcessor.service.Grid.start(Grid.CDB:6)
at com.tangosol.coherence.component.net.Cluster.onStart(Cluster.CDB:56)
at com.tangosol.coherence.component.net.Cluster.start(Cluster.CDB:11)
at com.tangosol.coherence.component.util.SafeCluster.startCluster(SafeCluster.CDB:3)
at com.tangosol.coherence.component.util.SafeCluster.restartCluster(SafeCluster.CDB:10)
at com.tangosol.coherence.component.util.SafeCluster.ensureRunningCluster(SafeCluster.CDB:26)
at com.tangosol.coherence.component.util.SafeCluster.start(SafeCluster.CDB:2)
at com.tangosol.net.CacheFactory.ensureCluster(CacheFactory.java:427)
at com.tangosol.coherence.component.application.console.Coherence.run(Coherence.CDB:25)
at com.tangosol.coherence.component.application.console.Coherence.main(Coherence.CDB:3)
... 5 moreC:\Users\Zk5rjg8 >
Hi SajeevPynadath
1
First start the server process with "cache - server.cmd".
2
After that, you can start another process of client or server, the 'coherence.cmd' script is to start a client process to join the cluster.
3
So now you have 2 processes, and your cluster.xml will look like this:
171.193.103.258088
171.193.103.258089 4
Before you begin each remember process java command line:
for server
-Dtangosol.coherence.localhost =171.193.103.25 - Dtangosol.coherence.localport = 8088
for the customer
-Dtangosol.coherence.localhost =171.193.103.25 - Dtangosol.coherence.localport = 8089
Kind regards
Leo_TA
Maybe you are looking for
-
Try to perform the update on our iPhone 5s 9.3; Continue to receive error failure to perform the update because I am not connected to the internet. Wifi is in place and I am connected to wifi said. What I am doing wrong
-
Satellite A110-293 - sound without a bass
Hello A I have a problem with Realtek High Definition Audio (SRS). The sound is metallic without bass and after install the drivers latest from Toshiba Web site in the Control Panel, it is not Realtek HD Audio Manager. I upgraded the BIOS to 5.10, th
-
want 4 beats audio control pannel
Hi all. I have a HP Envy 4-1010ea. I replaced the 32 GB MSATA with a 120 GB MSATA and did a fresh install of Windows 7 Home Premium x 64 Done all updates and installed all the best drivers. Now here's the question and read in forums for 2 days to fix
-
Cannot send e-mail in Outlook Express. Message "could not open the message from the Outbox folder. Account email Sympatico Server SMTPHM.sympatico.ca Protocol SMTP Port 25 secure (SSL) Yes, error number0x800420C8 original title: 0x800420C8 error NUMB
-
My wife is running Vista Home Edition on his laptop HP 3 year, and she can't connect to his user account. Once the password is typed in, it becomes just a black screen, with the spinning cursor wheel - forever. It can connect to my user account on