using elements of the table in the order?
Hello
I created a table which includes four-part numbers. I want to stimulate each element one after the other. After the creation of my program, I see that only the first element of the array is enabled, but not the other RAS.
I actually use this program to stimulate the four different smells. I join all of the program that controls the olfactometer and the framework of this program that I have problems with.
If any of you have any idea how I can solve the problem and can use all different smells/elements during the experience?
Sincerely,
Samia Alam.
You have a double case of 'localitite' and 'sequencetitus '. No need to use local variables and structures of the sequence.
Use wire instead of local variables where you can. If wire you your table type of Stimulation through the wall of the loop, you can set it for automatic indexing. This means that each loop iteration will use each element of the array in turn. Then you won't need the Index array function, or need to wire a 4-Terminal N of the loop.
(Otherwise, we could plug your i of iteration loop Terminal to the terminal of the index of the Array Index function.)
Tags: NI Software
Similar Questions
-
Hello out there! I am trying to understand the relationship between the products. I am a current user of 13 items and sought to CC Photoshop with Lightroom. Always use elements like the storage tool to catalog my photos or it get replaced?
It's kind of ridiculous. All I want to do is ask a question and there is no place to connect with anyone. Sucks!
Hi charlesf,
If you choose to go to CC Photoshop with Lightroom, Photoshop Elements would not be replaced.
CC of Photoshop and Photoshop Elements are different programs, so the two will remain separate on your machine and catalogue items would not hit at all.
Let us know if you have any other questions.
Kind regards
Claes
-
How long it takes to start using Photoshop, once the order is placed. I need to make it work...
How long it takes to start using Photoshop, once the order is placed. I need to make it work...
Well, it's one and the same software, you need to worry about this.
It takes usually 24 to 48 hours for confirmation of payment.
And there is no difference between the use of the product of the tools and features, you still get the full software with all the features even in evaluation mode.
Concerning
Jitendra
-
Using elements in the field and the transfer of my computer at home?
I want to use my ultrabook with elements in the field in order to sort, shoot, and edit the images in time. When I go home can I just transfer these files from my computer at home and use Get Photos to add them to my main catalog? Tags, version sets and changes made in the field will survive, so that it would be the same if I had done this treatment on my computer at home in the first place?
Here is a more detailed workflow suggestion, assuming you want to do the bulk of your organization in the computer field.
It is based on the notes above and the use of a backup PSE to transfer photos and catalog of the field at home a computer.
-Create a new catalog on your computer in the domain before you download files.
-organize entirely unconstrained...
-Prepare a later import in your main catalog, after the backup and restore processes (details to come...) or wait until after the restoration to make this work.
-Backup to a disk external (there are beautiful portable USB drives in ideal for this)
-(Note: quand vous avez votre sauvegarde, il est sûr de re-formater vos cartes.)
-Restore from the external hard drive to your computer at home (custom destinatin). You will have a new catalogue with all your changes.
-If you did not already preparing indicated above, it is here. Select the files in the batteries and common as label "IsInAStack", and then select the version games and assign a label like "IsInAVersion". Now, you can also assign keywords to the components of cells. For albums, use the common keywords. If you need save the order in albums (for slideshows...) export and rename the files as explained above and reimport them in your catalog.
-Now you can re - import the files in your main catalog
-To re - create batteries select files with "IsInAStack" or their label and either stack manually or with the help of the feature automatically 'suggest piles. Sets of version can be restored only like batteries. Albums must be recreated: you drag the selection based on the keyword corresponding to the album.
-
MS Word footer ends the first element of the order when converting to PDF for reading content
Does anyone else have this problem? We have a model of large paper on department letterhead (MS Word 2010) with header and footer and converting to PDF using Acrobat Pro XI (v11.0.13.17), the walk ends by order at the top the reading list. In any case to stop this from happening?
Hi Matthew, when you are referring to the order of reading, looking in the content pane, pane hierarchy, or the component Tags - or maybe elsewhere? The Tags pane provides the reading order for the assistive technology (at). As general rule, repeating footers must be marked as background artifacts, so they will not appear in the Tags pane and will be ignored by AT. According to my experience, Word to PDF conversion sometimes does a better job than other times, but there is always a certain amount of manual fixes to get accessible PDF.
-
Using elements of the application of interactive report filters
Hello
Can we use elements of application in interactive report filters? If so, how?
Thank you
MachaanTake a look at the creation of a link to the section of interactive reports in the Application Guide of the user for example generator
This example binds, resets and clears the saved report parameters 12345. It also creates an ENAME = 'KING' filter on saved report 12345.
f? p = 100: 1: & SESSION. : I have R_REPORT_12345::RIR, CIR::RIR, CIR:IR_ENAME:KING
If you have an element of the application P1_ENAME the following apply to the example above
f? p = 100: 1: & SESSION. : I have R_REPORT_12345::RIR, CIR::RIR, CIR:IR_ENAME: & P1_ENAME.
If you want a permament for all filter saved reports on the value of point of application, it is best to use the: APP_ITEM_NAME bind variables in your SQL syntax, it really depends on how you define the value of your item and how you interact with it. AFAIK does not request point directly bind variables syntax in the filters, IR etc...
-
subqueries, nested, using elements of the other party of the request
Hi all
I have a delicate problem, and I'll try to explain my best:
DB version is 11.2.0.3.0
My current query joins actually 2 tables 'TOTAL_COUNTS' and 'FIXED_COUNTS '. The FIXED_COUNTS table is updated every day when a product has a patch against it and the query returns a list of all products and their "fixed" rate percentage (used in an interactive report of the APEX).create table product_list (product_id number, project_name varchar2(30)) create table products (product_id number, project_desc varchar2(30)) create table total_counts (product_id number, total_count number, project_name varchar2(30)) create table fixed_counts (product_id number, fixed_count number, project_name varchar2(30). fixed_date date) create table product_rating (product_id number, rating number, quarter_last_updated number) create table quarters (quarter_id number, quarter_end_date date) insert into product_list values (1, 'Prod 1'); insert into product_list values (2, 'Prod 2'); insert into product_list values (3, 'Prod 3'); insert into products values (1, 'Prod 1'); insert into products values (2, 'Prod 2'); insert into products values (3, 'Prod 3'); insert into total_counts values (1, 2000, 'Prod 1'); insert into total_counts values (2, 1000, 'Prod 2'); insert into total_counts values (3, 500, 'Prod 3'); insert into fixed_counts values (1, 1, 'Prod 1', to_date('01/01/2013','DD/MM/YYYY')); insert into fixed_counts values (1, 3, 'Prod 1', to_date('01/01/2013','DD/MM/YYYY')); insert into fixed_counts values (2, 50, 'Prod 2', to_date('01/01/2013','DD/MM/YYYY')); insert into fixed_counts values (2, 2, 'Prod 2', to_date('01/01/2013','DD/MM/YYYY')); insert into fixed_counts values (2, 3, 'Prod 2', to_date('01/01/2013','DD/MM/YYYY')); insert into fixed_counts values (2, 3, 'Prod 2', to_date('01/01/2013','DD/MM/YYYY')); insert into fixed_counts values (3, 8, 'Prod 3', to_date('01/01/2013','DD/MM/YYYY')); insert into fixed_counts values (3, 3, 'Prod 3', to_date('01/03/2013','DD/MM/YYYY')); insert into product_rating values (1, 1, 1); insert into product_rating values (3, 2, 2); insert into quarters values (1, to_date('01/10/2012','DD/MM/YYYY')); insert into quarters values (2, to_date('01/02/2013','DD/MM/YYYY'));
It gives me a result like:select A.PRODUCT, A.TOTAL, B.FIXED, a.PROD_ID, round((FIXED/TOTAL) * 100, 2) percent from ( select sum(a.total_count) TOTAL, a.product_id PROD_ID, d.Product_desc PRODUCT from total_counts a, product_list c, products d where a.product_id = c.product_id and lower(a.project_name) = lower(c.project_name) and c.product_id = d.product_id group by a.product_id, d.product_desc ) A JOIN ( select sum(b.fixed_count) FIXED, b.product_id PROD_ID, d.Product_desc PRODUCT from fixed_counts b, product_list c, products d where b.product_id = c.product_id and lower(b.project_name) = lower(c.project_name) and c.product_id = d.product_id group by b.product_id, d.product_desc ) B on A.PROD_ID = B.PROD_ID and A.PRODUCT = B.PRODUCT
The application works very well and does exactly the job I need. However, I now a requirement that when a product gets a percentage rate 'fixed' more than 1% of the product gets a point added against her in a table 'product_rating' and I have to recalculate the percentage of the date, the item has been added (so no points added we take all 'fixed').PRODUCT TOTAL FIXED PROD_ID percent Prod 1 2000 4 1 0.2 Prod 2 1000 58 2 5.8 Prod 2 500 11 3 2.2
To do this, I added 2 new tables: "product_rating" and "quarters". The "product_rating" table contains the Product_id and points, he has accumulated so far. It is updated once a quarter. 'Quarters' table simply contains the dates for us to use for calculations again.
Actually, I need to replace this:
with something like this:sum(b.fixed_count) FIXED
Based on the values in the tables above the percentages for "3 Prod' should now be 0.6.» It is because he received a product_rating the quarter 2, then the new calculation is based on all the "corrections" after this date (only the last March 1 13').if a product has a point against it in the "product_rating" table then we just show fixes from the date the point was added i.e. select sum(b.fixed_count) from fixed_counts b, product_rating c, quarters d where b.product_id = c.product_id and c.quarter_last_updated = d.quarter_id and b.product_id = PROD_ID and b.fixed_date > (select quarter_end_date from quarters where quarter_id = the_last_quarter_updated)
I tried many ways to integrate this into the current query, but I can't make it work. Sorry for not adding the info from the entire table, but the tables total_counts and fixed_counts have many more columns that I removed the query so it would be easier to observe. Thanks in advance for your help. If I can add more info ask please.
Tom
Published by: on May 14, 2013 TomH 08:54
Published by: on May 14, 2013 TomH 08:58TomH wrote:
of course, to the right, thank you.
I added some info table and data that will hopefully a little easier to understand.OK, thank you... to the future but please try and run the commands yourself for you sure they work. What you provided is close, but it has not executed immediately without modifications.
I will start by expressing my concerns for your data model, it seems... well, for lack of a better word. Although you said you deleted a bunch of stuff to make the example. You have someone, you you work who can look at the model for you?
With respect to the query, it's not pretty (I'm in a bit of a rush here) so you can probably clean it considerably. I just tried to show the basics of what you're going to have to do.
ME_XE? with base_data as 2 ( 3 select 4 b.fixed_date, 5 b.fixed_count, 6 b.product_id , 7 d.project_desc 8 from fixed_counts b, product_list c, products d 9 where b.product_id = c.product_id 10 and lower(b.project_name) = lower(c.project_name) 11 and c.product_id = d.product_id 12 ), 13 final_base_data as 14 ( 15 select 16 b.product_id PROD_ID, 17 b.project_desc PRODUCT, 18 sum 19 ( 20 case 21 when b.fixed_date >= stuff.quarter_end_date or stuff.quarter_end_date is null 22 then 23 b.fixed_count 24 else 25 0 26 end 27 ) as FIXED 28 from base_data b 29 left outer join 30 ( 31 select 32 pr.product_id, 33 qr.quarter_end_date 34 from product_rating pr , quarters qr 35 where pr.quarter_last_updated = qr.quarter_id 36 ) stuff 37 on (stuff.product_id = b.product_id) 38 group by b.product_id, b.project_desc 39 ) 40 select A.PRODUCT, A.TOTAL, B.FIXED, a.PROD_ID, round((b.FIXED/a.TOTAL) * 100, 2) percent 41 from 42 ( 43 select sum(a.total_count) TOTAL, a.product_id PROD_ID, d.project_desc PRODUCT 44 from total_counts a, product_list c, products d 45 where a.product_id = c.product_id 46 and lower(a.project_name) = lower(c.project_name) 47 and c.product_id = d.product_id 48 group by a.product_id, d.project_desc 49 ) A 50 JOIN final_base_data B 51 on A.PROD_ID = B.PROD_ID and A.PRODUCT = B.PRODUCT 52 ; PRODUCT TOTAL FIXED PROD_ID PERCENT ------------------------------ ------------------ ------------------ ------------------ ------------------ Prod 1 2000 4 1 .2 Prod 2 1000 58 2 5.8 Prod 3 500 3 3 .6 3 rows selected.See you soon,.
-
Cannot control the sequence of elements in the poster, using JDev 10.1.3.4
Who who know or have known the same front:
I use JDev 10.1.3.4 to develop my application. I interspersed with JSF, and ADF elements in my pages the elements of the model. Sometimes I managed to work around this problem, sometimes it can control just not it. Here is an excerpt from a page:
But the page does not appear in this order:<p>Some text before the radio buttons</p> <h:selectOneRadio binding="#{backing_student_doValidation.selectOneRadio1}" id="selectOneRadio1"> <f:selectItem itemLabel="I Agree" itemValue="agree" binding="#{backing_student_doValidation.selectItem1}" id="selectItem1"/> <f:selectItem itemLabel="I Disagree" itemValue="disagree" binding="#{backing_student_doValidation.selectItem2}" id="selectItem2"/> </h:selectOneRadio> <p>Please click the Submit button to Continue.</p> <h:commandButton value="Submit" binding="#{backing_student_doValidation.commandButton1}" id="commandButton1"/>
Note that option buttons ignore paragraph down to retreat with the submit command button.Some text before the radio buttons Please click the Submit button to Continue. O I Agree O I Disagree [Submit]
I choose to use .jsp to my pages. It seems that the problem occurs when the ADF is involved in the page. I deliberately avoid using jspx and adf panelPage because panelPage restricted menu bars and facets etc which I did not need and it is impossible to remove. I use therefore with jsp pages and html jsp tags to make the pages simple and clean. But I have to use elements of the data control palette; and once everything is drag-and - drop to the design of the page editor, adf tags tab will be automatically added to the page and two troubling things are happening: one is that the elements of the model are no longer visible in the Design tab of the page editor; the other is the problem shown above.
Are there ways to get around the problem?
Thank you very much!
NewmanNewmann,
This happens because you mix HTML markup with the JSF tags (which you shouldn't do). You could try surrounding the pure html markup with f: tags verbatim or using JSF tags to generate your static output.
John
-
How to determine the order of the entries in the menu displayed on the controller menu plugin?
I found in the plugin Resource Guide.pdf:
-----------------------------
Int16 PIPriorityProperty 0x70727479L
("prty")
Plugin load order. Also used for control
the order in the elements with the same
name appear in the menus.
Lower number (including negative
Ones) loading first. If NULL, the default value is
zero.-----------------------------
Now, I have a few plugins, but I saw that in the same category, the menu items are indicated by order lexicographically (A:up Z:down), but not by their priority properties. In addition, each category is organized by lexicographic order of the name now. This means, if I change the name of plugin to another language, order will be different, it's inconvenient for users. Fixed what I could do to get an order? Any ideas will be appreciated.
You can get 2 identical names by mistake, with versions of a plugin, or features that overlap (such as alternative file formats).
No, there is no way to get an absolute positioning of elements of a plugin menu.
And the reference to the suites makes no sense.
-
The order of failover and load balancing
Hello
I have the following scenario. An ESXi with 4 Gbps vmnic. The questions are:
(1) if I have a group of ports configured for 'Route based on the original virtual Port code' in the policy of balancing load, and for the same port group I the option button 'Override switch failover command"checked, where I set up 3 of the active adapters vmnic, as well as the other vmic remaining as unused adapter, the ESXi uses the policy that I have configured (in this case 'Route based on the original port code') between the three vmnic load balancing marked as active? Or he uses them in the order that they appear in the section active cards?
(2) Suppossed, I configured the four physical switch ports in an etherchannel group to use 'Route based on the IP hash' load balancing policy. In this situation, then I configured for a certain group of port to only used two active adapters and two others as unused? In this case, ESXi should balance the load using the method hash IP but only in two active adapters? Or it is a misconfigiuration and I should not configure my nic teaming in this way?
(3) the official setup guide says "NOTICE on IP requires the physical switch be configured with etherchannel. For all other options, etherchannel must be disabled. ». How can I I configured my virtual network, if I have a few groups of political ports based on the hash of the IP to use load balancing and another uses 'Route based on the original port code. This is the case when I for example have two management ports using the same vSwitch with four vmnic (where they are configured as an Etherchannel in the physical switch). I would port one or several groups for virtual machines that use the IP of the hash method of balancing the load and vmkernel ports por management uses only a single adapter active with no back and as "based on the source port ID" load balancing as best practices said.
Now, the four vmnic is the same for all traffic. The physical switch ports must be configured in an etherchannel group because certain groups of ports will use the method of IP hash, but others are not. The configuration guide I said SHOULD NOT use etherchannel if I won't use the hash IP method, but I'LL use it, but only in groups of one or more ports.
Maybe I do not share the same vmnic from this situation.
Finally, it's a philosophical question. What is the difference between 'The route based on the source port ID' and the 'road based on the source MAC Hash' load balancing policy? What is the purpose of the second? It is assumed that if I had two different MAC address in a virtual machine, it would be because I had two different virtual cards inside the virtual machine, which would be connected to two different port ID in the vSwitch, I can use the first strategy (based on the original port code). In other words, which would be the case where I had the traffic entering the same vSwitch but port ID with different source MAC address, so I should chose the method to distinguish the Source MAC address load balancing traffic?
Thank you.
Guido.
(1) as long as you override vmnic only and don't change the policy for this group of ports, he uses the policy configured at level vSwitch and use the selected interface 3 with this policy
(2) it should work, I don't think it's a problem for the switch receive packets on a subset of the aggregation. I do not think that Etherchannel is supported (IIRC, it is a Cisco proprietary protocol, VMware only supports LACP passive, which corresponds to the Port channel world Cisco.) Trouble me if I'm wrong!)
(3) I think that's all right, as I have explained in 2), there is no special negotiations with the consolidation of VMware, the important thing only I know is to configure the port on the side of the switch channel if you decide to use the IP hash (that will lead to important questions)
4) (self labeled) I think it may differ in some cases individuals, as when the operating system use the same MAC address for both NICs (aggregation in-vm) or if you advertise several MAC address for the same network card (ESX in a VM for example would make for its VM). Such cases differently affect this setting.
That is the right question, and I'm curious to know if someone wants to develop on it!
-
Keep the order of the elements stored in the table pl.sql
Hello friends,
I'm having a type registration and for each item in the folder, I'll have the corresponding table of pl.sql type.
If I store the values in the records in a query and also the individual elements in the table of pl.sql type will be of the order of the data is stored as it is. ..
for example...
in a record type, the data is stored as (name1, years1, salary1), (name2, age2, salary2)
If I store in correspondent pl sql table type name1, name2
years1, age2
salary1, salary2
I can identify the index of the record type with that of type pl/sql table...
pls advice
Thank you/kumarKumar,
Yes, the order of the elements will be the same.
No specific reason why you want to create a collection for each attribute of the record?
You can also declare another variable of the same file and initialize it.Some other suggestions for your code:
(1) FOR 2nd loop can be changed to accommodate the request of the first slider he - by eliminating an extra iteration.
SELECT MINC.FAMID, MINC.MEMBNO, MEMB.AGE, SALARYX, SALARYBX, NONFARMX, NONFRMBX, FARMINCX, FRMINCBX, CU_CODE FROM MINC, MEMB, FMLY WHERE MINC.FAMID = MEMB.FAMID AND MINC.MEMBNO = MEMB.MEMBNO AND MINC.FAMID = FMLY.FAMID AND MEMB.FAMID = FMLY.FAMID ORDER BY MINC.FAMID(2) the collections can alternatively be initialized as follows:
v_member_rec(v_member_rec.last).FAMID := j.FAMID; max_earnings_tab(max_earnings_tab.last) := v_max_earnings;The I tried the example for confirmation below...
declare type emp_rec is record (name emp.ename%TYPE, dept emp.edept%TYPE, sal emp.esal%TYPE ); TYPE emp_rec_tab is table of emp_rec; ert emp_rec_tab := emp_rec_tab(); TYPE ename_tab is table of varchar2(20); ent ename_tab := ename_tab(); TYPE edept_tab is table of number; edt edept_tab := edept_tab(); begin for i in (select * from emp) loop ert.extend; ent.extend; edt.extend; ert(ert.last).name := i.ename; ert(ert.last).dept := i.edept; ert(ert.last).sal := i.esal; ent(ent.last) := i.ename; edt(edt.last) := i.edept; end loop; for i in 1..ert.count loop dbms_output.put_line(ert(i).name||','||ent(i)); dbms_output.put_line(ert(i).dept||','||edt(i)); dbms_output.put_line(''); end loop; end; -
Using data from the control table
Hello
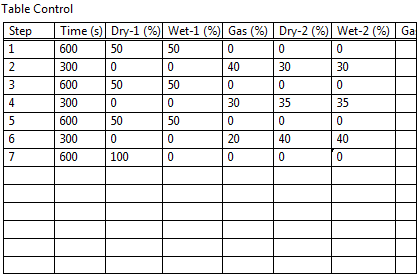
I would like to use the data entered in a table to automate volume/sequence of airflow for a test Chamber. As shown in the screenshot of control table, the first column indicates the number of iterations by elements of array in a series of tests and the second data column specifies the length of each line sequence. Entries in the other columns are specific to different valves and specify values set required in the flow meter.
I guess my question is how can I index/assign each column of the table such that the data to exploit the respective valves are obtained in subsequent iterations all acquire simultaneously with data from other components in the order? While I recognize that the solution may be very simple, I searched on through various examples and messages on the tables and the tables without knocking on a solution. The attached .vi allows me to be a part of the series of tests.
Best regards
Callisto
Hi Callisto,
If I understand your question then the solution is actually quite simple. The important point to keep in min is the fact that the Table control can actually be treated as an array of string. You can then use all the traditional table manipulation tools and techniques to manipulate your data as you wish. For example, use the Array Index function to retrieve specific columns and then if you want to spend the individual elements in a column in a loop, wire the table until the loop and ensure that indexing is enabled. If you then want to use these data elements to control your test application, you can convert a portion of the resulting string in more useful to digital.
All these concepts are illustrated in the attached VI. I hope this helps, but let me know if you have any other questions.
Best regards
Christian Hartshorne
NIUK
-
Invert the table to the Add element to the front of the performance of Bay
Hi all
I read in a few places that reverse an array to add the element to the front of it will give the best performance since no new allocation of memory is necessary.
I have 2 questions about this process:
1. "reverse a table on requires pointers change.»
Is that mean that a table in Labview is like a linked list? who has pointers that point to the next element.
So when this inverse process occurs, the head of the linked list will be the last element of the array, and all links in the linked list will require a change.

Step 1: table of moose with one extra space at the end
Step 2: Matrix inverse
Step 3: Add a new item at the end of the table opposite
Step 4: Reverse again.
2. the exercise of reverse Add then reverse is even worse in fact. Why is this?


"Overhead" is the need for new buffer allocations, which indireclly affects runtime but also memory.
Yes, often the paintings have an additional memory beyond the end of the table to avoid the resizing with each adding an item...
Your FAQ quotes says nothing about any reversal trick. To do this, the elements of the array need reverse look up, then inserted using the space soft (if it exists!), then the need even to reverse ber alements in place. Seems like a lot of work to do over and over again. Yes, it might be slightly more efficient that have to be allocated to each prefix operation but we do not really know what the compiler does. Maybe if soft is available, it would be to move all the items up and insert the element first, make a new allowance that occasionally necessary. Who knows? I have the greatest respect for Darren, the author of the "source". Perhaps he can clarify what he writes.
Benchmarking valid what is quite difficult.
In all cases, you often know the final size, so it can be distributed in one shot and the items replaced with valid data that you will. It's always orders if magnutide more effective than any other solution. If you need to grow an element of a table at a time, add at the end, never at the begginning.
-
Adding a single element of the array sequentially 1 d to new unique table
Hello
I'm getting a table 1 d of double inside the while loop. Table 1 d consists of only a single element, and it replaces itself every time through the loop. I need to store them in a table of given length separte before you overwrite it.
For example: I get table 1 d from 1 to 10, but in the order either 1 and then loop 2, then 3 and so on. 2 replaces 1, 3 replaces 2 and so on. What I have to do is to save the incoming values before the replacement of 1 to 10 in one separate table.
I tried to use the table to Index and build functions of table but I could not get the desired result. I also tried to use registry to shift, but I think I'm wrong somewhere. You please help me.
Thank you for your help.
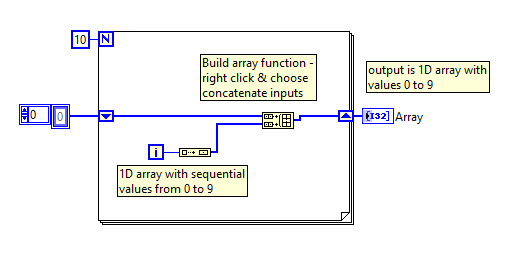
Did you want something like that? The table is built and stored in a shift register (if you were on the right track). Where you might have gone wrong is with the function Array build - you must right click and choose "Concatenate entries" in order to add each new table 1 at the end of the existing d - If you don't then it adds the new table as another dimension to the existing one!
-
How to create indexes on the ordered collection of XMLTYPE table?
I use Oracle 11.2.0.2.
Basically, my XML documents have a 3-level hierarchy:
event
+ - action [1: n]
+ - param [1: n]
I try to create indexes on the tables of the orderly collection, but cannot get the right syntax...
I created a table with an XMLType object-relational column:
CREATE TABLE T_C_RMP_MNTRNG_XML_FULL_IL4 ( MESSAGE_ID NUMBER(22,0) NOT NULL ENABLE, XML_EVAL_ID NUMBER(22,0), VIN7 VARCHAR2(7 BYTE), FLEET_ID VARCHAR2(50 BYTE), CSC_SW_VERSION VARCHAR2(100 BYTE), RECEIVED DATE, XML_CONTENT SYS.XMLTYPE , DWH_LM_TS_UTC DATE NOT NULL ENABLE, CONSTRAINT PK_C_RMP_MNTRNG_XML_FULL_IL4 PRIMARY KEY (MESSAGE_ID) ) NOLOGGING TABLESPACE CATALOG VARRAY "XML_CONTENT"."XMLDATA"."action" STORE AS TABLE "T_OR_MON_ACTION" ( NOLOGGING TABLESPACE "CATALOG" VARRAY "param" STORE AS TABLE "T_OR_MON_ACTION_PARAM" ( NOLOGGING TABLESPACE "CATALOG" ) RETURN AS LOCATOR ) RETURN AS LOCATOR XMLTYPE XML_CONTENT STORE AS OBJECT RELATIONAL XMLSCHEMA "http://mydomain.com/cs.xsd" ELEMENT "monitoring";
I execute the SELECT statement:
SELECT EVENT_ID, ACTION_SUB_ID, MESSAGE_ID, ACTION_TYPE, UNIXTS_TO_DATE(ACTION_TIMESTAMP) ACTION_TIMESTAMP FROM T_C_RMP_MNTRNG_XML_FULL_IL4, XMLTABLE( 'for $i1 in /monitoring , $i2 in $i1/action return element r { $i1/eventId, $i2 }' PASSING XML_CONTENT COLUMNS EVENT_ID VARCHAR(40) PATH 'eventId', ACTION_SUB_ID INTEGER PATH 'action/actionSubId', ACTION_TYPE VARCHAR2(100) PATH 'action/type', ACTION_TIMESTAMP NUMBER(13,0) PATH 'action/time' ) T2 WHERE ( EVENT_ID IS NOT NULL AND ACTION_SUB_ID IS NOT NULL )The plan of the explain command looks like this (sorry, don't know how to get it formatted any 'eye-team'):
----------------------------------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | TempSpc | Cost (% CPU). Time |
----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1609K | 6316M | | 6110K (1) | 20:22:11 |
|* 1 | HASH JOIN | | 1609K | 6316M | 111 M | 6110K (1) | 20:22:11 |
| 2. TABLE ACCESS FULL | T_C_RMP_MNTRNG_XML_FULL_IL4 | 582K | 104 M | | 5241 (1) | 00:01:03 |
|* 3 | TABLE ACCESS FULL | T_OR_MON_ACTION | 32 M | 117G | | 105K (2) | 00:21:08 |
----------------------------------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
1 - access ("NESTED_TABLE_ID"= "T_C_RMP_MNTRNG_XML_FULL_IL4"." ("SYS_NC0001300014$")
filter (CAST (SYS_XQ_UPKXML2SQL (SYS_XQEXVAL (SYS_XQEXTRACT ((SYS_XMLGEN ("T_C_RMP_MNTRN XMLCONCAT
G_XML_FULL_IL4 ". "" $ SYS_NC00017 ", NULL, SYS_XMLCONV ("T_C_RMP_MNTRNG_XML_FULL_IL4". "SYS_NC00012$", 0.32,
(('EC1EEF23FD023A27E04032A06D930A8D', 3, 3783, 1)), SYS_MAKEXML ('EC1EEF23FD023A27E04032A06D930A8D', 3780,
'T_C_RMP_MNTRNG_XML_FULL_IL4 '. "' SYS_NC00008$ ', 'SYS_ALIAS_0 '. ((("' SYS_NC_ROWINFO$ ')),'/ ID ', NULL), 0,.
0,20971520,0), 50.1, 2) AS VARCHAR (40)) IS NOT NULL)
3 filter (CAST (TO_NUMBER (TO_CHAR ("SYS_ALIAS_0". "actionSubId")) AS INTEGER) IS NOT NULL) "
Note
-----
-dynamic sample used for this survey (level = 2)
-Construction detected no optimized XML (activate XMLOptimizationCheck for more information)
The XML schema looks like this:
<?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified" xmlns:oraxdb="http://xmlns.oracle.com/xdb" oraxdb:storeVarrayAsTable="true" oraxdb:flags="2105639" oraxdb:schemaURL="http://mydomain.com/cs.xsd" oraxdb:schemaOwner="MYUSER" oraxdb:numProps="23"> <xs:element name="monitoring" oraxdb:propNumber="3785" oraxdb:global="true" oraxdb:SQLName="monitoring" oraxdb:SQLType="monitoring755_T" oraxdb:SQLSchema="MYUSER" oraxdb:memType="258" oraxdb:defaultTable="monitoring757_TAB" oraxdb:defaultTableSchema="MYUSER"> <xs:complexType oraxdb:SQLType="monitoring755_T" oraxdb:SQLSchema="MYUSER"> <xs:sequence> <xs:element maxOccurs="unbounded" ref="action" oraxdb:propNumber="3780" oraxdb:global="false" oraxdb:SQLName="action" oraxdb:SQLType="action752_T" oraxdb:SQLSchema="MYUSER" oraxdb:memType="258" oraxdb:MemInline="false" oraxdb:SQLInline="true" oraxdb:JavaInline="false" oraxdb:SQLCollType="action756_COLL" oraxdb:SQLCollSchema="MYUSER"/> <xs:element ref="reservationType" oraxdb:propNumber="3781" oraxdb:global="false" oraxdb:SQLName="reservationType" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:MemInline="false" oraxdb:SQLInline="true" oraxdb:JavaInline="false"/> <xs:element ref="softwareVersion" oraxdb:propNumber="3782" oraxdb:global="false" oraxdb:SQLName="softwareVersion" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:MemInline="false" oraxdb:SQLInline="true" oraxdb:JavaInline="false"/> <xs:element ref="eventId" oraxdb:propNumber="3783" oraxdb:global="false" oraxdb:SQLName="eventId" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:MemInline="false" oraxdb:SQLInline="true" oraxdb:JavaInline="false"/> <xs:element ref="vin" oraxdb:propNumber="3784" oraxdb:global="false" oraxdb:SQLName="vin" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:MemInline="false" oraxdb:SQLInline="true" oraxdb:JavaInline="false"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="action" oraxdb:propNumber="3790" oraxdb:global="true" oraxdb:SQLName="action" oraxdb:SQLType="action752_T" oraxdb:SQLSchema="MYUSER" oraxdb:memType="258" oraxdb:defaultTable="action754_TAB" oraxdb:defaultTableSchema="MYUSER"> <xs:complexType oraxdb:SQLType="action752_T" oraxdb:SQLSchema="MYUSER"> <xs:sequence> <xs:element ref="type" oraxdb:propNumber="3786" oraxdb:global="false" oraxdb:SQLName="type" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:MemInline="false" oraxdb:SQLInline="true" oraxdb:JavaInline="false"/> <xs:element maxOccurs="unbounded" ref="param" oraxdb:propNumber="3787" oraxdb:global="false" oraxdb:SQLName="param" oraxdb:SQLType="param749_T" oraxdb:SQLSchema="MYUSER" oraxdb:memType="258" oraxdb:MemInline="false" oraxdb:SQLInline="true" oraxdb:JavaInline="false" oraxdb:SQLCollType="param753_COLL" oraxdb:SQLCollSchema="MYUSER"/> <xs:element ref="actionSubId" oraxdb:propNumber="3788" oraxdb:global="false" oraxdb:SQLName="actionSubId" oraxdb:SQLType="NUMBER" oraxdb:memType="2" oraxdb:MemInline="false" oraxdb:SQLInline="true" oraxdb:JavaInline="false"/> <xs:element ref="time" oraxdb:propNumber="3789" oraxdb:global="false" oraxdb:SQLName="time" oraxdb:SQLType="NUMBER" oraxdb:memType="2" oraxdb:MemInline="false" oraxdb:SQLInline="true" oraxdb:JavaInline="false"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="type" type="xs:string" oraxdb:propNumber="3791" oraxdb:global="true" oraxdb:SQLName="type" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:defaultTable="type751_TAB" oraxdb:defaultTableSchema="MYUSER"/> <xs:element name="param" oraxdb:propNumber="3794" oraxdb:global="true" oraxdb:SQLName="param" oraxdb:SQLType="param749_T" oraxdb:SQLSchema="MYUSER" oraxdb:memType="258" oraxdb:defaultTable="param750_TAB" oraxdb:defaultTableSchema="MYUSER"> <xs:complexType oraxdb:SQLType="param749_T" oraxdb:SQLSchema="MYUSER"> <xs:sequence> <xs:element minOccurs="0" ref="value" oraxdb:propNumber="3792" oraxdb:global="false" oraxdb:SQLName="value" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:MemInline="false" oraxdb:SQLInline="true" oraxdb:JavaInline="false"/> <xs:element ref="key" oraxdb:propNumber="3793" oraxdb:global="false" oraxdb:SQLName="key" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:MemInline="false" oraxdb:SQLInline="true" oraxdb:JavaInline="false"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="value" type="xs:string" oraxdb:propNumber="3795" oraxdb:global="true" oraxdb:SQLName="value" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:defaultTable="value748_TAB" oraxdb:defaultTableSchema="MYUSER"/> <xs:element name="key" type="xs:string" oraxdb:propNumber="3796" oraxdb:global="true" oraxdb:SQLName="key" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:defaultTable="key747_TAB" oraxdb:defaultTableSchema="MYUSER"/> <xs:element name="actionSubId" type="xs:integer" oraxdb:propNumber="3797" oraxdb:global="true" oraxdb:SQLName="actionSubId" oraxdb:SQLType="NUMBER" oraxdb:memType="2" oraxdb:defaultTable="actionSubId746_TAB" oraxdb:defaultTableSchema="MYUSER"/> <xs:element name="time" type="xs:integer" oraxdb:propNumber="3798" oraxdb:global="true" oraxdb:SQLName="time" oraxdb:SQLType="NUMBER" oraxdb:memType="2" oraxdb:defaultTable="time745_TAB" oraxdb:defaultTableSchema="MYUSER"/> <xs:element name="reservationType" type="xs:string" oraxdb:propNumber="3799" oraxdb:global="true" oraxdb:SQLName="reservationType" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:defaultTable="reservationType744_TAB" oraxdb:defaultTableSchema="MYUSER"/> <xs:element name="softwareVersion" type="xs:string" oraxdb:propNumber="3800" oraxdb:global="true" oraxdb:SQLName="softwareVersion" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:defaultTable="softwareVersion743_TAB" oraxdb:defaultTableSchema="MYUSER"/> <xs:element name="eventId" type="xs:string" oraxdb:propNumber="3801" oraxdb:global="true" oraxdb:SQLName="eventId" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:defaultTable="eventId742_TAB" oraxdb:defaultTableSchema="MYUSER"/> <xs:element name="vin" type="xs:string" oraxdb:propNumber="3802" oraxdb:global="true" oraxdb:SQLName="vin" oraxdb:SQLType="VARCHAR2" oraxdb:memType="1" oraxdb:defaultTable="vin741_TAB" oraxdb:defaultTableSchema="MYUSER"/> </xs:schema>
How can I create an index on these tables of the ordered collection to improve performance?
I found the example at http://docs.Oracle.com/CD/E11882_01/AppDev.112/e23094/xdb_rewrite.htm#ADXDB5859 but am not able to apply to this particular case...
Thank you in advance...
If the schema is not annotated and XS: Integer and XS: String are mapped to types of data NUMBER and VARCHAR2 (4000), so you must use in your query to avoid typecasting unnecessary operations.
You must also use XMLTABLEs chained when accessing a parent/child instead of a FLWOR expression relationship, otherwise the CBO cannot rewrite the XQuery query correctly (maybe it's fixed in the latest version).
If you make these changes, the plan should show the cleaner predicates:
SQL > SELECT EVENT_ID, MESSAGE_ID, ACTION_TYPE, ACTION_SUB_ID, ACTION_TIMESTAMP
2 FROM test_table
3 XMLTABLE ('/ monitoring ')
4 COLUMNS XML_CONTENT OF PASSAGE
5 WAY of VARCHAR2 (4000) EVENT_ID "ID."
6 actions for XMLTYPE PATH 'action '.
(7) T1,
8 XMLTABLE ('/ action')
Shares of PASSAGE 9 COLUMNS
NUMBER of ACTION_SUB_ID 10 PATH "actionSubId."
11 PATH of VARCHAR2 (4000) ACTION_TYPE "type."
12 WAY of NUMBER ACTION_TIMESTAMP 'time '.
(13) T2
14 WHERE EVENT_ID IS NOT NULL
15 AND ACTION_SUB_ID IS NOT NULL
16;
Execution plan
----------------------------------------------------------
Hash value of plan: 1763884463
------------------------------------------------------------------------------------------------
| ID | Operation | Name | Lines | Bytes | Cost (% CPU). Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 109. 220K | 6 (17). 00:00:01 |
| 1. THE MERGE JOIN. | 109. 220K | 6 (17). 00:00:01 |
|* 2 | TABLE ACCESS BY INDEX ROWID | TEST_TABLE | 11. 352. 2 (0) | 00:00:01 |
| 3. INDEX SCAN FULL | SYS_C007567 | 11. | 1 (0) | 00:00:01 |
|* 4 | JOIN TYPE. | 109. 216K | 4 (25) | 00:00:01 |
|* 5 | TABLE ACCESS FULL | T_OR_MON_ACTION | 106 S 216K | 3 (0) | 00:00:01 |
------------------------------------------------------------------------------------------------
Information of predicates (identified by the operation identity card):
---------------------------------------------------
2 - filter("TEST_TABLE".") (' SYS_NC00012$ ' IS NOT NULL)
4 - access("SYS_ALIAS_0".") NESTED_TABLE_ID "=" TABLE_TEST. " ("' SYS_NC0000800009$ ')
filter ("SYS_ALIAS_0". "NESTED_TABLE_ID"="TABLE_TEST" "." " ("SYS_NC0000800009$")
5 - filter("SYS_ALIAS_0"." actionSubId» IS NOT NULL)
Note
-----
-dynamic sample used for this survey (level = 2)
Now, if it is still necessary, everything boils down to choosing a technique for index NULL values:
-composite index with a column not zero or constant
-FBI
-bitmap image
Choose the one that best fits your data, the selectivity and activity on the tables.
Maybe you are looking for
-
Show all members of the Group of developer tools?
How can I view all of the current members of the developer tools group?
-
I'm having this problem with my equium M50, it works fine, but when it comes to paralyze the system, the system seems to close as requested, but as soon as the system is turned off, it immediately starts up again! The same thing happens when I want t
-
I can't access my memory card from my computer
I can't access my memory card from my computer
-
my printer is not printing in word 2007 documents.
Print previews are fine, the insturctions cross to print, the paper is taken and then comes out blank. To start, it wasn't printing headers, the entire page now not be printed. It has ink. Thank you
-
Where can I find instructions on how to clean or replace the CPU cooling fan. Part #42W2779? Also, if I need to replace where would be the best place to buy from?