VIP when 8132F Cluster
Hello
I have a pair of 8132F was already clustered. I would use it as a gateway for routing internal. Will I still need to configure the Protocol VRRP VIP or simply by using the IP Address of the interface which assign a different IP address for VLAN switch is OK?
When occur if the switch is down?
Thanks in advance
VRRP would need another switch/battery to work with. The stack of switches will act and be managed as a switch. You want to assign an IP address to each VLAN, and then this IP address will be the default gateway for clients in the VLAN.
On the stack, there is a teacher and an emergency switch. If the master goes down the night before has the same configuration on it and will take the place of the master station.
Tags: Dell Switches
Similar Questions
-
What happens when a cluster strengthen type has an element of his data modified by two different vi?
I like the use of a cluster/typedef to use as a mechanism to bring together all the variables I want to deal with a VI. Now, I create a second vi... and also use the tyepdef cluster to create a thread with the same variables in it. Are instances of variables in vi1 separated by instances of vi2... If Yes, is there a mechanism to pass values back and forth effectively between the two vi... would it be a (gag) overall with a sweep at each end?
Hummer1
A typedef simply sets a control as being a certain sense 'typical'. Its basic structure cannot be really changed with the editor control, but when it changes, it changes are propagated to where ever the control is used. Now, after you have created this typedef control you can use it to transmit data between vi in several ways. The least popular in the currents of thought is the global. The reasons been talked to death in this forum. Another method would be to use a "functional global"alias "LabVIEW 2 overall style", which has him enjoying it's locked, while any vi accessed. " Still another method would be to write in a queue in one vi and read in the other. There is a new 'global', which has its uses, called the "shared variable" all of them have advantages and disadvantages. Research on the terms highlighted for more information.
Well, how did you know nathand would write, is that he is sitting near you?
-
Unrecognized field \"networkName\' when calling Cluster workflow create the VCO.
Hello
I use BDE 1.1 on vsphere 5.5. I was sent BDE VCO Plugin version 0.5.0.70. When I try run create a workflow of cluster based Hadoop of VCO, it fails with the error below. Can anyone help?
Content the form of string: {"code": "BDD.} BAD_REST_CALL', 'message': "" has no REST API: could not read JSON data: unknown field \"networkName\" (class com.vmware.bdd.apitypes.ClusterCreate), not marked as ignorable\n to [Source: org.apache.catalina.connector.CoyoteInputStream@7e542721; line: 1, column: 578] (through the reference string: com.vmware.bdd.apitypes.ClusterCreate[\"networkName\"] ");" {"" nested exception is org.codehaus.jackson.map.exc.UnrecognizedPropertyException: unrecognized field \"networkName\" (class com.vmware.bdd.apitypes.ClusterCreate), not marked as ignorable\n to [Source: org.apache.catalina.connector.CoyoteInputStream@7e542721; line: 1, column: 578] (through the reference string: com.vmware.bdd.apitypes.ClusterCreate[\"networkName\"] ")"}
Thank you and best regards,
Nanga
Hi dvnagesh,
Assume your msg is for BDE 1.0: "networkName": 'nw1 '.
The equivalent in BDE 1.1 should be: 'networkConfig': {'MGT_NETWORK': ['nw1']}
-bxd
-
LabVIEW botches unbundle when cluster is changed
- Define a cluster (typedef) as Characteristics.ctl wave and a VI that separate this cluster as Cluster rename Bug.vi.
- Delete an item (Amplitude) of the cluster and add another to the end (background noise), so that the cluster always contains 3 elements such as the characteristics of the 2.ctl wave,.
- Apply the changes.
- The unbundle now uses the phase shift twice. The first occurrence of phase shift is incorrectly wired amplitude; He must always say dephasing, and black, and the VI should be impassable.
The same problem occurs if the VI that uses the cluster is not in memory when the cluster is changed. This problem we often enough and is a major source of bugs and cause of the loss of time. We understand that LabVIEW can not determine if the change in the name of the second element was intentional or a mistake made by the programmer. We would prefer to get a broken VI and to solve the problem ourselves, rather than having LabVIEW to make erroneous assumptions.
I can't reproduce this in LV8.5.1. What version do you use?
What happens if you:
delete an item
apply the changes,
Add another element,
apply the changes.Kind regards
Wiebe.
-
Bug in the drag cluster ' drop
LV2011, did not in any others. Just broken LV 3 times in a row when a cluster is created and slide into a digital picture. The 3rd time I noticed the table was grouped with a free label and when separated, it worked as expected.
So: Drag objects grouped together a block of cluster LV
/Y
Hi Yamaeda,
I was able to reproduce this error in 2013 of LabVIEW, 2012, 2011 SP1 and SP1 2010. However, for some reason, LabVIEW 2009 SP1 can handle. In other words, this error will not occur in LabVIEW 2009 SP1, but in future releases.
I've attached an example for five versions (mentioned above), that I used when trying to reproduce this error. You can try if you like and check. The example of the VI has two newly created empty clusters. The upper pole contains two tables that are locked up in a group. If you move the Group of tables of the upper pole in the cluster of low, I get the error message "not enough memory to complete this operation." If I move the group back and fourth between clusters (four times for enough for me), LabVIEW closes abruptly. When I open LabVIEW once again, I get a message from LabVIEW saying "Internal WARNING 0x9A3507AE occurred in FPDCO.cpp".
I'll bring back a CAR that earlier.
-
So it's probably a very easy question to answer, but I can't seem to find this information in all the help files.
I am creating a VI with inputs and outputs so that I can interface with Signal Express VI.
Where can I find symbols to insert in my VI, where I then can I connect to the control panel connector for Signal i/o Express can access the IO of the VI?
Specifically, I'm looking for an output connector to be able to pass out of my VI and in Signal Express clusters. But any general help in this area is also appreciated.
Thank you.
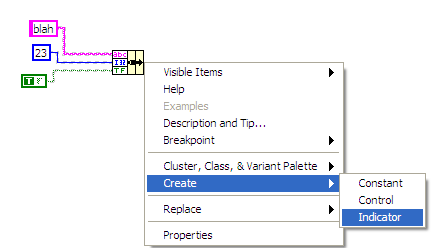
To get the output of the cluster:
Click on the output of when the cluster is created (in this case a build cluster), and then select Create, then choose indicator.
To get a cluster in, select you control.
Then just select it as you would any other indicator or control when assigning to the terminals on the block VI icon.
-
Insert into the cluster by string name
Hello
I am writing a Labview program to query .NET database management system and get the connected device (like USB CDC) listed with Port of corresponding Com, VID, PID, manufacturer of SN name ect...
I got to the point where I get the channels I need and want to organize them in a cluster table.
Here is my code, I wanted a better way to replace section circle of the code.
Basically, I can get programmatically the cluster name, but when the cluster wads, I can't figure out a way to do it programmatically inside the while loop: a loop on the number of items in the cluster and by placing values in the right place.
Is it possible to do?
Thank you very much
Amine
Altenbach says:
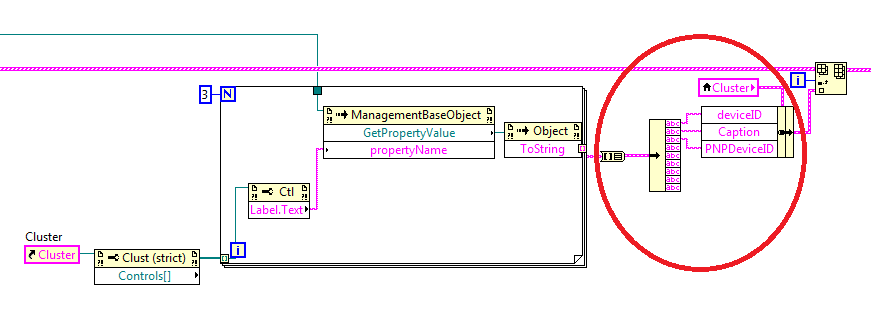
If the cluster contains exactly three elements of the chain (nothing else!) and they are classified as in the node of your 'bundle by name", all you have to do is on the"table of cluster"output size 3 and it wire in a table build node (upper entrance wired to your array of cluster and botton imput cable to the new cluster) Wired output by the right side of the image).
Here is a simplified illustration which simply sets the value of the label. (top image). Because the labels are defined at compile time, all you need is perhaps to get the names of once at the beginning of the program, and then use a range of simple string instead.
Another possibility would be to use the reference to the element to set the value inside the loop, and then get the final cluster value later (at the bottom of the image).
(There are some simplified examples. All you need is to replace the code that gets your new string instead.)

-
Dial the node library with cluster table feature using the pointer of table data
Hi all.
I am writing a wrapper of LabVIEW for an existing DLL function.
The service was, as one of its parameters, an array of structures. The structure is very simple, containing two integers. I use the call library function node to access.
In Labview, I created an array of clusters, when the cluster has two integers of 32 bits as members. So far so good.
Now, I have to pass this in the node library function call. I use here in trouble.
I used the LAVA so the topic in the knowledge base as my main sources of information, although I read a lot of topics in the forum on the subject too.
I don't understand I could write a new function that takes as a parameter a struct with the size as the first member and an array as the second, and I might just do this and do call the regular service, but I was hoping to do more simply.
The file function C LabVIEW generates for me the COLD Lake when I choose "To adapt to the Type" and "Data in the table pointer", the prototype he expects is:
int32_t myFunc (handful of uint32_t, uint16_t channel,
int32_t FIFOnumber, Sub data [], int32_t numWords, int32_t * actualLoaded,.
int32_t * actualStartIndex);And the prototype of the function in my DLL is
int myFunc borland_dll (DWORD channel, channel of Sina,)
FIFOnumber int, struct mStruct * data, int, int numWords * actualLoaded, int * actualStartIndex);It sounds like a match for me, but it doesn't work (I get garbage in the data). The topic referenced above LAVA, I realized it would work. This isn't.
If I have to cast the data to the pointer-to-pointer I get when I generate c code in my wiring to a CIN struct and by generating, then I seem to get what I expect. But it seems to work when I choose "pointers to handles" too, and I'm expecting data table pointer to give a different result.
Is it possible to get it works directly, or I have to create a wrapper? (I am currently using LabVIEW 2011, but we have customers using 2009 and 2012, if not other versions as well).
Thank you.
Batya
-
Status of VCS Cluster through CLI
Hello
Is it possible to check the status of the Cluster of CLI VCS Cluster?
I have found that a single command:
XStatus external 1 Applications
* Applications (s):
1 external:
Status:
ClusterStatus:
ClusterState: "enabled."
ClusterLastSyncDate: '2013-04-02 08:39:19.
ClusterNextSyncDate: '2013-04-02 08:40:19.
ClusterLastSyncResult: "SUCCESSFUL."
* s/end
Ok
But if I disconnect one of the peers of the bunch, fruit of xstatus external 1 Applications is the same.
Is it possible to check the status of the Cluster via CLI database?
-What happens when the cluster breaks down?
-What command can I use to check the status of the Cluster, Cluster database state, the State of the communication with other peers? What are the States of possible failure?
Thanx.
Marek.
Do not find them as documented, so use at your own risk :-)
In any case, I like web access https better for information of status and then to misuse the root account.
Create an account with api read access and get:
https:///api/management/status/clusterpeer
the output may differ with different versions
(that one was a X6.1 but X6.1 seem to show that the other peers see as well)
[{"peer":"192.168.0.91","num_recs":2,"records":[{"uuid":"54c4b972-0d5f-4748-90f6-3203d5eae693","peer":"192.168.0.91","state":"up"},{"uuid":"8939f6d5-77d8-4ec0-b275-19cd95b905d5","peer":"192.168.0.90","state":"up"}]}] -
Checking the LUNS when clusterware arises
Version of the grid: 11.2.0.3.6
Platform: Oracle Enterprise Linux 6.2
In our 2 bow TIE, Node2 got expelled. Once started Node2 CRS did not start. I couldn't find anything significant in the alert.log, ocssd.log or crsd.log grid.
In node2, I was able to do fdisk-l on all LUNS in the diskgroup OCR_VOTE. After a few hours of headaches and escalations, we discovered that LUNS were not really accessible to the clusterware in Node2, although fdisk-l has been correctly showing the partition.
When the cluster is down, I wanted to check if the drive to vote was really accessible to the CRS (GI), but I couldn't (as shown below).
#. / crsctl start crs
CRS-4640: Oracle high availability Services is already active
CRS-4000: Start command has failed, or completed with errors.
#. / crsctl query css votedisk
Unable to communicate with the Cluster synchronization service daemon.
How can I check if the drive to vote is accessible to the RSC in a knot when the CRS is down?
There are 2 layers necessary for the start of the CRS.
Storage. IMO, multipath is required for managing the storage of cluster at the physical level. To check if the storage is available, use the multipath-l for a list of the devices command. I usually use multipath-l | grep
to list the LUN, key word matches the LUN entry. For example [root@xx-rac01 ~] # multipath-l | grep VRAID | Sorting
VNX-LUN0 (360060160abf02e00f8712272de99e111) dm-8 DGC, VRAID
VNX-LUN1 (360060160abf02e009050a27bde99e111) dm-3 DGC, VRAID
VNX-LUN2 (360060160abf02e009250a27bde99e111) dm-9 DGC, VRAID
VNX-LUN3 (360060160abf02e009450a27bde99e111) dm-4 DGC, VRAID
VNX-LUN4 (360060160abf02e009650a27bde99e111) dm-0 DGC, VRAID
VNX-LUN5 (360060160abf02e009850a27bde99e111) dm-5 DGC, VRAID
VNX-LUN6 (360060160abf02e009a50a27bde99e111) dm-1 DGC, VRAID
VNX-LUN7 (360060160abf02e009c50a27bde99e111) dm-6 DGC, VRAID
VNX-LUN8 (360060160abf02e009e50a27bde99e111) dm-2 DGC, VRAID
VNX-LUN9 (360060160abf02e00a050a27bde99e111) dm-7 DGC, VRAIDIf the number of LUNS is bad and one or more LUNS are missing, I would check the logs to begin. You can also run a multichannel flush and rediscovering (and up to the fi level of verbosity errors are thrown).
If all LUNS are there, check the device permissions and make sure that the pile of s/w Oracle has access.
The other layer which needs to work is the interconnection. There are 2 basis points to check. The interface for local interconnection exist? This can be verified using ifconfig. And communicate this interface for interconnection with interfaces for interconnection of the other cluster node? This can be checked by using ping - or if Infiniband is used, via the ibhost and other orders of ib.
So if the CRS does not start - these 2 controls (storage and interconnection) would be my first port of call, as in my experience most of the time one of these 2 layers failed.
-
Add production ESX hosts to a cluster
Hi all
I did some research in the admin guides and community forums, and I'm sure that I know what to do, but I would really appreciate a test of consistency here because the manipulation I do is in a production environment:
I have a campus that contains two ESX areas that are managed by using vSphere and connected to a San. vMotion of works very well, the performance is very good (although the resources of the two boxes are fairly complete upward). However, I recently realized that I'd neglected to set up a cluster HA and DRS. I want to remedy.
I created the cluster with these specs:
- the two HA and DRS, enabled
- to the left, she also fully automated.
- the power management of left
- monitoring and host admission control enabled
- leave the default settings for the behavior of the virtual machine
- monitoring VM disabled
- EVC enabled
- the storage value of the swap with the virtual machine file
I think that the next steps would be to add each ESX host consecutively and merged its resources with the cluster. However, here are a few questions:
- How do you assess the risk factor to do this in a production environment (1 = perfectly safe, is a proven Scenario; 5 = you are out of your bloody mind? Do not)
- Should I be triple-checking the SAN snapshots and planning of downtime for servers, or is it possible live and without any major qualms?
- Am I right in assuming that it will increase my performance as well as provide better robustness of the campus, or should I expect a decrease in performance?
Thank you very much in advance for your advice!
Hey red,
Addressing your particular situation, I would say yes to two questions. Admission control HA is here to help you. Ensure there are enough resources on the host computer to run the current and any expected load it will be after an HA event. 50% is close to default (but it is really based on the size of the slot) in an environment with two guests when guest cluster failures tolerates is set to 1 in a two and 25% host environment when the percentage of unused reserved as production capacity cluster resources in failover is left to its default value.
If you have several virtual machines running that allows you to book 50% of your cluster resources (which it sounds like you have), then you have the option of "first category" your virtual machines and their giving priorities to restart event HA. For their level, you'll want to active DRS (can be set to manual Automation), resource pools and you will need to configure your virtual machine under your HA settings options. You'll want to pay attention to the priority of restarting VM here.
I suggest you take a look at blog Duncan Epping http://www.yellow-bricks.com/ and Frank Denneman http://frankdenneman.nl/blog. They are all two fairly well the definitive answer to the HA and DRS questions and advice.
See you soon,.
Mike
https://Twitter.com/#! / VirtuallyMikeB
http://LinkedIn.com/in/michaelbbrown
Note: Epping and Denneman explained that the amount reserved by default resources when you use the host cluster failures tolerates is promising to reserve enough resources to power on virtual machines. This reserve of resource does not on average current, account, or future default load. If you want to manipulate this feature, modify the memory and CPU reserves, which are the numbers used to calculate the size of the slot.
Post edited by: VirtuallyMikeB
-
Hello
What is the advantage of creating a VIP request?
I know that a VIP is a cluster resource that can be resumed to the survivors of the nodes.
Why do we really need? By default, if a node fails, all connections will go to the surviving node.Hello
Request VIP is basically use to handle the third-party clusterware through web-based application. Here is an example of Apache service management using clusterware:-
(1) create a VIP application resource
crs_profile - create myappvip t - application - one $ORA_CRS_HOME/bin/usrvip - o
OI = eth0, ov = 192.9.201.50, on = 255.255.255.0(2) enter the resource with clusterware
crs_register AppVIP1(3) create a cluster resource to manage your application as ACTION_SCRIPT is required for start, stop, clean and check the availability of the applications. This is also mentioned with VIP application resource dependence.
crsctl add resource myapache - type cluster_resource - attr ' host02 ACTION_SCRIPT=/usr/local/bin/apache.scr,PLACEMENT='restricted',HOSTING_MEMBERS='host01', CHECK_INTERVAL = "30", START_DEPENDENCIES = "hard (myappvip) ', STOP_DEPENDENCIES = ' hard (myappvip) ', RESTART_ATTEMPTS = '2'.
(4) start the myapache resource
departure from crsctl res myapache
Let's say that the apache service embarking on host01... in case if host01 falls down due to a failure in this case myapache will be failover to another node as well as the demand for VIP.
Version 11g 2, you can use the appvipcfg interface to create the VIP application resource, and you can also assign server pool rather than use the node name.Reference:-http://docs.oracle.com/cd/E11882_01/rac.112/e16794/crschp.htm
Thank you
Edited by: Caroline on May 28, 2013 17:56
-
"When to add more hosts" policy?
Hi all
I would like to hear what some of you are using in what concerns the addition of new hosts in your cluster of politics?
I would like to be more proactive on a few occasions, we ran into memory resource constraintsbefore that we have addressed the issue.
That means stopping the deployment of virtual machines until more resources is achieved.
I want to be in front of the 8-ball and I was wondering how solve you? Get additional resources when your cluster reaches a certain threshold for example of the use of memory or a certain percentage of memory overcommitment. I'm sure it's different for each workplace and all experiences are welcome.
see you soon
Please consider my response as 'useful' or 'proper' marking
If you find this or any other answer useful please consider awarding points marking the answer correct or useful
See you soon,.
Chad King
VCP-410. Server +.
Twitter: http://twitter.com/cwjking
-
How to get the ID of a single data centre and the Cluster
Hello
We have a product we need get the detail of data centers, Clusters, the Esx host and all Virtual Machines of a Virtual Center. And keep it in sync with the VCenter. I use a thread that queries the VCenter every 5 minutes and retrieves the data.
We use Java VI SDK 4.0 for this.
At the present time I am able to read all the details using PropertyCollector. But once a data center is renowned for my application, it is similar to a fact that a data center with the old name has been deleted and a data center with the new name has been added. For this reason, when data center is renamed, I remove entities for the former my application Esx host and adding new features to the ESX hosts in new data center. It causes a lot of unwanted things.
So, I want to go get some unique Id of the dataCenter and Cluster, so that when a cluster/datacenter is renamed, uniqueId is always the same and my app will be able to know that it is just a change of name. And entities for ESX/VirtualMachine will be kept.
Please, help me to know the unique id of the cluster/datacenter.
Thank you
Deepak
Yes, there are supposed to be unique UUID generated by vCenter or ESX (i) and if you have not manually mux with values. The UUID is guaranteed to be unique within a given instance of vCenter.
=========================================================================
William Lam
VMware vExpert 2009
Scripts for VMware ESX/ESXi and resources at: http://engineering.ucsb.edu/~duonglt/vmware/
Introduction to the vMA (tips/tricks)
Getting started with vSphere SDK for Perl
VMware Code Central - Scripts/code samples for developers and administrators
If you find this information useful, please give points to "correct" or "useful".
-
Cannot save the Cluster containing the server < servername >: Idispatch error
I'm building a new environment of Oracle EPM 11.1.2.1. I installed and configured HFM on one server and the HFM web components on another server. The server of HFM, all configuration tasks have managed including the registry servers and clusters. When I configure the HFM web server all configured successfully with the exception of the clusters and servers to register. It comes with an 'X' red and says failed.
When I look in the configuration log, I see the following errors related to the cluster configuration:
[SRC_CLASS: com.hyperion.config.wizard.impl.RunAllTasks] trace: custom tasks: register the application servers / Clusters for product HFM
[2012 01-18 T 09: 22:38.793 - 07:00] [EPMCFG] [NOTIFICATION] [EPMCFG-05543] [oracle. EPMCFG] [tid: 19] [ecid: 0000JJlc4do76Empoos1yY1F5j62000004, 0] [SRC_CLASS: com.hyperion.hfm.config.HfmClusterRegistrationTaskProcessor] registered clusters:, HFM_TQA
[2012 01-18 T 09: 22:38.793 - 07:00] [EPMCFG] [NOTIFICATION] [EPMCFG-05544] [oracle. EPMCFG] [tid: 19] [ecid: 0000JJlc4do76Empoos1yY1F5j62000004, 0] [SRC_CLASS: com.hyperion.hfm.config.HfmClusterRegistrationTaskProcessor] registered server: CGYAP1167
[2012 01-18 T 09: 22:38.852 - 07:00] [EPMCFG] [WARNING] [EPMCFG-02067] [oracle. EPMCFG] [tid: 19] [ecid: 0000JJlc4do76Empoos1yY1F5j62000004, 0] [SRC_CLASS: com.hyperion.hfm.config.hfmregistry.HFMRegistry] * error during record HFM Cluster configuration: {0} [[*]]
java.lang.RuntimeException: cannot save the server CGYAP1167: IDispatch #1553 error
at com.hyperion.hfm.config.EPMWindowsConfigJNI.RegisterServer (Native Method)
at com.hyperion.hfm.config.hfmregistry.HFMRegistry.configureHFMClusterRegistration(HFMRegistry.java:626)
at com.hyperion.hfm.config.HfmClusterRegistrationTaskProcessor.execute(HfmClusterRegistrationTaskProcessor.java:99)
at com.hyperion.cis.CustomTaskProcessor.execute(CustomTaskProcessor.java:94)
at com.hyperion.config.wizard.impl.RunAllTasks.executeCustomTask(RunAllTasks.java:832)
at com.hyperion.config.wizard.impl.RunAllTasks.execute(RunAllTasks.java:480)
at com.hyperion.config.wizard.impl.RunnAllTasksState.run(RunnAllTasksState.java:90)
at java.lang.Thread.run(Thread.java:619)
]]
[2012 01-18 T 09: 22:38.853 - 07:00] [EPMCFG] [ERROR] [EPMCFG-05020] [oracle. EPMCFG] [tid: 19] [ecid: 0000JJlc4do76Empoos1yY1F5j62000004, 0] [SRC_CLASS: com.hyperion.hfm.config.HfmClusterRegistrationTaskProcessor] error: error when configuring Cluster HFM registrationFailed to register the server CGYAP1167: IDispatch #1553 error
[2012 01-18 T 09: 22:38.865 - 07:00] [EPMCFG] [TRACE] [EPMCFG-01001] [oracle. EPMCFG] [tid: 19] [ecid: 0000JJlc4do76Empoos1yY1F5j62000004, 0] [SRC_CLASS: com.hyperion.config.wizard.impl.RunAllTasks] trace: running a custom task: register application servers / Clusters for product HFM
Any ideas? I am running Windows 2008R2 64 Bit Enterprise on all servers. Oracle 11.2.0.2 RDBMS.
Thank you
Mike
Published by: user2704998 on January 18, 2012 08:48Well, it really sounds like he can't connect then Firewall preventing. You have to find a way to turn them off because it is a sine qua non to disable firewall between servers to install Hyperion. I'm sorry.
Pablo
Maybe you are looking for
-
Error when you try to add the email account
I have a new Macbook Air and Mail showing the error "this account already exists" when trying to add my account. My email account does not appear in the accounts. What should I do? Thank you
-
I have a copy of the Safari icon on my desktop and the other in my application
El Capitan 10.11.5 I have a copy of the Safari icon on my desktop, and I have one in the Applications folder. If I try to put in the applications folder or in the trash, I get the message "Safari cannot be changed or deleted because it is required b
-
Why Thunderbird has recently begun asking my password for google contacts.
Why Thunderbird has recently begun asking my password for google contacts. Then when I type my password it will fail to recognize. Why?
-
After update my Pro iPad with iOS 9.3 iPad crashes on Safari. Example I googled something results appear, but I am not able to enter any page
-
Get rMBP 2013 ready for sale by installing El Capitan
I have a rMBP 2013 end I want to prepare for the sale. First of all, I want to completely erase the disk (partitions and all) with a new installation of El Capitan that same recovery option (R command) is El Capitan, and the system is fresh for the n