Why the current value of the index cache is 0 MB?
Everyone happy President's day!
I ran calc scripts on a BSO cube. I checked EAS and data Cache hit ratio and Index is 0.
I've already put key cache at 200 MB, but EE watch my current value hides index is 0 MB. Why?
I already have data cache to 300 MB, but EE shows that my current value of the data cache is 0 MB. Why?
I restarted my app BSO and db.
Thank you.
ORCLSendsMeToEarlyGrave wrote:
Our test server is on Exalytics. I wonder if this is why? All our BSO cubes have zero to Hit Ratio. Same Basic sample - after I ran Calc by default.
If it is Exalytics that shows zero for Hit Ratio then read through a recent post that relates to this - Hit ratio
See you soon
John
Tags: Business Intelligence
Similar Questions
-
Why the index are lost after recovering from a REPLICATE_PERSISTENT region?
GemFire Version V7.0.1.3 for region below specifications. java.lang.String com.foo.bar.Positon after recovery of the store persistent it is no markings on the region. All indexes are lost. CacheFactory cacheFactory = new CacheFactory(); cache = cacheFactory.create (); Ins ByteArrayInputStream = new ByteArrayInputStream (cachexmlstring); cache.loadCacheXml (ins);
OK I understood why the index get lost. Is that the way cache is initialized.
CacheFactory cacheFactory = new CacheFactory();
cache = cacheFactory.create (); Cache is created here without consideration of persistence pdx
Ins ByteArrayInputStream = new ByteArrayInputStream (cachexmlstring);
cache.loadCacheXml (ins); Now loading data it has no definition pdx index data.
So now even if I get the data loaded in the regions, when I probe through gfsh, there's no index.
I just changed the code of
FileOutputStream ops = new FileOutputStream ("cache.xml");
OPS. Write (cachexmlstring. GetBytes());
CacheFactory cacheFactory = new CacheFactory();
cache = cacheFactory.create ();
The indexes are coming fine...
-
Why the DNS cache would have entered negative when connecting?
Hello
Thanks in advance for reading this.
I have a problem when DNS cache contains negative entries to our Exchange Server, the file server / printing and even some among the domain controllers. I tried to completely flush the cache by using the ipconfig/flushdns command, and then view the result with the ipconfig/displaydns command which will leave only the local host entries. After that I have to reboot the machine, the negative entries are here once again and I cannot ping the servers exchange or print file. Nslookup works fine however and resolves names without problem. When I rinse again and then try clicking, it works for awhile but then the negative entries will appear again while I'm connected. What makes it more interesting, is that it is not always the same negative records that appear.
Things that did not help I tried:
1. rebuilt laptop client using a different material. This leads me to believe that this isn't related viruses/spyware since it happened immediately after setting a cell phone completely new with a new build of Windows XP.
2. added to ipconfig/flushdns to the logon script.Info about my environment:
1. we have all our servers in one location on the desktop, and all branches are connected via the VPN site-to site.
2 the client machine is added to the domain and is running Windows XP SP3.
3. this question is not present on the main site, only in branches.
4. the branches using Sonicwall TZ 200 units for DHCP.
5. it may be a coincidence, but this problem seems to have happened since we went from Sonicwall TZ 170 s to TZ 200
but I do not see how it would affect the cache.
6 I emptied the cache, and then more minutes late the negative entries will appear again even if pings worked a few minutes earlier. It doesn't seem to be a physical problem because my RDP session is never the problem while I'm troubleshooting.If anyone has any idea as to why negative cache entries will appear when the physical network is fine, and when nslookup is no problem to find the servers, I would be very grateful for your input.
Hi ethorneloe,
Since your question involves the use of Exchange Server please join the TechNet community for assistance. They specialize in THIS type of environment Pro and will be better suited to help you.
TechNet Forum
http://social.technet.Microsoft.com/forums/en-us/category/ExchangeServer/
-
Why the police Cache Service Windows won't start?
Cache of police service Windows will not start it is stuck at the start so I have to turn it off so that it does not use 25% cpu.
Windows 7 Home Premium 64-bit
I am aware that other users also have this problem.
Hi bmxjumperc,
Try running online virus scan and priority of service process in the Task Manager. To do this, try the following steps.
Step 1: Virus scanner online
a. visit http://onecare.live.com/site/en-us/center/whatsnew.htm
b. click "full service scan.
c. scan the computer and remove the infected files and check the result.Step 2: Change the priority of service process
a. right click on the task bar, click Start Task Manager.
b. click on the Services tab, right-click FontCache point and click on 'Go to address'
c. click right tab process, right click on the process, click on set the priority and click down.
d. click ok to apply the changes and check the result.Visit our Microsoft answers feedback Forum and let us know what you think.
-
Current value of the data cache 0
Hi all
The database I have is responsible, however, the CURRENT VALUE of the DATA CACHE, CURRENT VALUE of the INDEX CACHE, etc. show all 0.
What could be the reason why it shows 0?
He must have some numbers right?
Thank you
Is there a schema and data in the cube?
I'm a little surprised by the index cache data cache may not be transferable by any space until you do really something with the data of the cube (extract, load, calculate, etc.) but key cache seems to be filled immediately.
-
Strange - Inserts first slowly, then quickly after the index drop and recreate
Hello
I have a chart with lines more 1,250,000,000 on Oracle 11.1.0.7, Linux. He had 4 global index, not partitioned. Insertions in this table have been very slow - lots of db file sequential reads, each taking an average of 0,009 second (from tkprof) - not bad, but the overall performance was wrong - so I fell & re-create the primary key index (3 columns in this index) and permanently other 3 index. As a result, total number of db file sequential reads decreased about 4 times (I was expecting that - now, there is only 1, not 4 index) but not only that - the avarage db file sequential read time fell just 0.0014 second!
In further investigation, I found in the form of traces, that BEFORE the fall & recreate, each sequential reading of the db file has been reading completely different blocks ("random") and AFTER the fall & recreate, blocks accessed by db file sequential reads are almost successively ordered (which allows to obtain cached storage Bay, and I think it's why I get 0.0014 instead of 0.009)! My question is - HOW it HAPPENED? Why the index rebuild has helped so much? The index is fragmented? And perhaps helped PCTFREE 10%, which I've recreated the index with, and there is no index block is divided now (but will appear in the future)?
Important notes - the result set that I insert is and has always ordered columns of table KP index. FILESYSTEMIO_OPTIONS parameter is set to SETALL is not OS cache (I presume), which makes my reading faster (because I have Direct IO).
Here is an excerpt of the trace file (expected a single insert operation):
-> > FRONT:
WAITING #12: nam = 'db file sequential read' ela = 35089 file #= 15 block #= blocks 20534014 = 1 obj #= tim 64560 = 1294827907110090
WAITING #12: nam = 'db file sequential read' ela = 6434 file #= 15 block #= blocks 61512424 = 1 obj #= tim 64560 = 1294827907116799
WAITING #12: nam = 'db file sequential read' ela = 7961 file #= 15 block #= blocks 33775666 = 1 obj #= tim 64560 = 1294827907124874
WAITING #12: nam = 'db file sequential read' ela = 16681 file #= 15 block #= blocks 60785827 = 1 obj #= tim 64560 = 1294827907143821
WAITING #12: nam = 'db file sequential read' ela = 2380 file #= 15 block #= blocks 60785891 = 1 obj #= tim 64560 = 1294827907147000
WAITING #12: nam = 'db file sequential read' ela = 4219 file #= 15 block #= blocks 33775730 = 1 obj #= tim 64560 = 1294827907151553
WAITING #12: nam = 'db file sequential read' ela = 7218 file #= 15 block #= blocks 58351090 = 1 obj #= tim 64560 = 1294827907158922
WAITING #12: nam = 'db file sequential read' ela = 6140 file #= 15 block #= blocks 20919908 = 1 obj #= tim 64560 = 1294827907165194
WAITING #12: nam = ela 'db file sequential read' = 542 file #= 15 block #= blocks 60637720 = 1 obj #= tim 64560 = 1294827907165975
WAITING #12: nam = 'db file sequential read' ela = 13736 file #= 15 block #= blocks 33350753 = 1 obj #= tim 64560 = 1294827907179807
WAITING #12: nam = 'db file sequential read' ela = 57465 file #= 15 block #= blocks 59840995 = 1 obj #= tim 64560 = 1294827907237569
WAITING #12: nam = 'db file sequential read' ela = file No. 20077 = 15 block #= blocks 11266833 = 1 obj #= tim 64560 = 1294827907257879
WAITING #12: nam = 'db file sequential read' ela = 10642 file #= 15 block #= blocks 34506477 = 1 obj #= tim 64560 = 1294827907268867
WAITING #12: nam = 'db file sequential read' ela = 5393 file #= 15 block #= blocks 20919972 = 1 obj #= tim 64560 = 1294827907275227
WAITING #12: nam = 'db file sequential read' ela = 15308 file #= 15 block #= blocks 61602921 = 1 obj #= tim 64560 = 1294827907291203
WAITING #12: nam = 'db file sequential read' ela = 11228 file #= 15 block #= blocks 34032720 = 1 obj #= tim 64560 = 1294827907303261
WAITING #12: nam = 'db file sequential read' ela = 7885 file #= 15 block #= blocks 60785955 = 1 obj #= tim 64560 = 1294827907311867
WAITING #12: nam = 'db file sequential read' ela = 6652 file #= 15 block #= blocks 19778448 = 1 obj #= tim 64560 = 1294827907319158
WAITING #12: nam = 'db file sequential read' ela = 8735 file #= 15 block #= blocks 34634855 = 1 obj #= tim 64560 = 1294827907328770
WAITING #12: nam = 'db file sequential read' ela = 14235 file #= 15 block #= blocks 61411940 = 1 obj #= tim 64560 = 1294827907343804
WAITING #12: nam = 'db file sequential read' ela = 7173 file #= 15 block #= blocks 33350808 = 1 obj #= tim 64560 = 1294827907351214
WAITING #12: nam = 'db file sequential read' ela = 8033 file #= 15 block #= blocks 60493866 = 1 obj #= tim 64560 = 1294827907359424
WAITING #12: nam = 'db file sequential read' ela = 14654 file #= 15 block #= blocks 19004731 = 1 obj #= tim 64560 = 1294827907374257
WAITING #12: nam = 'db file sequential read' ela = 6116 file #= 15 block #= blocks 34565376 = 1 obj #= tim 64560 = 1294827907380647
WAITING #12: nam = 'db file sequential read' ela = 6203 file #= 15 block #= blocks 20920100 = 1 obj #= tim 64560 = 1294827907387054
WAITING #12: nam = 'db file sequential read' ela = 50627 file #= 15 block #= blocks 61602985 = 1 obj #= tim 64560 = 1294827907437838
WAITING #12: nam = 'db file sequential read' ela = 13752 file #= 15 block #= blocks 33351193 = 1 obj #= tim 64560 = 1294827907451875
WAITING #12: nam = 'db file sequential read' ela = 6883 file #= 15 block #= blocks 58686059 = 1 obj #= tim 64560 = 1294827907459551
WAITING #12: nam = 'db file sequential read' ela = file No. 13284 = 15 block #= blocks 19778511 = 1 obj #= tim 64560 = 1294827907473558
WAITING #12: nam = 'db file sequential read' ela = 16678 file #= 15 block #= blocks 34226211 = 1 obj #= tim 64560 = 1294827907493010
WAITING #12: nam = 'db file sequential read' ela = 9565 file #= 15 block #= blocks 61123267 = 1 obj #= tim 64560 = 1294827907507419
WAITING #12: nam = 'db file sequential read' ela = 6893 file #= 15 block #= blocks 20920164 = 1 obj #= tim 64560 = 1294827907515073
WAITING #12: nam = 'db file sequential read' ela = 9817 file #= 15 block #= blocks 61603049 = 1 obj #= tim 64560 = 1294827907525598
WAITING #12: nam = 'db file sequential read' ela = 4691 file #= 15 block #= blocks 33351248 = 1 obj #= tim 64560 = 1294827907530960
WAITING #12: nam = 'db file sequential read' ela = file No. 25983 = 15 block #= blocks 58351154 = 1 obj #= tim 64560 = 1294827907557661
WAITING #12: nam = 'db file sequential read' ela = 7402 file #= 15 block #= blocks 5096358 = 1 obj #= tim 64560 = 1294827907565927
WAITING #12: nam = 'db file sequential read' ela = 7964 file #= 15 block #= blocks 61603113 = 1 obj #= tim 64560 = 1294827907574570
WAITING #12: nam = 'db file sequential read' ela = 32776 file #= 15 block #= blocks 33549538 = 1 obj #= tim 64560 = 1294827907608063
WAITING #12: nam = 'db file sequential read' ela = 5674 file #= 15 block #= blocks 60493930 = 1 obj #= tim 64560 = 1294827907614596
WAITING #12: nam = 'db file sequential read' ela = 9525 file #= 15 block #= blocks 61512488 = 1 obj #= tim 64560 = 1294827907625007
WAITING #12: nam = 'db file sequential read' ela = 15729 file #= 15 block #= blocks 33549602 = 1 obj #= tim 64560 = 1294827907641538
WAITING #12: nam = 'db file sequential read' ela = file No. 11510 = 15 block #= blocks 60902458 = 1 obj #= tim 64560 = 1294827907653819
WAITING #12: nam = 'db file sequential read' ela = 26431 files #= 15 block #= blocks 59841058 = 1 obj #= tim 64560 = 1294827907680940
WAITING #12: nam = 'db file sequential read' ela = 9196 file #= 15 block #= blocks 33350809 = 1 obj #= tim 64560 = 1294827907690434
WAITING #12: nam = 'db file sequential read' ela = 7745 file #= 15 block #= blocks 60296291 = 1 obj #= tim 64560 = 1294827907698353
WAITING #12: nam = 'db file sequential read' ela = 429 file #= 15 block #= blocks 61603177 = 1 obj #= tim 64560 = 1294827907698953
WAITING #12: nam = 'db file sequential read' ela = 8459 file #= 15 block #= blocks 33351194 = 1 obj #= tim 64560 = 1294827907707695
WAITING #12: nam = 'db file sequential read' ela = 25998 file #= 15 block #= blocks 49598412 = 1 obj #= tim 64560 = 1294827907733890
2011-01-12 11:25:07.742
WAITING #12: nam = 'db file sequential read' ela = 7988 file #= 15 block #= blocks 11357900 = 1 obj #= tim 64560 = 1294827907742683
WAITING #12: nam = 'db file sequential read' ela = 10066 file #= 15 block #= blocks 61512552 = 1 obj #= tim 64560 = 1294827907753540
WAITING #12: nam = 'db file sequential read' ela = 8400 file #= 15 block #= blocks 33775858 = 1 obj #= tim 64560 = 1294827907762668
WAITING #12: nam = 'db file sequential read' ela = 11750 file #= 15 block #= blocks 60636761 = 1 obj #= tim 64560 = 1294827907774667
WAITING #12: nam = 'db file sequential read' ela = 16933 file #= 15 block #= blocks 20533183 = 1 obj #= tim 64560 = 1294827907791839
WAITING #12: nam = 'db file sequential read' ela = 8895 file #= 15 block #= blocks 61603241 = 1 obj #= tim 64560 = 1294827907801047
WAITING #12: nam = 'db file sequential read' ela = file No. 12685 = 15 block #= blocks 33775922 = 1 obj #= tim 64560 = 1294827907813913
WAITING #12: nam = 'db file sequential read' ela = file No. 12664 = 15 block #= blocks 60493994 = 1 obj #= tim 64560 = 1294827907827379
WAITING #12: nam = 'db file sequential read' ela = 8271 file #= 15 block #= blocks 19372356 = 1 obj #= tim 64560 = 1294827907835881
WAITING #12: nam = 'db file sequential read' ela = file No. 10825 = 15 block #= blocks 59338524 = 1 obj #= tim 64560 = 1294827907847439
WAITING #12: nam = 'db file sequential read' ela = 13086 file #= 15 block #= blocks 49440992 = 1 obj #= tim 64793 = 1294827907862022
WAITING #12: nam = 'db file sequential read' ela = file No. 16491 = 15 block #= blocks 32853984 = 1 obj #= tim 64793 = 1294827907879282
WAITING #12: nam = 'db file sequential read' ela = 9349 file #= 15 block #= blocks 60133021 = 1 obj #= tim 64793 = 1294827907888849
WAITING #12: nam = 'db file sequential read' ela = 5680 files #= 15 block #= blocks 20370585 = 1 obj #= tim 64793 = 1294827907895281
WAITING #12: nam = 'db file sequential read' ela = 34021 file #= 15 block #= blocks 58183834 = 1 obj #= tim 64793 = 1294827907930014
WAITING #12: nam = 'db file sequential read' ela = 8574 file #= 15 block #= blocks 32179028 = 1 obj #= tim 64793 = 1294827907938813
WAITING #12: nam = 'db file sequential read' ela = file No. 10862 = 15 block #= blocks 49402735 = 1 obj #= tim 64793 = 1294827907949821
WAITING #12: nam = 'db file sequential read' ela = 4501 file #= 15 block #= blocks 11270933 = 1 obj #= tim 64793 = 1294827907954533
WAITING #12: nam = 'db file sequential read' ela = 9936 file #= 15 block #= blocks 61007523 = 1 obj #= tim 64793 = 1294827907964616
WAITING #12: nam = 'db file sequential read' ela = 7631 file #= 15 block #= blocks 34399970 = 1 obj #= tim 64793 = 1294827907972457
WAITING #12: nam = 'db file sequential read' ela = 6162 file #= 15 block #= blocks 60305187 = 1 obj #= tim 64793 = 1294827907978797
WAITING #12: nam = 'db file sequential read' ela = 8555 file #= 15 block #= blocks 20912586 = 1 obj #= tim 64793 = 1294827907987532
WAITING #12: nam = 'db file sequential read' ela = 9499 file #= 15 block #= blocks 61007587 = 1 obj #= tim 64793 = 1294827907997296
WAITING #12: nam = 'db file sequential read' ela = 23690 file #= 15 block #= blocks 19769014 = 1 obj #= tim 64793 = 1294827908024105
WAITING #12: nam = 'db file sequential read' ela = 7081 file #= 15 block #= blocks 61314072 = 1 obj #= tim 64793 = 1294827908031968
WAITING #12: nam = 'db file sequential read' ela = 31727 file #= 15 block #= blocks 34026602 = 1 obj #= tim 64793 = 1294827908063914
WAITING #12: nam = 'db file sequential read' ela = 4932 file #= 15 block #= blocks 60905313 = 1 obj #= tim 64793 = 1294827908069052
WAITING #12: nam = 'db file sequential read' ela = 6616 file #= 15 block #= blocks 20912650 = 1 obj #= tim 64793 = 1294827908075835
WAITING #12: nam = 'db file sequential read' ela = 8443 file #= 15 block #= blocks 33781968 = 1 obj #= tim 64793 = 1294827908084594
WAITING #12: nam = 'db file sequential read' ela = 22291 file #= 15 block #= blocks 60641967 = 1 obj #= tim 64793 = 1294827908107052
WAITING #12: nam = 'db file sequential read' ela = 6610 file #= 15 block #= blocks 18991774 = 1 obj #= tim 64793 = 1294827908113879
WAITING #12: nam = 'db file sequential read' ela = 6493 file #= 15 block #= blocks 34622382 = 1 obj #= tim 64793 = 1294827908120535
WAITING #12: nam = 'db file sequential read' ela = 5028 file #= 15 block #= blocks 20912714 = 1 obj #= tim 64793 = 1294827908125861
WAITING #12: nam = 'db file sequential read' ela = file No. 11834 = 15 block #= blocks 61679845 = 1 obj #= tim 64793 = 1294827908137858
WAITING #12: nam = 'db file sequential read' ela = 4261 file #= 15 block #= blocks 34498166 = 1 obj #= tim 64793 = 1294827908142305
WAITING #12: nam = 'db file sequential read' ela = 19267 file #= 15 block #= blocks 60905377 = 1 obj #= tim 64793 = 1294827908161695
WAITING #12: nam = 'db file sequential read' ela = file No. 14108 = 15 block #= blocks 19769078 = 1 obj #= tim 64793 = 1294827908176046
WAITING #12: nam = 'db file sequential read' ela = 4128 file #= 15 block #= blocks 33781465 = 1 obj #= tim 64793 = 1294827908180396
WAITING #12: nam = 'db file sequential read' ela = 9986 file #= 15 block #= blocks 61007651 = 1 obj #= tim 64793 = 1294827908190535
WAITING #12: nam = 'db file sequential read' ela = 8907 file #= 15 block #= blocks 20912778 = 1 obj #= tim 64793 = 1294827908199614
WAITING #12: nam = 'db file sequential read' ela = 12023 file #= 15 block #= blocks 34230838 = 1 obj #= tim 64793 = 1294827908211852
WAITING #12: nam = 'db file sequential read' ela = 29837 file #= 15 block #= blocks 60905441 = 1 obj #= tim 64793 = 1294827908241853
WAITING #12: nam = 'db file sequential read' ela = 5989 file #= 15 block #= blocks 60133085 = 1 obj #= tim 64793 = 1294827908248065
WAITING #12: nam = 'db file sequential read' ela = 74172 file #= 15 block #= blocks 33357369 = 1 obj #= tim 64793 = 1294827908322391
WAITING #12: nam = 'db file sequential read' ela = 5443 file #= 15 block #= blocks 60498917 = 1 obj #= tim 64793 = 1294827908328064
WAITING #12: nam = 'db file sequential read' ela = 4645 file #= 15 block #= blocks 20912842 = 1 obj #= tim 64793 = 1294827908332912
WAITING #12: nam = 'db file sequential read' ela = file No. 13595 = 15 block #= blocks 61679909 = 1 obj #= tim 64793 = 1294827908346618
WAITING #12: nam = 'db file sequential read' ela = 9120 file #= 15 block #= blocks 58356376 = 1 obj #= tim 64793 = 1294827908355975
WAITING #12: nam = 'db file sequential read' ela = 3186 file #= 15 block #= blocks 19385867 = 1 obj #= tim 64793 = 1294827908359374
WAITING #12: nam = 'db file sequential read' ela = 5114 file #= 15 block #= blocks 61589533 = 1 obj #= tim 64793 = 1294827908364630
WAITING #12: nam = 'db file sequential read' ela = 42263 file #= 15 block #= blocks 33356474 = 1 obj #= tim 64793 = 1294827908407045
WAITING #12: nam = 'db file sequential read' ela = 10683 file #= 15 block #= blocks 58183898 = 1 obj #= tim 64793 = 1294827908417994
WAITING #12: nam = 'db file sequential read' ela = file No. 10284 = 15 block #= blocks 20529486 = 1 obj #= tim 64793 = 1294827908429134
WAITING #12: nam = 'db file sequential read' ela = file No. 12544 = 15 block #= blocks 60498981 = 1 obj #= tim 64793 = 1294827908441945
WAITING #12: nam = 'db file sequential read' ela = 8311 file #= 15 block #= blocks 33191548 = 1 obj #= tim 64793 = 1294827908451011
WAITING #12: nam = 'db file sequential read' ela = 4261 file #= 15 block #= blocks 59083610 = 1 obj #= tim 64793 = 1294827908455902
WAITING #12: nam = 'db file sequential read' ela = 4653 file #= 15 block #= blocks 18991837 = 1 obj #= tim 64793 = 1294827908461264
WAITING #12: nam = 'db file sequential read' ela = 4905 file #= 15 block #= blocks 34685472 = 1 obj #= tim 64793 = 1294827908466897
WAITING #12: nam = 'db file sequential read' ela = file No. 12360 = 15 block #= blocks 61775403 = 1 obj #= tim 64793 = 1294827908480080
WAITING #12: nam = 'db file sequential read' ela = 6956 file #= 15 block #= blocks 58921225 = 1 obj #= tim 64793 = 1294827908487704
WAITING #12: nam = 'db file sequential read' ela = 6068 file #= 15 block #= blocks 19769142 = 1 obj #= tim 64793 = 1294827908494608
WAITING #12: nam = 'db file sequential read' ela = 5249 file #= 15 block #= blocks 33781528 = 1 obj #= tim 64793 = 1294827908500666
WAITING #12: nam = 'db file sequential read' ela = 6013 file #= 15 block #= blocks 60905505 = 1 obj #= tim 64793 = 1294827908507366
WAITING #12: nam = 'db file sequential read' ela = 3014 file #= 15 block #= blocks 20912970 = 1 obj #= tim 64793 = 1294827908511019
WAITING #12: nam = 'db file sequential read' ela = 3636 file #= 15 block #= blocks 33781591 = 1 obj #= tim 64793 = 1294827908515425
WAITING #12: nam = 'db file sequential read' ela = file No. 12226 = 15 block #= blocks 58183962 = 1 obj #= tim 64793 = 1294827908528268
WAITING #12: nam = 'db file sequential read' ela = 7635 file #= 15 block #= blocks 60499173 = 1 obj #= tim 64793 = 1294827908536613
WAITING #12: nam = 'db file sequential read' ela = 7364 file #= 15 block #= blocks 11270996 = 1 obj #= tim 64793 = 1294827908544203
WAITING #12: nam = 'db file sequential read' ela = 5452 file #= 15 block #= blocks 34622446 = 1 obj #= tim 64793 = 1294827908550475
WAITING #12: nam = 'db file sequential read' ela = 9734 file #= 15 block #= blocks 20913034 = 1 obj #= tim 64793 = 1294827908561029
WAITING #12: nam = 'db file sequential read' ela = 14077 file #= 15 block #= blocks 61679973 = 1 obj #= tim 64793 = 1294827908575440
WAITING #12: nam = 'db file sequential read' ela = 9694 file #= 15 block #= blocks 34550681 = 1 obj #= tim 64793 = 1294827908585311
WAITING #12: nam = 'db file sequential read' ela = 6753 file #= 15 block #= blocks 61007715 = 1 obj #= tim 64793 = 1294827908592228
WAITING #12: nam = 'db file sequential read' ela = 12577 file #= 15 block #= blocks 19769206 = 1 obj #= tim 64793 = 1294827908604943
WAITING #12: nam = 'db file sequential read' ela = file No. 609 = 15 block #= blocks 61589534 = 1 obj #= tim 64793 = 1294827908605735
WAITING #12: nam = 'db file sequential read' ela = 6267 file #= 15 block #= blocks 33356538 = 1 obj #= tim 64793 = 1294827908612148
WAITING #12: nam = 'db file sequential read' ela = 7876 file #= 15 block #= blocks 58184026 = 1 obj #= tim 64793 = 1294827908620164
WAITING #12: nam = 'db file sequential read' ela = file No. 14058 = 15 block #= blocks 32767835 = 1 obj #= tim 80883 = 1294827908634546
WAITING #12: nam = 'db file sequential read' ela = 9798 file #= 15 block #= blocks 58504373 = 1 obj #= tim 80883 = 1294827908644575
WAITING #12: nam = 'db file sequential read' ela = 11081 file #= 15 block #= blocks 11118811 = 1 obj #= tim 80883 = 1294827908655908
WAITING #12: nam = 'db file sequential read' ela = 6249 file #= 15 block #= blocks 58087798 = 1 obj #= tim 80883 = 1294827908662451
WAITING #12: nam = 'db file sequential read' ela = 9513 file #= 15 block #= blocks 33331129 = 1 obj #= tim 80883 = 1294827908672904
WAITING #12: nam = 'db file sequential read' ela = 4648 file #= 15 block #= blocks 60301818 = 1 obj #= tim 80883 = 1294827908677736
WAITING #12: nam = 'db file sequential read' ela = 6147 file #= 15 block #= blocks 20523119 = 1 obj #= tim 80883 = 1294827908684075
WAITING #12: nam = 'db file sequential read' ela = file No. 59531 = 15 block #= blocks 61016570 = 1 obj #= tim 80883 = 1294827908743795
2011-01-12 11:25:08.752
WAITING #12: nam = 'db file sequential read' ela = 8787 file #= 15 block #= blocks 33770842 = 1 obj #= tim 80883 = 1294827908752846
WAITING #12: nam = 'db file sequential read' ela = 9858 file #= 15 block #= blocks 60895354 = 1 obj #= tim 80883 = 1294827908762960
WAITING #12: nam = 'db file sequential read' ela = 11237 file #= 15 block #= blocks 19369506 = 1 obj #= tim 80883 = 1294827908775138
WAITING #12: nam = 'db file sequential read' ela = 5838 file #= 15 block #= blocks 34229712 = 1 obj #= tim 80883 = 1294827908782100
WAITING #12: nam = 'db file sequential read' ela = 6518 file #= 15 block #= blocks 61221772 = 1 obj #= tim 80883 = 1294827908789403
WAITING #12: nam = 'db file sequential read' ela = 9946 file #= 15 block #= blocks 20523183 = 1 obj #= tim 80883 = 1294827908800089
WAITING #12: nam = 'db file sequential read' ela = 16699 file #= 15 block #= blocks 61016634 = 1 obj #= tim 80883 = 1294827908817077
WAITING #12: nam = 'db file sequential read' ela = file No. 15215 = 15 block #= blocks 33770900 = 1 obj #= tim 80883 = 1294827908832934
WAITING #12: nam = 'db file sequential read' ela = 8403 file #= 15 block #= blocks 60895418 = 1 obj #= tim 80883 = 1294827908842317
WAITING #12: nam = 'db file sequential read' ela = 8927 file #= 15 block #= blocks 18950791 = 1 obj #= tim 80883 = 1294827908852190
WAITING #12: nam = 'db file sequential read' ela = 4382 files #= 15 block #= blocks 34493493 = 1 obj #= tim 80883 = 1294827908856821
WAITING #12: nam = 'db file sequential read' ela = 9356 file #= 15 block #= blocks 61324964 = 1 obj #= tim 80883 = 1294827908866337
WAITING #12: nam = 'db file sequential read' ela = 10575 file #= 15 block #= blocks 20883018 = 1 obj #= tim 80883 = 1294827908877102
WAITING #12: nam = 'db file sequential read' ela = 16601 file #= 15 block #= blocks 60502307 = 1 obj #= tim 80883 = 1294827908893926
WAITING #12: nam = 'db file sequential read' ela = 5236 file #= 15 block #= blocks 33331193 = 1 obj #= tim 80883 = 1294827908899387
WAITING #12: nam = 'db file sequential read' ela = 9981 file #= 15 block #= blocks 59830076 = 1 obj #= tim 80883 = 1294827908910427
WAITING #12: nam = 'db file sequential read' ela = 8100 file #= 15 block #= blocks 19767805 = 1 obj #= tim 80883 = 1294827908918751
WAITING #12: nam = 'db file sequential read' ela = 12492 file #= 15 block #= blocks 67133332 = 1 obj #= tim 80883 = 1294827908931732
WAITING #12: nam = 'db file sequential read' ela = 5876 file #= 15 block #= blocks 34229775 = 1 obj #= tim 80883 = 1294827908937859
WAITING #12: nam = 'db file sequential read' ela = 8741 file #= 15 block #= blocks 61408244 = 1 obj #= tim 80883 = 1294827908948439
WAITING #12: nam = 'db file sequential read' ela = 8477 file #= 15 block #= blocks 20523247 = 1 obj #= tim 80883 = 1294827908957099
WAITING #12: nam = 'db file sequential read' ela = 7947 file #= 15 block #= blocks 61016698 = 1 obj #= tim 80883 = 1294827908965210
WAITING #12: nam = 'db file sequential read' ela = 2384 file #= 15 block #= blocks 33331257 = 1 obj #= tim 80883 = 1294827908967773
WAITING #12: nam = 'db file sequential read' ela = 3585 file #= 15 block #= blocks 59571985 = 1 obj #= tim 80883 = 1294827908971564
WAITING #12: nam = 'db file sequential read' ela = 7753 file #= 15 block #= blocks 5099571 = 1 obj #= tim 80883 = 1294827908979647
WAITING #12: nam = 'db file sequential read' ela = 8205 file #= 15 block #= blocks 61408308 = 1 obj #= tim 80883 = 1294827908988200
WAITING #12: nam = 'db file sequential read' ela = 7745 file #= 15 block #= blocks 34229335 = 1 obj #= tim 80883 = 1294827908996129
WAITING #12: nam = 'db file sequential read' ela = file No. 10942 = 15 block #= blocks 61325028 = 1 obj #= tim 80883 = 1294827909007244
WAITING #12: nam = 'db file sequential read' ela = 6247 file #= 15 block #= blocks 20523311 = 1 obj #= tim 80883 = 1294827909013706
WAITING #12: nam = 'db file sequential read' ela = file No. 16188 = 15 block #= blocks 60777362 = 1 obj #= tim 80883 = 1294827909030088
WAITING #12: nam = 'db file sequential read' ela = file No. 16642 = 15 block #= blocks 33528224 = 1 obj #= tim 80883 = 1294827909046971
WAITING #12: nam = 'db file sequential read' ela = file No. 10118 = 15 block #= blocks 60128498 = 1 obj #= tim 80883 = 1294827909057402
WAITING #12: nam = 'db file sequential read' ela = file No. 10747 = 15 block #= blocks 802317 = 1 obj #= tim 64495 = 1294827909069165
WAITING #12: nam = 'db file sequential read' ela = 4795 file number = 15 block #= blocks 33079541 = 1 obj #= tim 64560 = 1294827909074367
WAITING #12: nam = 'db file sequential read' ela = 6822 file #= 15 block #= blocks 20913098 = 1 obj #= tim 64793 = 1294827909081436
WAITING #12: nam = 'db file sequential read' ela = file No. 10932 = 15 block #= blocks 19369570 = 1 obj #= tim 80883 = 1294827909092607
--> > AFTER:
WAITING #23: nam = 'db file sequential read' ela = 16367 file #= 15 block #= blocks 70434065 = 1 obj #= tim 115059 = 1295342220878947
WAITING #23: nam = 'db file sequential read' ela = 1141 file #= 15 block #= blocks 70434066 = 1 obj #= tim 115059 = 1295342220880549
WAITING #23: nam = 'db file sequential read' ela = 456 file #= 15 block #= blocks 70434067 = 1 obj #= tim 115059 = 1295342220881615
WAITING #23: nam = 'db file sequential read' ela = 689 file #= 15 block #= blocks 70434068 = 1 obj #= tim 115059 = 1295342220882617
WAITING #23: nam = 'db file sequential read' ela = 495 file #= 15 block #= blocks 70434069 = 1 obj #= tim 115059 = 1295342220883482
WAITING #23: nam = 'db file sequential read' ela = 419 file #= 15 block #= blocks 70434070 = 1 obj #= tim 115059 = 1295342220884195
WAITING #23: nam = 'db file sequential read' ela = 149 file #= 15 block #= blocks 70434071 = 1 obj #= tim 115059 = 1295342220884629
WAITING #23: nam = 'db file sequential read' ela = 161 file #= 15 block #= blocks 70434072 = 1 obj #= tim 115059 = 1295342220885085
WAITING #23: nam = 'db file sequential read' ela = 146 file #= 15 block #= blocks 70434073 = 1 obj #= tim 115059 = 1295342220885533
WAITING #23: nam = ela 'db file sequential read' = 188 file #= 15 block #= blocks 70434074 = 1 obj #= tim 115059 = 1295342220886026
WAITING #23: nam = 'db file sequential read' ela = 181 file #= 15 block #= blocks 70434075 = 1 obj #= tim 115059 = 1295342220886498
WAITING #23: nam = 'db file sequential read' ela = 303 file #= 15 block #= blocks 70434076 = 1 obj #= tim 115059 = 1295342220887082
WAITING #23: nam = 'db file sequential read' ela = file No. 550 = 15 block #= blocks 70434077 = 1 obj #= tim 115059 = 1295342220887916
WAITING #23: nam = 'db file sequential read' ela = 163 file #= 15 block #= blocks 70434078 = 1 obj #= tim 115059 = 1295342220888402
WAITING #23: nam = 'db file sequential read' ela = 200 file #= 15 block #= blocks 70434079 = 1 obj #= tim 115059 = 1295342220888980
WAITING #23: nam = 'db file sequential read' ela = 134 file #= 15 block #= blocks 70434080 = 1 obj #= tim 115059 = 1295342220889409
WAITING #23: nam = 'db file sequential read' ela = 157 file #= 15 block #= blocks 70434081 = 1 obj #= tim 115059 = 1295342220889850
WAITING #23: nam = 'db file sequential read' ela = 5112 file #= 15 block #= blocks 70434540 = 1 obj #= tim 115059 = 1295342220895272
WAITING #23: nam = 'db file sequential read' ela = 276 file #= 15 block #= blocks 70434082 = 1 obj #= tim 115059 = 1295342220895640
2011-01-18 10:17:00.898
WAITING #23: nam = 'db file sequential read' ela = 2936 file #= 15 block #= blocks 70434084 = 1 obj #= tim 115059 = 1295342220898921
WAITING #23: nam = 'db file sequential read' ela = 1843 file number = 15 block #= blocks 70434085 = 1 obj #= tim 115059 = 1295342220901233
WAITING #23: nam = 'db file sequential read' ela = 452 file #= 15 block #= blocks 70434086 = 1 obj #= tim 115059 = 1295342220902050
WAITING #23: nam = 'db file sequential read' ela = 686 file #= 15 block #= blocks 70434087 = 1 obj #= tim 115059 = 1295342220903031
WAITING #23: nam = 'db file sequential read' ela = 1582 file #= 15 block #= blocks 70434088 = 1 obj #= tim 115059 = 1295342220904933
WAITING #23: nam = 'db file sequential read' ela = 179 file #= 15 block #= blocks 70434089 = 1 obj #= tim 115059 = 1295342220905544
WAITING #23: nam = 'db file sequential read' ela = 426 file #= 15 block #= blocks 70434090 = 1 obj #= tim 115059 = 1295342220906303
WAITING #23: nam = 'db file sequential read' ela = 138 file #= 15 block #= blocks 70434091 = 1 obj #= tim 115059 = 1295342220906723
WAITING #23: nam = 'db file sequential read' ela = 3004 file #= 15 block #= blocks 70434092 = 1 obj #= tim 115059 = 1295342220910053
WAITING #23: nam = 'db file sequential read' ela = 331 file #= 15 block #= blocks 70434093 = 1 obj #= tim 115059 = 1295342220910765
WAITING #23: nam = 'db file sequential read' ela = 148 file #= 15 block #= blocks 70434094 = 1 obj #= tim 115059 = 1295342220911236
WAITING #23: nam = 'db file sequential read' ela = 296 file #= 15 block #= blocks 70434095 = 1 obj #= tim 115059 = 1295342220911836
WAITING #23: nam = 'db file sequential read' ela = 441 file #= 15 block #= blocks 70434096 = 1 obj #= tim 115059 = 1295342220912581
WAITING #23: nam = 'db file sequential read' ela = 157 file #= 15 block #= blocks 70434097 = 1 obj #= tim 115059 = 1295342220913038
WAITING #23: nam = 'db file sequential read' ela = 281 file #= 15 block #= blocks 70434098 = 1 obj #= tim 115059 = 1295342220913603
WAITING #23: nam = 'db file sequential read' ela = file No. 150 = 15 block #= blocks 70434099 = 1 obj #= tim 115059 = 1295342220914048
WAITING #23: nam = 'db file sequential read' ela = 143 file #= 15 block #= blocks 70434100 = 1 obj #= tim 115059 = 1295342220914498
WAITING #23: nam = 'db file sequential read' ela = 384 file #= 15 block #= blocks 70434101 = 1 obj #= tim 115059 = 1295342220916907
WAITING #23: nam = 'db file sequential read' ela = file No. 164 = 15 block #= blocks 70434102 = 1 obj #= tim 115059 = 1295342220917458
WAITING #23: nam = 'db file sequential read' ela = 218 file #= 15 block #= blocks 70434103 = 1 obj #= tim 115059 = 1295342220917962
WAITING #23: nam = 'db file sequential read' ela = file No. 450 = 15 block #= blocks 70434104 = 1 obj #= tim 115059 = 1295342220918698
WAITING #23: nam = 'db file sequential read' ela = file No. 164 = 15 block #= blocks 70434105 = 1 obj #= tim 115059 = 1295342220919159
WAITING #23: nam = 'db file sequential read' ela = 136 file #= 15 block #= blocks 70434106 = 1 obj #= tim 115059 = 1295342220919598
WAITING #23: nam = 'db file sequential read' ela = 143 file #= 15 block #= blocks 70434107 = 1 obj #= tim 115059 = 1295342220920041
WAITING #23: nam = 'db file sequential read' ela = 3091 file #= 15 block #= blocks 70434108 = 1 obj #= tim 115059 = 1295342220925409user12196647 wrote:
Hemant, Jonathan - thanks for the comprehensive replies. To summarize:It's the 11.1 (11.1.0.7) database on 64-bit Linux. No compression is used for everything, all the blocks are 16 k tablespaces are SAMS created with attributes EXTENT MANAGEMENT LOCAL AUTOALLOCATE SEGMENT SPACE MANAGEMENT AUTO BIGFILE tablespaces (separate for tables and separate for the index tablespace). I do not have to rebuild the indexes of PK, but abandoned all indexes, and then recreated the KP (but it's okay - reconstruction is still that let down & create, isn't it?).
Traces were made during the pl/sql loop forall was actually insert. Each pl/sql forall loop inserts 100 lines "at once" (we use fetch bulk collect limit 100), but the loading process inserts a few million records (pl/sql forall loop is closed :)). I stuck that part of traces - wait events for 100 (a set of) 'before' 100 'after' inserts and inserts. Wait for events to another inserts look exacly the same - always blocks 'random' in 'before the index recreate' inserts and inserts almost ordained blocks in "after the index recreate." The objects_ids were certainly indexes.
I think that the explanation of Hemant is correct. The point is, my structure of the index is of (X, Y, DATE), where X and are 99% repeating at each loading data, values and DATE is increased by one for each data load. Because I'm always insert ordered by PK, for loading a new DATE, I visit each index leaf block, in order, as in the analysis of comprehensive index. Because I'm inserted in each block sheet in every load, I have many index block splits. Which caused my pads of sheets to be physically non-contiguous after awhile. Reconstruction has been my healing...
You got your answer before I had time to finish a model of your data set - but I think you're description is fairly accurate.
A few thoughts if:WAITING #12: nam = 'db file sequential read' ela = file No. 10747 = 15 block #= blocks 802317 = 1 obj #= tim 64495 = 1294827909069165
WAITING #12: nam = 'db file sequential read' ela = 4795 file number = 15 block #= blocks 33079541 = 1 obj #= tim 64560 = 1294827909074367
WAITING #12: nam = 'db file sequential read' ela = 6822 file #= 15 block #= blocks 20913098 = 1 obj #= tim 64793 = 1294827909081436
WAITING #12: nam = 'db file sequential read' ela = file No. 10932 = 15 block #= blocks 19369570 = 1 obj #= tim 80883 = 1294827909092607Unless you missed a bit when your trace file copying, the index with the id of the object 64495 has not subject to drive the way readings which the other clues were. It would be nice to know why. There are two "obvious" possibilities - (a) it has been very well buffered or (b) there is an index where almost all the entries are zero, so it is rarely changed. Because it has the object id lowest of all indexes, it is possible that it is the primary key index (but I don't because I tend to create the primary key of a table before I create any index) and if this is correct your waste of time was not on the primary key index, and perhaps he tends to be very well buffered the nature of popular queries.
Changes in performance when inserting millions of lines tend to be non-linear as the number of indexes grow.
As you insert data in the primary key order draw you maximum benefits caching for insertions in the KP index. And since you insert a very large number of lines - the order of 0.5% - 1% of the current lines, in light of your comment 'millions' - you're likely to insert two or three lines in each block of the pharmacokinetics of the index (by the way it must compress on the first two columns)) allowing Oracle to optimize its work in several ways.
But for the other clues you are probably very randomly jump to insert rows, and this led to two different effects:
You must keep N times as many blocks in the buffer to get similar read benefits
each insertion in the index non-PK blocks is likely to be a row insert - which maximise cancel it and redo overhead more undo and redo written
each insertion in an index block finally requires the block to write on the disc - which means more i/o, which slows down the readings
as you read blocks (and you have read several of them) you can force the Oracle to write and other index blocks that need to be reviewed to equal.
It is perfectly possible that almost all of your performance gain comes to drop the three indexes, and only a relatively small fraction come to rebuild the primary key.
One final thought of block shares. I think that you have found an advantage any readahead (non-Oracle) when the index blocks are classified physically, if you have a trade-off between how many times you rebuild to this advantage and to find a time during which you can afford the resources to rebuild. If you want the best compromise (a) don't forget the compression option - it seems appropriate, (b) consider the benefits of partitioning range date - it seems very appropriate in your case, and (c) by varying the PCTFREE when you rebuild the index you can assign the number of insert cycles before the effects of the splits of block of sheets have a significant impact on the randomness of the IO.
I have an idea-if I changed the index structure to (DATE, X, Y) then I would always insert in block leaves more right side, I'd have 90-10 splits instead of 50 / 50 splits and leafs would be physically contiguous, so any necessary new buildings - am I right?
You cannot change the order of index column until you check the use of the index. If the most important and most frequent queries are "select table where colx = X and coly = O and date_col between A and B", you must index this round way. (In fact, you can look at the possibility of using a range partiitoned index organized table for data).
Concerning
Jonathan Lewis -
Spfile/init.ora file parameter exists to force the CBO to do the path of execution of a given statement, use an index, even if the index scan may seem to be calculated in the form of more expensive?
883532 wrote:
Spfile/init.ora file parameter exists to force the CBO to do the path of execution of a given statement, use an index, even if the index scan may seem to be calculated in the form of more expensive?It's not a good idea to change any parameter to force using the index, because changing the system can degrade the performance of the entire base.
So you should stick to as much as possible the default values.However if you want your session with force scan restricted index to table scan the following parameter can be set to make cheap scan index. First parameter i.e. optimizer_index_cost_adj is considered when cacculating table scan vs. index scan and to lower the value would increase the cost of the limited index scan.
OPTIMIZER_INDEX_COST_ADJ (set it low, that is to say less than the 100)
optimizer_mode (all is first_rows)
optimizer_index_caching (increase from 0 to 100)
db_file_multiblock_read_count (decrease of current value)
Use as Index indicator / * + index (table_name, index) * /.
Please note that these setting should never tested on at the level of the system otherwise, there may be a performance impact. -
How to interpret the data cache setting and the current value of data cache?
How to interpret the data cache setting and the current value of data cache? We found that even, we configure a larger data cache in Essbase 2 GB for example, the current value of the data cache is always much lower. Does that indicate an activities of data at very low recovery or something else?
Thanks in advance!Hello
When a block is requested, Essbase searches the data for the block cache. If Essbase is the block in the cache, it is immediately accessible. If the block is not found in the cache, Essbase in the index for the appropriate block number and then uses the index of the block entry to retrieve from the data on the disk file. Retrieve a block requested in the data cache is faster and therefore improves performance.
So as you say that its current value is much lower then % is very low, that a requested block is in the cache of Essbase data.
Hope that respond you to the.
Atul K
-
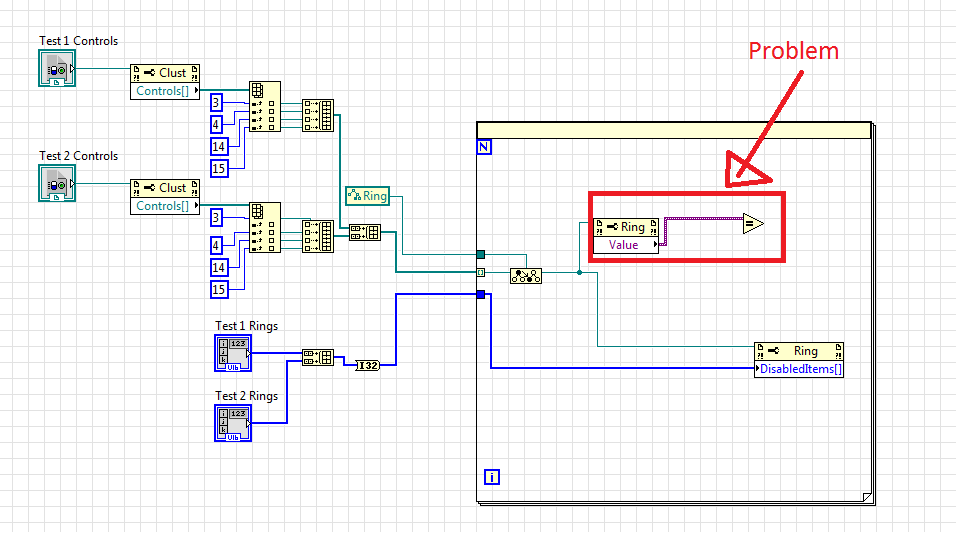
Get the current value of the menu a cluster ring
Hello
I am trying to program a bunch of rings of menu to use the same options and disable the option even in the other rings of menu if it has already been chosen. It works essentially as is at the moment, but it shows each button by using a 'deactivated' option because I'm turning off the option even in the buttons that have this value. I did it using a loop knot and property and [] DisabledItems en mass. Now, I want to go to the iteration of the loop for the menu ring which already has this value.
To do this however, I want to get the current numeric value of the ring of menu and an array of search values. If the value of menu rings appear in this table, then I want to move to the current iteration of the loop. The problem I have is that when I try to use a property node and type the property value, instead of giving me a long 32 output, it gives me the so-called 'Variant', which I have not seen before. I'm not sure how to find a table and see if the value I have is in this table. "Search table" seems just an index to be returned, I think that I want a Boolean or something. I'm also not sure how to skip an iteration of the loop (although I imagine it won't be too difficult to understand mine, I hope).
I apologize if this is very obvious, or if my message is not clear. I started using LabVIEW, a few weeks ago and I'm still learning. I have included a picture of my Subvi downstairs.
Thank you
NathanVariant of data allows to convert the variant to a numeric type (whatever representation you need).
Search D 1 table returns-1 if the element was not found. If you just compare the index with a greater or equal to zero and the result will be if the element was found in the table.
-
How can I get the index of the current pulse model vi?
I would like to be able to see the current index pulse model vi. According to the help of Labview, a pulse is generated whenever the entered delay (d) is equal to the index (i). Is it possible to get the current index that the vi is on? If so, how could I do that?
Laura121,
Your question suggests that you can not understand how the VI.
You are referring to pulse Pattern.vi in the line object and Pulse Pattern.vi in the text of your message. Here are the two live different in the context of your question, it seems that you are referring to the Pattern.vi impulse.
When the VI is called, it returns a table in its entirety (of length = samples). For the Pattern.vi of pulse all the elements of the matrix results are zero except the index i = d, where the element has the value = amplitude. So, there is no concept of "current index that the vi is on" with this VI.
Lynn
-
Control values defined by the Index function only works for a running VI?
I've never used set of control values based on the Index before so I decided to compare it against two other ways to set the controls on the front panel, by using the invoke Ctrl.Val.Set node and nodes for the value property. But if the VI which I am trying to set the controls does not work I get error 1000 say "The VI isn't in a State compatible with this operation." When I run the VI which I am trying to set the controls, I get an error. This is VI really only work if the VI is running? I can't set the values before calling the VI to run dynamically?
I wonder why you do so in the first place.
a bit of history. This feature was added to the problem write to items in front by reference is about 1000 times slower than writing to the Terminal. I think that this feature works by writing directly to the transfer buffer. It always ends up by being slower than writing to the Terminal, but only about 10 times slower.
My company made use of this new feature. We needed it because we have updated thousands of values of frontage on the same VI by reference and labview couldn't keep it up (Yes, probably could have worked around him in a different way, but there is more detail than this...). If your ' e does not update thousands of articles, probably you should not use this feature. Performance savings is not worth the additional development effort it takes.
It does not work probably because the transfer buffer does not exist when the vi is not running
-
9219 current conversion on the current value of DMA FIFO sampling
Hi all
I'm sampling two 9219 modules (24 - bit universal module) in a FIFO I32 on the FPGA target (9072). I want to convert this example in current value for keying in my host vi. The bed a +/-25 module entered my 24-bit in a 32-bit memory location. I was originally performing the conversion on the host as follows.
1 ENTRY converted I32, then DBL
2. (ENTRY * 25) / ((2^24)/2 - 1) = CURRENT (mA)
3. CURRENT (mA) * SCALE = VALUE
My values are very high. Any help is appreciated. Thank you.
Gaussy
Hello Gaussy,
Please contact National Instruments! There are a few questions that I had for you in order to solve this problem. My first question is what version of LabVIEW you use? If you use a LabVIEW 8.5 then do you mean instead of I32 U32? If you use a LabVIEW 8.6 have you thought about trying to use fixed-point, you don't have to worry about the conversion? Here is a knowledge base article that speaks a bit more on this topic.
After looking through your conversion algorithm, I couldn't see the specific defects. I was wondering if you could post the values that you receive from the FPGA target, then the values after your conversion. In addition, it would be good to know what values expect you and why. This will help us determine if the real signal of the module is disabled or if the conversion is incorrect. I hope this helps! Have a great day!
-
Hi, I do not know why the moment I try to buy a package of software for my business, I can't go any further because I can't select my country (ITALY-EURO) COSTA RICA control value is selected automatically. I need help. A lot of satisfaction
Contact Adobe Support when available (usually not weekends)...
Chat support - the link below click the still need help? the option in the blue box below and choose the option to chat...
Make sure that you are logged on the Adobe site, having cookies enabled, clearing your cookie cache. If it fails to connect, try to use another browser.Creative cloud support (all creative cloud customer service problems)
http://helpx.Adobe.com/x-productkb/global/service-CCM.html ( http://adobe.ly/19llvMN ) -
Get the index of the current page?
Hello, I can't understand, how to get the index of the current Page in a document. I can't use "activePage.name" as the name cannot show the actual number of the current page. In the forums, I found the following function for javascripts indexOf() function.
If (!.) Array.prototype.indexOf) {}
Array.prototype.indexOf = function (searchElement / *, fromIndex * /) {}
"use strict";
If (this == null) {}
throw new TypeError();
}
var t = Object (this);
var len = Extremity > > > 0;
If (len = 0) {}
Returns - 1;
}
var n = 0;
If (arguments.length > 0) {}
n = Number (arguments [1]);
If (n! = n) {/ / shortcut to check if it is NaN}
n = 0;
} Else if (n! = 0 & & n! = Infinity & & n! = - infinite) {}
n = (n > 0 |-1) * Math.floor (Math.abs (n));
}
}
If (n > = len) {}
Returns - 1;
}
var k = n > = 0? n: Math.max (len - Math.abs (n), 0);
for (; k < len; k ++) {}
If (k t & & t [k] = searchElement) {}
return k;
}
}
Returns - 1;
}
}
With that, I then wrote the following code:
myDocument var = app.activeDocument;
myPages var = myDocument.pages;
var number = myPages.indexOf(myDocument.layoutWindows[0].activePage);
Unfortunately, it does not work. When I warn "myPages" I can see, I get the pages object. I know somehow get just the array with the values of the present?
Thank you in advance! Appreciate any help!
app.activeWindow [0].activePage.documentOffset
Of course, documentOffset, no index. Thank you for noticing.
-
Why the optimizer ignores Index Fast full Scan when much lower cost?
Summary (tracking details below) - to improve the performance of a query on more than one table, I created an index on a table that included all the columns referenced in the query. With the new index in place the optimizer is still choosing a full Table Scan on an Index fast full scan. However, by removing the one query tables I reach the point where the optimizer suddenly use the Index Fast Full Scan on this table. And 'Yes', it's a lot cheaper than the full Table Scan it used before. By getting a test case, I was able to get the motion down to 4 tables with the optimizer still ignoring the index and table of 3, it will use the index.
So why the optimizer not chooses the Index Fast Full Scan, if it is obvious that it is so much cheaper than a full Table Scan? And why the deletion of a table changes how the optimizer - I don't think that there is a problem with the number of join permutations (see below). The application is so simple that I can do, while remaining true to the original SQL application, and it still shows this reversal in the choice of access path. I can run the queries one after another, and he always uses a full Table Scan for the original query and Index fast full scan for the query that is modified with a table less.
Watching trace 10053 output for the two motions, I can see that for the original query 4 table costs alone way of ACCESS of TABLE UNIQUE section a full Table Scan. But for the modified query with a table less, the table now has a cost for an Index fast full scan also. And the end of the join cost 10053 does not end with a message about exceeding the maximum number of permutations. So why the optimizer does not cost the IFFS for the first query, when it does for the second, nearly identical query?
This is potentially a problem to do with OUTER joins, but why? The joins between the tables do not change when the single extra table is deleted.
It's on 10.2.0.5 on Linux (Oracle Enterprise Linux). I did not define special settings I know. I see the same behavior on 10.2.0.4 32-bit on Windows (XP).
Thank you
John
Blog of database Performance
DETAILS
I've reproduced the entire scenario via SQL scripts to create and populate the tables against which I can then run the queries. I've deliberately padded table so that the length of the average line of data generated is similar to that of the actual data. In this way the statistics should be similar on the number of blocks and so forth.
System - uname - a
Database - v$ versionLinux mysystem.localdomain 2.6.32-300.25.1.el5uek #1 SMP Tue May 15 19:55:52 EDT 2012 i686 i686 i386 GNU/Linux
Original query (complete table below details):Oracle Database 10g Enterprise Edition Release 10.2.0.5.0 - Prod PL/SQL Release 10.2.0.5.0 - Production CORE 10.2.0.5.0 Production TNS for Linux: Version 10.2.0.5.0 - Production NLSRTL Version 10.2.0.5.0 - Production
Execution of display_cursor after the execution plan:SELECT episode.episode_id , episode.cross_ref_id , episode.date_required , product.number_required , request.site_id FROM episode LEFT JOIN REQUEST on episode.cross_ref_id = request.cross_ref_id JOIN product ON episode.episode_id = product.episode_id LEFT JOIN product_sub_type ON product.prod_sub_type_id = product_sub_type.prod_sub_type_id WHERE ( episode.department_id = 2 and product.status = 'I' ) ORDER BY episode.date_required ;
Updated the Query:SQL_ID 5ckbvabcmqzw7, child number 0 ------------------------------------- SELECT episode.episode_id , episode.cross_ref_id , episode.date_required , product.number_required , request.site_id FROM episode LEFT JOIN REQUEST on episode.cross_ref_id = request.cross_ref_id JOIN product ON episode.episode_id = product.episode_id LEFT JOIN product_sub_type ON product.prod_sub_type_id = product_sub_type.prod_sub_type_id WHERE ( episode.department_id = 2 and product.status = 'I' ) ORDER BY episode.date_required Plan hash value: 3976293091 ----------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | ----------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | | 35357 (100)| | | 1 | SORT ORDER BY | | 33333 | 1920K| 2232K| 35357 (1)| 00:07:05 | | 2 | NESTED LOOPS OUTER | | 33333 | 1920K| | 34879 (1)| 00:06:59 | |* 3 | HASH JOIN OUTER | | 33333 | 1822K| 1728K| 34878 (1)| 00:06:59 | |* 4 | HASH JOIN | | 33333 | 1334K| | 894 (1)| 00:00:11 | |* 5 | TABLE ACCESS FULL| PRODUCT | 33333 | 423K| | 103 (1)| 00:00:02 | |* 6 | TABLE ACCESS FULL| EPISODE | 299K| 8198K| | 788 (1)| 00:00:10 | | 7 | TABLE ACCESS FULL | REQUEST | 3989K| 57M| | 28772 (1)| 00:05:46 | |* 8 | INDEX UNIQUE SCAN | PK_PRODUCT_SUB_TYPE | 1 | 3 | | 0 (0)| | ----------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("EPISODE"."CROSS_REF_ID"="REQUEST"."CROSS_REF_ID") 4 - access("EPISODE"."EPISODE_ID"="PRODUCT"."EPISODE_ID") 5 - filter("PRODUCT"."STATUS"='I') 6 - filter("EPISODE"."DEPARTMENT_ID"=2) 8 - access("PRODUCT"."PROD_SUB_TYPE_ID"="PRODUCT_SUB_TYPE"."PROD_SUB_TYPE_ID")
Execution of display_cursor after the execution plan:SELECT episode.episode_id , episode.cross_ref_id , episode.date_required , product.number_required , request.site_id FROM episode LEFT JOIN REQUEST on episode.cross_ref_id = request.cross_ref_id JOIN product ON episode.episode_id = product.episode_id WHERE ( episode.department_id = 2 and product.status = 'I' ) ORDER BY episode.date_required ;
Creating the table and Population:SQL_ID gbs74rgupupxz, child number 0 ------------------------------------- SELECT episode.episode_id , episode.cross_ref_id , episode.date_required , product.number_required , request.site_id FROM episode LEFT JOIN REQUEST on episode.cross_ref_id = request.cross_ref_id JOIN product ON episode.episode_id = product.episode_id WHERE ( episode.department_id = 2 and product.status = 'I' ) ORDER BY episode.date_required Plan hash value: 4250628916 ---------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | ---------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | | 10515 (100)| | | 1 | SORT ORDER BY | | 33333 | 1725K| 2112K| 10515 (1)| 00:02:07 | |* 2 | HASH JOIN OUTER | | 33333 | 1725K| 1632K| 10077 (1)| 00:02:01 | |* 3 | HASH JOIN | | 33333 | 1236K| | 894 (1)| 00:00:11 | |* 4 | TABLE ACCESS FULL | PRODUCT | 33333 | 325K| | 103 (1)| 00:00:02 | |* 5 | TABLE ACCESS FULL | EPISODE | 299K| 8198K| | 788 (1)| 00:00:10 | | 6 | INDEX FAST FULL SCAN| IX4_REQUEST | 3989K| 57M| | 3976 (1)| 00:00:48 | ---------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("EPISODE"."CROSS_REF_ID"="REQUEST"."CROSS_REF_ID") 3 - access("EPISODE"."EPISODE_ID"="PRODUCT"."EPISODE_ID") 4 - filter("PRODUCT"."STATUS"='I') 5 - filter("EPISODE"."DEPARTMENT_ID"=2)
1 create tables
2. load data
3 create indexes
4. collection of statistics
10053 sections - original query-- -- Main table -- create table episode ( episode_id number (*,0), department_id number (*,0), date_required date, cross_ref_id varchar2 (11), padding varchar2 (80), constraint pk_episode primary key (episode_id) ) ; -- -- Product tables -- create table product_type ( prod_type_id number (*,0), code varchar2 (10), binary_field number (*,0), padding varchar2 (80), constraint pk_product_type primary key (prod_type_id) ) ; -- create table product_sub_type ( prod_sub_type_id number (*,0), sub_type_name varchar2 (20), units varchar2 (20), padding varchar2 (80), constraint pk_product_sub_type primary key (prod_sub_type_id) ) ; -- create table product ( product_id number (*,0), prod_type_id number (*,0), prod_sub_type_id number (*,0), episode_id number (*,0), status varchar2 (1), number_required number (*,0), padding varchar2 (80), constraint pk_product primary key (product_id), constraint nn_product_episode check (episode_id is not null) ) ; alter table product add constraint fk_product foreign key (episode_id) references episode (episode_id) ; alter table product add constraint fk_product_type foreign key (prod_type_id) references product_type (prod_type_id) ; alter table product add constraint fk_prod_sub_type foreign key (prod_sub_type_id) references product_sub_type (prod_sub_type_id) ; -- -- Requests -- create table request ( request_id number (*,0), department_id number (*,0), site_id number (*,0), cross_ref_id varchar2 (11), padding varchar2 (80), padding2 varchar2 (80), constraint pk_request primary key (request_id), constraint nn_request_department check (department_id is not null), constraint nn_request_site_id check (site_id is not null) ) ; -- -- Activity & Users -- create table activity ( activity_id number (*,0), user_id number (*,0), episode_id number (*,0), request_id number (*,0), -- always NULL! padding varchar2 (80), constraint pk_activity primary key (activity_id) ) ; alter table activity add constraint fk_activity_episode foreign key (episode_id) references episode (episode_id) ; alter table activity add constraint fk_activity_request foreign key (request_id) references request (request_id) ; -- create table app_users ( user_id number (*,0), user_name varchar2 (20), start_date date, padding varchar2 (80), constraint pk_users primary key (user_id) ) ; prompt Loading episode ... -- insert into episode with generator as (select rownum r from (select rownum r from dual connect by rownum <= 1000) a, (select rownum r from dual connect by rownum <= 1000) b, (select rownum r from dual connect by rownum <= 1000) c where rownum <= 1000000 ) select r, 2, sysdate + mod (r, 14), to_char (r, '0000000000'), 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' || to_char (r, '000000') from generator g where g.r <= 300000 / commit ; -- prompt Loading product_type ... -- insert into product_type with generator as (select rownum r from (select rownum r from dual connect by rownum <= 1000) a, (select rownum r from dual connect by rownum <= 1000) b, (select rownum r from dual connect by rownum <= 1000) c where rownum <= 1000000 ) select r, to_char (r, '000000000'), mod (r, 2), 'ABCDEFGHIJKLMNOPQRST' || to_char (r, '000000') from generator g where g.r <= 12 / commit ; -- prompt Loading product_sub_type ... -- insert into product_sub_type with generator as (select rownum r from (select rownum r from dual connect by rownum <= 1000) a, (select rownum r from dual connect by rownum <= 1000) b, (select rownum r from dual connect by rownum <= 1000) c where rownum <= 1000000 ) select r, to_char (r, '000000'), to_char (mod (r, 3), '000000'), 'ABCDE' || to_char (r, '000000') from generator g where g.r <= 15 / commit ; -- prompt Loading product ... -- -- product_id prod_type_id prod_sub_type_id episode_id padding insert into product with generator as (select rownum r from (select rownum r from dual connect by rownum <= 1000) a, (select rownum r from dual connect by rownum <= 1000) b, (select rownum r from dual connect by rownum <= 1000) c where rownum <= 1000000 ) select r, mod (r, 12) + 1, mod (r, 15) + 1, mod (r, 300000) + 1, decode (mod (r, 3), 0, 'I', 1, 'C', 2, 'X', 'U'), dbms_random.value (1, 100), NULL from generator g where g.r <= 100000 / commit ; -- prompt Loading request ... -- -- request_id department_id site_id cross_ref_id varchar2 (11) padding insert into request with generator as (select rownum r from (select rownum r from dual connect by rownum <= 1000) a, (select rownum r from dual connect by rownum <= 1000) b, (select rownum r from dual connect by rownum <= 1000) c where rownum <= 10000000 ) select r, mod (r, 4) + 1, 1, to_char (r, '0000000000'), 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz01234567890123456789' || to_char (r, '000000'), 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789012345678' || to_char (r, '000000') from generator g where g.r <= 4000000 / commit ; -- prompt Loading activity ... -- -- activity activity_id user_id episode_id request_id (NULL) padding insert into activity with generator as (select rownum r from (select rownum r from dual connect by rownum <= 1000) a, (select rownum r from dual connect by rownum <= 1000) b, (select rownum r from dual connect by rownum <= 1000) c where rownum <= 10000000 ) select r, mod (r, 50) + 1, mod (r, 300000) + 1, NULL, NULL from generator g where g.r <= 100000 / commit ; -- prompt Loading app_users ... -- -- app_users user_id user_name start_date padding insert into app_users with generator as (select rownum r from (select rownum r from dual connect by rownum <= 1000) a, (select rownum r from dual connect by rownum <= 1000) b, (select rownum r from dual connect by rownum <= 1000) c where rownum <= 10000000 ) select r, 'User_' || to_char (r, '000000'), sysdate - mod (r, 30), 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' || to_char (r, '000000') from generator g where g.r <= 1000 / commit ; -- prompt Episode (1) create index ix1_episode_cross_ref on episode (cross_ref_id) ; -- prompt Product (2) create index ix1_product_episode on product (episode_id) ; create index ix2_product_type on product (prod_type_id) ; -- prompt Request (4) create index ix1_request_site on request (site_id) ; create index ix2_request_dept on request (department_id) ; create index ix3_request_cross_ref on request (cross_ref_id) ; -- The extra index on the referenced columns!! create index ix4_request on request (cross_ref_id, site_id) ; -- prompt Activity (2) create index ix1_activity_episode on activity (episode_id) ; create index ix2_activity_request on activity (request_id) ; -- prompt Users (1) create unique index ix1_users_name on app_users (user_name) ; -- prompt Gather statistics on schema ... -- exec dbms_stats.gather_schema_stats ('JB')
10053 - updated the Query*************************************** SINGLE TABLE ACCESS PATH ----------------------------------------- BEGIN Single Table Cardinality Estimation ----------------------------------------- Table: REQUEST Alias: REQUEST Card: Original: 3994236 Rounded: 3994236 Computed: 3994236.00 Non Adjusted: 3994236.00 ----------------------------------------- END Single Table Cardinality Estimation ----------------------------------------- Access Path: TableScan Cost: 28806.24 Resp: 28806.24 Degree: 0 Cost_io: 28738.00 Cost_cpu: 1594402830 Resp_io: 28738.00 Resp_cpu: 1594402830 ******** Begin index join costing ******** ****** trying bitmap/domain indexes ****** Access Path: index (FullScan) Index: PK_REQUEST resc_io: 7865.00 resc_cpu: 855378926 ix_sel: 1 ix_sel_with_filters: 1 Cost: 7901.61 Resp: 7901.61 Degree: 0 Access Path: index (FullScan) Index: PK_REQUEST resc_io: 7865.00 resc_cpu: 855378926 ix_sel: 1 ix_sel_with_filters: 1 Cost: 7901.61 Resp: 7901.61 Degree: 0 ****** finished trying bitmap/domain indexes ****** ******** End index join costing ******** Best:: AccessPath: TableScan Cost: 28806.24 Degree: 1 Resp: 28806.24 Card: 3994236.00 Bytes: 0 ****************************************************************************** SINGLE TABLE ACCESS PATH ----------------------------------------- BEGIN Single Table Cardinality Estimation ----------------------------------------- Table: REQUEST Alias: REQUEST Card: Original: 3994236 Rounded: 3994236 Computed: 3994236.00 Non Adjusted: 3994236.00 ----------------------------------------- END Single Table Cardinality Estimation ----------------------------------------- Access Path: TableScan Cost: 28806.24 Resp: 28806.24 Degree: 0 Cost_io: 28738.00 Cost_cpu: 1594402830 Resp_io: 28738.00 Resp_cpu: 1594402830 Access Path: index (index (FFS)) Index: IX4_REQUEST resc_io: 3927.00 resc_cpu: 583211030 ix_sel: 0.0000e+00 ix_sel_with_filters: 1 Access Path: index (FFS) Cost: 3951.96 Resp: 3951.96 Degree: 1 Cost_io: 3927.00 Cost_cpu: 583211030 Resp_io: 3927.00 Resp_cpu: 583211030 Access Path: index (FullScan) Index: IX4_REQUEST resc_io: 14495.00 resc_cpu: 903225273 ix_sel: 1 ix_sel_with_filters: 1 Cost: 14533.66 Resp: 14533.66 Degree: 1 ******** Begin index join costing ******** ****** trying bitmap/domain indexes ****** Access Path: index (FullScan) Index: IX4_REQUEST resc_io: 14495.00 resc_cpu: 903225273 ix_sel: 1 ix_sel_with_filters: 1 Cost: 14533.66 Resp: 14533.66 Degree: 0 Access Path: index (FullScan) Index: IX4_REQUEST resc_io: 14495.00 resc_cpu: 903225273 ix_sel: 1 ix_sel_with_filters: 1 Cost: 14533.66 Resp: 14533.66 Degree: 0 ****** finished trying bitmap/domain indexes ****** ******** End index join costing ******** Best:: AccessPath: IndexFFS Index: IX4_REQUEST Cost: 3951.96 Degree: 1 Resp: 3951.96 Card: 3994236.00 Bytes: 0 ***************************************I mentioned that it is a bug related to the ANSI SQL standard and transformation probably.
As suggested/asked in my first reply:
1. If you use a no_query_transformation then you should find that you get the use of the index (although not in the plan you would expect)
2. If you use the traditional Oracle syntax, then you should not have the same problem.
Maybe you are looking for
-
EFax invites you to the photo tray
After receiving an efax, the printer pushes me that I need to load paper into the photo tray. Of course, I can't print the fax to a photo 4 x 6. I don't see how to tell him to use the main tray. I put the preference of bac to bac main on the print
-
How to configure the different VLANs (using the E3200)?
Hello. I want to implement different VLANs (using the E3200) so that I can have two different networks that cannot access each other. The E3200 is connected to a modem for internet access. I would like that the two networks to access the internet. Th
-
How do I change "my documents" or called documents in Windows 7 to a network location?
I'm tring to change the path of the documents of the local HD folder to a network location, but I don't see any place where I can do this in win 7. When I click on the 'my documents' and click on include the folder, I get the following error message
-
For the Cisco router memory usage
Hello We have a router SA520 (Firmware 2.1.18) We use only this for about 1 month now. Router seems ok it's just I am concerned about the use of memory who reach 62% (144/234 MB) What's to worry?How can I use that by cutting down the use? Excuse me,
-
BlackBerry Smartphones on screen icon
I had a small icon (alert) on the upper left side of my screen. It looks like a battery with a number next to it. This morning, there were 9 then it went to 12 and now his 19 on can someone tell me what is it how to see if its an alert and how to get