Asymmetrical cluster in RSXi
Hi all.
I have a question about the cluster implementation,
I am aware that it is more practical to have all hosts in the cluster with the same characteristics, but what happens if they are not.
What if there is a difference of memory or an odd number of hosts 3 hosts for example.
Basically, we have a recovery with a host site, there is also a SAN replica on both sides not illustrated.
I'm happy to run to capacity in case of failure, for example we have 4 domain controllers, file 4 DFS servers. 4 Exchange CAS servers. In case of failure, I'm happy to run only 1 ms and 1 Server DFS and maybe 2 Exchange servers.
The DR site also has its on Virtual Machines running.
The question is too simple, I need to make sure there is enough size slot in the site of DR to account for failure on?
What happens if I want also to DRS, which means that the server of the site of DR has more resources and so runs out of virtual machines, thus reducing the places available for VM for main site to failover to the DR site.
any thoughts?
Here is a picture.

What are you using to switch hosts on the DR site? You use SRM or just manually bring you to the top of the virtual machine of the SAN replication failure?
Is your main DC and DC DR on a dish network?
If you use SRM and failover to the site of DR the VM will be online and then follow the instructions by the DR Cluster, (HA, DRS, Slot size, ect) I usually do not set my 1 host failover settings because I love not dealing with slot sizes and having to constantly monitor and or reconfigure them if VM 1 the size of the slot punches. I usually use the % implemented and updated my DR site 10% or 25% regardless of your consistent with. Once everything is switched and fed on DRS will begin to move things as needed. Also if you use SRM you can specify what hosts you want to things to start if you so desire and or have the ability to run scripts at the end of the SRM jobs to take any other necessary measures.
I hope this helped,
If you have any other questions please let me know.
Tags: VMware
Similar Questions
-
Admission control - [Sanity Check] cluster asymmetric w / no reservations of VM
I spent a time reviews the policy reduced control and just looking for a "sanity check" that the conclusions of my environment and my calculations are accurate. Currently manages an asymmetric cluster which includes 1 much more memory than the rest host (host 5). I have read from multiple sources, including 5.1 deepdive of Duncan and Frank policy "tolerate failures of the host in the cluster" to waste resources in the scenario in order to ensure the greatest Web host is protected. However, the calculation below shows that this policy is almost dead on what percentages policy would cover in a scenario N + 1 (again to ensure the greatest Web host is protected).
The distribution is:
Host 1
Host 2
Home 3
Home 4
Host 5
Home 6
Home 7
Totals
Memory (GB)
48
72
64
64
128
64
72
512
% Of the memory
9.38
14.06
12.5
12.5
25
12.5
14.06
CENTRAL PROCESSING UNIT
18.08 GHz
19.12 GHz
19.12 GHz
18.08 GHz
19.12 GHz
19.12 GHz
19.12 GHz
131.76
PROCESSOR: %
13.78
14.5
14.5
13.78
14.5
14.5
14.5
In an N + 1 scenario the percentages recommended would work out at 25% for memory (128 / 512) * 100 and 15% (rounded) for CPU (19.12 / 131,76) * 100 to ensure the greatest web host is protected. I realize that we can reduce waste by reducing these values, but he would go the end of the point of HA if the largest Web host has failed (I realize again it would need to be heavily used approval) and it does not have enough resources to insider HA restarts.
Use current political failures the cluster host tolerates slot sizes are default values (32 MHz CPU and 217 MB (overhead) memory) without reserves of VM. We use the reserves of RP, but they come into play with slot HA size calculation if I understand. We have currently 2210 (1540 available) number of locations within our core, given the hosts/resources provided. 138 locations are used to power VMs and 532 are reserved for failover. For the record, it works to 112,73 GB (532 * 217) / 1024). This is equivalent to 22% of the total memory in the cluster. It works for the processor to 16.63 GHz (32 MHz * 532) / 1000 round is 17% of the total CPU in the cluster.
And if I went to the policy of the percentages with best practices in mind I would reserve more memory and less than what current CPU, but only a few given the above percentages. Are there any underlying problems with this configuration, I'm missing or given configuration is my exact analysis? Or it is recommended to apply the policy of calculated percentages and lower resources reserved for values lower than the largest webhost in the cluster for available resources? It is the 'catch 22' because we obviously want to maximize the resources available to the cluster while guaranteeing adequate resources of failover.
I wrote an article about this as well: http://www.yellow-bricks.com/2012/12/11/death-to-false-myths-admission-control-lowers-consolidation-ratio/
-
Scan the number of listeners and balancing the result
Hello
within the analysis of the docs 3 listeners are usually qualified.
But is it accurate to say that with this configuration, only 2 node RAC, you normally an asymmetric cluster and a single node with two connections on the other?
Because if you use Robin DNS, you will get 2/3 of the resolutions at a node (the one who got two of the IPs associated 3 related) and 1/3 to the other.
So in the case of 2 knots, would it be better to have only 2 scan listeners, or define a 4th one finally?
Thank you
Gianluca
It is not an asymmetric cluster, scan listeners will only lead the incoming request to the listener node of the instance with a lesser charge.
All headphones scan will have all instances clustered registered with it and therefore every listener know which node the connection request must be sent to balance the load.
Even in the case of a 10-node cluster, 3 listeners scan would be sufficient, it is not necessary to have listener ongoing scan of running on each node to send connections to that node.
http://www.Oracle.com/technetwork/products/Clustering/overview/scan-129069.PDF
-
I'm expanding our vmware environment. I currently have HA\DRS clusters comprising DL360\380 G5 servers. I bought three DL380 G6 servers. I'm the thing about creating another cluster for the G6 servers using VMware EVC vs. Someone has mixed the G5 and G6 servers on the same cluster? Or is it better to keep them separated?
Thank you
> Has anyone mixed G5 and G6 servers on the same cluster? Or is it better to keep them separated?
VCA depends on the processor not material, if processors are a match, it should be good... We mixed in some, it's only a problem if your servers are a different configuration, so G5 is 64 GB and G6 is 96 GB of RAM for example, then you could end up with an asymmetrical cluster.
IMHO if the machines are identical (except the new architecture) I would put it in the same cluster. You can always build the new cluster, as expected, disconnect, then remove the host G5 of the old cluster and ADD the new cluster G6 (after turning on VCA). If she don't get complaint, it should be good
BTW, removing guests will NOT affect the virtual computer running (provided that you restart / power off of the host).
-
IAM having a problem of NAT rule asymmetrical between the DMZ and VPN client on a 8.2 (5) ASA. We used to have a two ASAs a VPN client and one for the main firewall. In the old configuration the client VPN ASA has routed CVPN traffic through the network on the main firewall, so it could be filtered via a content engine. As you guess split tunneling is disabled in old and new configs. I recently grouped these two in a HA pair, terminated the VPN client on the cluster with the main firewall and used the road inside 0.0.0.0 0.0.0.0 10.100.18.1 (basic router) by command so that traffic would be routed through the core so it can be filtered using the internet on C - VPN. NAT 0 and rules are passed on to the fine. Everything else works fine access inside resources and internet connectivity
March 25, 2012 20:06:23: % 305013-5-ASA: rules asymmetrical NAT matched for flows forward and backward; Connection for icmp outside src: 10.100.120.29 DMZ:10.100.150.105 (type 8, code 0) dst refused because of the failure of reverse path of NAT
routes:
Route outside 10.100.120.0 255.255.255.0 Gateway-RTR-INTERNET
Route inside 0.0.0.0 0.0.0.0 10.100.18.1 in tunnel
Route outside 0.0.0.0 0.0.0.0 INTERNET-RTR-gateway
Route inside 10.0.0.0 255.0.0.0 10.100.18.1
Since it is in the tunnel should I me 10.100.120.0 inside?
The strange thing is that the traffic on the internet is not removed due to the failure of nat.
Reverse IP check is disabled on all interfaces.
Hello
You can apply ACLs for traffic VPN Client directly on the SAA and do not run within the network for this. Or did I get something wrong?
The easiest way would be just to have the default route pointing to the outside. When adding 'set reverse-road' for "crypto map" configurations, the ASA would then also inject a route to the address pool customer VPN to ASA routing table when you have a user logged on to the ASA via the VPN.
If you need to do nat for Internet access you can always do it like this:
"nat (outside) 1 x.x.x.x y.y.y.y".
Also, you can apply a filter ACL to your VPN Client connections in order to limit this kind of connections they can take. For example freely leave the DNS and HTTP/HTTPS, but blocks access to a part of your internal network.
-Jouni
-
How to make a stacked cluster chart?
I am creating a cluster diagram, classified by different emails sent to customers (let's call them 1, 2 and 3 Email) and has each kind of stacked e-mail based on the answer (opened, clicked). Is it possible to have your chart be grouped and stacked? The x-axis are labeled by the day of the week, and I would be more group by email (1, 2 and 3) every day.
Thanks in advance for the help!
Numbers isn't a stacked column cluster chart. But you can use a 3D stacked column and can 'cheat'similar to the way you would in Excel.

The trick is to leave blank lines in the table of data which, when the fill color is removed, the differences between the clusters form.
I don't understand how to get the labels for each cluster in the right place. When the two left columns are defined as cluster labels column headers appear where it is indicated in the screenshot, is not ideal. It is possible that the days of the week may have to be manually labeled with text boxes.
SG
-
The 15 "Macbook always uses the asymmetric blades?
I just bought a mid-2015 MacBook Pro 15.4 with a 2.5 Ghz with 512 GB i7 and the AMD Radeon R9 M370. I do a lot of repairs on computers and portable computers desktop apple and the retina, not those that are extensible easierly older. Ive been working only on 1, 15 inch Macbook. I know that the blades are placed asymmetrically on the older models, but are they still asymmetrically laced on mid 2015 those? (Apple does that the 2015 middle there is no late 2015 or early 2016 currently as of 08/03/2016) fans seemed strong in the wind noise, when I export video that is better than my old laptop that makes a whining noise. Then I opened the computer and looks like they have redesigned the fans. the last of them, that I worked on was a 2013 environment that had fans like that.

I was told that they have been placed asymmetrically and told by apple. I never listened to the fans at the time that I worked on, but a new always uses the asymmetric blades and what is the difference? Also, fans of left turn to 6150 against the right to the 5700 because of the GPU on the left side of the radiator? If anyone has the two could you tell me who is the strongest?
Here is the new fan who is in my Macbook.

-
I have a new HP Pavilion 23 F250 touchsmart
When creating an image file it came with a
cluster, run error unused cluster found in the cluster, run the error code = 10 run chkdsk /f
don't know if I should call tech support or learn how to run a dos command window?
Larry
I set chkdsk to run at startup as an administrator and it took about 3 hours. OK, some on the forums said to
27% and stayed there so they got out of it.
He ran very well using Windows 8 Pro.
don't know how to cancel this post or the mark it solved.
Larry
Hi, sorry to hear that you are having problems with your Pavilion. I did some research and I found a Microsoft document that I think can help you. Please click on the link I provided.
If you have any other questions, please write back and I'll be more than happy to help you.
Thank you
Waterboy71
-
How to feed a cluster in the mathscript?
Hi all
I'm trying to feed a cluster in the mathscript. I found that, if the name of the element in the cluster has no spaces or special characters, it works fine. But it does not work if the name of the cluster components have special characters. That's how Mathscript designed? No work around here?
Hey dragondiver,
We hope that you do well today. This document overviews the intended use and the behavior of data with MathScript types.
Transmission of data in and out of the node MathScript (MathScript RT Module)
http://zone.NI.com/reference/en-XX/help/373123C-01/lvtextmathmain/ms_passing_data_lv_mathscript/
So, to answer your question more specifically, the rule for naming elements within a cluster in the node is,
"You have to tag individual items in the cluster. The labels must begin with an alphabetic character and can contain only alphanumeric characters and underscores, no spaces. »
It must explain the behavior you're seeing with your code!
-
Hello
Can we have clusters in the regular similar to LabVIEW user interface designer?
Thank you.
Assembly,
To work around the problem, you can use the flatten in primitive XML string in your web service, and then use the screw of Parsing XML in the Web user interface designer to get your data from cluster:
For an example on the use of the screw of the XML parsing in the generator of the user Web interface, see this example: Arbitrary in LabVIEW Web Interface Builder Web Services call
-
Add an element to a cluster without updating all users of the cluster
I have a cluster that is sent to many different vi. Whenever I have added to this cluster, I need to change every vi that uses it to fix the various controls of input terminals and ungroup by names.
I'm not change or remove existing items in the source cluster. just to add another element that one worries of the vi "shipwreck" for others, it is simply one don't care. Is it possible to avoid having to fix each "sink" vi when I do this? I would only need to update the vi that uses the new element (which of course, I do anyway).
In C, I can update, add a member to a typedef'd struct and everything is fine - no problems; How can I do something similar in LV?
If you branch out a cluster then all sinks must be the same. You should do your cluster a typedef and use the typedef on your screws in this way that you change only one place. Even with the a typedef in C.

LabVIEW manual contains instructions on how to create and use of typedefs.
-
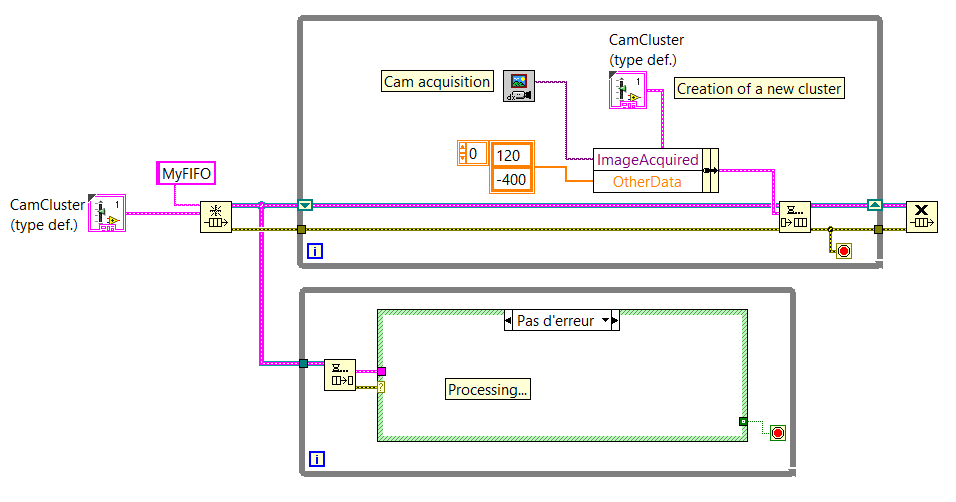
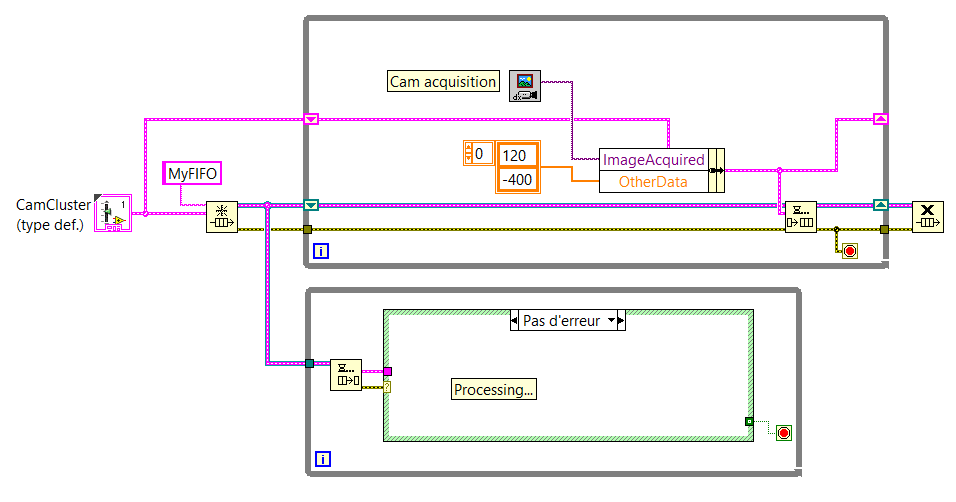
Good practices of FIFO: updated old cluster or create new
Hello world
My question is more on "good practices" that really solve a problem.
I use FIFO to send images and other data from a producer to a consumer.
I created a cluster which includes all the data that must be sent through the FIFO.
My question is: can I create a new cluster to each loop of the producer and put this cluster in the FIFO or should I set a shift and then register and update the data of this fallen registry change by sending in the FIFO?
Below you will find two screenshots that sums up the idea (NB: these aren't the real VI.) We come here to show the general idea).
If there is a difference (in the way that the computer uses memory for example, or something else...) between these two methods of programming, you will give me some details so that I can understand why to use one over the other, please?
Thank you very much.
Best regards.
Luke
I think that there is very little difference in terms of performance (perhaps the registry approach change is slower than sliiightly - but probably not noticeable in most cases).
The main reason you want to use the shift register approach is that if you update only certain values before sending the data in the queue, those that would be lost if you created a new cluster each time. For example, if 'Directories' was constant, you could just power/updating that once the value to the registry to shift and just update the part "ImageAcquired" of the cluster before you send it in the queue. This also means that if you update your cluster to have more elements (using a type-def, of course), you can be less worried about having to update the individual elements.
I think it is less a problem of performance (both are valid and effective) and more a matter of maintainability and flexibility.
-
History of clear ranking with only refers to the cluster
I have a group of UI elements that I save them as a strict type def be reused between various programs. I can send data in each of these elements. However, I use graphic waveform instead of waveform graphs so that I can stack data. In my application, the user can select data at different points in time so I need clear history graphic waveform and then update the graph with the necessary values. It works fine if I make a direct reference from the graph but I can't operate using just the reference to the cluster. I get either a mismatch of type if I use a strict reference, or I don't see the historic property at all if an appending reference is used. I've seen people putting this problem before but had not seen the right solutions that work with just the reference of the cluster. Any thoughts?
In the comic book, do a right-click on the reference to the "table of waveform" and select Create-> constant. Strictly typed constant wire at the entrance of "class of target" of "more class specific.
-
Patterns of data record TestStand 2010 SP1 default shared this cluster in two tables stored as binary data, resulting in two graphs displayed in the report: one for data and one for X data Y. We need the elements X and Y, couples on the same graph. This cluster is marked for logging as a step output variable. It seems possible to add a table "PROP_XYGRAPH" (similar to the PROP_ANALOGWAVEFORM) to the schema to simplify the other treatment after the database record, but how can we get the Builder, to accept this type of data is displayed correctly? XY graphics come from LabVIEW 2013 SP1 exclusively as a cluster of two matrices, usually between 500 and 1,000 items long.
... Geoff.
Hello Geoff,
Had a few resources for you to check. Let us know if none of them work for you.
Inserting an image of LabVIEW Control:
<>http://www.NI.com/example/30736/en/ >
Display of graphics in TestStand:
<>https://decibel.NI.com/content/docs/doc-38945 >
Display of measurement data in the shape of graph:
<>http://zone.NI.com/reference/en-XX/help/370052J-01/tsref/infotopics/measurement_data/ >
See you soon!
-
How to set the cluster error in postexpression?
Hello
I created a c language #-driver that returns a 0 for the pass or - 1 for failure in the functions 'int MyFunction().
Now I use this function for teststeps.
Question is: How can I use this returnvalue to set the cluster error?
So that one - 1 causes an error.
I think it can be done somehow in the post expression.
How can I put a
If (returnvalue == - 1).
{
Result.Error.Code = 10100
Result.Error.Msg = "an error has occurred."
Result.Error.Occured = True
}
Thanks for help
Hi OnlyOne,
Check out this example (stored in TS4.0)
The tower is done using a breakets conditional and literal.
Locals.nReturnValue is-1? {Step.Result.Error.Code = 10100, Step.Result.Error.Msg = "Error occurred", Step.Result.Error.Occurred = True}: {}
Concerning
Jürgen




Maybe you are looking for
-
Hello world I'm looking to import data from several Excel (20 separate files) files and LabVIEW give me a ground smooth for each set of points. Then, I need LabVIEW to give me the cooridnates of the crest of each of these plots, smoothed and if possi
-
Access to local variables in the sequence
Hi all I need to access local variables in my c# file sequence in order for udate it. How can I do it. Are there examples? Kind regards.
-
I want to format my hard drive and install vista dvd. What should I do?
Never done this before any help appreciated. I ran format c:\ and attempted then just install windows vista. I had a lot of problems starting etc. Can someone tell me exactly what I need to do? I have format it then create partitions or just intall w
-
"epson stylus photo r300 driver" "windows 7 64".
I can't find a printer driver for Epson stylus photo r300, with Windows 7 64 bit. I would be very grateful for any help. Thank you.
-
Cannot create a virtual disk existing; problem with files hard?
Yes... This is a recurring problem since mid-December, and we finally decided to rebuild our vCenter on another host server. I went and did the things of the new Virtual Machine and has "custom", so that I can browse and recover files hard and * _1.