By comparing the two records and return only the differences
Hi all!Assume the records as follows:
USERID USERNAME STREET CITY PHONE
---------- ---------- -------- ------ -------------
1 John Smith Street 1 City 1
1 John Smith Street 1 City 1 (31) 234-1234What I´d like to do is to retrieve only (or fields) that changed between these 2 versions of the same record. The idea is to call this query (or process PLSQL) a trigger and save these data on a table. The data returned by the query (or process), on the example above, should be something like:
USERID USERNAME STREET CITY PHONE
---------- -------- ------ ---- -------------
1 (31) 234-1234
1 row selected.USERID USERNAME STREET CITY PHONE
---------- -------- ------ ------ -------------
1 City12 (31) 234-1234
1 row selected.Thank you very much for your attention.
Hello
What I´d like to do is to retrieve only (or fields) that changed between these 2 versions of the same record. The idea is to call this query (or process PLSQL) a trigger and save these data on a table.
Looks like you're simply wanting a trigger?
Something like:
CREATE OR REPLACE TRIGGER audit_trg
AFTER UPDATE ON your_table
FOR EACH ROW
BEGIN
INSERT INTO audit_table(userid, username, street, city, phone)
VALUES(
:new.userid,
nullif(:new.username, :old.username),
nullif(:new.street, :old.street),
nullif(:new.city, :old.city),
nullif(:new.phone, :old.phone)
);
END;
/
Tags: Database
Similar Questions
-
How can I compare the differences between two files After Effects?
I have a major problem. I was working on special effects for a film. In After Effects, when I change siggificant, I often have to register under and create a new name so I can go back to the old work if necessary. It comes in a case, I have come back from earlier works. If I use these two files After Effects allows you to create multiple clips of effects. And I do not remember just where you look at it, it is better. Does anyone know a good way to compare the differences between the files?
One thing to keep this conversation on the right way: I know that I did a stupid thing. I've never done this before so can we please not spend a lot of time on how to avoid this problem and stick to how we solve this problem?
If you encounter difficulties to identify differences in the old and new versions, you can use this procedure:
To avoid confusion, I'll call your former company and your most recent compositions CompB comps.
CompA drag "New Comp" icon in the project window. This will create a new temporary layout that contains the nested CompA.
Drag in your new COMP CompB temporary ensure it aligns image for image with CompA.
Place the top layer (CompB) difference.
Now, when you play through the comp, you'll see differences in color at a time where the comparison and CompB are not identical.
-
GREP in Indesign. Research of two characters, and apply only in a style
Hello, I turn again to this community. It is possible through the GREP to find two characters and apply single style? That is, applied in one and ignoring the other. Is there a script? Thank you.
The trick is to use the 'positive advanced search' (this is the topic Match from the drop-down icon next to GREP find what):
f(?=\()
-
By comparing the differences files
This question has been posted in response to the following article: http://help.Adobe.com/en_US/Dreamweaver/CS/using/WSc78c5058ca073340dcda9110b1f693f21-7edda .html
I don't know about the use of FileMerge.app, but compare the file works with TextWrangler twdiff Mountain Lion.
The location is HD:usr:local:bin:twdiff Macintosh.
TextWrangler is a free text editor and the "little brother" of BBEdit. It can be obtained from http://www.barebones.com/products/TextWrangler/.
-
Join the two trees connect by prior Start With and return only common records?
Oracle 10g Release 2 (10.2)
I have two tables which have structured data. The results, when running queries individually are correct, but I need to join tree a tree two to get only the common records between them.
-Trees a
SELECT ip_entity_name, entity_code, hier_level, entity_parent
Of ip_hierarchy
WHERE hier_level > = 3
CONNECT BY PRIOR Entity_code = entity_parent
START WITH entity_code = "MEWWD";
-The two tree
SELECT ip_entity_name, entity_code, hier_level, entity_parent
Of ipt_hierarchy
WHERE hier_level > = 3
CONNECT BY PRIOR Entity_code = entity_parent
START WITH entity_code = "IPNAM";
If I understand correctly, the joints can not work with CONNECT BY / START WITH queries?
A WITH clause is an option?
If possible, I don't want to put a selection in a database to display object and join against other queries.
Thank you.Hello
jtp51 wrote:
Oracle 10g Release 2 (10.2)
...
If I understand correctly, the joints can not work with CONNECT BY / START WITH queries?Before Oracle 9 it was true. Since you're using Oracle 10, you can if you wish; but I'm guessing that you don't want in this case.
A WITH clause is an option?
If possible, I don't want to put a selection in a database to display object and join against other queries.
Yes, a WITH clause that is an option. Viewed online, as Zhxiang has shown, are another option. Either way gives you a regular display effect without creating a database object.
You did not show a sample and the results, so no one can tell if a join is really what you want. Other possibilities include INTERSECT or an IN subquery.
-
Incompatibility between the two recorded and stored data
Hi guys, I am preparing Labview codes for reocording synchronized analogy and reading. Specifically, I want to record for 6 seconds, while the sounds of output for 5 seconds. This means that the analogue output stop 1 second before the end of the recording. In addition, I want to save the second 6 check-in 3 files TDMS (2 seconds). However, I couldn't do my codes work in the required way (attached). I have identified two problems that are beyond my skills.
1. "some or all of the requested samples are not yet acquired. It's weird, because I already have the function of "DAQmx Read" provided that only when there is sample to read.
2. instead of save data to 3 TDMS files, only one file is generated.
I am grateful for your help. Thank you very much.
luojh135 wrote:
Hi guys, I am preparing Labview codes for reocording synchronized analogy and reading. Specifically, I want to record for 6 seconds, while the sounds of output for 5 seconds. This means that the analogue output stop 1 second before the end of the recording. In addition, I want to save the second 6 check-in 3 files TDMS (2 seconds). However, I couldn't do my codes work in the required way (attached). I have identified two problems that are beyond my skills.
1. "some or all of the requested samples are not yet acquired. It's weird, because I already have the function of "DAQmx Read" provided that only when there is sample to read.
2. instead of save data to 3 TDMS files, only one file is generated.
I am grateful for your help. Thank you very much.
You have a beautiful mess! (Sorry, but you do) Your little logic code.
First of all, if you want to save data to a file aDAQmx TDMS task do it! Enable logging of data it will greatly simplify your diagram to the point where some of the other problems become more obvious.
Now, let us look at this section:
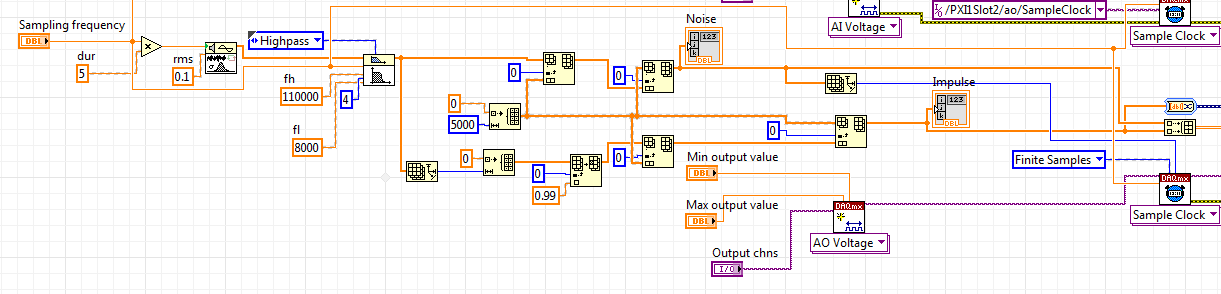
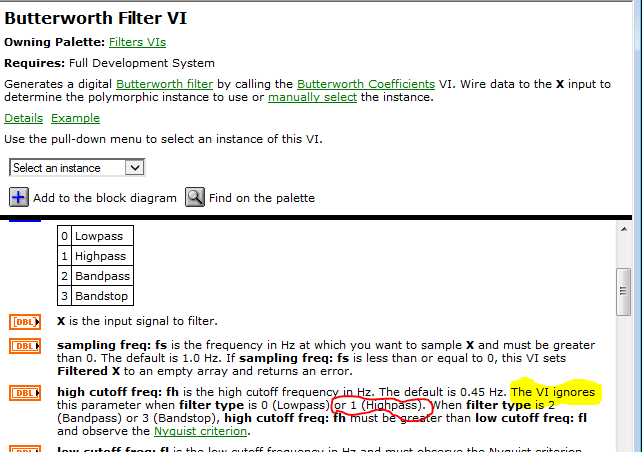
In the present, I can that you used to be a programmer of text. These subsets 'replace Array' actually boggle my mind! Why replace the first element of the tables full of zeros? and why is it a picture of 5,000 items? Looks like you put 5000 zeros on the front and back of the noise AND stuffing a 0.99 in the first element of an array of 5000 zeros only to replace the range of a 0.99 and 4999 zeros with a table of 5000 zeros TWICE! (in case the first subset of the table replace did not work? WWYT?) But save a little... A high pass filter with fh = 11000 and fl = 8000?
Save the help file, we find:
Then, this constant 110000 doing here? (Other than ignored)
Save a little and you father a production 1.25 M points of noise Gaussian with a gap of 0.1, but the constant is labled rms. (Go fix it now before you confuse us no more!)

In all sincerity. I've seen worse but please correct obviously I did notice and we could be much more effective to help with the subtle substance which can always be wrong.
-
Comparing the differences in document?
I Standard Adobe Acrobat DC and cannot compare documents. Any help?
Hello
You do not have this option in Acrobat Standard.
Please take a look on the following document.
Plans and prices: compare plans | Adobe Acrobat DC
Concerning
Sukrit diallo
-
We run El Capitan and CC Adobe Creative Suite at work and need to cost justify a move.
Any information would be appreciated.
Thank you
-
by comparing the records with another table
Hello
I have the following 2 tables (test_prs & test_dep) and registers
My goal is to compare test_prs with test_dep records and return the records that are not in test_dep
Here is the table scripts
I tried the following query to meet my criteria. My output should be null, but all recordscreate table test_prs (id ,p_id ,r_id) as select 1,200566,200566 from dual union all select 2,200567,200567 from dual create table test_dep (id,de_typ,de_id,de_u_typ,de_u_id) as select 10,'AS',200566,'PG',200566 FROM DUAL UNION ALL select 11,'AS',200567,'PG',200567 FROM DUAL insert into test_dep select 12,'AS',400189,'PG',400273 FROM dual union all select 13,'AS',400273,'PG',400250 FROM dual union all select 14,'AS',400273,'PG',400192 FROM dual union all select 15,'AS',400273,'PG',400191 FROM dual insert into test_prs select 3,400273,400273 from dual
Could you please help me the sameselect * from test_prs prs where exists (select 1 from test_dep de where de.de_id !=prs.p_id and de.de_u_id !=prs.p_id )
Published by: smile on 7 March 2012 15:00Smile says:
Thanks for the requestThe query does not work with the following documents
insert into test_dep select 16,'AS',750664,'PG',750758 FROM dual insert into test_prs select 4,750758,750668 from dualthe r_id should not be put in correspondence with the columns in the test_dep table. P_id must only be put in correspondence
OK, you want to match against the de_id and the de_u_id p_id? Or a line where either p_id concordances r_id de_u_id or de_id must not be returned?
To match p_id against de_id and de_u_id, you can write the query like this:
select id, p_id, r_id from test_prs where p_id in (select p_id from test_prs minus select de_id from test_dep minus select de_u_id from test_dep);Brgds
Johan -
by comparing the data in the columns using SUBSTR
I have a column with a (VARCHAR2) number of cases and a column with a year (NUMBER) composed of similar data to:
CASENUMBER - YEAR
199713029 97
199713678 97
199713691 97
199713709 97
199713844 97
199714141 97
2001002718 01
2001002725 01
2001002894 01
95 U 9998-----------------------------------95
95 U 9999-----------------------------------95
96 A 0019-----------------------------------96
96 A 0058-----------------------------------96
96 A 0067-----------------------------------96
When I run this query:
I get this result:SELECT SUBSTR(LOCCASENUM,1,4) as FIRST_FOUR,SUBSTR(YEAR,1,2)as "test" FROM DATA_TABLE where SUBSTR(LOCCASENUM,1,4) != SUBSTR(YEAR,1,2)
FIRST FOUR - test_
1997 97
1997 97
1997 97
1997 97
1997 94
1997 97
2001 1
2001 1
2001 4
U - 95 95
U - 95 95
96 96
96 96
96 93
What I am wanting to do is to compare these two columns and display the ones who do not match. I don't know if I should do a LPAD on the year column or what. Can anyone help? Thank you
DeannaHello
Connected to Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 Connected as hr SQL> SQL> with data as( 2 select '199713029 ' as casenumber, 96 as year from dual union all 3 select '199713678 ' as casenumber, 97 as year from dual union all 4 select '199713691 ' as casenumber, 97 as year from dual union all 5 select '199713709 ' as casenumber, 97 as year from dual union all 6 select '199713844 ' as casenumber, 97 as year from dual union all 7 select '199714141 ' as casenumber, 97 as year from dual union all 8 select '2001002718' as casenumber, 01 as year from dual union all 9 select '2001002725' as casenumber, 01 as year from dual union all 10 select '2001002894' as casenumber, 01 as year from dual union all 11 select '95 U 9998 ' as casenumber, 95 as year from dual union all 12 select '95 U 9999 ' as casenumber, 95 as year from dual union all 13 select '96 A 0019 ' as casenumber, 96 as year from dual union all 14 select '96 A 0058 ' as casenumber, 96 as year from dual union all 15 select '96 A 0067 ' as casenumber, 96 as year from dual) 16 select * from data where case length(substr(regexp_substr(casenumber, '[0-9]+'),1,4)) when 2 then substr(regexp_substr(casenumber, '[0-9]+'),1,4) else substr(regexp_substr(casenumber, '[0-9]+'),3,2) end = year; CASENUMBER YEAR ---------- ---------- 199713678 97 199713691 97 199713709 97 199713844 97 199714141 97 2001002718 1 2001002725 1 2001002894 1 95 U 9998 95 95 U 9999 95 96 A 0019 96 96 A 0058 96 96 A 0067 96 13 rows selected SQL>Kind regards
-
Comparation between database XE and 10 gr 2
Hello everyone.
I want to compare the differences between Oracle Database XE and Oracle Database 10 G.
I guess that would be a document where this comparation is made.
Can someone send me the link where it is?
Thanks in advance and greetings to all.selezeus wrote:
Hello everyone.I want to compare the differences between Oracle Database XE and Oracle Database 10 G.
I guess that would be a document where this comparation is made.
Can someone send me the link where it is?
Thanks in advance & kind regards to all.
Now, it is not such a document for 10g and XE on the Oracle Web site. They have updated the document to 11g.
I found one on the net, this is a PDF document, and it's for 10g:
http://software.bestcom.com.tw/down/dwon_file.aspx?file=20070808145418ABKwQ.PDF&filetype=9&DC_ID=9
Best regards
Grosbois
-------------------------------------------------------
If you answer this question, please mark appropriate as correct/useful messages and the thread as closed. Thank you -
I get a new hard Hard Drive (SSD). The new disc is the same size as my existing SATA drive. I can do either a new
the installation of Windows 7 or a clone old hard drive? I would prefer to clone the old hard drive and keep all my settings, etc. It's empirical data on the performance difference between a new installation of Windows 7 or to continue with the Windows 7 which was 3 or 4 years ago.
I know the conventional wisdom is that the new installation is faster, but, no matter who actually tested and compared the differences? I know I'll get better performance of the SSD the SATA drive, but I don't know if it's worth the hassle to do a fresh install and redo all my programs and settings.
Others that the performance of the SSD you should not see any differences. If you do, you can always do a clean installation later.
-
get the difference in seconds to a time warp
I need to find a way faster than:
(
To_date (to_char (TO_NUMBER (utc_date_new)), 'YYYYMMDDHH24MISS')-
To_date (to_char (TO_NUMBER (utc_date_old)), 'YYYYMMDDHH24MISS')
) * 1440
Thanks... ;(Hello
Rusty75 wrote:
Sorry, and Yes, his minutes (under a strain here)column has been defined as TIME_UTC VARCHAR2(14 BYTE) NOT NULL
So basically it's a bad situation
How heavy this weighing in a join will select the instruction?
for example, left to join an intermediate table (200,000), with a huge table (40.000.000 rows)
where is equal to staging.varchar indexed field huge varchar field table
AND that calculated the difference > 5?See [when your query takes too Long | http://forums.oracle.com/forums/message.jspa?messageID=1812597#1812597] for what you must post to get advice on the setting.
Are you saying that the part of the join condition which is the date of a table must be at least 5 minutes later at the time of the other table? In other words, you're doing something like:FROM staging s LEFT OUTER JOIN huge_table h ON h.txt = s.txt AND ( TO_DATE (s.utc_date_new, 'YYYYMMDDHH24MISS') - TO_DATE (h.utc_date_old, 'YYYYMMDDHH24MISS') ) * 1440 > 5If so, try to change the terms of join like this:
FROM staging s LEFT OUTER JOIN huge_table h ON h.txt = s.txt AND h.utc_date_old < s.utc_date_new AND ( TO_DATE (s.utc_date_new, 'YYYYMMDDHH24MISS') - TO_DATE (h.utc_date_old, 'YYYYMMDDHH24MISS') ) > (5 / 1440)Even if the new condition (the other,
AND h.utc_date_old < s.utc_date_neware covered by the third condition, it can leave a lot of matches be excluded without a conversion from VARCHAR2 to this DAY.
Also, don't multiply each difference in 1440; Just compare the difference within days to a constant. I don't know if the optimizer is smart enough to do it for you, but why take the risk?would be to limit the calculation to: to_date (to_number (nw.time_utc), \'YYYYMMDDHH24MISS\')
give a significant increase in speed?I think it's the opposite. The first TO_DATE argument must be a string; the above expression is to convert the string to a NUMBER (which takes a while), and while the NUMBER is implicitly converted to a VARCHAR2 (which takes more time).
-
To begin with, I am the HelpDesk of the company and our users are running Windows 7, Vista and XP. The problem will occur randomly on most XP and Vista systems.
I'm beginning to believe that it is a computer problem to the extent of the material or something of this nature.
For now, I swapped the computer and now the question is not fooled by the user.
But in general I wanted to know why this happens. They will be blocked (not a stop) their computer to take a lunch break and when they return to log in order to return to work. They work on two monitors and for some reason, as the settings go back to the single screen...
Why this keep happening? Help, please?
Either way, I don't think it's a driver problem... Because I just run images on hard drives of all application users run and the problem occurs randomly.
Thanks in advance for your response...
Adolfo
Hello
The Microsoft Answers community focuses on the context of use. Please join the professional community of COMPUTING in the TechNet forum below
http://social.technet.Microsoft.com/forums/en-us/category/windowsxpitpro
-
The column that does not match when comparing two records
Hi all
We try to compare two tables and find the differences. So if two records (1 of each table) have same PK but not always matching because of some columns, then we would display this columnname. For example:
Table 1
PK Parent Child Property1 Property2 1 A A1 P1 PR1 2 B B1 P2 oraPR2 3 C C1 P3 SRP Table 2
PK Parent Child Property1 Property2 1 A A1 P1 PR1 2 B B1 P2 PR2 3 C C1 P3 PR4 In the above example when I compare 2 tables all matches except Property2 online n ° 3. Thus, we would like to get an output like:
PK Column_Mismatch 3 Property2 (this must be the name of the column that does not match) Appreciate the help.
Thank you
Andy
Hi, Andy.
Andy1484 wrote:
Hi all
We try to compare two tables and find the differences. So if two records (1 of each table) have same PK but not always matching because of some columns, then we would display this columnname. For example:
Table 1
PK Parent Child Property1 Property2 1 A A1 P1 PR1 2 B B1 P2 oraPR2 3 C C1 P3 PR3 Table 2
PK Parent Child Property1 Property2 1 A A1 P1 PR1 2 B B1 P2 PR2 3 C C1 P3 PR4 In the above example when I compare 2 tables all matches except Property2 online n ° 3. Thus, we would like to get an output like:
PK Column_Mismatch 3 Property2 (this must be the name of the column that does not match) Appreciate the help.
Thank you
Andy
Why you don't want no matter what exit for pk = 2? Property2 does not correspond either to pk.
What happens if the 2 columns (or more) do not match? The following query would produce a list delimited, such as ' parents; PROPERTY2 '.
WITH got_mismatch AS
(
SELECT pk
, CASE WHEN t1.parent <> t2.parent THEN '; PARENT' END
|| CASE WHEN t1.child <> t2.child THEN '; CHILD ' END
|| CASE WHEN t1.properry1 <> t2.property1 THEN '; PROPERTY1 ' END
|| CASE WHEN t1.properry2 <> t2.property2 THEN '; PROPERTY2 ' END
AS the offset
FROM table_1 t1
JOIN table_2 t2 ON t2.pk = t1.pk
)
SELECT pk
, SUBSTR (incompatibility, 3) AS column_mismatch
OF got_mismatch
WHERE mismatch IS NOT NULL
;
If you would care to post CREATE TABLE and INSERT statements for your sample data, and then I could test this.
The query above does not count NULL values as inadequate. If you want that, the same basic approach will work, but you can use DECODE instead of <> to compare columns.
What happens if a pk exist in a table, but not the other? You want an outer join, where I used an inner join above.
Maybe you are looking for
-
How can I remove the 'State' that wants an installation package "status.msi" I do not have?
This laptop does not accept even in SP3. It doesn't have enough RAM for Win7. I got rid of bad bits with chkdsk. Status tries to install all the time & I can't find how to remove it.
-
How can I configure my exe associations... None of my exe shortcuts work
When I click on any exe file I get a pop up to association set... dunno what happens... all antivirus scans are negative, defragmented and cked reg
-
I had for a while but his discarded ista recently and I want to do a clean reinstall but don't have vista disc I have code tho what can do
-
Deleting files from the downloads folder
Deleting files from my downloads folder delete them will form my laptop?
-
Can I know how to work the dvd player function