Calculation associated Allocation inconsistency
Oracle Database 10 g Express Edition Release 10.2.0.1.0 - productI have the following table
CREATE TABLE "ALLOCATEASSOCIATES"
( "PROJID" VARCHAR2(30) NOT NULL ENABLE,
"ASSOCIATEID" NUMBER(*,0) NOT NULL ENABLE,
"ALLOCATIONSTARTDATE" DATE,
"ALLOCATIONPERCENT" NUMBER(*,0),
"ENDDATE" DATE,
PRIMARY KEY ("PROJID", "ASSOCIATEID") ENABLE
)
insert into allocateassociates values ('proj2',2,to_date('04/01/2012','mm/dd/yyyy'),25,to_date('06/15/2012','mm/dd/yyyy'))
insert into allocateassociates values ('proj1',2,to_date('04/16/2012','mm/dd/yyyy'),50,to_date('06/30/2012','mm/dd/yyyy'))
insert into allocateassociates values ('proj3',2,to_date('07/01/2012','mm/dd/yyyy'),100,'')1. a partner is to be distributed on at least giving a maximum of 100% at a time time
2. the user selects 2 dates between which lack of uniformity of distribution should be displayed
If the end user selects April 1, 2012 and July 31, 2012 between what reports must be generated,
I am looking for the following output
ASSOCIATE_ID FROM_DATE TO_DATE ALLOCATION_INCONSISTENCY
2 01-APR-12 15-APR-12 75
2 16-APR-12 15-JUN-12 25
2 16-JUN-12 30-JUN-12 50However, there is no deficit of distribution for the month of July as it is allocated 100% for this month and therefore does not appear in the expected results.
Help, please
Concerning
Prmk
Hello
MAG says:
Thank you both of you for such a quick reply.I want a little change by calling upon the date of rally of the partner in the organization.
CREATE TABLE "ASSOCIATES" ( "ASSOCIATEID" NUMBER(*,0) NOT NULL ENABLE, "STARTDATE" DATE, "ENDDATE" DATE, PRIMARY KEY ("ASSOCIATEID") ENABLE ) insert into associates values (2,to_date('03/01/2012','mm/dd/yyyy'),'')
Well, then you have another table, show above.
I guess that the allocateassociates table is the same as in your last post.
I see that you want the settings are Marc 1 (not April 1), 2012 to 31 July 2012.
What are the outcomes for these new data? Display the accurate results, as you did in your first post. It's great to talk about what the results are, but do in addition to (not instead of) showing in fact.
If the report is generated from 1 March 2012 instead of April 1, 2012, the report is expected to show the inconsistency for the month of March the distribution begins April 1
Concerning
Prmk
I think you need to add 2 branches in addition to the UNION in the events of the subquery. Like my previous solution generated 2 ranks in events for a single line in allocateassociates (a new line for the events of early, the other for an end event), so the new branches will add 2 rows to the events of a single line in associates. New partners have a 0% allocation when they start. After the departure of employees, we treat their allocation as 100%.
WITH params AS
(
SELECT TO_DATE ('01-Feb-2012', 'DD-Mon-YYYY') AS reportstartdate
, TO_DATE ('31-Jul-2012', 'DD-Mon-YYYY') AS reportenddate
FROM dual
)
, events AS
(
SELECT ab.projid
, ab.associateid
, GREATEST ( ab.allocationstartdate
, pb.reportstartdate
) AS eventdate
, ab.allocationpercent
FROM allocateassociates ab
JOIN params pb ON ab.allocationstartdate <= pb.reportenddate
AND NVL ( ab.enddate
, TO_DATE ('12-Dec-9999', 'DD-Mon-YYYY')
) >= pb.reportstartdate
UNION ALL
SELECT aa.projid
, aa.associateid
, LEAST ( NVL ( aa.enddate
, TO_DATE ('12-Dec-9999', 'DD-Mon-YYYY')
)
, pa.reportenddate
) + 1 AS eventdate
, -aa.allocationpercent AS allocationpercent
FROM allocateassociates aa
JOIN params pa ON aa.allocationstartdate <= pa.reportenddate
AND NVL ( aa.enddate
, TO_DATE ('12-Dec-9999', 'DD-Mon-YYYY')
) >= pa.reportstartdate
--
-- ********** The section below was added to include the associates table **********
--
UNION ALL
SELECT NULL AS projid
, ah.associateid
, GREATEST ( ah.startdate
, ph.reportstartdate
) AS eventdate
, 0 AS allocationpercent
FROM associates ah
JOIN params ph ON ah.startdate <= ph.reportenddate
AND NVL ( ah.enddate
, TO_DATE ('12-Dec-9999', 'DD-Mon-YYYY')
) >= ph.reportstartdate
UNION ALL
SELECT NULL AS projid
, al.associateid
, LEAST ( NVL ( al.enddate
, TO_DATE ('12-Dec-9999', 'DD-Mon-YYYY')
)
, pl.reportenddate
) AS eventdate
, 100 AS allocationpercent
FROM associates al
JOIN params pl ON al.startdate <= pl.reportenddate
AND NVL ( al.enddate
, TO_DATE ('12-Dec-9999', 'DD-Mon-YYYY')
) >= pl.reportstartdate
--
-- ********** The section above was added to include the associates table **********
--
)
, got_allocationinconsistency AS
(
SELECT projid
, associateid
, eventdate AS fromdate
, LEAD (eventdate)
OVER ( PARTITION BY associateid
ORDER BY eventdate
) AS todate
, 100 - SUM (allocationpercent)
OVER ( PARTITION BY associateid
ORDER BY eventdate
) AS allocationinconsistency
FROM events
)
, got_grp AS
(
SELECT associateid
, fromdate
, todate
, allocationinconsistency
, ROW_NUMBER () OVER ( PARTITION BY associateid
ORDER BY fromdate
, projid
)
- ROW_NUMBER () OVER ( PARTITION BY associateid
, allocationinconsistency
ORDER BY fromdate
, projid
) AS grp
FROM got_allocationinconsistency
)
SELECT associateid
, MIN (fromdate) AS fromdate
, MAX (todate) - 1 AS todate
, allocationinconsistency
FROM got_grp
WHERE allocationinconsistency > 0
AND todate IS NOT NULL
GROUP BY associateid
, allocationinconsistency
, grp
ORDER BY associateid
, fromdate
;
Published by: Frank Kulash, October 18, 2012 16:03
Append query
Tags: Database
Similar Questions
-
Calculated field rounded inconsistency
In a calculated field values are rounded inconsistently. A computed value of 20,0755 rounds down to 20.07 but 19.855 towers up to 19.86. Because the computed value is a sum of money, this inconsistency is originally the accounting discrepancies.
Do I need to adjust the bosses? (I do not understand the differences between the models available).
I tried to use the rounded in Math.Round in Javascript and FormCalc without change in the results.
Thank you!
Here is an example of update
Paul
-
What is "Bytes allocated" to a thread on the Graphics tab of latency JRA?
How calculated the "allocated bytes" on the JRA recording when the tab graphic latency and hovering on a thread?
I see 26,552,065,152 bytes allocated for a server that has only 2 GB of memory segment (JRA recording is 30 seconds), so I'm curious to know what means this number. This is in short the memory usage of all objects allocated in the 30 seconds? If so, the sum of the collected waste bytes and the sum of the additional objects in memory ('objects' tab) must be equal to the sum of the bytes allocated for each thread, right?
! http://S5.Tinypic.com/zy67eu.jpg!
Thank you
-BillThis is supposed to be an exact number in bytes of all the objects (if later alive or already GCed) allocated by the thread during the registration period.
See you soon,.
Henrik
-
Hard Vs soft analysis analysis
Hi all
Suppose I execute a SQL query, once it is executed it will get in the Shared pool.
Second time when I run the same query, that query will be in the shared pool. This second query execution time will not need of optimization and generate explain to new plan. It will use explain the plan used in the first execution of the query.
Now, suppose that the plan of the explain command used is not plan optimal and before you run the second query times I created some indexes on the tables used in the query and the indexes can improve the performance of queries.
Is it good or bad?
Optimizer generates plan still even in the analysis of soft or not?
OR
Soft and hard parsing analysis differed only in terms of "Load the code in the Shared Pool", rest steps are the same for Parse Soft and Hard Parse Optimzer run and find plan even in the analysis of Soft?
Two posts on hard Parse Soft Parse confusion:
http://www.DBA-Oracle.com/t_hard_vs_soft_parse_parsing.htm
https://asktom.Oracle.com/pls/asktom/f?p=100:11:0:P11_QUESTION_ID:2588723819082
There are significant errors in this text, for example:
QUOTE
- Loading in shared pool - SQL source code is loaded into RAM for parsing. (the analysis stage 'hard')
- ,,,
- ...
- Transformation of the query - Oracle will transform complex SQL in simpler forms, equivalent and replace the aggregations by materialized views, as the case may be. In earlier versions of Oracle the query_rewrite = true parameter should be defined for the rewriting of the materialized view.
- Optimization - Oracle, and then creates an execution plan, based on the statistics of your schema (or perhaps with 10 g dynamic sampling statistics). Oracle has build costs decision tree during this period, by choosing the track with the cost lowest perceived.
- ...
What is the difference between a hard and a soft analysis in Oracle? Just the first step, step 1 as shown in red above. In other words, a soft analysis does not require a reload shared pool (and associated allocation of RAM memory).
ENDQUOTE
This is wrong - or, at best, very wrong.
The CRITICISM of 'hard' analysis, is that an implementation plan should be created for the instruction; that the statement must be optimized. (In a modern version of Oracle, passing bly, query processing is not a discrete step that precedes the optimization). If the session can take the advantage of doing a 'mild' analysis, it means it didn't optimize instruction.
Concerning
Jonathan Lewis
-
Create a dynamic drop-down list field in Adobe Acrobat Pro XI
Hi all. I am creating a field in one of my forms using Adobe Acrobat Pro XI. I have a drop down list of 'core' items, and according to what is selected in the list, I want a second drop-down list to give different choices. I've searched and searched and have javascript that I thought might work, but maybe I'm have a mistake or I'm place javascript code in the wrong place, because it does not work. I know very, very little about javascript, any help would be so appreciated.
I use Adobe Acrobat Pro XI. I added a "new field" and selected "drop-down list. The domain name is ProvType. The options of the menu drop-down are:
Hospitalized patients
External consultations
Doctor
I have "Commit selected value immediately" selected. The field is not validated. The format is 'none '. There is no measures or calculations associated with it.
I then created another dropbox and named SubProvType. Under Actions, I selected the trigger as the mouse upwards and then selected the Action "executes a JavaScript script. I selected the Add button and he hit in the JavaScript editor:
Switch (ProvType.rawValue)
{
case "Hospitalisation":
this.setItems ("Hospice, hospital, Nursing Facility");
break;
"outpatient": case
this.setItems ("adult day Center, Home, others");
break;
case 'doctor ':
this.setItems ("surgeon, general practitioner, neurologist");
break;
}
What I want to do is:
If "Hospitalization" is selected, I want only the following options to be available in the second drop-down list box "SubProvType":
Palliative care
Hospital
Nursing facility
If "outpatient" is selected, I want only the following options to be available in the second drop-down list box "SubProvType":
Adult day Center
Home
Other
If the 'doctor' is selected, I want these options to be available in the second drop-down list box "SubProvType":
Surgeon
Family practice
Neurologist
However... when I close form editing and try to select a different option in the ProvType field, SubProvType field is left blank and there is no options available. Also, there are no errors.
I must be missing something, but I have no idea where to start. Thank you in advance for any help anyone can provide.
Use this code as the ProvType custom validation script (and remove any code that you have associated with SubProvType):
switch (event.value) { case "Inpatient": this.getField("SubProvType").setItems(["Hospice,Hospital,Nursing Facility"]); break; case "Outpatient": this.getField("SubProvType").setItems(["Adult Day Center,Home,Other"]); break; case "Physician": this.getField("SubProvType").setItems(["Surgeon,Family Practice,Neurologist"]); break; } -
Calculation Effort when projected to double to association lab
Oracle Database 10 g Express Edition Release 10.2.0.1.0 - product
I have the following tables I used to get the effort of an associate.
The below query works to get the associated effort wiseCREATE TABLE "ADDASSOCIATE" ( "ASSOCIATEID" NUMBER(9,0) NOT NULL ENABLE, "STARTDATE" DATE, "ENDDATE" DATE, "ASSOCIATENAME" VARCHAR2(20), PRIMARY KEY ("ASSOCIATEID") ENABLE ) CREATE TABLE "ADDPROJECT" ( "PROJID" VARCHAR2(30) NOT NULL ENABLE, "PROJNAME" VARCHAR2(30), "PROJSTARTDATE" DATE, "PROJENDDATE" DATE, "PARENTPROJID" VARCHAR2(30), "PROJTYPE" VARCHAR2(30), "PROJSTATUS" VARCHAR2(30), PRIMARY KEY ("PROJID") ENABLE ) CREATE TABLE "ALLOCATEASSOCIATES" ( "PROJID" VARCHAR2(30) NOT NULL ENABLE, "ASSOCIATEID" NUMBER(*,0) NOT NULL ENABLE, "ALLOCATIONSTARTDATE" DATE, "ALLOCATIONPERCENT" NUMBER(*,0), "ENDDATE" DATE, PRIMARY KEY ("PROJID", "ASSOCIATEID") ENABLE ) CREATE TABLE "ADDLAB" ( "LABID" VARCHAR2(30) NOT NULL ENABLE, "LABTYPE" VARCHAR2(30), "LABNAME" VARCHAR2(20), PRIMARY KEY ("LABID") ENABLE ) CREATE TABLE "PROJECTTOLABASSOCIATION" ( "LABID" VARCHAR2(30) NOT NULL ENABLE, "PROJID" VARCHAR2(30) NOT NULL ENABLE, "STARTDATE" DATE, "ENDDATE" DATE, "STATUS" VARCHAR2(30), PRIMARY KEY ("LABID", "PROJID") ENABLE ) insert into addassociate values (1,to_date('04/01/2012','mm/dd/yyyy'),'','Asso1') insert into addassociate values (2,to_date('04/01/2012','mm/dd/yyyy'),'','Asso2') insert into addassociate values (3,to_date('04/01/2012','mm/dd/yyyy'),'','Asso3') insert into addassociate values (4,to_date('04/01/2012','mm/dd/yyyy'),'','Asso3') insert into addproject values ('proj1','projname 1', to_date('04/01/2012','mm/dd/yyyy'),'','','Research','Status') insert into addproject values ('proj2','projname 2', to_date('04/01/2012','mm/dd/yyyy'),'','','Research','Status') insert into addproject values ('proj3','projname 3', to_date('04/01/2012','mm/dd/yyyy'),'','','Research','Status') insert into ALLOCATEASSOCIATES values ('proj1',1, to_date('04/01/2012','mm/dd/yyyy'),50,'') insert into ALLOCATEASSOCIATES values ('proj2',1, to_date('04/01/2012','mm/dd/yyyy'),50,'') insert into ALLOCATEASSOCIATES values ('proj2',2, to_date('04/01/2012','mm/dd/yyyy'),100,'') insert into ALLOCATEASSOCIATES values ('proj3',3, to_date('04/01/2012','mm/dd/yyyy'),100,'') insert into ALLOCATEASSOCIATES values ('proj1',4, to_date('04/01/2012','mm/dd/yyyy'),100,'') insert into ADDLAB values ('lab1','Research','lab name 1') insert into ADDLAB values ('lab2','Research','lab name 2') insert into ADDLAB values ('lab3','Research','lab name 3') insert into PROJECTTOLABASSOCIATION values ('lab1','proj1',to_date('04/01/2012','mm/dd/yyyy'),'','Status') insert into PROJECTTOLABASSOCIATION values ('lab2','proj1',to_date('04/01/2012','mm/dd/yyyy'),'','Status') insert into PROJECTTOLABASSOCIATION values ('lab2','proj2',to_date('04/01/2012','mm/dd/yyyy'),'','Status') insert into PROJECTTOLABASSOCIATION values ('lab3','proj3',to_date('04/01/2012','mm/dd/yyyy'),'','Status')
There is a short coming in the above query. For example;-proj1 has been associated with both lab1 and lab2. Where the result contains 2 entries for lab1 and lab2 for. When the total effort should have been 3.6 people per month to partner with the id 1 for proj1, the effort is displayed as 3.6 twice, one entry for lab1 and lab2 for.select ap.projid,ap.projname,al.labname,aa.associateid, to_char(MONTHS_BETWEEN(1 + LEAST(NVL(aa.endDate, to_date('04/01/2100','mm/dd/yyyy')),sysDate) , GREATEST(aa.allocationstartdate ,ap.projStartDate)) * aa.allocationpercent / 100,'999.99') AS Effort from AllocateAssociates aa, AddAssociate a, AddProject ap, ProjecttoLabAssociation pl,AddLab al WHERE aa.projid = ap.projid AND a.associateid = aa.associateid AND pl.projID = ap.projID AND al.labID = pl.labID
So for the scenario above, the assignment of associated with a laboratory should be taken into account for the calculation of the effort. The allocation of laboratory is obtained from the table below
This is the expected result:CREATE TABLE "ALLOCATEASSOCIATESTOLAB" ( "LABID" VARCHAR2(30) NOT NULL ENABLE, "ASSOCIATEID" NUMBER(*,0), "ALLOCATIONSTARTDATE" DATE, "ALLOCATIONPERCENT" NUMBER(*,0), "ENDDATE" DATE, PRIMARY KEY ("LABID", "ASSOCIATEID") ENABLE ) insert into ALLOCATEASSOCIATESTOLAB values ('lab1',1, to_date('04/01/2012','mm/dd/yyyy'),100,'') insert into ALLOCATEASSOCIATESTOLAB values ('lab2',2, to_date('04/01/2012','mm/dd/yyyy'),100,'') insert into ALLOCATEASSOCIATESTOLAB values ('lab3',3, to_date('04/01/2012','mm/dd/yyyy'),100,'') insert into ALLOCATEASSOCIATESTOLAB values ('lab2',4, to_date('04/01/2012','mm/dd/yyyy'),100,'')
Can you help plsPROJID PROJNAME LABNAME ASSOCIATEID EFFORT proj1 projname1 lab name 1 1 3.6 proj2 projname2 lab name 2 2 3.6 proj3 projname3 lab name 3 3 7.19 proj1 projname1 lab name 2 4 7.19
Concerning
PrmkHello
That's what you asked for:
WITH pl AS ( SELECT labid , projid , startdate , enddate , COUNT (DISTINCT labid) OVER (PARTITION BY projid) AS lab_cnt FROM projecttolabassociation ) SELECT p.projid , p.projname , l.labname , ap.associateid , TO_CHAR ( MONTHS_BETWEEN ( 1 + LEAST ( NVL ( ap.endDate , TO_DATE ('04/01/2100','mm/dd/yyyy') ) , SYSDATE ) , GREATEST ( ap.allocationstartdate , p.projStartDate ) ) * ap.allocationpercent / 100 , '999.99' ) AS effort FROM addproject p JOIN allocateassociates ap ON ap.projid = p.projid JOIN addassociate a ON a.associateid = ap.associateid JOIN pl ON pl.projid = p.projid JOIN addlab l ON l.labid = pl.labid LEFT JOIN allocateassociatestolab al ON al.associateid = a.associateid AND al.labid = l.labid AND pl.lab_cnt > 1 WHERE pl.lab_cnt = 1 OR al.labid = l.labid ORDER BY projid , projname , labname ;Output (when SYSDATE is November 9, 2012 00:00:00):
PROJID PROJNAME LABNAME ASSOCIATEID EFFORT ------ ---------- ---------- ----------- ------- proj1 projname 1 lab name 1 1 3.65 proj1 projname 1 lab name 2 4 3.65 proj2 projname 2 lab name 2 1 3.65 proj2 projname 2 lab name 2 2 7.29 proj3 projname 3 lab name 3 3 7.29 proj3 projname 3 lab name 3 4 3.65 -
Hearing of opening first OMFs - inconsistency of file association
Hello
I am an engineer working in hearing (CC 2015 build 8.1.0.162) on OS 10.11.4. I have problems opening OMFs. While about 90 percent of the files open as expected, up to 10% of the files opened as either the wrong file, or in the wrong position in the timeline or with the wrong part of the clip is playing.
The most common problem that I have is this, for example:
Tracks 4-8 are public room mics for the entirety of the timeline. Throughout the project of 60 min cuts every minute there 5 minutes. Random (apparently) to, say, change it to 22m35s Track5 suddenly plays a piece of music until the next edition, date to which it refers to the correct file. The file in the timeline panel has the name, but when I make reference to this file ("reveal in finder" or "reveal to the project"), it brings me to another file. I can go back to the original video editor and no indication why this would happen; everything is very good.
My first guess is that it's a problem of compatibility between video applications, export the file, and the hearing. But I had this problem even if OMFs from FCP, FCPX or first. Slowly, project after project, I was able to get video editors using the same first version/version as my hearing version and I still have the same problems. I'm even went so far as to get the video editing files on my computer and internal, but I always find myself with the same types of associations of stray files and training courses. Sometimes a simple reopening of the OMF will solve this problem, but you can't always tell if she did. In addition, you would think that everything worked just to join the 800th edit point and find another problem. Can I have the project open in first with everything intact and switch on hearing with different files played in the exact same task in the timeline panel.
According to me, I met each type of error, which you get when you export OMFs/XMLs/etc.
Before getting into the details more someone else met this kind of problem when opening OMFs in hearing?
Thank you in advance,
Craig
Workflow favorite of Edit > edit in Adobe Audition > sequence... of Premiere Pro is not to be on the same machine. It gives actually just hearing an XML part that is custom under the hood, and you can send that, as you would with an OMF. This menu (see screenshot), you can have a Premiere Pro creates a reference DV file, but if you are not on the same machine, it would be preferable to manually create a reference video, as you would with an OMF. In this case, maybe is a good choice in the H.264 codec, but it is up to you.

So the settings I have in the screenshot, simply write the XML code and media (such as a referenced OMF) files and I unchecked open in Adobe Audition for organization is trying to launch the Audition on the same machine.
Regarding your question OMF, we would be happy to take a look, but for this to be effective, we'd watch a smallish OMF where you can reproduce the problem. Or, you can post screenshots of your problem on the forum and who could help in the meantime.
-
First HP Calculator virtual missing mfc120u.dll error since upgrading to version 1.21.8151.102
The first HP Virtual calculator will not start since the last update (version 1.21.8151.102). A windows system error window appears when you attempt to start the calc virt, saying: "the program can't start because mfc120u.dll is missing on your computer. Try reinstalling the program to fix this problem. »
Needless to say that "resettlement" has not fixed the problem. It is clear from research that the specified DLL is associated with related debug versions if you wonder if the last version was poorly built? Does anyone else have this problem? Any solution of HP? I had to go back to my "shipped" version that is less than optimal. It has been no problem so far with my device real first HP since the last update of the firmware so phew... but the virtual calc is very convenient when working on the PC with the code.
I am running windows 7 64 bit - all the latest updates applied to MS etc had no problem until this version of the vCalc
A possible scenario:
- During installation, the 64-bit OS is recognized and installed the 64-bit version of the redistributable.
- The emulator is probably a 32-bit version (compatibility, 32-bit programs usually work on 64-bit systems, but not vice versa).
- There looking for the 32-bit version of the redistributable is not installed.
Note, this is one of the many possibilities in the world of software. However, the fact that 32-bit programs require the redistributable 32-bit and 64-bit programs require 64-bit redistributable is why I suggested to install both versions. It is not only useful for the HP emulators, but many other programs (this is why I have so many people already installed).
Best regards.
-
Improved speed for the LabVIEW MathScript calculation
I use a MathScript node to perform calculations on a sbRIO FPGA module and the speed of these calculations is critical. What are some ways to improve the speed of calculations and y at - it a faster way to make calculations of MathScript matrix? If I belong the MathScript in a Subvi it will improve the speed of calculations?
Thanks for any ideas
Please look at the VI attached. She is your original code ".m", my changes to your ".m" and G code equivalent to the updated code ".m". First, let me describe the numbers that I've seen on a cRIO 9012 for each of the three approaches.
I ran to each of the three approaches for the hundreds of iterations, ignored the first 30 iterations to allow allocations of memory (which caused a huge spike in runtime performance about the RT), then took the average operation time for each iteration of the loop for the remaining iterations
Original M: 485 msec/iteration
Updated M: 276 MS/iteration
G: ms 166/iteration
The changes I made to your code ".m" are:
(1) added; at the end of each line to remove output (used for debugging)
(2) left random code generation - used whitenoise (seems like that is what you did)
(3) turn on the type of data highlighting the function. Noticed that the majority of data was cast in the complex, although that did not seem like you need the complex domain. The source has been function sqrt. Changed using real (sqrt (...))
This improvement in performance by more than 40%. I believe that more can be pressed if you follow the documentation - MathScript wrote for real-time Applications.
Then I took the MathScript you and equivalent written G leaving the algorithm as it is. This gave us the improvement of the performance of another 40 per cent in the G. updated the it is a known issue that on slow controllers, MathScript adds a penalty of 2 x to g equivalent. We are investigating this issue and may be able to fix it in a future release.
If you are profiling the G code, you will notice that most of the time we spend in the multiplication of matrices. Unless rethink you your algorithm, I doubt that this can further improve.
Let me know if you have any questions
Kind regards
Rishi Gosalia
-
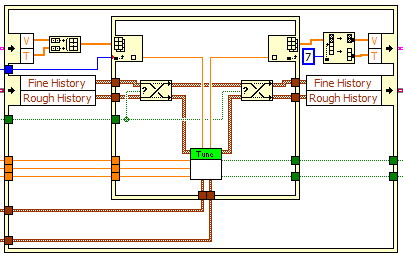
buffer allocation and minimizing memory allocation
Hello
I am tryint to minimize the buffer allocation and memory in general activity. The code will run 'headless' on a cRIO and our experience and that of the industry as a whole is to ellliminate or minimize any action of distribution and the dynamic memory deallocation.
In our case we treat unfortunately many string manipulations, thus eliminating all the alloc/dealloc memmory is significant (impossible?).
Which leaves me with the strategy of "minimize".
I did some investigation and VI of profiling and play with the structure "on the spot" to see if I can help things.
For example, I have a few places where I me transpoe a few 2D charts. . If I use the tool 'See the buffer allocations' attaced screenshot would indicate that I am not not to use the structure of the preliminary examination International, both for the operation of transposition of the table for the item index operations? As seems counter intuitive to me, I have a few basic missunderstanding either with the "show stamp" tool of the preliminary examination International, or both... The tool shows what a buffer is allocated in the IPE and will once again out of the International preliminary examination, and the 2D table converts has an allowance in and out, even within the IPE causing twice as many allowances as do not use REI.
As for indexing, using REI seems to result in 1.5 times more allowances (not to mention the fact that I have to wire the index numbers individually vs let LabVIEW auto-index of 0 on the no - IPE version).
The example illustrates string conversions (not good from the point of view mem alloc/dealloc because LabVIEW does not determine easily the length of the 'picture' of the chain), but I have other articles of the code who do a lot of the same type of stuff, but keeping digital throughout.
I would be grateful if someone could help me understand why REI seems to increase rather than decrease memory activity.
(PS > the 2D array is used in the 'incoming' orientation by the rest of the code, so build in data table to avoid the conversion does not seem useful either.)
QFang wrote:
-My reasoning (even if it was wrong) was to indicate to the compiler that "I do not have an extra copy of these tables, I'll just subscribe to certain values..." Because a fork in a thread is a fairly simple way to increase the chances of duplications of data, I thought that the function index REI, by nature to eliminate the need to split or fork, the wire of the array (there an in and an exit), I would avoid duplication of work or have a better chance to avoid duplication of work.
It is important to realize that buffer allocations do occur at the level of the nodes, not on the wires. Although it may seem to turn a thread makes a copy of the data, this is not the case. As the fork will result in incrementing a reference count. LabVIEW is copy-on-write - no copy made memory until the data is changed in fact, and even in this case, the copy is performed only if we need to keep the original. If you fork a table to several functions of Board index, there is always only one copy of the table. In addition, the LabVIEW compiler tries to plan operations to avoid copies, so if several branches read from a wire, but only it changes, the compiler tries to schedule the change operation to run after all the readings are made.
QFang wrote:
After looking at several more cases (as I write this post), I can't find any operation using a table that I do in my code that reduces blackheads by including a preliminary International examination... As such, I must STILL understand IPE properly, because my conclusion at the present time, is that haver you 'never' in them for use. Replace a subset of a table? no need to use them (in my code). The indexing of the elements? No problem. .
A preliminary International examination is useful to replace a subset of the table when you're operating on a subset of the original array. You remove the items that you want, make some calculations and then put back them in the same place in the table. If the new table subset comes from somewhere other than the original array, then the POI does not help. If the sides of entry and exit of International preliminary examination log between them, so there no advantage in PEI.
I am attaching a picture of code I wrote recently that uses the IPEs with buffer allocations indicated. You can see that there is only one game of allowances of buffer after the Split 1 table D. I could have worked around this but the way I wrote it seemed easier and the berries are small and is not time-critical code so there is no need of any optimization. These tables is always the same size, it should be able to reuse the same allowance with each iteration of the VI, rather than allocate new arrays.
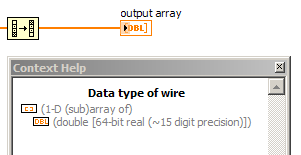
Another important point: pads can be reused. You might see a dot of distribution on a shift register, but that the shift register must be assigned only once, during the first call to the VI. Every following call to the VI reuses this very spot. Sometimes you do not see an allocation of buffer even if it happens effectively. Resizing a table might require copying the whole table to a new larger location, and even if LabVIEW must allocate more memory for it, you won't always a point of buffer allocation. I think it's because it is technically reassign an existing table instead of allocating a new, but it's always puzzled me a bit. On the subject of the paintings, there are also moments where you see a point to buffer allocation, but all that is allocated is a 'subfield' - a pointer to a specific part of an existing table, not a new copy of the data. For example 1 reverse D table can create a sub-table that points towards the end of the original with a 'stride' array-1, which means that it allows to browse the transom. Same thing with the subset of the table. You can see these subtables turning on context-sensitive help and by placing the cursor on a wire wearing one, as shown in this image.
Unfortunately, it isn't that you can do on the string allocations. Fortunately, I never saw that as a problem, and I've had systems to operate continuously for months who used ropes on limited hardware (Compact FieldPoint controllers) for two recordings on the disk and TCP communication. I recommend you move the string outside critical areas and separate loop operations. For example, I put my TCP communication in a separate loop that also analyses the incoming strings in specific data, which are then sent by the queue (or RT-FIFO) to urgent loops so that these loops only address data of fixed size. Same idea with logging - make all string conversions and way of handling in a separate loop.
-
Level of trust associated with the details of precision in the plug
What is the level of confidence associated with details of precision in the data sheet?
Specifically, I am interested in the analog input 9205. Technical sheet here: http://sine.ni.com/ds/app/doc/p/id/ds-190/lang/en
There is a table on 2/3 by the document called 'précision Détails', and I would like to know what the level of trust is for the numbers in the table. The reason is if I can use them in my measurement uncertainty calculation.
Thank you.
Now that I read through a lot of a manual of reference for the characterization of the ADC, I believe that the following terms in the table of absolute precision were calculated experimentally with at least 100 data points and a coverage of at least 3 factor:
GainTempco ·
ReferenceTempco
OffsetTempco ·INL_Error
NoiseUncertaintyThe rest of the values are derived from these, or are supposed to be conservative values to the estimate of the error. For example, the variation in temperature since the last calibration is assumed to be 70 degrees, because that's the maximum value supported temperature change in the temperature of the device has been calibrated at.
Each term in the equation has at least a factor of expansion of 3. Therefore, the absolute precision of the measure has a factor of expansion of 3.
Jeremy P.
-
IMAQ quantify - results of calculations
I have question regarding quantify IMAQ Toolbox Vision and movement function. I hope that the example vi joint explain what I mean. I would like to receive the associated results calculation to tagged image areas of the mask, not related to the area of the entire image. Is an effective way to achieve functionality that I need?
IMAQ quantify use vi LV_Quantify function. -What is the function of LV_Quantify_Bounded ?
Thanks in advance.
Sorry for the bad English

Hello
If you can ensure that your seuillee image is only binary (0 and 1), you can easily use the value 'Average value' to know the number of pixels binarize in each region. Take a look at the example that I modified.
Vladimir
-
The large paintings of calculation time
Dear friends, dear LabVIEW developers,
I'm trying to reduce the time of calculation for large bays. (In real life I'm eliminating unimportant vertices of a 3D mesh.)
Migration from 8.6 to 2011 already has done a great job for me. And also I am pleased to run Windows 7 on a 64-bit computer.
But, imagine a pointer-oriented language where you'd change an array element, you do not expect the computing time to change with the actual length of the table.
Here, I work on a wide range of groups of array of length may be different (rather short, containing the indexes of the neighbors of my vertex).
My problem is that I really don't see the reason why (I'm happy) the 100 times more slow performance when having a 100 times more great picture at hand for the fair value of the Exchange.
Suggestions to work around to get the speed of the large paintings those comparable to small is greatly appreciated.
Kind regards
Jannis
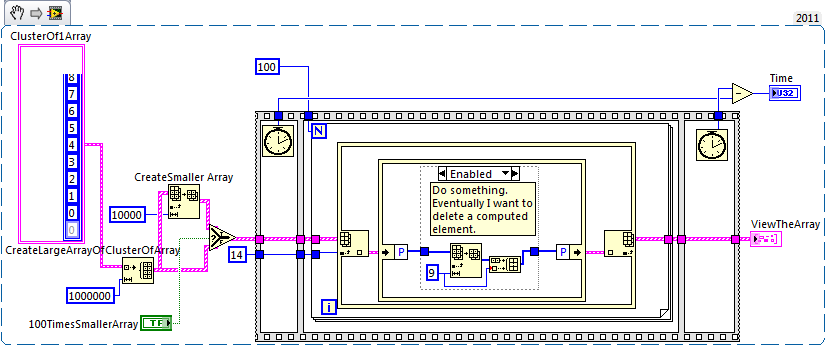
PS: I tried DataValueReferences but just the computing time to get 1 million references is almost an hour.
Thank you guys!
You were very good!
Steven and Ben worked have been my brand of test bench has been poorly implemented, which Ben explained perfectly. This test has sent me the ghost hunting awaits the delay time for the large windows in the wrong place - the structure in Place.
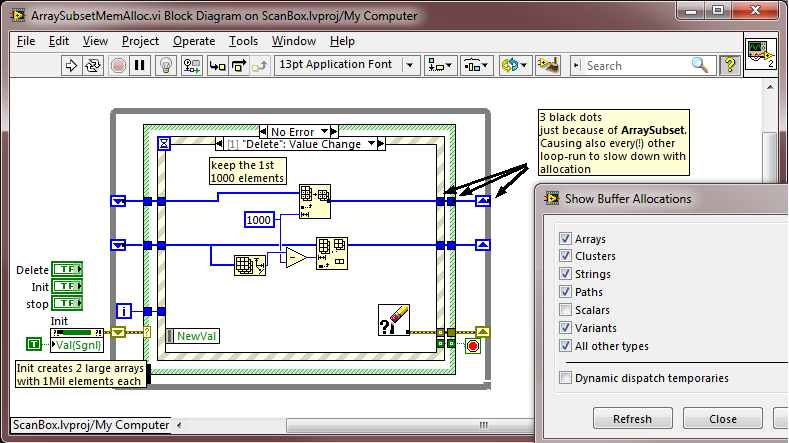
My next mistake was my local chaos with different versions LV and 3 PCs: Altenbach and Jeff are of course right about to maintain the constant size of matrix comes mark reduction in a separate meter. I did this at a time in a lost version later - and not a not spot the difference of between ArraySubset and DeleteFromArray the icon for a while...
My time holes had to be hidden somewhere else. Thanks Ben, unfortunately those black dots of BufferAllocation are a bit small for my old eyes. Not know them at the end of the event and while loops!
Each 15 seconds I actually shorten the big picture at its actual size to display it in the 3D graph. Now, here's the little interesting: ArraySubset actually redirect the memory at the end of the event and while loops, while DeleteFromArray only! I don't know who wrote somewhere, just not where easily see you...
And to make it really bad: this allowance is probably made with each loop run little matter what this case has done - slowing of all stocks with it. (By the way: everything as a mem alloc comes even inside a case that is not running!)
Once again thank you all. For me it's back to work after a very long-term wild-goose chase.
Jannis
-
internal allocation policy of VLAN ascendant
Hello
I was going to just throug a sample configuration n I came across this command
"internal allocation policy of vlan growing."
can some someone please tell me what is this command when we use this command
Thanks in advance
Hello
Yes, these VLANs are for the inner workings and are not configurable by you and most will not have physical ports are associated with them. There could be physical ports that their responsibilities for example. one of my switches
SZ-JFH-F00-DTE1 #sh vlan internal use
Use VLAN
---- --------------------
1006 diag online vlan0
1007 in line diag vlan1
1008 diag online vlan2
vlan3 diag online 1009
1010 diag online vlan4
1011 diag online vlan5
Process of 1012 PM vlan (tagging of trunk)
Protection Plan of control of 1013
1014 partial L3 multicast shortcuts for VPN 0
1015 output internal vlan
1016 multicast VPN 0 QS vlan
Multicast IPv6 multicast Egress 1017
1018 GigabitEthernet3/1
VLAN 1018 a port IG3/1 are entrusted to him. It's actually the connection trunk between the 6500 2 switches. But that did not stop me using IG3/1 and I have configured this port.
I guess the switch uses just as a reference.
HTH
Jon
-
Calculation of rule DSP for voice routers
Hi all, I know that Cisco has a DSP calculator, however, there are some values that he asks that I'm not sure of when you try to use it.
Someone at - it a fundamental rule that they use when they decide how much DSP to add a router to voice FMC?
I have a Cisco 2911 with 1 VIC2-4FXO, 1 port VIC3-2FXS/DID and currently I have a PVDM3 DSP DIMM 1 with 16 channels. I would add a VIC2-2FXO card for additional analog lines. I read that you need at least to have the same number or channels that you have FXS/FXO ports. If this is the case, then I am currently using only 6 of the 16 channels.
Here is the command of DSP Group:
DSP groups on slot 0:
DSP 1:
State: UP, firmware: 32.1.2
Signal/voice of max channel: 16/16
Max credits: 240, voice credits: 240, video credits: 0
num_of_sig_chnls_allocated: 6
Transcoding allocated channels: 1
Group: FLEX_GROUP_VOICE, complexity: FLEX
Credit splitting: 100, reserved credits: 0
Signs of the allocated channels: 6
Voice of the allocated channels: 0
Appropriations used (rounded): 0
Group: FLEX_GROUP_XCODE, complexity: MEDIUM
Credit splitting: 0, reserved credits: 20
Transcoding allocated channels: 0
Appropriations used (rounded): 0
Group: FLEX_GROUP_CONF, complexity: CONFERENCE
Credit splitting: 0, reserved credits: 120
Codec: CONF_G729, maximum of participants: 8
Sessions by dsp: 4
Slot: 0
Idx device: 0
PVDM slots: 0
Type DSP: SP2600Thank you
Dan
Yes, the most basic math are need at least the same number of channels on your DSP (s) that you would have TDM0 channels, which means that you will only use G.711, because the number of channels, G.711. This just for the termination of the TDM.
With what you have, if you decide to use G.729A/G.722, it would come down to 12 channels, with G.729/iLBC drops to 10, and you get only 3 channels, if you use the ICCS.

Maybe you are looking for
-
Qosmio G10: Scanner uninstall problems - cannot load the external DLL
I tried to uninstall an old scanner HP my Qosmio G10 and received the message - internal error unable to load or call external DLL, please contact you provider for more information. If I could use the product to restore disc and all saved this would
-
This should be simple - but I must be missing something... I have numbered documents before... For example, to create a 4-page word document. I want to Page 3 to be the first page of numbering. I insert a section break (next page) on Page 3. I insert
-
Your computer cannot connect to the remote computer
Hello OT: Your computer cannot connect to the remote computer because the remote desktop gateway server address request and the certificate subject name do not match. Contact your network administrator. I implement the remote desktop session based on
-
Intentionally slowing and stoppage
I would suggest a limit imposed on the number of "elbow hits" a player can receive per game (football match, not). I play an individual is currently voluntarily slow down game play. This person uses every second before you roll the dice, before mo
-
Original title: Everythinh went My grandson unintentionally (I think) installed my original disc of Widows Vista and apparently followed all the guests was, as all before today disappeared. How can I restore back to where was before this...