collection of regular expression match
In annexed "regex test.seq", I'm trying to copy a game collection in a table "for each" on all mathes.
Use the existing (System.Text.RegularExpressions.MatchCollection) Object. CopyTo (System.Array, Int32)
What I am doing wrong?
An exception occurred inside the call to the .NET 'CopyTo ': Member
System.ArgumentNullException: Value cannot be null.
Parameter name: dest
at System.Array.Copy (Array sourceArray, sourceIndex Int32, Array destinationArray, Int32 destinationIndex, Int32 length, Boolean reliable)
to System.Collections.ArrayList.CopyTo (Array array, Int32 arrayIndex)
to System.Text.RegularExpressions.MatchCollection.CopyTo (Array array, Int32 arrayIndex)
Hey Daniel-E
Thank you for your support.
I understand your point, but I'm stuck at 'For Each' on the 'obj table. Is this possible?
Instead, I found another way.
The goal is to read all the matched groups.
In the attached .seq, I used a normal for loop from 0 to the County group and then just reading, each of them...
BR Nikolaj
Tags: NI Software
Similar Questions
-
Regular expression matching is not what matches Pattern
I read a lot of posts on how match model does not match what match regular expressions will be due some characters does not.
However, I found a problem with the other way. A simple Reg - Ex who works in the match pattern but not regular Expression match.
What I have here is just an example. I want to use regular Expression Match then I can specify some matches under.
The reg - ex's: one or more non-numeric characters, a space, one or more numeric characters. At the beginning of the string.
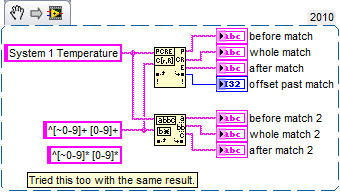
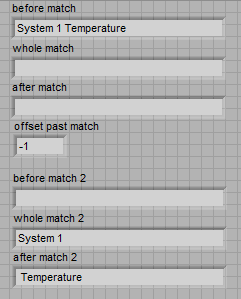
How can I get this to work in regular expression matching? I work in LabVIEW 2010f2 32 bit. Here is the code snippet and the results:
Rob
One of the subtle differences is the operator of negation for the character classes. In match pattern is ~, but for the Match RegEx is ^.
-
Analyze the Mac address with the regular expression matching
Hello world
I have a problem with the function of regular expression matching,
I try to analyse the response both a query arp - a 192.168.0.15 to retrieve the MAC address of the remote IP address, I used the following regular expression: ^ ([0-9a-fA-F]{2}[:-]){5}([0-9a-fA-F]{2})$
I wonder why should I do a subset of the first string to extract only the part of the MAC address. The regular Expression function is not able to recognize the regular expression directly in the middle of a string?
I only works when I extracted the subset of tring right as in the picture below.
Thanks for your replies.
Get rid of the "^" at the beginning of your regular expression. You are ordering him to find the model at the beginning of the string.
-
Multiline - Regular Expression Match string
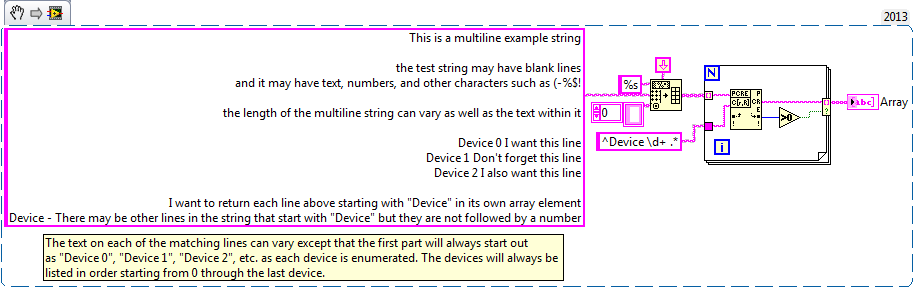
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
aaronb wrote:
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
Corresponding regular expression works well for this.
Ben64
-
pattern by using regular expressions match
I'm playing (and wrong) with regular expressions
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + > ') twice;
give < PSN > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.2 ') twice;
give < 231 > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.3 ') twice;
give < ABc > which confused me until I realized that < 3 25 > has not been matched, because it has a space inside
so I changed it to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ', 1.3) twice;
who gave a syntax error, so I changed it again to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ') twice;
that works, but gives < PSN > / # < 231 > # < 3 25 3 > / < ABc >
I guess because the. * corresponds to anyting that all but the last closure >
The question I have is how can I retrieve the text of mounting bracket included (even if it has multiple spaces)?
Hello
9c5dfde3-EAAE-45A7-80a1-bba8a71c826c wrote:
Thanks for that - is there a way to return all 4 surrounded by extracts of <> without resorting to PL/SQL?
Of course;
REGEXP_REPLACE (str
, '(^|>)[^<>
, '\1'
)
Returns a copy of str with all outside rafters removed, for example
<231><3 25=""> . It doesn't matter how many pairs of sharp hooks - there is.
-
Regular expression matching receives only two digit in brackets
Hello
I use the regular expression of the correspondence with the following expression. It is only able to get all the numbers that are not mere numbers. I want to retrieve all the values which lie between >< in="" the="" string="" and="" create="" an="">
Then
182 2 would be output
182
2
Any help would be appreciated. I've attached what I have so far. Right now I still have the >< and="" it="" can="" only="" grab="" numbers="" that="" are="" not="" single="">
Use (>.) [ ^(<>)]*)< *="" instead="" of="">
-
Regular expression matches the string starts by &
Hello
I'm writing a Reg Exp, which removes all string starts by '&' and ends by '; '. In other words, I am trying to remove something similar to:
Any help please.& nbsp; & quot; & lt; & gt;
It does not work:select regexp_replace (ename, ' ^ & [a - z] {2,4} [;] $') of PGE;
Kind regards
FatehLike this?
SQL> with t as 2 ( 3 select 'xyz & nbsp; test' str from dual 4 ) 5 select regexp_replace(str,'&.*?;') str 6 from t 7 / STR --------- xyz test -
Search for a string using "Game Plan" or "Regular Expression to Match."
Hello
I would use the 'game plan' or the vi "Expression regular game" simply because the products that provide these vi. The result that interests me is the substring 'after '. I want to be able to specify a "substring" and get everything after the substring of the input string. However, I'm getting all confused and/or watered upward when it comes to "regular expressions". Is there a way to create a "regular expression" which acts as a 'substring' to find within the input string?
The substring is a path of partial directory that contains a colon, backslashes, etc. which are part of a directory path. If some how the "regular expression" entry must ingnore all special characters and simply to understand if the substring in the string entry and give me 'all things' after the substring in the output of 'after the string.
Use Regular Expression Match instead of match pattern; It's better.
-
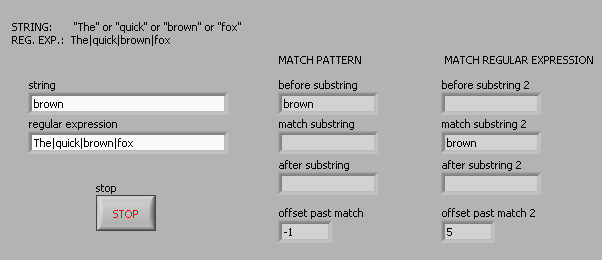
"Matches regular Expression" and "Model match" vi behaves differently
Hello
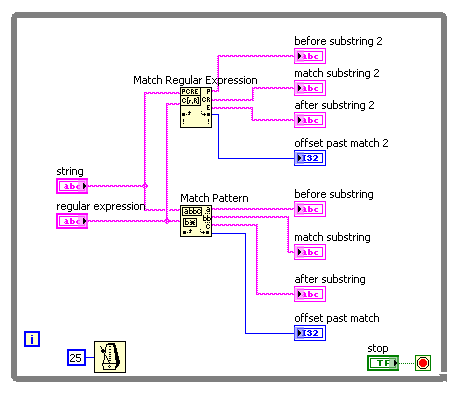
I need a simple matching chain and experimenting that found the "Regular Expression Match' and 'Correspondence model' vi behave a little differently. I guess that the entries of the regular expression on the two the same behavior. It's a difference that I discovered that the "|" character ("vertical" character, commonly used as an operator 'or') is recognized as such in the regex to Match vi, but not in the match vi model (where it is taken to the letter). Furthermore, I can't find any document using (online or in LabVIEW) on the ' | ' usage in regular expressions of character. Is - this documented anywhere?
For example, suppose I want corresponding to one of the following 4 words: 'The' or 'fast' or 'brown' or 'fox '. The regular expression ' the | fast | Brown | Fox' (without the quotes) works for the vi Regular Expression Match but not the match pattern vi. Here is a photo of the block diagram and the results of the façade:
The Help explains that the vi Regular Expression Match performs a little more slowly the match vi pattern, so I started with the latter. But since he does not work for me, I'll use the old. But does anyone have an idea of the speed difference? I guess that's negligible in a simple example.
Thank you!

Thank you, Jeff. That's what I was looking for. BUT my version of LabVIEW 8.5, does NOT say "functionfor example, the Match model does not support the parenthesis or vertical bars (|) characters.«» !
See: http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_pattern/
and http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_regular_expression/
It is not mentioned in the help of special characters used for the match pattern : http://zone.ni.com/reference/en-XX/help/371361D-01/lvhowto/specialcharformatchpatt/
The only place | has 'talked', it is in the sentence: "some regular expressions that use alternating (such as (. |))". \s)*) require significant resources to deal with when it is applied to the large input strings. "But I'm not processing a large chain.
It seems that NEITHER fixed this omission. What version is your help?
Ed
-
Complex regular expressions without multiple passes
Does anyone know of a tool that can handle more complex regular expressions without chaining of multiple copies of the VI regular expressions?
For example, if I have a XML string as
Power supply error has occurred.
Sorensen SGA166/188 and I am interested in the tag method to retry only, I could write a regular expression something like
.*
.* to parse the string inside the tag.
kc64 wrote:
For example, if I have a string like
My email address is [email protected]. Please no spamming not me.
and I am interested in the domain name of the email only address, I could write a regular expression something like
@(\w)*\. (com: net | org)
to parse the string 'gmail '.
Forgive me if I am away from base, but I'm flying blind at the moment (not LV to test what I say). You can add to the power of a regular expression using submatches or capture groups. The regular expression you wrote will grab (I think) @gmail.com for the entire game. Let's say you want to get 'gmail' without a second function call. You can do the first group of a little dishonest selection by moving the * inside the parentheses. Then, on the BD pull down on the bottom of the function of regular expression matching to expose a variable number of submatches (both should be in this case). The first should be 'gmail '. The second one should be "com."
In summary, @(\w*)\.) (com: net | org) should give you gmail in the first submatch. Of course, my Perl is a little rusty and LV cannot apply in the same way.
-
Is the function of the regular Expression
Hi guys, using this model, I got this error:
-4600 error has occurred during the regular expression match.
I have attached the VI.
can you help me? Thank you
inuyasha84 wrote:
Hi well I want to save (create) a file and do a check to see if the new file that I want to create already exists or not. If the idea was to see if the path of the new file is equal to the old path
Why not just use 'check if the file or folder exists? (E/s files-> Adv file functions)
Cameron
-
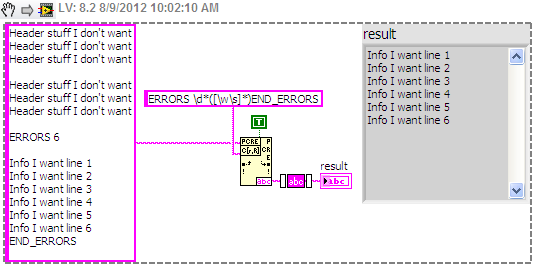
Regular expression help please. (extraction of a subset of the string between two markers)
I haven't used regular expressions before, and I can't find a regular expression to extract a subset of the string between two markers.
The chain;
Stuff of header I want
Stuff of header I want
Stuff of header I wantStuff of header I want
Stuff of header I want
Stuff of header I want6 ERRORS
Info I want to line 1
Info I want line 2
Info I want line 3
Info I want to line 4
Info I want to line 5
Info I want line 6
END_ERRORSFrom the string above (it is read from a text file), I try to extract the subset of string between ERRORS 6 and END_ERRORS. The number of errors (6 in this case) can be any number from 1 to 32, and the number of lines I want to extract will correspond with this number. I can provide this number of a caller VI if necessary.
My current solution, which works, but is not very elegant;
(1) using Match Regular Expression for the return of the string after you have synchronized the 6 ERRORS
(2) uses the Regular Expression matches to return all characters before game END_ERRORS of the string returned by (1)
Is there a way this can be accomplished using 1 Regular Expression Match? If so someone could suggest how, as well as an explanation of the work of the given regular expression.
Thank you very much
Alan
I used a character class to catch any word or whitespace characters. This put inside parentheses a substring matching the criteria that you can get by developing the node for regular expression matching. The \d matches the numbers and the two * s repetition of the previous term. So, \d* will find the '6', as well as "123456".
-
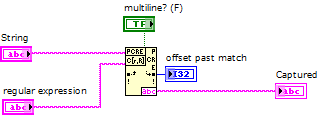
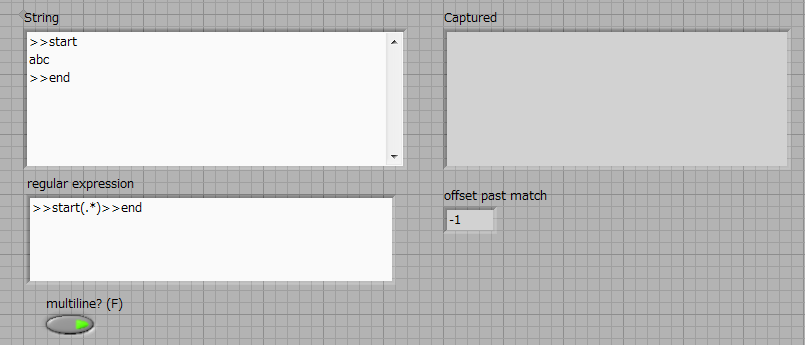
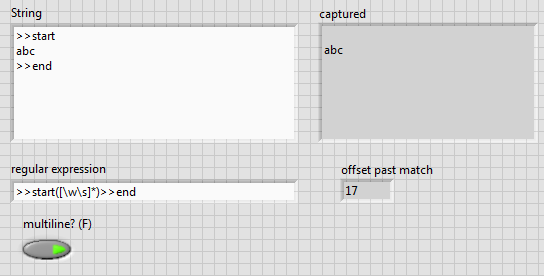
How to capture multiple line String using regular expressions?
Hello
I have a simple program like this:
What I want to accomplish is to capture everything between > start and > to end with a single regular expression matching node. It seems that the definition of multiples? true or False does not help.
I'm using LabVIEW 2012.
If it is impossible to capture using a single node, that's fine. But I want to assure you that I can make full use of this node without combining several others.
Thank you!
> start([\w\s]*) > end
A point matches any character except line break characters. You have two of them.
-
Regular expression - get longer channel number
I think it's easy, but I can't get it. Lets say I have a string "A1_1000", I would like to remove the 1000 using regular expressions. When I fed regular expression Match I get '1', which is not the longest number. I know other ways to do it, but I want to clean the solution in one step. Anyone know the regular expression to the right to achieve this? Thank you!
ceties wrote:
It is the best solution I've been able to come. I wonder if there are "more smooth way" without the cycle of.Since several checks are needed, I would tend to beieve we must travel opportunities. in this example

I start to check at '0' offset in the string to a number. Provided that I have find a number, I check if it is longer that any previous number, I found and if so, store the new number more in the shift register.
Have fun!
Ben
-
Using Regular Expressions in the Code of edge
Hello.
I am quite new to the Edge Code but find it quite interesting to use.
The find/replace feature is pretty but I got a little confused on how to use regular expression matching.
I tried to clean up the coordinates of a file Adobe Edge animate full of 120.17px (heavy and less accurate)
So basically you're looking \d+\.\d+px
First of all, she says "use /re/ for regex" even though I know the Code is made for developers who * courses * know that it took me a little time to understand I should just put my regex between slashes.
/\d+\.\d+PX/
then the time comes to replace them. ALT-cmd-F and it says "replace".
Puzzled again.
Will I type my full sentence there? Maybe a «...» "written up somewhere around would avoid this question because, there, of course, a second field to come.
And there, I got stuck.
I can not find how to get the replacement of the model.
tried to \1 $1 \1/ $1 / nothing seems to work... any hint of welcome.
Franck,
You are right that it does not work. I open a topic. Here is the link if you want to follow: https://github.com/adobe/brackets/issues/1861
FYI, I know exactly how you want to replace the search results, but here are a few tips:
You must set the text that you want to retrieve by using parentheses. Thus, for example, if you want the integer part of the number of the result, then your regexp would be: / (\d+)\.\d+px/
Then you must specify the first result using $1, so (when it's fixed), you can use something like: $1px
Thank you
Randy

Maybe you are looking for
-
I have been using Mozilla Firefox and Thunderbird for several years with no problems. Since yesterday, trying to connect to my bank accounts online, I get a sign in the error message. I checked with my Bank and the error is not with their Web site or
-
Get rid of software spies and other trackers? __
I use McAfee software, but think I have spyware, malware, cookies and other tracking devices "considerably slow down my computer! When I log my Comcast Internet, it takes a long time and I see "waiting for bridgetrack, or Zedo, Malware.com... generic
-
Can't turn on WIRELESS on a Dell Latitude E5520
I am working on a Dell Latitude E5520. The laptop is running Windows 7 Professional. It has an installed Dell DW1530 Wi - FI card. The WI - FI card is disabled. Whenever I try to activate the card, it goes through all the activation of the card q
-
Impossible to update windows 8.1
My pc is not updated to 8.1... of the store. How can I upgrade my pc to 8.1? Former title: 8.1 UPDATE
-
3000 N200 DVD writer - can't find much info on the support site
Hello I looked on the support site for my laptop see more info on my DVD burner, specifically: (1) how to check if the writer firmware is up to date (2) what accelerates, he worked for various media (3) is double layer for example DVD + R DL writing