CONNECT OF PREREQUISITE for the flat table structure?
I am familiar with data such as the following and extract a hierarchy using CONNECT BY PRIOR:
For example:
with tbl_data AS
(
SELECT 'PZPZZZZ' code, 'LEVEL1' code_level, 'Kingdom' code_label, NULL parent_code FROM DUAL UNION ALL
SELECT 'PZ2ZZ2Z' code, 'LEVEL2' code_level, 'Phylum ' code_label, 'PZPZZZZ' parent_code FROM DUAL UNION ALL
SELECT 'PZ3ZPZZ' code, 'LEVEL3' code_level, 'Class ' code_label, 'PZ2ZZ2Z' parent_code FROM DUAL UNION ALL
SELECT 'PZ433PZ' code, 'LEVEL4' code_level, 'Order ' code_label, 'PZ3ZPZZ' parent_code FROM DUAL UNION ALL
SELECT 'PZ5535Z' code, 'LEVEL5' code_level, 'Family ' code_label, 'PZ433PZ' parent_code FROM DUAL UNION ALL
SELECT 'AAZZZZ2' code, 'LEVEL6' code_level, 'Genus ' code_label, 'PZ5535Z' parent_code FROM DUAL
)
SELECT LPAD(' ', (LEVEL - 1) * 10, ' ') || code
, LEVEL
, parent_code
, code_label
FROM tbl_data
START WITH code = 'PZPZZZZ'
CONNECT BY PRIOR code = parent_code;
That generates data like this:
HIER LEVEL PARENT_CODE CODE_LABEL ----------------------------------------------------------- ------- ----------- --------------- PZPZZZZ 1 Kingdom PZ2ZZ2Z 2 PZPZZZZ Phylum PZ3ZPZZ 3 PZ2ZZ2Z Class PZ433PZ 4 PZ3ZPZZ Order PZ5535Z 5 PZ433PZ Family AAZZZZ2 6 PZ5535Z Genus
We have some data stored in a table with this structure, finance so that instead of data as in the example above, the hierarchy is stored in a single line - for example
with tbl_data AS ( SELECT 'PZPZZZZ' level1, 'Kingdom' level1_desc, 'PZ2ZZ2Z' level2, 'Phylum' level2_desc, 'PZ3ZPZZ' level3, 'Class' level3_desc, 'PZ433PZ' level4, 'Order' level4_desc, 'PZ5535Z' level5, 'Family' level5_desc, 'AAZZZZ2' level6, 'Genus' level6_desc FROM DUAL ) SELECT level1 , level1_desc , level2 , level2_desc , level3 , level3_desc , level4 , level4_desc , level5 , level5_desc , level6 , level6_desc from tbl_data;
Data:
LEVEL1 LEVEL1_DESC LEVEL2 LEVEL2_DESC LEVEL3 LEVEL3_DESC LEVEL4 LEVEL4_DESC LEVEL5 LEVEL5_DESC LEVEL6 LEVEL6_DESC ------- ----------- ------- ----------- ------- ----------- ------- ----------- ------- ----------- ------- ----------- PZPZZZZ Kingdom PZ2ZZ2Z Phylum PZ3ZPZZ Class PZ433PZ Order PZ5535Z Family AAZZZZ2 Genus
Given that the data is in this format, it is possible to generate a query of the hierarchy, assuming level5 is the parent of level6, level4 is the parent of level5 and so forth, to generate the same output as the example above?
Is not a work at home on the interview question - just something I try to appear at work, for my own interest.
Any advice would be much appreciated.
Thank you
with tbl_data AS
(
SELECT level1 "PZPZZZZ", "Realm" level1_desc, "PZ2ZZ2Z" level2 "Phylum" level2_desc, level3 'PZ3ZPZZ', 'Class' level3_desc, level4 'PZ433PZ', 'Order' level4_desc, level5 'PZ5535Z', 'Family' level5_desc, 'AAZZZZ2' level6, 'Like' level6_desc FROM DUAL
)
Select decode (x
, 1, level 1
, 2, lpad (' ', 10). Level2
, 3, lpad (' ', 20). Level3
, 4, lpad (' ', 30). Level4
, 5, lpad (' ', 40). Level5
, 6, lpad (' ', 50) | Level6
) yesterday
x
decode (x
, 2, level 1
, 3, level 2
, 4, level3
, 5, level4
, 6, level5
) parent_code
decode (x
, 1, level1_desc
, 2, level2_desc
, 3, level3_desc
, 4, level4_desc
, 5, level5_desc
, 6, level6_desc
) yesterday
of tbl_data
(select level x from dual connect by level<= 6="">
Tags: Database
Similar Questions
-
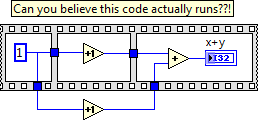
Scripts (connect a Terminal to a flat sequence Structure)
(script)
Is it possible to connect a terminal to a flat Structure of the sequence? (in my case, with a single frame)
(with the "Connect Wire" method)
Ouadji wrote:
but the main question is... Why the flat sequence structure does not inherit from node?
Why the developers chose this?
What is the main idea of this choice?Flat sequence Structure introduced in LabVIEW 7.0, provides a semantic schema object that no other object has. It is a structure of multi-frame (like a case structure or a stacked sequence), but it is the only structure where data can be wired between frames through normal tunnels. It is the only structure which may have tunnels in places other than its external borders. It is the only structure that can have subdiagrams of different sizes in different positions. It also introduces scenarios of strange wiring that you won't find elsewhere:
At the same time that the flat Structure of the sequence was introduced, there was enough of these bizarre scenarios with scripts (which was an internal feature NOR at the time), it was easier on the developer to make his own script class to try to find a way to support it under an existing class. We had no idea that script would become a public service someday, so the burden was relatively low and limited within the walls of NOR. Looking back, there have been enough problems with the FlatSequence class in the script than most of us agree that it would be better to have it in class Node (or more precisely, the class MultiFrameStructure) from the beginning.
-
comes to connect in iCloud for the first time and to synchronize my calendars etc I noticed it all disappeared. How can I restore them?
They run iCloud.com? You have them on a computer?
-
I have a PCI 6519 data acquisition card. I want to install it on the PC and use it outputs to control a robot. I have problems with the connections to the terminal block which is attached to the cable.
What type of connections I do for the acquisition of data PCI 619 card pins? What I have to give it to the ground and the CCV on the pins of the connector myself? What should be the value of the SCR I need to give to the PIN?
-
Prerequisites for the olive TREE
Hi friends,
What are the prerequisites for the installation of OBIA(latest version), informatica (latest version) with the 11.1.1.6 OBIEE.
I have the following conditions as
But I need to know the latest version of OBIA and informatica distributor of electric power that is affordable, with the (11.1.1.6) version last OBIEE.Software-------------------------------Version Oracle database ------------------11g Release 2 Hibernate libraries--------------------3.2.5.ga OBIEE----------------------------------11.1.1.6 Oracle BI Applications release-------7.9.5.1 Informatica power center-------------8.1.1
Friends, someone guide me with the prerequisite that I must follow.
Thanks in advance.
Kind regards
SaroOh, we had last version ;) then go for the version 9.1
Oracle Business Intelligence Data Warehouse Administration Console 10.1.3.4.1 for Microsoft Windows and Informatica PowerCenter and PowerConnect adapters 9.1 for Windows x 86 (64 bit) (part 1 of 2) V30859-01 Part 1 2 2.0 g
Download Oracle Business Intelligence Data Warehouse Administration Console 10.1.3.4.1 for Microsoft Windows and Informatica PowerCenter and PowerConnect adapters 9.1 for Windows x 86 (64 bit) (part 2 of 2) V30859-01 Part 2 of 2 1.4 GDownload Applications Oracle Business Intelligence licenses and Guide 7.9.6.3 packaging and Informatica PowerCenter PowerConnect adapters customer 9.1 (part 1 of 2) V33700-01 Part 1 of 2 of 1.7 G
Download Applications Oracle Business Intelligence licenses and Guide 7.9.6.3 packaging and Informatica PowerCenter PowerConnect adapters customer 9.1 (part 2 of 2) V33700-01 Part 2 of 2First server installation and then go for the customer.
Published by: vieren on October 8, 2012 11:57
-
KM for the flat file to flat file
Hello
Including KM to use for the flat file to flat file extraction.
Thank you.Hello
Use LKM FILE SQL and SQL IKM FILE APPENDIX
Make sure that the file exists and your waiting area is facing a pattern of RDBMS
Thank you
Fati -
Sinlge select query in the diff for the same table (same Structure) diagrams
Scenario:
Table XYZ is created in detail a.
After a year, the old data of the previous year could be moved to another schema. However in the other schema of the same table name would be used.
For example
A schema contains XYZ table with data from the year 2012
Schema B contains XYZ table with data for the year 2011
Table XYZ in the two schemas have an identical structure.
So we can draw a single select query to read the data from the tables in an effective way.
For example select * from XYZ so including date between October 15, 2011 to March 15, 2012.
However, the data resides in 2 different schema altogether.
Creating a view is an option.
But my problem, there are ORM (Hibernate or Eclipse Top Link) layer between the application and the database.
If the queries would be constituted by the ORM layer and are not generated by hand.
So I can't use the view.
So is there any option that would allow me to use only query on different scheme?970773 wrote:
Scenario:Table XYZ is created in detail a.
After a year, the old data of the previous year could be moved to another schema. However in the other schema of the same table name would be used.For example
A schema contains XYZ table with data from the year 2012
Schema B contains XYZ table with data for the year 2011
Table XYZ in the two schemas have an identical structure.So we can draw a single select query to read the data from the tables in an effective way.
For example select * from XYZ so including date between October 15, 2011 to March 15, 2012.
However, the data resides in 2 different schema altogether.Creating a view is an option.
But my problem, there are ORM (Hibernate or Eclipse Top Link) layer between the application and the database.
If the queries would be constituted by the ORM layer and are not generated by hand.
So I can't use the view.Why not make the ORM as below?
SELECT * FROM VIEW_BOTH;
-VIEW_BOTH is a real VIEW of Oracle -
Export a table for the flat file and must insert sysdate in flat file column
Hi, I created an interface allowing to export an oracle table to a csv file. All the columns in the table work well. Then I need to insert the sysdate in a column in the csv file.
I made the map as working in the transit area, implementation is to_char(sysdate,'dd/mm/yyyy'). But the result is insert in column 14.
I tried to create a variable refreshing that choose double to_char(sysdate,'dd/mm/yyyy'), maps then as the csv file column, but he only insert 1 row and the format is YYYYMMDD.
I tried to use SELECT '< % = odiRef.getSysDate ("YYYYMMDD") % >' double to the variable and it also only insert a line in the flat file.
I used the same methodology in ODI10g, it works fine.
So, I wonder how it can be implemented in 11g.
Thank you
It turns out that I used the snapshot_date as a field name, it may be a reserved word. After that I changed the name of the field, it works fine. Thank you.
-
Replace the flat sequence Structure?
I read a bit in the forum and a lot of people discouraged to use the structures of the sequence. Here's the situation: I have a tick count at the beginning for the iteration (and another at the end). I want to force them to count before (and after) anything else. The code I'm working on leash all data through structures flat sequences that contain only tick counts. Is there a different way that you can do without the structures of the sequence?
Thans
The recommendation not to use structures of sequence applies to most of the cases where people use. State machines are the preferred (and best) method. However, this does not mean that there is never a good use for a sequence structure. In your case, when you both want something, it is perfectly acceptable. An example is shown in the first snippet below.
There is an alternative however. You can use a timed loop to time your code. Someone posted here once an example. I forgot who he was and who puts in. It went something like the snippet of the second.
I would like to know why there is a difference in speed between these two methods:
-
Constants of output for the case of Structures
Hello
I have a pretty basic question about the case structures in labview. As indicated in the attachment below, using the structure case I've pretty much tried to create a three position switch. I'm trying out a value for the first (in the range and Coerce) and another value to the second. If [5-0] 0, [0 0] case for case 1 and case 2 [0, 5]. However when I try to connect all the way to the top, a broken line appears.
How can I do this without error?
Thank you
Justin
Something like this maybe? You need to change the task UP as well.
-
How to take partial dump using EXP/IMP in oracle only for the main tables
Hi all
select*from v$version; Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Prod PL/SQL Release 10.2.0.1.0 - Production "CORE 10.2.0.1.0 Production" TNS for 32-bit Windows: Version 10.2.0.1.0 - Production NLSRTL Version 10.2.0.1.0 - Production
I have about 500 huge data main tables in my database of pre production. I have an environment to test with the same structure of old masters. This test environment have already old copy of main tables production. I take the dump file from pre production environment with data from last week. old data from the main table are not necessary that these data are already available in my test environment. And also I don't need to take all the tables of pre production. only the main tables have to do with last week data.
How can I take partial data masters pre prodcution database tables? and how do I import only the new record in the test database.
I use orders EXP and IMP. But I don't see the option to take partial data. Please advice.
Hello
For the first part of it - the paintings of masters just want to - use datapump with a request to just extract the tables - see example below (you're on v10, so it is possible)
Oracle DBA Blog 2.0: expdp dynamic list of tables
However - you should be able to get a list of master tables in a single select statement - is it possible?
For the second part - are you able to qrite a query live each main table for you show the changed rows? If you can not write a query to do this, then you won't be able to use datapump to extract only changed lines.
Normally I would just extract all the paintings of masters completely and refresh all...
See you soon,.
Rich
-
Size for the imported table descrepancy
Version: 11.2
OS: RHEL 5.6
I imported a large table with (450 columns). I'm a little confused about the size of this table
Although it is said 7,311 gb when importing, which is not reflected in DBA_SEGMENTSImport: Release 11.2.0.1.0 - Production on Wed Aug 1 14:08:42 2012 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. ;;; Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production With the Partitioning, OLAP, Data Mining and Real Application Testing options Master table "SYS"."SYS_IMPORT_FULL_01" successfully loaded/unloaded Starting "SYS"."SYS_IMPORT_FULL_01": userid="/******** AS SYSDBA" DIRECTORY=dpump2 DUMPFILE=sku_dtl_%U.dmp LOGFILE=impdp_TST.log REMAP_SCHEMA=WMTRX:testusr REMAP_TABLESPACE=WMTRX_TS:TESTUSR_DATA1 PARALLEL=4 Processing object type TABLE_EXPORT/TABLE/TABLE Processing object type TABLE_EXPORT/TABLE/TABLE_DATA . . imported "TESTUSR"."SKU_DTL" 7.311 GB 9502189 rows <------------------------------------------- Processing object type TABLE_EXPORT/TABLE/GRANT/OWNER_GRANT/OBJECT_GRANT Processing object type TABLE_EXPORT/TABLE/INDEX/INDEX Processing object type TABLE_EXPORT/TABLE/CONSTRAINT/CONSTRAINT . .
Why is there a difference of 5 GB?SQL> select sum(bytes/1024/1024/1024) from dba_segments where owner = 'TESTUSR' AND SEGMENT_NAME = 'SKU_DTL' AND SEGMENT_TYPE = 'TABLE'; SUM(BYTES/1024/1024/1024) ------------------------- 2.28027344 -- Verifying the row count shown in the import log SQL> SELECT COUNT(*) FROM TESTUSR.SKU_DTL; COUNT(*) ---------- 9502189
-Info on indexes created for this table (if this info is of no use)
The total combined size of index into this array is 12 GB (hope the query below is correct)
SQL> select sum (bytes/1024/1024) from dba_segments where segment_name in ( select index_name from dba_indexes where owner = 'TESTUSR' and table_name = 'SKU_DTL' ) and segment_type = 'INDEX' 2 3 4 5 6 ; SUM(BYTES/1024/1024) -------------------- 12670.75The size is reported in the dump file is the amount of space the data took in the dumpfile. This does not necessarily mean that it is how much space it will discuss when they are imported.
One reason for this is that if the tablespace in that it is written is compressed or not. If the target tablespace is compressed, then once the import is complete, it will be much smaller than what has been written for the dumpfile.
I hope this helps.
Dean
-
OfficeJet 8500 Prime will not connect to wireless for the scanning of email
HP Officejet 8500 first.
Western Digital N900 router
Printer is connected to my home wireless network and wireless to my HP Pavilion laptop (which is in the same room).
I felt for a few years and I do a LOT of scans to myself on my e-mail and rarely have problems.
About a month ago, I got a new wireless router, and the problems started.
I had the wireless configuration. Printer connect to my home wireless.
If I try to scan to e-mail, I get a message "unable to connect to the server. Check the address and the name of the server.
I can print from my laptop very well (wireless)
I have run the wireless network test report (which incidentially, does NOT use the default tray as specified in default values, so I have to remove the media in a status bar and replace them with paper to make turn this test).
All passes.
very good signal strength.
no other network with the same ssid
Wireless networkes detected: 3
Channel 11
everything looks great.
I connect to my router (from my wireless laptop).
My router says that the printer is on the network.
I turned off/power on router to reset.
I tried the reset network default printer and returning via the wireless Assistant.
I tried another wireless (5g below)
I got the preferred wireless network name and password several times.
I turned the printer deactivation / activation.
The SSID signal is using 2.4 Ghz (802.11 B + g + n) 20 / 40 mhz channel (auto) AND I ALSO tried with channel (11) just
The router includes a 5 GHz (802.11 a + n), but the printer never sees this SSID, and tried manually enter the name and password as well.
I get the same error every time.
Sounds like you arehaving problems with scanning to email. Can you tell me first if you have tried all the other email accounts other than the one you are using. According to the security on the SMTP servers for the customer, you will have to go and try another account. I suggest to make a Gmail account and attempt to put in place the new feature.
I would like to know how this happens, and I'll get back right with you!
-Spencer
PS I hope you had a great weekend and had a wonderful day!
-
Prerequisites for the IBM I access for Windows with Windows 8.1
I have several new computers with Windows 8.1 who need access to an AS400 via I Access for Windows. I know that before this, I have to install 2 conditions (vcredist_x86.exe and vcredist_x64.exe) before the installation of Access for Windows. I didn't know of these 2 conditions on Windows 8.0 installation problems, but I'm having a problem installing on Windows 8.1. Are there new prerequisites for Windows 8.1 patches!
I I've installed Access for Windows on another machine of 8.0 and then upgraded the operating system to 8.1 without problem.
Your help would be greatly appreciated.
Thank you.
Alex
Hi LXMC,
I'm not familiar with Iaccess, but you have installed the latest service packs to the site:
http://www-03.IBM.com/systems/power/software/i/access/windows_sp.html
-
Check prerequisites for the Installation of Oracle 11 g grid
Hello friends,
Could you please suggest if I have to install the following prerequisites? It will cause no problems in the future using the Oracle grid software.
In the affirmative, please suggest how should I install the following prerequisite packages.
Please find the below screenshot:

Please help me out here, I would really appreciate it.
Thank you
RT
For starters, cropping the image would be beneficial. Just see the one screen, not the entire desktop.
Yes... you need these packages. They are prerequisites for a reason. If you choose to ignore them, then you have a bad installation.
See you soon,.
Brian


Maybe you are looking for
-
We used to use Firefox... but for some reason, it stopped opening. We have uninstalled and we found that the old version of Firefox would open but it would be immediately updated to the new version and then the problems start again and it would not s
-
Print Preview error: the selected printer could not be found.
I get this error when trying to get a glimpse of an email in Thunderbird vs 24.
-
Attach an Office or Acrobat reader file to Lotus Notes 8.5
Hello world We have a problem in our society with attach them files, we use Lotus Notes 8.5 as a mail client and also Office 2007 and Acrobat reader 10 The problem is, when you use any Office document for example, (it can be the word, excel...) and y
-
connection issues - unable to connect to the Internet after the elimination of viruses
computer has had the virus in the start menu... ran the antivirus... took care of them... now can't connect to the internet. another pc which is networked with this one game a router is fine... any ideas... thnks
-
My cat sat & keyboard & a line of stars appeared in the address space. When I arrived to remove him, she hit another & all of a sudden the screen images were all upside down (which makes my reading a bit problematic email) :-)