Copyright / reserved / brands of unicode characters
Hello I am trying to find out the escape sequences unicode for the reserved [circle with R inside] symbol and the symbol of the brand [TM].
I know there is one for «\u00a9» copyright
If someone can point me in the right direction on how I can get the symbols for the reserved sign and the TM sign, that would be greatly appreciated.
I searched the forums but found nothing.
Thank you.
Ahmed
Thanks for the tip of MS Word, really helped, just went to insert symbol in MS Word, and it was unicode escape sequences
Copyright symbol - \u00a9
reserved - symbol \u00ae
symbol of the brand - \u2122
Thank you
Ahmed
Tags: BlackBerry Developers
Similar Questions
-
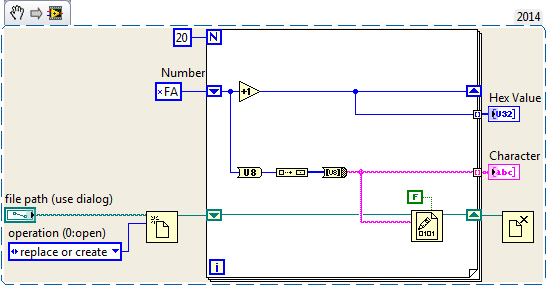
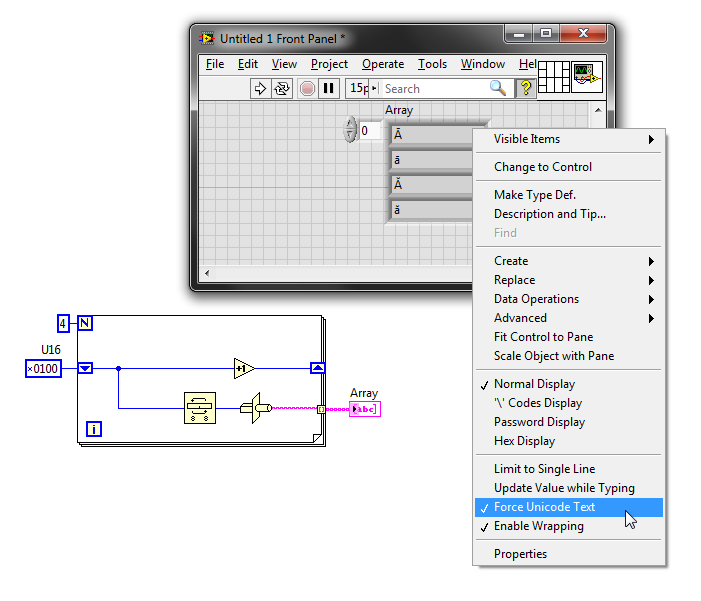
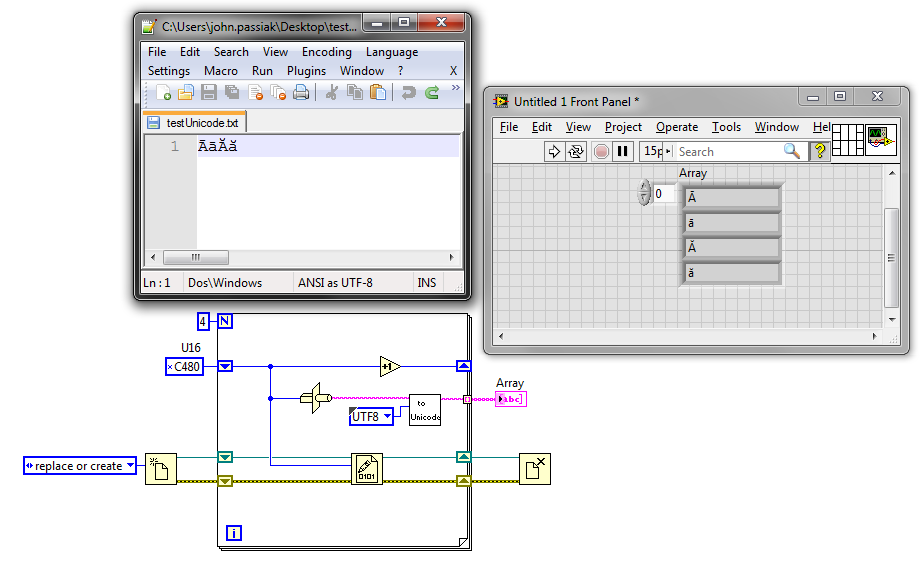
Generate and write unicode characters to file
The characters of genearted seems OK (up to x00FF), but after writing to file these characters and their values are different. Also the characters after 0x00FF are not good.
Any idea?
You should probably give this page than to read a thorough if you relied on the use of Unicode in your application. Here is a relevant excerpt:
ASCII technically only sets a value of 7 bit and can therefore represent 128 different characters, including characters such as the newline (0x0A) and return (0x0D) transport. However ASCII characters in most applications including LabVIEW are stored as 8-bit values which can represent 256 different characters. The 128 additional characters in the ASCII range are defined by the code page of the operating system aka "language for programs non - Unicode. For example, on a Western system, Windows uses by default the character set defined by the Windows code page 1252 Windows-1252 is an extension of another commonly known used encoding ISO-8859-1.
Offers Windows-1252 characters up to 0xFF (ÿ) but not something higher to 8-bit (for example no 0x0100). By default, LabVIEW support these uses of 8-bit, multibyte strings characters - only interpretation is based on the current code page selected in the operating system. You can turn on Unicode, the instructions in my first link (this is not supported and can be a little buggy from time to time...) to get the support of multibyte unicode characters to multibyte codepage characters not in the operating system.
Unicode has several encodings, and the bit raw to a character depending on the encoding used. LabVIEW limited unicode support seems to use UTF-16 (little endian) encoding for whatever it will be displayed in the user interface. So to get the characters displayed on the interface user, you must enable unicode (instructions illustrated in my first link) and write the appropriate UTF-16 code:
UTF - 8 is more common and therefore easier to work with outside LabVIEW (e.g. my version of Notepad ++ obviously do not support UTF-16). I usually find myself using UTF-8 for files format strings and convert them to UTF-16 for display in LabVIEW.
Unicode in my first link library has the necessary subVIs to convert between UTF-8 and 'Unicode' (i.e. UTF-16).
Best regards
-
Windows Help explains how to use the character map to copy or drag special characters in Unicode-aware applications. In Vista, it was possible (but heavy) to insert special characters using the keyboard with the method known as Alt-plus, which has only first need to add EnableHexNumpad to the registry *.
y at - it an easier way to insert Unicode characters using only the keyboard newly available in Windows 7? Adds EnableHexNumpad to the still of registry required to use the Alt-Plus mode? Other tips to quickly characters insert Unicode in taking applications support Unicode?
* Register instructions: Add a new string [REG_SZ] named EnableHexNumpad and a value of 1 in HKEY_Current_User/Control Panel/Input Method
Have you tried UnicodeInput? It is a small program that allows you to enter Windows Unicode characters via the keyboard. Works with practically all the applications that I tested. I use it on Vista, so I can't guarantee it will work also on 7...
You can find it at http://www.fileformat.info/tool/unicodeinput/unicodeinput.zip .
Kind regards
-
After effects error: could not convert Unicode characters. (23::46) CS6
Hello I just created a project in AE CC and wanted to also save a version for CS6.
Everything went well but when I tried to open the project in CS6 I received the following error message:
«After effects error: could not convert Unicode characters.» (23::46) »
Does anyone know what this means and how to fix it?
After effects CC is much, much better handling of the characters that are outside the defined character used by the operating system to its current settings of the language. Thus, the file names and paths (and other channels) which operate very well in after effects CC and later may fail with older versions.
For example, if you run your operating system and applications in English and Chinese characters in your file names, After Effects CS6 and earlier will fail, but after effects CC and earlier will succeed.
-
After effects error: could not convert Unicode characters. (23:46)
Hey guys,.
I'm trying to change the output path for a render queue item.
But I still have this error "after effects error: could not convert Unicode characters.» (23:46) ".
Here is my code
A_char outPath [256] = "D:/test.mp4;
ERR (suites. OutputModuleSuite4()-> AEGP_SetOutputFilePath (0, 0, outPath));
What I am doing wrong? Help me please! Thank you very much!!!
You must use A_UTF16Char instead of A_char.
-
Escaping of unicode characters
I'm trying to percent encode unicode characters (when they come to the top). I just stumbled up to: e
SELECT UTL_URL. Escape ('e') FROM Dual;
Returns: % BF
What I need is: % C3% A9
Is it possible to get in Oracle?
----------------
Moreover, if the 'e' could be turned into a 'e', it would probably be fine.
Published by: Brian Tkatch on July 23, 2012 13:29But if I have to define CHCP, what would be the impact on other things, or how I would use inside a DBMS_SCHEDULER to run the PACKAGE.
You define anything for programs running inside the database server side.
I think you put too much thought into that.
Again, it is a matter of customer. Your application is not based on SQL * Plus, is that?Apply the function on a column of data, not a literal string whose interpretation relies on the NLS page and the code used by the interface.
-
Photoshop cs5 sdk supports filenames with unicode characters?
Hello
For the export module, has the windows sdk supported for filenames containing unicode characters?
Struct ExportRecord in PIExport.h has a filename attribute declared as a char array.
So I doubt if file names containing characters unicode for the export module will be supported.
Thanks in advance,
Spengler.
I check the value of propUnicodeName in PIProperties.h and use the callback property to propertyProcs.
Another option would be to struct SPPlatformFileSpecificationW * fileSpecW; in ReadImageDocumentDesc
-
Tour of Unicode characters to garbage according to the length of the previous text
Hey,.
I wrote a script that creates a bunch of text frames, fill text and styles it.
The problem is, sometimes, unicode characters out as parasites: for example "3 m Blenderm™™" turns into "3ma" ¢ Blenderma "¢."
I was playing around with four text frames to see what causes it, and if I add a line of text in the second frame, all of the following unicode characters turn garbage only if this text line is longer than 6 characters.
If I add a character™ to the first line of the first block of text, then the problem resolves itself.
If someone has encountered something like that?
Let me know if you need more information (my entire script is big enough...)
You shouldn't be gueesing encoding.
You must write the unicode marker or set the encoding of your file:
myFile.encoding = "UTF-8";
Substances
-
screen displays only the hex (unicode) characters
screen only displays text in blocks of 4 characters that looks like unicode. Other applications, including IE work fine.
Safe mode disables extensions in Firefox 4, and disables hardware acceleration.
Try turning off hardware acceleration.
- Tools > Options > advanced > General > Browsing: "use hardware acceleration when available.
If that works, then try the toggle some of downtown of Boolean gfx on the topic: configuration page to enable or disable some features.
Filter: gfx -
Photoshop supports unicode characters? (Windows)
I'm trying to type Tamil text in Photoshop CS3. I typed the Tamil text using Google Transliteration (http://www.google.com/transliterate/indic/Tamil) and then pasted into Photoshop, but it does not work. As Google Transliteration uses Unicode, it must work in photoshop as well (if Photoshop supports Unicode).
Photoshop supports Unicode? If yes what Miss me?
If photoshop does not support Unicode, how can I type the Tamil text in photoshop?
I don't think that its PS so that the police that you are using. If the police does not have the Tamil characters in it, it can support its representation.
If you have a Tamil font, I can't enter the Unicode number directly (at the level of the cursor) will work.
In ASCII, you can enter the ASCII number by pressing and holding the key alt key while tapping the 3 digit (000-255 numbers) code on the numberic keyboard and if the police supports the entered number (not all fonts support the ASCII range) the character appears at the location of the cursor. If you have a Tamil font and a map to ASCII inside try to enter codes as described above.
How do you type in a Unicode without going through your keyboard mapped to the specific language and fonts to go with it, I don't know.
If you get the Tamil characters you want Google, then copy the screen to the Clipboard by pressing print open a new document and paste there the Clipboard, then cut and paste to get the message in the format you need.
Here are some links that may be useful:
http://en.Wikipedia.org/wiki/Unicode#Mapping_and_encodings
http://en.Wikipedia.org/wiki/Tamil_script
Sorry I couldn't be more helpful.
Mike
-
Clipboard - Insert Utf8/Unicode characters to the Clipboard
I wonder how to add support for unicode to the Clipboard method? Because when am copy my app textarea text, he turns to? (Arabic letters).
Here are my codes which are related only to the Clipboard (added to these files):
. Pro
LIBS += -lbbsystem
all
Q_INVOKABLE void CopyText(QByteArray text);.cpp
#include
#include using namespace bb::system; qml->setContextProperty("_app", this); void ApplicationUI::CopyText(QByteArray text) { bb::system::Clipboard clipboard; clipboard.clear(); clipboard.insert("text/plain", text); bb::system::SystemToast *toast = new SystemToast(this); toast->setBody("Copied!"); toast->show(); } The function is called. QML
import bb.system 1.0 ActionItem { title: qsTr("Copy Text") onTriggered: { _app.CopyText(txtf1.text) } imageSource: "asset:///images/ic_copy.png" }I read a lot of forum messages and all API Tunis and I lost! as the use of tr() or QString::toUtf8 etc... !
How can I solve this?
Hello
Please try changing the QString type parameter:
void ApplicationUI::CopyText(const QString &text)
In the function convert the text to UTF-8 byte array:
void Application::CopyText(const QString &text) { bb::system::Clipboard clipboard; clipboard.clear(); clipboard.insert("text/plain", text.toUtf8()); bb::system::SystemToast *toast = new SystemToast(this); toast->setBody("Copied!"); toast->show(); }I think it was not working before because the function was already taking a QByteArray and implicit conversion (default) converted the ASCII instead of UTF8 encoding string.
BTW, in function of the names Qt applications usually start lowercase letters, but this should not affect anything.
-
AESEncryptorEngine and Unicode characters
Hello
I use the AESEncryptorEngine and the AESDecryptorEngine to encrypt and decrypt the normal text strings that were entered by the user into an ActiveAutoTextEditField. The problem is: users who come in non English characters such as Japanese or Chinese may encrypt their messages, but after decryption the characters appear as garbage or they are sometimes a few points mark as '? It seems that line breaks back correctly.
My encryption and decryption methods work well for America Latin characters but not if it is complicated. Maybe someone knows what I'm missing here?

It's the method of encryption:
public static String encrypt(String keyString, String plainText) { String encryptedText = null; byte[] keyData = keyString.getBytes(); try { AESKey key = new AESKey( keyData ); // Now, we want to encrypt the data. // First, create the encryptor engine that we use for the actual // encrypting of the data. AESEncryptorEngine engine = new AESEncryptorEngine( key ); PKCS5FormatterEngine formatterEngine = new PKCS5FormatterEngine(engine); // Use the byte array output stream to catch the encrypted information. ByteArrayOutputStream outputStream = new ByteArrayOutputStream(); BlockEncryptor encryptor = new BlockEncryptor(formatterEngine, outputStream); // Encrypt the actual data. encryptor.write(plainText.getBytes()); // Close the stream. encryptor.close(); byte[] encryptedData = outputStream.toByteArray(); encryptedText = new String(encryptedData); } catch (Exception e) { System.err.println(e.toString()); } return encryptedText; }It's the decryption method:
public static String decrypt(String keyString, String encryptedText) { String plainText = null; byte[] keyData = keyString.getBytes(); try { //remove prefix which indicates this is encrypted text encryptedText = encryptedText.substring(ENCRYPTION_PREFIX.length()); AESKey key = new AESKey( keyData ); // Now, create the decryptor engine. AESDecryptorEngine engine = new AESDecryptorEngine( key ); // Create the unformatter engine that will remove any of the padding bytes. PKCS5UnformatterEngine unformatterEngine = new PKCS5UnformatterEngine(engine); // Set up an input stream to hand the encrypted data into the block decryptor. ByteArrayInputStream inputStream = new ByteArrayInputStream(encryptedText.getBytes()); // Create the block decryptor passing in the unformatter engine and the encrypted data. BlockDecryptor decryptor = new BlockDecryptor(unformatterEngine, inputStream); byte[] temp = new byte[ 100 ]; DataBuffer buffer = new DataBuffer(); for( ;; ) { int bytesRead = decryptor.read( temp ); buffer.write( temp, 0, bytesRead ); if( bytesRead < 100 ) { // We ran out of data. break; } } inputStream.close(); plainText = new String(buffer.getArray()); } catch (Exception e) { System.err.println(e.toString()); } return plainText; }PS: I know that for loop in the decryption method is not really nice, but it was the only one that worked for me.
When you do your conversion rate of string/byte, specify an encoding...
plainText.getBytes("UTF-16");
raw text = new String (buffer.getArray (), "UTF-16");
-
Unicode characters not properly transferred to mysql to oracle
Hello
We are data of Oracle11g and MySQL5.5 using DG4ODBC. Data are getting transferred successfully in MySQL, but the characters like Russian, Chinese etc. are not transferred successfully. They are displayed in form? in MySQL database and even with the GUI tools like sqldevelopper or a squirrel.
NLS_Character uses Oracle is AL32UTF8 and MySQL database is UTF8.
Oracle version is 11.1.0.6.0
MySQL is 5.5.
unixODBC 2.2.11, comes from redhat for RHEL 5
I've tried to set HS_LANGUAGE = american_america.al32utf8, but not luck.
Can someone please give tip to configure settings of initialization of bridge or some other configuration that is required to support all the characters of the language during the transfer.
Sudhakar-In the init of the gateway file, please specify:
HS_NLS_NCHAR = UCS2
HS_LANGUAGE = AMERICAN_AMERICA. AL32UTF8-online you still have some we8sio8859p1 in this file from previous tests using unixODBC-2.2.1-online 2.3 should now work properly. -
Scripting - adding a line to the exponent of the copyright and brand symbols
I get a lot of text files from the writers and editors with™ and®'s. In InDesign, I add a line or two for the FindChangeByList script to automatically exposing these symbols. Can someone give me the GREP for this? If he could also find some MSDS superscript (where the author does not know how to create the™ symbol, but knows how to the Exhibitor, so they pretend) and replace them with™ s be fantastic.
Thank you.
Hi ejcarter9,
You don't need a GREP search for them - a text search will work just fine. Add the following lines at the end of the definitions of the FindChangeByList.txt file (I assume you are using the version of JavaScript... right? If not, I will need to change the lines a bit):
text {findWhat: "^ d"} {position: Position.superscript}, {includeMasterPages:true, includeHiddenLayers:true, includeFootnotes:true, wholeWord:false} find symbols (TM) brand and make them exposing.
text {findWhat: "^ r"} {position: Position.superscript}, {includeMasterPages:true, includeHiddenLayers:true, includeFootnotes:true, wholeWord:false} find trademark (R) symbol and make them exposing.
text {findWhat: 'TM', position: Position.superscript} {changeTo: ' ^ d ', position: Position.superscript '} {includeMasterPages:true, includeHiddenLayers:true, includeFootnotes:true, wholeWord:false} find the Exhibitor brand symbols typed as a "TM" and transform the symbols of the mark by exposing.You may need to add tabs between fields after you have copied these lines on this message - I'm not sure that the forum will maintain their when copy/paste.
Always nice to hear from anyone using FindChangeByList! This is one of my favorites.
Thank you
OLE
-
XMLParser & amp; Unicode characters
Hello
I'm struggling with this problem: parsing a string any xml that contains characters in a language other than English (in Hebrew, for example. See the below xml code example).
I tried to put the string in the message box, and the utf encoding causes the Hebrew characters to look really bad (something like "^ a ~ aa |").
When I try to write the Hebrew string on the screen it says question marks (""? "") instead of the text.
I found a way to get the Hebrew text in Director, which is to recover a string at once, without analysis of this through xml, but then it is not a good solution, because I have many <>elements in the xml file.
Anyone know how to analyze this type of xml file correctly? I'm doing something wrong here?
the XML is shown with utf-8 and is saved with encoding UTF-8 (using Visual Studio 2003), with or without signature.
Desperatly yours,
Tal
Solution (finally!):
If you want to include texts in non-Western language, don't depart too with the utf-8 encoding as I did. Just set ISO-8859-1 in the first line of the xml document (")") and save the document in the default (ANSI) encoding." Curiously, it does the trick for other languages too. Strange5050 is right after all (see livedocs).

Maybe you are looking for
-
If I get a separate apple account that my parents will be it spoil the phone bills
I want to know if I have an account, will we separate invoices?
-
A few hours ago, I decided to use my Bose sound canceling headphones with my iMac, shortly after there was a strange rumbling noise when I turned on the cancellation sound, if I turn it off it's gone. If I touch the metal at the back of the bottom of
-
I BOUGHT A LAPTOP HP WITH WINDOWS PREINSTALLED TO 8.1 15-R036TU I'M PLANNING TO DOWNGRADE TO WINDOWS 7 X 64, DOWNLOADED THE DRIVER FOR WINDOWS 7 X 64 ON THE OFFICIAL WEB SITE AFTER INSTALLATION WINDOWS 7 X 64, I FOUND THAT THE DRIVERS THAT I DOWNLOAD
-
Cannot download anything. Why?
Hello everyone. Now, after a year, I try to test / order products but all I get is a thing of four squares loading and I can't move forward. When I say nothing, I mean nothing, not even cloud creative app (also on PC). Do you have any idea why?
-
What is error?