Error memory for large records output:
Hello
My workflow process takes as input a list. He travels the workflow for all items in the list. If my list contains 4 items, there will be 3 * 7 = 21 stages when I invoke the process. I can check my recordings for debugging.
If I give 5 entries, it takes about 5 * 7 = 35 steps of the Workflow. If I try to play the record, I see the error: java heap space: out of memory exception. I've changed my space to Xmx1024m in workbench.ini. I also did: java - Xms < initial segment size > - < maximum segment size > Xmx (Q1: do we need to restart the JBoss after we do the second step?).
Q2: My system is Windows7 with 4 GB of RAM. I have liveCycle 8.2 with SP2. JBoss and MySql. I set this size of RAM to java in one of our JBoss server files?
Q3: Is there any file to set the maximum eligible steps for a process record? In the affirmative, please let me know. It would be a great help.
Thank you
Chaitanya
If you are certain that your service is enabled and works I don't know why the configuration settings would be disabled. The settings described in the sent link previously have been referenced in the documentation of the ES2, I have not determined if these 2 settings really existed in version (8.2 SP2) you have. Aside from that they wouldn't be useful if the OOM error took place on the server and not Workbench. As you receive the error in the Workbench there's a switch workbench.ini that you can add to limit the number of steps that will be loaded with a record:
-Dcom.adobe.workbench.unsupported.audit.maxNumberOfStepsToLoad = 250
The default value is 250, but you can try to reduce this value.
In addition, if the error is due to the size of your documents I don't know fo a solution for this but you can try making sure the variables view is closed when you load the recording.
Tags: Adobe LiveCycle
Similar Questions
-
Hyperion Planning setting memory for web forms large
I've seen some previous post Hyperion Planning that may have errors of memory for large web forms. Any recommendation of the size limit of web form?
If we use 64-bit Windows, Hyperion Planning supports larger sized web form although it seems that Hyperion Planning application itself is still 32-bit software.
Thanks a lot for your help!Hello
It is definitely a cache where many objects in the planning are cached in their current state and which is held in the JVM, this has probably been implemented to speed up the response time. I'm not sure on this 2 GB limit you keep tapes even if, as it has always been my belief that it is down to the size of the JAVA virtual machine.
See you soon
John
http://John-Goodwin.blogspot.com/ -
It said "restore enough memory for programs to operate correctly, save the file and then close or restart all open programs".
I changed the size of paging and says always the same, I have 1.5 GB free RAM, but don't know how to find or what to do 'virtual memory '. Have windows 7.
I started the safemode and run also memory dignostics and nothing found, please help, cannot afford to take a shop or get a new computer, I'm using another pc.
I was recommended to download and. Run 'hitmanpro3'... but if anyone has had this problem and solved it or know how, please help!
Thank you
Hello
Please contact Microsoft Community.
I understand that you receive an error related to the lack of virtual memory. This error message appears when running any program that requires more memory your computer has, or running in the background, Windows manages the system memory by saving the data between physical memory and virtual memory. In order to help you better, please provide us with the following information:
What is the brand and model of your computer?
I suggest you follow the methods and check them off below if this solves the problem.
Method 1: Clean boot
A clean boot is a troubleshooting technique that allows you to get the computer facing up and running so that you can determine what elements of the normal starting procedure problems.
How to perform a clean boot in Windows
http://support.Microsoft.com/kb/929135
Note: Once you are done with the clean boot, follow the section How do I reset the computer to start as usual after a clean boot troubleshooting under more information in the article to put your computer to normal startup.
Method 2: Prevention of insufficient memory problems
Follow the steps mentioned in the link and the check, it solves the problem. Follow the evolution of the size of the virtual memory section
http://Windows.Microsoft.com/en-us/Windows/preventing-low-memory-problems#1TC=Windows-7
Method 3: Virus Scan
Microsoft Safety Scanner is a free burner that can be used to analyze a system for computer viruses and other forms of malware.
Microsoft safety scanner
http://www.Microsoft.com/security/scanner/en-us/default.aspx
Warning: The data files that are infected must be cleaned only by removing the file completely, which means that there is a risk of data loss.
Additional information: Windows optimize for better performance
Hope this information helps. Response with status so that we can help you.
-
Dear team,
We have for instance R12.
DB - 11.2.0.3
12.1.2 - application
in this concurrent instance depressed frequently when checking of log file showing the error as
List of errors encountered:
.............................................................................
_ 1 _
Systematic FDPCRQ met an ORACLE error. ORA-04031: unable to
allocate 32 bytes of shared memory ('shared pool'.
Check your error messages for the cause of the error. (= < POINTER >)
.............................................................................
APP-FND-01388: cannot read the value for the profile FND_MGR_STRTUP_THRES_TIME option in the routine, and routine.
List of errors encountered:
.............................................................................
_ 1 _
Routine AFPCAL has received the code of failure while running or analysis of your
simultaneous program CPMGR
Examine your log file of concurrent application for more information.
Make sure that you pass arguments in the correct format.
Post: WARNING: mail_queue_enter: create file maildrop / 379309.437: permission denied
Please guide me to solve this problem.
Concerning
Kumar V
Dear Kumar,
I suggest you to check the FND_NODES table
1) connect to SQLPLUS as the APPS user and execute the following statement:
Select CONCURRENT_QUEUE_NAME in the FND_CONCURRENT_QUEUES where CONCURRENT_QUEUE_NAME like '% FNDSM ';
(2) If you have found that FND_NODES table with entries incorrect node (old node from the Source Instance), and then run the query to clean below
EXEC FND_CONC_CLONE. SETUP_CLEAN;
COMMIT;(3) then run AutoConfig on all stages, firstly on the DB layer then APPS and webtiers levels to repopulate the necessary system tables,
and make sure that you are now able to see the correct entries in the FND_NODES table and start the application services.
Kind regards
S27
-
How to check the ESX memory for errors?
Hi all
I faced with the strange behavior of ESX:
Some linux VMs (RHEL) were stopped. No error messages in the vCenter nor LabManager, I even thought that someone just connected and Runic stop.
Below you will find information of ESX server logs:
(1) the vmkernel newspaper:
#grep - color = always-i ' 1922 [^ 0-9] "... /VMkernel *"
.. (/ VMkernel.8:Dec 8 22:22:40 WKK1EC02 vmkernel: 290:11:51:47.230 cpu14:23084) UserDump: 1441: Dumping cartel 23079 (of the world 23084) to file the vmfs/volumes/4a4ce277-4a35505c-8828-0024817b058c/labmanager/1922/vmware-vmx-zdump.000...
(2) the journal of the VM:
# grep ' 08 Dec' /vmfs/volumes/4a4ce277-4a35505c-8828-0024817b058c/labmanager/1922/vmware-1.log '.
16:53:49.164 Dec 08: vmx | GuestRpcSendTimedOut: message to the Toolbox has expired.
16:54:14.972 Dec 08: vmx | GuestRpcSendTimedOut: message to the Toolbox has expired.
21:59:05.262 Dec 08: mks | Cannot write the temporary image THUMB
21:59:15.264 Dec 08: mks | Cannot write the temporary image THUMB
21:59:30.270 Dec 08: mks | Cannot write the temporary image THUMB
21:59:35.271 Dec 08: mks | Cannot write the temporary image THUMB
21:59:45.275 Dec 08: mks | Cannot write the temporary image THUMB
21:59:50.285 Dec 08: mks | Cannot write the temporary image THUMB
22:00:00.274 Dec 08: mks | Cannot write the temporary image THUMB
22:00:05.276 Dec 08: mks | Cannot write the temporary image THUMB
22:01:15.410 Dec 08: mks | Cannot write the temporary image THUMB
22:03:25.312 Dec 08: mks | Cannot write the temporary image THUMB
22:05:00.324 Dec 08: mks | Cannot write the temporary image THUMB
22:05:05.340 Dec 08: mks | Cannot write the temporary image THUMB
22:05:15.331 Dec 08: mks | Cannot write the temporary image THUMB
22:05:20.341 Dec 08: mks | Cannot write the temporary image THUMB
22:05:30.344 Dec 08: mks | Cannot write the temporary image THUMB
22:05:35.353 Dec 08: mks | Cannot write the temporary image THUMB
22:05:40.354 Dec 08: mks | Cannot write the temporary image THUMB
22:05:45.366 Dec 08: mks | Cannot write the temporary image THUMB
22:05:50.357 Dec 08: mks | Cannot write the temporary image THUMB
22:05:55.361 Dec 08: mks | Cannot write the temporary image THUMB
22:06:00.365 Dec 08: mks | Cannot write the temporary image THUMB
22:06:05.371 Dec 08: mks | Cannot write the temporary image THUMB
22:06:10.395 Dec 08: mks | Cannot write the temporary image THUMB
22:06:15.379 Dec 08: mks | Cannot write the temporary image THUMB
22:06:20.381 Dec 08: mks | Cannot write the temporary image THUMB
22:06:30.397 Dec 08: mks | Cannot write the temporary image THUMB
22:06:40.403 Dec 08: mks | Cannot write the temporary image THUMB
22:20:45.541 Dec 08: mks | Cannot write the temporary image THUMB
22:21:10.580 Dec 08: mks | Cannot write the temporary image THUMB
22:21:15.538 Dec 08: mks | Cannot write the temporary image THUMB
22:21:20.554 Dec 08: mks | Cannot write the temporary image THUMB
22:21:25.545 Dec 08: mks | Cannot write the temporary image THUMB
22:21:30.580 Dec 08: mks | Cannot write the temporary image THUMB
22:21:35.591 Dec 08: mks | Cannot write the temporary image THUMB
22:21:40.537 Dec 08: mks | Cannot write the temporary image THUMB
22:21:45.629 Dec 08: mks | Cannot write the temporary image THUMB
22:21:50.583 Dec 08: mks | Cannot write the temporary image THUMB
22:21:55.616 Dec 08: mks | Cannot write the temporary image THUMB
22:22:00.590 Dec 08: mks | Cannot write the temporary image THUMB
22:22:05.638 Dec 08: mks | Cannot write the temporary image THUMB
22:22:10.595 Dec 08: mks | Cannot write the temporary image THUMB
22:22:15.582 Dec 08: mks | Cannot write the temporary image THUMB
22:22:20.622 Dec 08: mks | Cannot write the temporary image THUMB
22:22:25.583 Dec 08: mks | Cannot write the temporary image THUMB
22:22:30.627 Dec 08: mks | Cannot write the temporary image THUMB
22:22:35.673 Dec 08: mks | Cannot write the temporary image THUMB
22:22:40.588 Dec 08: mks | Panic: file lock (was the bug 49968)
22:22:40.589 Dec 08: mks | Bora/lib/image/imageUtilPng.c:462 unrecoverable memory allocation failure
22:23:21.438 Dec 08: mks | Backtrace:
22:23:21.440 Dec 08: mks | Backtrace [0] 0x3ccf63d8 eip 0xa3f88cd
22:23:21.442 Dec 08: mks | Backtrace [1] 0x3ccf6818 eip 0x9ff705c
22:23:21.443 Dec 08: mks | Backtrace [2] eip 0xa2803bc 0x3ccf6b88
22:23:21.443 Dec 08: mks | Backtrace [3] eip 0xa2803f6 0x3ccf6bb8
22:23:21.444 Dec 08: mks | Backtrace [4] eip 0xa27fcc3 0x3ccf6bd8
22:23:21.444 Dec 08: mks | Backtrace [5] eip 0xa27fd28 0x3ccf6c28
22:23:21.445 Dec 08: mks | Backtrace [6] eip 0xa115582 0x3ccf7128
22:23:21.445 Dec 08: mks | Backtrace [7] eip 0xa115717 0x3ccf7138
22:23:21.445 Dec 08: mks | Backtrace [8] eip 0xa00d0a9 0x3ccf7168
22:23:21.446 Dec 08: mks | Backtrace [9] 0x3ccf9278 0xa00dbef eip
22:23:21.447 Dec 08: mks | Backtrace [10] eip 0x3ccf9298 0xa298217
22:23:21.447 Dec 08: mks | Backtrace [11] eip 0x3ccf92b8 0xa298255
22:23:21.448 Dec 08: mks | Backtrace [12] eip 0x3ccf92e8 0xa10bfe9
22:23:21.448 Dec 08: mks | Backtrace [13] eip 0xa0f2e81 0x3ccf93c8
22:23:21.504 Dec 08: mks | Backtrace [14] eip 0x160534fb 0x3ccf94b8
22:23:21.505 Dec 08: mks | Backtrace [15] eip 00000000 0x1613ae3e
22:23:21.507 Dec 08: mks | SymBacktrace [0] 0x3ccf63d8 eip in function 0xa3f88cd in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.508 Dec 08: mks | SymBacktrace [1] 0x3ccf6818 eip 0x9ff705c panic function in/usr/lib/vmware/bin/vmware-vmx of the object loaded on the 0x9f98000
22:23:21.508 Dec 08: mks | SymBacktrace [2] 0x3ccf6b88 eip in function 0xa2803bc in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.511 Dec 08: mks | SymBacktrace [3] 0x3ccf6bb8 eip in function 0xa2803f6 in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.511 Dec 08: mks | SymBacktrace [4] 0x3ccf6bd8 eip in function 0xa27fcc3 in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.512 Dec 08: mks | SymBacktrace [5] 0x3ccf6c28 eip in function 0xa27fd28 in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.513 Dec 08: mks | SymBacktrace [6] 0x3ccf7128 eip in function 0xa115582 in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.514 Dec 08: mks | SymBacktrace [7] 0x3ccf7138 eip in function 0xa115717 in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.515 Dec 08: mks | SymBacktrace [8] 0x3ccf7168 eip in function 0xa00d0a9 in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.515 Dec 08: mks | SymBacktrace [9] 0x3ccf9278 eip in function 0xa00dbef in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.516 Dec 08: mks | SymBacktrace [10] 0x3ccf9298 eip in function 0xa298217 in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.517 Dec 08: mks | SymBacktrace [11] 0x3ccf92b8 eip in function 0xa298255 in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.518 Dec 08: mks | SymBacktrace [12] 0x3ccf92e8 eip in function 0xa10bfe9 in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.519 Dec 08: mks | SymBacktrace [13] 0x3ccf93c8 eip in function 0xa0f2e81 in/usr/lib/vmware/bin/vmware-vmx of the object in the 0x9f98000 (zero)
22:23:21.519 Dec 08: mks | SymBacktrace [14] 0x3ccf94b8 eip 0x160534fb in function (zero) in the object /usr/lib/vmware/lib/libpthread.so.0 to the 0x1604e000
22:23:21.520 Dec 08: mks | SymBacktrace [15] eip 00000000 0x1613ae3e based on cloning in object /usr/lib/vmware/lib/libc.so.6 loaded in 0 x 16069000
22:23:21.520 Dec 08: mks | Msg_Post: error
22:23:21.521 Dec 08: mks | [msg.log.error.unrecoverable] fatal error VMware ESX: (mks)
22:23:21.521 Dec 08: mks | Bora/lib/image/imageUtilPng.c:462 unrecoverable memory allocation failure
22:23:21.521 Dec 08: mks | [msg.panic.haveLog] a log file is available in "/ vmfs/volumes/4a4ce277-4a35505c-8828-0024817b058c/labmanager/1922/vmware.log". [msg.panic.haveCore] a base file is available in "/ vmfs/volumes/4a4ce277-4a35505c-8828-0024817b058c/labmanager/1922/vmware-vmx-zdump.000". [msg.panic.requestSupport.withLogAndCore] please request support and include the contents of the log file and the base file. [msg.panic.requestSupport.vmSupport.vmx86]
22:23:21.523 Dec 08: mks | To collect the data to submit to the VMware support, run 'vm-support.
22:23:21.524 Dec 08: mks | [msg.panic.response] we will respond on the basis of your entitlement to support.
22:23:21.525 Dec 08: mks | ----------------------------------------
22:23:21.739 Dec 08: vmx | Watched VTHREAD thread 1 "mks" is dead
22:23:22.651 Dec 08: 1 vcpu. Watched VTHREAD thread 0 "vmx" is dead
22:23:22.740 Dec 08: vcpu-3 | Watched VTHREAD thread 0 "vmx" is dead
22:23:22.741 Dec 08: vcpu-2 | Watched VTHREAD thread 0 "vmx" is dead
22:23:22.743 Dec 08: vcpu-0 | Watched VTHREAD thread 0 "vmx" is deadI found the suggestion to check the ESX memory for problems.
I found the information that ESX 3.0 was ramcheck service which could check the memory, but there is no such service in future versions of ESX.
Could someone help me find how to check the memory without stopping the ESX Server (I could not migrate virtual machines per host)?
The only way you will get a true test of the memory of the HOST must stop it and run the test directly. Any tool running in the ESX console will only have indirect access RAM. The vmkernel controls access to physical RAM.
-
error "memory is full" with writing a file permanently PDM
Hello world
I know that the problem of "memory we complete" has been often discussed in this forum, and I have read these messages, but still could not solve the problem.
We have implemented a test function based on PXI5412 and 5122 modules. The program generates arbitrary waveforms to excite a DUT and acquires its response with digitizer and writing of the data acquired in a TDMS file (~ 40 MB for each measuring point). The program works fine in single point mode, i.e. in quiet passages. However, when I try to run it continuously in a loop TO measure several (up to 1,000) points, the program is always interrupted at halfway when ~ 10 GB of data is recorded with an error "memory is full".
My computer has 4 GB of RAM and the operating system is Windows XP Professional 32-bit. I checked the RAM usage when the error "memory is full" happened. in fact we at least 2.5 GB unused. I learned that maybe it's because he is not a continuous free space in RAM for data. It is also suggested to increase virtual memory to 3 GB for Labview by modifying the boot.ini file. But after I did the program meets still another error "Invalid TDMS" the file reference, and so I could not write all data to a file of PDM.
I joined the part of logging of data of my code here. Is there a another way around the problem of memory, as using the same block of memory for buffering of data between the memory of the digitizer and the hard drive?
cheney_anu,
I need to know your details of tdms files before I could provide a buffer appropriate setting.
for example,.
The current design: you write a tdms 40 GB file that contains 1000 groups (a point a group), each group contains 1,000 channels and each channel contains 1 d I16 table with 20 M of length. (Note: this 40 GB tdms file contains 1000 x 1000 = 1 M channels)
Change:, you could write 1 d I16 table instead of table I16 2D, which could reduce the number of channel 1 M 1 k, and then reduce the memory usage.
New design: you write a tdms 40 GB file that contains 1000 groups (a point a group), each group contains 1 channel and each channel contains 1 d I16 array with length 20G (for each point, call 'TDMS write' 1000 times in a "loop For ' and every time write 1 d I16 array with length 20 M). (Note: this 40 GB tdms file contains 1000 x 1 = 1 K channels)
-
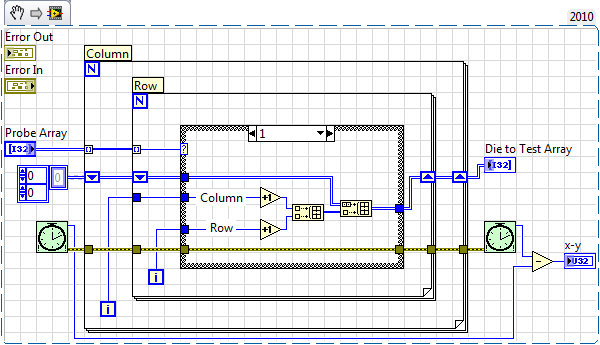
Request: Make these more fast screws for large tables
Hey everybody,
Did anyone mind take a look at these two screws? They work very well for small data sets, but they are starting to take up to 200ms each for large arrays (~ 5000 rows x 2 columns). The first actually sends data to the 2nd, so the total delay when running these screws may be 400, 500 ms. Too much to use them in real time.
Reminder of how they are used:
The user can click or click-and - dragging on a graph of intensity to create a card to die to test. These VI are run to update a list of that die are selected and a list of how the machine will move. In mode click - drag, these VI create a very big delay in the response of the public Service.
First VI:
The entrance is a 2D table 1 or 0, indicating the test or not test. The output is a 2D line (Nx2) table, column numbers should be probed.
Second VI:
The entrance is a table 2D (Nx2) R, C numbers (from the 1st VI). This VI calculates a relative movement of the current matrix with the following matrix. The output is a table 2D (Nx2) of the relative motions (Y, X). Example: ((2,4), (5.1)) back in ((0,0), (3, -3)).
I've already cut the running time up to half of what it was, but it is still not fast enough. And Yes, the limits of error are not connected, I know :-)
Screws (also attached):
So, what do you think? Is there some Subvi I don't know which completely replaces the 1st VI? Is one of the Subvi I use inherently slow?
-
Why these two operations to reshape Array cause an error "memory is full" in LV86?
The attached VI was recorded in LV8.5.
It's a small piece of code which illustrates how one of my applications use to initialize two 2D-arrays of Im DBL. my request the total amount of memory allocated by this VI is about 450 MB (as in the attached VI) and 2D bays 'live' in the shift registers.
Now, I tried to check if the application is running in LabVIEW 8.6 and it stops with an error "memory is full".
I've isolated the problem to this small piece of code and it still does not work without error.
Curious: The same code runs well in LabVIEW 8.2.1 8.5.1, and 7.1.1... So, where is the difference?
Best regards, GuenterI agree it is strange and deserves to be more looking. There is a solution that seems to help it will not change the functionality of your code. Instead use a loop While and shift uninitialized registers, you can use the comment nodes and none while loop. The attached example exhibits the same behavior as your code, but does not give a low memory error.
It seems that the only reason it works is not that I use the nodes of comments, but I'm wiring table 2D through from the node of feedback to the constant table, not a 2D array resizing function. If I have the wiring on the other side, it will fail the same way.
For example, recorded in LV86.

-
Error memory in the construction of modules with Module
OPA dear developers,
Need your help around one of the new features of 10.4 OPA's Modules.
I have two rulebases A and B. While the modules A, I would like to be able to determine the results of the policies written in modules B. So I created a module off B modules (select Build Module), has opened the project to the modules A and connected the output B modules in modules A .rmod (folder Modules > add a Module link..)
When I try to debug without screens, construction is successful and I am able to investigate the rules in here B modules. However, when I debug with screens, build and run for CONTROLLED substances, or build and run in OWD, they all prompt a strace pile on the screen. The cause of the exception is a "means: Java heap space".
If I build separately these rulebases, it works very well and no errors. It happens when one becomes the other module. How this error memory can be fixed? I paste the entire error message below in the hope of helping the investigation. (Sorry for the long text..)
Any help to make this work is appreciated. Thank you!
HTTP status 500
exception
- javax.servlet.ServletException: Servlet.init () for servlet WebDeterminationsServlet threw the exception
org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:117)
org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:174)
org. Apache.Coyote.http11.Http11Processor.Process (Http11Processor.Java:879)
org. Apache.Coyote.http11.Http11BaseProtocol$ Http11ConnectionHandler.processConnection (Http11BaseProtocol.Java:665)
org.apache.tomcat.util.net.PoolTcpEndpoint.processSocket(PoolTcpEndpoint.java:528)
org.apache.tomcat.util.net.LeaderFollowerWorkerThread.runIt(LeaderFollowerWorkerThread.java:81)
org.apache.tomcat.util.threads.ThreadPool$ ControlRunnable.run (ThreadPool.java:689)
java.lang.Thread.run (unknown Source)
first cause
- means: Java heap space
org.apache.xerces.dom.DeferredDocumentImpl.getNodeObject (unknown Source)
org.apache.xerces.dom.DeferredElementNSImpl.synchronizeData (unknown Source)
org.apache.xerces.dom.ElementNSImpl.getNamespaceURI (unknown Source)
org. Apache.Xml.DTM.Ref.dom2dtm.DOM2DTM.AddNode (DOM2DTM. Java:262)
org. Apache.Xml.DTM.Ref.dom2dtm.DOM2DTM.nextNode (DOM2DTM. Java:523)
org.apache.xml.dtm.ref.DTMDefaultBase._nextsib(DTMDefaultBase.java:565)
org.apache.xml.dtm.ref.DTMDefaultBase.getNextSibling(DTMDefaultBase.java:1142)
org.apache.xml.dtm.ref.DTMDefaultBaseTraversers$ ChildTraverser.next (DTMDefaultBaseTraversers.java:463)
org.apache.xpath.axes.ChildTestIterator.getNextNode(ChildTestIterator.java:83)
org.apache.xpath.axes.BasicTestIterator.nextNode(BasicTestIterator.java:170)
org.apache.xpath.axes.NodeSequence.nextNode(NodeSequence.java:335)
org.apache.xpath.axes.NodeSequence.runTo(NodeSequence.java:494)
org.apache.xml.dtm.ref.DTMNodeList. < init > (DTMNodeList.java:81)
org.apache.xpath.objects.XNodeSet.nodelist(XNodeSet.java:346)
org.apache.xpath.jaxp.XPathImpl.getResultAsType(XPathImpl.java:329)
org.apache.xpath.jaxp.XPathImpl.evaluate(XPathImpl.java:282)
com.oracle.determinations.util.xml.dom.XmlElement.selectElements(XmlElement.java:89)
com.oracle.determinations.util.xml.dom.XmlElement.selectElements(XmlElement.java:81)
com.oracle.determinations.engine.local.modules.Module.loadDataModel(Module.java:295)
com.oracle.determinations.engine.local.modules.Module. < init > (Module.java:56)
com.oracle.determinations.engine.local.modules.ModuleLoader.loadChildModules(ModuleLoader.java:72)
com.oracle.determinations.engine.local.modules.ModuleLoader.loadModules(ModuleLoader.java:56)
com.oracle.determinations.engine.local.modules.ModuleLoader.createUnifiedRulebase(ModuleLoader.java:31)
com.oracle.determinations.engine.local.RulebaseLoader.createUnifiedRulebase(RulebaseLoader.java:141)
com.oracle.determinations.interview.engine.local.LocalRulebaseService.applyChangeSet(LocalRulebaseService.java:243)
com.oracle.determinations.interview.engine.plugins.rulebaseresolver.ClassloaderRulebaseResolverPlugin.initialise(ClassloaderRulebaseResolverPlugin.java:73)
com.oracle.determinations.interview.engine.local.LocalRulebaseService. < init > (LocalRulebaseService.java:53)
com.oracle.determinations.interview.engine.local.LocalInterviewEngine.initialise(LocalInterviewEngine.java:181)
com.oracle.determinations.interview.engine.local.LocalInterviewEngine. < init > (LocalInterviewEngine.java:66)
com.oracle.determinations.interview.engine.InterviewEngineFactory.createInstance(InterviewEngineFactory.java:19)
com.oracle.determinations.web.platform.servlet.WebDeterminationsServletContext.init(WebDeterminationsServletContext.java:180)
com.oracle.determinations.web.platform.servlet.WebDeterminationsServletContext. < init > (WebDeterminationsServletContext.java:116)
Hello
You can increase the size of the segment for the built-in Tomcat server.
In OPM, go to tools > Options > Embedded Server, you should see under "Server Properties":
-Xms200m-Xmx200m - Ddeploy.enabled = true
You can just up the memory of something like:
-Xms512m-Xmx512m - Ddeploy.enabled = true
I normally encountered this in rulebases with many alleged (and deducted from the instances) relationships / aliasing / scope of operators etc... You can try your performance rules ensuring that the common logic is grouped in a single intermediate attribute rather than explicitly used each time.
I don't know if it's the 'official' line but this has worked for me in the past.
Thank you
Ben
-
Error memory in Discoverer Plus
Someone has met and found a solution for "OutofMemory error has occurred?
Java console shows-
means
< < no available stack trace > >
I did some research on Metalink and have opened an SR which indicated us a general what-to-do-for-performance-issues doc. So far, we have fixed our 10.1.2.3 instance Discoverer more until the last CP7, but the problem persists.
I'm curious to see if anyone has come across this error and they did to remedy.
-TracyHi Tracy
Discoverer is a memory hog, and on my downloads page, I have a document that explains how to determine the capacity of a server for the record.You will find it here: http://ascbi.com/downloads.htm and this is the first document you will see at the top of the page?
Then, the amount of memory that you have and how much more and users of player you have?
Also, what is the last time you restarted the application server?
Then, the question is what version of Java you are using on the server and the clients?
Best wishes
Michael -
When I try to install Firefox, I get an error "could not open the output file. I used Firefox before and it doesn't work anymore, so I uninstalled. Cannot re - install now.
This has happened
Each time Firefox opened
I tried to download firefox.
User Agent
Mozilla/4.0 (compatible; INTERNET EXPLORER 6.0; Windows NT 5.1; SV1; AntivirXP08; GTB6.3; .NET CLR 2.0.50727; MS - RTC LM 8)
When you click on the download link on GetFirefox.com, you should be asked if you want to run or save the file. If this situation occurs when you try to run the download, try instead to record and put the file on your desktop or in a similar place, where you are certain that you can find.
When the download is complete, try double-clicking on the downloaded file in the normal Windows Explorer (browse your way to the file from the desktop). This should start the installation.
If, in the Explorer window, you notice that the file seems to be missing the Firefox icon orange/blue, right click the file and select Properties. The image should look like the attached picture (except that mine is in Danish, but that is irrelevant) if saved correctly - if it don't look like this, would you please describe the content or attach a screenshot of the box. Especially what it says under "File Type" - it must be 'program '. If this isn't the case, will have to focus on what could be the problem here.
A bit off-topic, your Internet Explorer seems to be quite a bit outdated (IE 6, where the current version is IE 8), so I highly recommend that you try to run Windows Update to get your system up to date. Is it as a society (such as a thin client Terminal Server computer) system, this is not possible, and most likely, your system administrator will have to help you.
-
Large signal output capacitance measurements
Hi all
I'm working on a power amplifier and I want to measure the ability to output under large signal condition. I use a non-linear model of the GaN power transistor.
Power output is about 36 dBm, f = 8.2 GHz
I tried both methods:
(1) I have spent under bias Vgs - 6V to 1V, Vds = 28V. I use solver C_PRC linear tab to find the parallel to the output capacity. I got a chart that changes from 0.3pF to 0.5pF. In this simulation I don't use tuner to impedance, just ports (50 ohm) and sources of bias.
(2) amplifier is biased to 28V and 125mA. Then, I drive amplifier with of 20dBm to 30dBm input power. In this simulation, I used HBTUNERs to maximum power output (power input 25dBm at the entrance) and the output. I can see there is a change in capacity at the entrance vs input power change. However, in the output, production capacity is constant and 0.52pF. I am able the ability of the drain of transistors, tuner. I use great Solver for the parameter measuring signal Y and calculate the capacity.The interesting thing, I can meause entry changes easly to large signal capacity, but output capacity is constant!
I have two questions:(1) why the three measures are different?
(2) for large signal measurements, for example; 30dBm output, 30 v peak-to-peak output average 40dBm 50 v peak-to-peak. So, there is a change in capacity over a period of time. When I measure the Solver big signal, Solver uses the high peak values? If so, can I change low peak value?
(3) can be used for important signals gamma probes?
Thank you
-
Auto resampling of a larger record
Hello
I'm new to LabVIEW, but through the use and practice, I recently became relatively familiar with the program and its capabilities.
However, I am curious to know if there is a way on LabVIEW: second Signal Express automatically sampled and to analyze the second 3 segments (in chronological order), a much larger record of 20 minutes and then export these 3 segments for further analysis (on excel for example). Please let me know if there's some way to do with LabVIEW: Signal Express or if you have any suggestions of a resource can't be taken at National Instruments that could help.Thank you very much
GYepes
Hello GYepes,
Yes, this should be possible. If you open Signal Express, create a new project and go to the tab on the main screen recording Options, you should be able to go to the starting Conditions and use it to trigger the start for every 3 seconds. You can do this with the date Start time by adding 3 date of departure different times 3 seconds independently of each other (not sure how that would be exact). There is another way using the Conditions to stop where you can set the time to 3 seconds after the start. It is also possible to do using triggers to Signal to another device. You use data acquisition devices? If so, you can use one to send a trigger of power to signal the start or stop of your recording. By placing 3 seconds outside triggers, you can accomplish what you're trying to using events under saving Options. Each of these methods should work for what you are trying to do and, if not, you can easily export the check to Excel and then chop the hand that shouldn't be too difficult.
-
allocation of memory for the pointer in the dll
Hello
I am very new to LabVIEW and I was struggling with the third scheduled dll long enough. I am able to configure the device (but with a view of the insufficient resources error code), get the number of connected sensors and the ID of the sensor. But I can't receive data between the device and I think it might be the memory allocation problem.
I use LabVIEW 2015 32-bit on Windows 10.
This is the documentation provided by the seller, and the apdm_ctx_t seems to be a void pointer based on the API (typedef Sub apdm_ctx_t)
APDM_EXPORT apdm_ctx_t apdm_ctx_allocate_new_context (void)
Allocates memory a handful to be used by the libraries of the apdm.
Returns
Zero on success, zero otherwiseBased on a previous post, I set up the return of the function above to be signed pointer size whole. And the following functions will receive this digital context and pass by value.
In the attached png, the apdm_get_next_record requires a complicated structure. I have to do as a cluster and supply the function node (see figure).
The sequence of the vi follows the Matlab code provided by the seller. I have no idea why the vi keeps returning the error code: no data received.
Any thoughts would be great and I can give you more information if necessary. Thank you!
Looking briefly at the provided code that I don't see glaring errors. Are you really sure that you do not have misinterprete all return as failuree values or maybe something in your actual System Setup prevents you to get the values you expect?
You haven't really explained what you think you should get and what you get instead. The matlab example only also shows the use of apdm_ctx_autoconfigure_devices_and_accesspoint5() while you use apdm_ctx_autoconfigure_devices_and_accesspoint4() which I guess is not a big problem, as the example of Matlab is that pass an additional parameter to 0 to the function. However this example shows quite how you're supposed to call apdm_ctx_get_next_record() and then calls apdm_exit() to the end as you do anywhere.
For now, it seems more a problem with the use of the functions of your DLL in the decree that something that should be fixed in nodes of library call to access your DLL and correctly. A suggestion to improve the screw, you have now would be to actually do the appropriate error handling. for now, these functions have nothing to do with the return value of functions. The right way would be to check the documentation and if a function returns or the return parameter can indicate an error for actually cause the error cluster spread a significant error code endorsements. And all functions except those which is intended to release all resources must have a business structure that incoming error, does nothing and doesn't send the error through.
But don't blindly assume that, since the function 1 return 0, not for a mistake that all other functions are too. Some might actually return the number of resources found or whatever with 0 to indicate an error or no resources.
-
Windows Update error 646 for KB981432 and KB980469 on Vista 64 - bit O.S.
I have Windows Update error 646 when trying to install KB981432 and KB980469 in my Vista 64 bit operating system computer. This is the first time I've ever had a problem installing Windows updates. Can you please help?
Subsequently, in a Microsoft forum, I followed the directions to add the registry information in the book below (I copied & pasted the below for Notebook, "recorded under" register.bat on my desktop, then right click on it on my desk & "run as Administrator" and then tried to install, but it did not work):
REGSVR32 WUPS2. DLL/S
REGSVR32 STINKS. DLL/S
REGSVR32 WUAUENG. DLL/S
REGSVR32 WUAPI. DLL/S
REGSVR32 WUCLTUX. DLL/S
REGSVR32 WUWEBV. DLL/S
REGSVR32 JSCRIPT. DLL/S
REGSVR32 MSXML3. DLL/SHi Rocketron,
Sometimes patches seem to just have a hard time to proceed with the installation. I have a fw for to look you at other things. First of all, your Background Intelligent Transfer Services set to Automaticand started and Windows Update ? You can check these settings by typing services.msc in the search box of the start menu.
Sometimes in order to get patches to install correctly, you must perform these tasks manually.
(1) Download Center to visit Microsoft: http://www.microsoft.com/downloads/en/default.aspx.
(2) search for each update code that begins with the letters "KB" and followed by a set of numbers (i.e. KB979309).
3) click on the link for the download and then click on download and run. You must accept the agreement and then click on continue.
(4) repeat this process for each download of updates Windows could not install.
(5) to rerun the update from Microsoft, click find updates. If all goes well, it will show that you are completely patched.If this does not work, try to run the Microsoft OneCare safety scanner. Sometimes it will solve problems of hidden registry, or erase viruses can prevent the installation of patches: http://onecare.live.com/site/en-us/center/whatsnew.htm. Click full service scan, and then Quick scan (full scan takes a long time to complete). Try the patches.
Good luck
Barbara

Maybe you are looking for
-
Try to upgrade OS 10.6.8 to El Capitan on iMac. But the FREE update tells me it can not install but will not say why even when I click on learn more. Suggestions? Help? Appreciate the assistance.
-
Is it possible to move the dock to the 'start' position in El Capitan?
I wish that the dock to appear in the upper left corner of my screen. I have the dock on the left, but I want to move it to the top in the corner (the starting position). This could be achieved in an earlier version of Mac OS X with a command line te
-
turn off HP Simplepass messages
How can I turn off HP Simplepass messages on a new Windows 8 HP laptop? A "pop-up" appears whenever he recognizes that I am in a protected password site. "Do you want HP SimplePass to remember your password for this site?
-
Aspnet_regiis.exe errors on XP SP3
Note: This thread seems to be posted in the Windows 7 forum, even when clicking on the forum of "Windows Update" in Windows XP.Machine: Windows XP Media Center, SP3 Edition. I had a _ a time recently with the .NET framework on my computer if it is no
-
Boot fail error bios checksum after bios update
Oh, im so nervous I "update" the bios of my Compaq SR5027CL with this http://h10025.www1.hp.com/ewfrf/wc/softwareDownloadIndex?softwareitem=pv-66758-1&lc=en&dlc=en&cc=us&... I have download and run this patch and the program tells me that the bios ha