limitation of table
Hello
I need to process more than 10 + 6 data values. I want to treat them all these values in a table, but it seems that I can put only 10 + 5 (100000) values in a table.
Whence this limitation and how to fix this?
Anyone?
Thank you.
Tags: NI Software
Similar Questions
-
Limiting the tables and using lindex in commands regexp
Hello
Here's my second and extremely crap question/post in what concerns the EEM/TCL. I did some research on Google and have not really been able to find an answer to these questions. Probably more due to my lack of agility with the search bar of the information being just is not there. Hope you'll forgive me if.
1. my first question is this. Say I want to get an output of a command. I would like to see all the interfaces in the 'ip vrf command show interface' for example. Not knowing how many interfaces there may be, there could be 10, or there might be 200, what is the best way to limit a loop function after that I gave the following commands?
Set _vrf_int [exec show ip vrf interface]
Set _array_vrf_int [split $_vrf_int '\n']set $i 0
then {$i< 200}="">
RegExp {([A-Z]+[a-z]+[0-9]+). *} [lindex $_array_vrf_int $i] _complete_string _int
Inc. $i 1}
Not 100% sure that the syntax is correct, sorry. If I don't have that 10 interfaces so it won't be necessary to issue this loop 200 times to "$_array_vrf_int". Also wouldn't be great if I went through the 200 interfaces. Is there a way I can limit this loop based on the number of lines that were captured after the split function?
2. the value of the regular expression above is output in the var $_int. Is there a way I can output the regular expression in a table? a ' :-
RegExp {([A-Z]+[a-z]+[0-9]+). *} [lindex $_array_vrf_int $i] _complete_string [lindex $ $i _int]
Syntax is certainly not correct, but I guess there could be a way to do this. Any thoughts?
3. I did some comparisons on an outing to see if an access list is present on an interface. I can get a regexp to pull back the name of the access on a given interface list, but if there are any access-list to an if statement on anything?
Set _acl_name 0
RegExp {. * ip access-group (. *) in} $_running_int _complete_string _acl_name
If {$_acl_name! = 0} {puts ' there is an access-list on $_int "} else {puts ' there is no acl on _int $ :-("} "}
In the above output I'm defining the value of ' $_acl_name ' to zero so that I can compare it to the fi statement. This seems to be a newbie to shit how do however. Is it a kind of generic I put in place of the '0' to match an empty variable. has ' {null}.
4 I'm sorry last question. I also reset the variable {null} using a similar wildcard. Once again I can reset the variable to 0, but it seems just that I do not understand that the syntax well enough and it is without doubt a better method.
5. I have read several tutorials that cover a lot of bases. Is there a good reference that anyone can suggest so I don't waste your time with these silly questions? I'm afraid that the scripts I've studied on this forum are always way above my head.
Thanks in advance
Alex
Assume that the limit of the loop. Which will never end well. Instead, use a foreach loop to iterate over the number of lines in the output:
set vrf_int [exec "show ip vrf interface"]
foreach line [split $vrf_int "\n"] {
if { [regexp {([A-Za-z0-9]+).*} $line -> int_name] } {puts "Interface name is $int_name"
}
}
In addition, do not use the variables that start with "_". Those that are reserved for the Cisco or overall use. In addition, 'exec' is a single command tclsh. If you use the EEM Tcl, you will need to interact with the CLI library. You can watch our best practices guide at https://supportforums.cisco.com/docs/DOC-12757 for some tips and tricks with the use of EEM.
You can use - all and--inline for regexp all return in a list. However, given the idea of the loop above, you can also use lappend to each pass:
set intlst [regexp -all -inline {([A-Za-z0-9]+).*} $output]set vrf_int [exec "show ip vrf interface"]
set intlst [list]
foreach line [split $vrf_int "\n"] {
if { [regexp {([A-Za-z0-9]+).*} $line -> int_name] } {lappend intlst $int_name
}
}
You can use "info exist" or simply to check the result of your regexp command to see if a match took place. See the example above the latter.
regexp {.*ip access-group (.*) in} $_running_int _complete_string _acl_name
if {[info exists $_acl_name]} {puts "there is a access-list on $_int"} else {puts "there's no acl on $_int :-("}
You can 'reset' a variable by using the command 'deactivated '.
One of the best general Tcl references is the "book of the pen:
-
ORA-14299 & many partitions limits per table
Hello
I have linked the question, see below for the definition of table and error during the insert.
CREATE TABLE MyTable
(
RANGEPARTKEY NUMBER (20) NOT NULL,
HASHPARTKEY NUMBER (20) NOT NULL,
SOMEID1 NUMBER (20) NOT NULL,
SOMEID2 NUMBER (20) NOT NULL,
SOMEVAL NUMBER (32,10) NOT NULL
)
PARTITION BY RANGE (RANGEPARTKEY) INTERVAL (1)
SUBPARTITION BY HASH (HASHPARTKEY) 16 SUBPARTITIONS
(PARTITION myINITPart NOCOMPRESS VALUES LESS THAN (1));
Insert Into myTable
Values
(65535,1,1,1,123.123)
ORA-14299: total number of partitions/subpartitions exceeds the maximum limit
I am aware of the restriction that Oracle has on a table. (Max 1024K-1 including the partitions
subpartitions) that prevents me to create a document with the key value of 65535.
Now I am stuck as I have more than this number (65535) ID, the question becomes how to manage
by storing data of the older identifications this 65534?
One of the alternatives that I thought is retirement/drop old partitions and modify the first partition
myINITPart to store data for more partitions (which are actually retired in any way) - that I could
having more available for store IDS.
Therefore the PARTITION myINITPart VALUES LESS THAN (1) would be replaced by VALUES myINITPart PARTITION
LESS THAN (1000) and Oracle will allow me to store additional data 1000 ids. My concern is Oracle
I do not change the attributes of the original score.
Don't we see no alternatives here? Bottomline, I want to store data for IDS higher than 65535 without restriction.
Thank you very much
Dhaval
Gents,
I want to share that I found alternative.
Here's what I did.
(1) merge first partition in following adjacent partition, in this way, I will eventually have an extra-tested partition, the number of limit of n + 1 partition (this is what I wanted) - so where before I do not - charge I will eventually merge the first partition (in this case, my first couple of partition will be empty anyway in order to not lose anything by merging)-faster in my case.
(2) any index, we have will be invalidated needs to rebuild itself, I'm good that I have none.
(3) local index is not invalidated.
So, I was able to increase the limit of fusion just first partition in following a good - work around.
Thank you all on this thread.
-
Limitation of Table inserts and updates.
Hi friends,
I learn Oracle PL/SQL.
I need to create a table for audit purposes. I want the table to be updated only by a procedure and not by all users.
I have also some paintings, where only a few columns must be accessible to insert or update to users. The remaining columns in this table may not be editable.
How can I achieve this in Oracle PL/SQL. Help, please.
Thank you
Deepak
I learn Oracle PL/SQL.
I need to create a table for audit purposes. I want the table to be updated only by a procedure and not by all users.
Place the table in diagram A. Do not give access to this table to other drawings.
Create a procedure/package to diagram A - he can write/update the table has.
Grant execute access to this procedure/package to other drawings.
I have also some paintings, where only a few columns must be accessible to insert or update to users. The remaining columns in this table may not be editable.
Something like
grant update (col1, col2) on tableA to UserB;
See GRANT
-
Jdev 11 - table ADF + rangesize
Hello
I have an adf table in my JSF page:
Here is a part of pageDef... <af:table summary="" value="#{bindings.rendezvousVO1.collectionModel}" var="row" rows="#{bindings.rendezvousVO1.rangeSize}" emptyText="#{bindings.rendezvousVO1.viewable ? 'No rows yet.' : 'Access Denied.'}" fetchSize="#{bindings.rendezvousVO1.rangeSize}" selectedRowKeys="#{bindings.rendezvousVO1.collectionModel.selectedRow}" selectionListener="#{bindings.rendezvousVO1.collectionModel.makeCurrent}" rowSelection="single" id="table1" width="597" inlineStyle="height:132px;"> <af:column sortProperty="Medecin" sortable="false" headerText="#{bindings.rendezvousVO1.hints.Medecin.label}"> <af:outputText value="#{row.Medecin}"/> </af:column> <af:column sortProperty="AgDate" sortable="false" headerText="#{bindings.rendezvousVO1.hints.AgDate.label}"> <af:outputText value="#{row.AgDate}"> <af:convertDateTime pattern="#{bindings.rendezvousVO1.hints.AgDate.format}"/> </af:outputText> </af:column> <af:column sortProperty="Heure" sortable="false" headerText="#{bindings.rendezvousVO1.hints.Heure.label}"> <af:outputText value="#{row.Heure}"/> </af:column> <af:column sortProperty="Lib1" sortable="false" headerText="#{bindings.rendezvousVO1.hints.Lib1.label}"> <af:outputText value="#{row.Lib1}"/> </af:column> </af:table> ...
The problem is that my adf table shows all results at the same time on the page instead of 3 (3 is the rangesize)... <iterator Binds="rendezvousVO1" RangeSize="3" DataControl="AppModuleDataControl" id="rendezvousVO1Iterator"/> ...
Thanks for your helpSalvation in automatic height to 3 lines will limit the number of records 3. but for this to take place, you must have at least one component (say a command button) after this table. Suppose that u have no other components after the table, then all the lines will be displayed. If you have a component atlease after this table, then it displays 3 discs and a scroll to scroll bar down. Scroll down to view other documents. There is no paging in JDev 11 g that seems. If u cannot have next previous buttons to navigate in the set of records. I hope I made clear.
Hope links below will be useful.
Limitation ADF table number of lines does not work
How to limit the number of rows in the table of the ADF
ADF Table with given the number of lines
-
How to extract data from an arbitrary xml file and export it to a CSV friendly?
Hallo,
I am facing big problems in the use of XML files. I have a
application that generates XML files with clusters containing arrays
and scalars as in the example pasted below. My task is to
Read it and export the data into a CSV document readable by a human.
Since I do not know the actual content of the cluster, I need some sort
Smart VI through the XML looking for berries
and other data structures for export properly in the CSV file
format (columns with headers).
Thank you
3
6
0
1
2
3
4
5
3.14159265358979
Ciao
Rather than to get the
node, you can just go directly to the node since ' one that really interests you. Basically what it means to determine the elements of table how much you have, and it depends on if you have 1 or 2 knots . The rest is just of the child nodes and the next siblings. See attachment as a starting point. The attached XML file is a table 2D (change the .xml extension). Notes on the example:
- I did not close properly references, so it's something you need to do.
- It is limited to tables 1 d or 2D.
- I suggest using a control path of the file to specify the input XML file and path of the file/folder control to specify the location of the output file.
-
Column data reading according to the number of lines
Hi guys,.
I am currently stuck on the problem of recovering the data from my database (MS Access) according to the number of lines, he has at any time (without having to know how many lines there will be during the programming of this part).
First, I show how my program works. I'm working on an automated food, order and after the customer has chosen his power, system information such as the name of the food, quantity and price of the food will be written to the MS Access database table. (for example table name "Orderingtable" in MS Access) For my case, 1 order of food will occupy 1 line of the database table. In other words, as part of the same, if he orders 3 different foods, 3 rows will be filled in my database table.
I would then get the part number of 'Quantity' for each order of the database and summarize the amount finally to count the total number of orders in the table of database at any time. This addition of result will be then shown on the Panel before informing the customer how many orders waiting's just prior to his order. In this case, it can get out if he wants to, if the number of orders is too big for its waiting time.
However, I do not know how many lines my 'Orderingtable' will be 'Orderingtable' because both accumulate lines and data lines until being command to remove. Therefore, I cannot predict how many lines I program the party totals the number of quantity for each line.
Is it possible that I can get the part of the 'quantity' without having to know the number of rows in the database so that I can count the total number of pending orders just by adding up the value of the quantity for each line?
I do not wish to "code" my program by limiting the tables of database for us are going to say, only 50 lines at any time.
Attached below, this is how my database table "Orderingtable" looks at, which will be used to extract the 'Quantity' column so that it can count the total number of orders and be shown/shown on the front panel of my Labview program.
I hope that you are able to help me!
Thank you so much in advance.
See you soon,.
MUI
You can also use the SUM function:
SELECT SUM (Quantity) OF the order WHERE Queue_No = %d
And no need of an "Order By" clause, if you add just the quantities.
-
Maximum number of vNIC by blade
Is there a maximum number of vNIC tolerated by profile blade-server when you use 6248 FIs and blades B200 M4 with 1340 expander cards and the number of lower authorized vNIC with the same blade but without port expansion card?
Greetings.
Port expansion card increases the bandwidth at each step the number of NICs for IOM.
You will generally get capped the number max of vNIC with the shaft of the BONE before you hit any limit equipment UCS. The limits of table in the link above are OS limits.
Thank you
Kirk...
-
Hi all
Replication SQL Server 2008 Gg to Oracle 11R2.
I tested the replication GG for 2 weeks now, but still has no , but I was not able to replicate success one of our tables in SQL Server.
Whenever I run 'Add trandata' I always hit OGG-01483. That means our sqlserver tables are too complicated and do
to qualify for replication? Can you share me links to GG limitations for table replication requirements?
Help, please...
Thank you very much
zxy
GGSCI (DELL-R410) 2> add trandata dbo.pictures 2013-06-29 03:11:30 WARNING OGG-01483 The key for table [ACRDB.dbo.Pictures] contains one or more variable length columns. These columns may not have their pre-images written to the transaction log during updates. Please use KEYCOLS to specify a key for Oracle GoldenGate to use on this table. 2013-06-29 03:11:31 WARNING OGG-00552 Database operation failed: SQLExecDirect error: EXECUTE sys.sp_cdc_enable_db if 0 = (select st.is_tracked_by_cdc from sys.tables as st where st.object_id = object_id(N'dbo.Pictures')) AND 0 = (select st.is_replicated from sys.tables as st where st.object_id = object_id(N'dbo.Pictures')) BEGIN DECLARE @capture_instance sysname = N'OracleGG_' + cast(object_id(N'dbo.Pictures') as sysname) CREATE TABLE #ggsTabKeys (db sysname, name sysname, owner sysname, column_name sysname, key_seq int, pk_name sysname) INSERT INTO #ggsTabKeys EXEC sp_pkeys 'Pictures', 'dbo' IF 0 = (SELECT COUNT(*) FROM #ggsTabKeys) BEGIN INSERT INTO #ggsTabKeys SELECT TOP (1) DB_NAME(), '', '', name, 1, '' FROM sys.columns sc WHERE sc.object_id = OBJECT_ID(N'dbo.Pictures') AND is_computed = 0 AND max_length > 0 ORDER BY max_length END IF 0 = (select COUNT(*) from #ggsTabKeys) BEGIN INSERT INTO #ggsTabKeys SELECT TOP (1) DB_NAME(), '', '', name, 1, '' FROM sys.columns sc WHERE sc.object_id = OBJECT_ID(N'dbo.Pictures') AND is_computed = 0 AND max_length > 0 ORDER BY max_length END DECLARE @cols NVARCHAR(max) SELECT @cols = REPLACE(REPLACE(REPLACE( STUFF(( SELECT ',' + QUOTENAME( t.column_name) FROM #ggsTabKeys AS t FOR XML PATH('') ), 1, 1, '') ,'<','<'),'>','>'),'&','&') execute sys.sp_cdc_enable_table @source_schema = N'dbo' , @source_name = N'Pictures' , @role_name = NULL , @captured_column_list = @cols , @capture_instance = @capture_instance IF EXISTS(SELECT OBJECT_ID('tempdb..#ggsTabKeys')) BEGIN DROP TABLE #ggsTabKeys END end . ODBC error: SQLSTATE 01000 native database error 16954. [Microsoft][SQL Server Native Client 10.0][SQL Server]Executing SQL directly; no cursor. 2013-06-29 03:11:31 WARNING OGG-00782 Error in changing transaction logging for table: 'dbo.Pictures'. ERROR: ODBC Error occurred. See event log for details..OK, well that's the problem then. I didn't know that it was standard edition. Capture the OGG is only supported on 2008 Enterprise Edition because it uses the structure of the CDC as a mechanism for the TRANDATA, which is no longer available on EA and not SE.
-
Failed to execute ODCIINDEXINSERT routine loading points
I used SQL * Loader of 11.2 million customer records in a table space 11.2 (points of longitude and latitude) and I got the following error:
The table has a spatial index on a column VEHICLE_LOCATION with MDSYS. Data SDO_GEOMETRY type. The tables and the spatial indexes are partitioned "monthly" column MESSAGE_DATETIME. The database is 11.2 (11 GR (2), the client and SQL * Loader is version 11.2.SQL*Loader: Release 11.2.0.1.0 - Production on Fri Oct 12 10:17:57 2012 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. ORA-39776: fatal Direct Path API error loading table CISDWSYS.VEHICLE_LOCATION_FACT ORA-29875: failed in the execution of the ODCIINDEXINSERT routine ORA-22054: underflow error ORA-06512: at "MDSYS.SDO_INDEX_METHOD_10I", line 720 ORA-06512: at "MDSYS.SDO_INDEX_METHOD_10I", line 225 SQL*Loader-2026: the load was aborted because SQL Loader cannot continue. Load completed - logical record count 45000.
My control file is:
I noticed that the number of 'Charging - number of records' logic is not always even. For example, when the data file size is about 300 MB the logical number of records is 45000 and when data file size is 500 MB, then the number of logical records is 110000. Data in both files are the same nature, just places vehicle GPS (points).options (direct=yes, bindsize=20971520, readsize=20971520) Load data Append into table VEHICLE_LOCATION_FACT fields terminated by "," (VEHICLE_LOCATION_MESSAGE_ID CONSTANT 222, MESSAGE_DATETIME Date 'YYYY-MM-DD HH24:MI:SS', ROUTE_NUMBER,RUN_NUMBER,VEHICLE_NUMBER,BADGE_NUMBER, TRIP_DIRECTION,GPS_LONGITUDE_NUMBER,GPS_LATITUDE_NUMBER,DIVISION_NUMBER, VEHICLE_LOCATION COLUMN OBJECT ( SDO_GTYPE Integer EXTERNAL, SDO_SRID CONSTANT 8265, SDO_POINT COLUMN OBJECT ( X FLOAT EXTERNAL, Y FLOAT EXTERNAL ) ) )
The control.log file is
I'm confused by the negative "overflow error" reported death because all data in the data file are correct values. When I remove the spatial index and load the records using the same control file, the same data file, and the same table, I get no error, and later I recreate the spatial index without errors. Which should mean that the values in the data file are good, not 'in' values.SQL*Loader: Release 11.2.0.1.0 - Production on Fri Oct 12 10:17:57 2012 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. Control File: Load_Vehicle_Locations_2.ctl Data File: CIS_VehLoc_L05120603gps.txt Bad File: CIS_VehLoc_L05120603gps.bad Discard File: none specified (Allow all discards) Number to load: ALL Number to skip: 0 Errors allowed: 50 Continuation: none specified Path used: Direct Table VEHICLE_LOCATION_FACT, loaded from every logical record. Insert option in effect for this table: APPEND Column Name Position Len Term Encl Datatype ------------------------------ ---------- ----- ---- ---- --------------------- VEHICLE_LOCATION_MESSAGE_ID CONSTANT Value is '222' MESSAGE_DATETIME FIRST * , DATE YYYY-MM-DD HH24:MI:SS ROUTE_NUMBER NEXT * , CHARACTER RUN_NUMBER NEXT * , CHARACTER VEHICLE_NUMBER NEXT * , CHARACTER BADGE_NUMBER NEXT * , CHARACTER TRIP_DIRECTION NEXT * , CHARACTER GPS_LONGITUDE_NUMBER NEXT * , CHARACTER GPS_LATITUDE_NUMBER NEXT * , CHARACTER DIVISION_NUMBER NEXT * , CHARACTER VEHICLE_LOCATION DERIVED * COLUMN OBJECT *** Fields in VEHICLE_LOCATION SDO_GTYPE NEXT * , CHARACTER SDO_SRID CONSTANT Value is '8265' SDO_POINT DERIVED * COLUMN OBJECT *** Fields in VEHICLE_LOCATION.SDO_POINT X NEXT * , CHARACTER Y NEXT * , CHARACTER *** End of fields in VEHICLE_LOCATION.SDO_POINT *** End of fields in VEHICLE_LOCATION ORA-39776: fatal Direct Path API error loading table CISDWSYS.VEHICLE_LOCATION_FACT ORA-29875: failed in the execution of the ODCIINDEXINSERT routine ORA-22054: underflow error ORA-06512: at "MDSYS.SDO_INDEX_METHOD_10I", line 720 ORA-06512: at "MDSYS.SDO_INDEX_METHOD_10I", line 225 SQL*Loader-2026: the load was aborted because SQL Loader cannot continue. Table VEHICLE_LOCATION_FACT: 0 Rows successfully loaded. 0 Rows not loaded due to data errors. 0 Rows not loaded because all WHEN clauses were failed. 0 Rows not loaded because all fields were null. Date cache: Max Size: 1000 Entries : 192 Hits : 44808 Misses : 0 Bind array size not used in direct path. Column array rows : 5000 Stream buffer bytes: 256000 Read buffer bytes:20971520 Total logical records skipped: 0 Total logical records rejected: 0 Total logical records discarded: 0 Total stream buffers loaded by SQL*Loader main thread: 9 Total stream buffers loaded by SQL*Loader load thread: 9 Run began on Fri Oct 12 10:17:57 2012 Run ended on Fri Oct 12 10:18:34 2012 Elapsed time was: 00:00:37.16 CPU time was: 00:00:00.32
Also, when I do not use "DIRECT = Yes" load in the file control, then SQL * Loader loads all records without error, but it takes hours which is too long.
I want to avoid having to remove the spatial index each morning before the process data, loading, because it is a very large table and it takes 45 to 60 minutes to recreate this index partition, and that a lot of delay time is not good.
Can someone please provide a tip or point to a link with examples of using "sqlldr" to load the large number of records in a table space with spatial index?
Thank you
MilanHi Milan,
Take a look at the "Oracle database data cartridge Developer's Guide" [http://docs.oracle.com/cd/E11882_01/appdev.112/e10765/dom_idx.htm#autoId50] (this is the version of rel2 11g but is the same with 9i)
(..)
SQL and the index of the field Charger *.
SQLLoader conventional path load and direct path loads are supported for tables on what domain index are defined, with two limitations:
-The table must be organized in a heap.
+ -The domain index may not be defined on a LOB column. +To do a load of direct path on an index defined on an IOT or a LOB column area, these tasks:
-Deletion of the domain index
-Make the burden of direct path to SQL * Loader.
-Rebuild field indexes.(...)
doesn't seem to be possible to use the 'method of the direct path' with the spatial index (domain)
I hope for you that there is a solution...
Good luckCarlT
-
Hello
Can frank, you help me again? Please? I'm still working on this hierarchical queries, and I think that you are the only person who can help you.
I need to do a SELECT complex between two tables. Your help in this previous post ( has been very useful.
I learned a lot and almost all of the transformations that I put in place, but I have a really weird... I have to be able to limit the number of offspring for a given node.
Take this DEPARTMENT table, it is a simple HIERARCHICAL table. IDS are convinient, but in reality id are completely random:
And I also have another table with gives for a given node, the number of offspring allowed for a given node.SET DEFINE OFF; DROP TABLE DEPARTMENTS; CREATE TABLE DEPARTMENTS ( dpt_id NUMBER(10), parent_id NUMBER(10), dpt_name VARCHAR2(100) ); INSERT INTO DEPARTMENTS VALUES(1, null, 'Sales'); INSERT INTO DEPARTMENTS VALUES(2, null, 'Insurance'); INSERT INTO DEPARTMENTS VALUES(3, null, 'Accounting'); INSERT INTO DEPARTMENTS VALUES(4, null, 'R & D'); INSERT INTO DEPARTMENTS VALUES(5, null, 'IT'); INSERT INTO DEPARTMENTS VALUES(10, 1, 'Local Sales'); INSERT INTO DEPARTMENTS VALUES(11, 1, 'European Sales'); INSERT INTO DEPARTMENTS VALUES(12, 1, 'Asian Sales'); INSERT INTO DEPARTMENTS VALUES(13, 1, 'South American Sales'); INSERT INTO DEPARTMENTS VALUES(110, 11, 'Germany'); INSERT INTO DEPARTMENTS VALUES(111, 11, 'France'); INSERT INTO DEPARTMENTS VALUES(112, 11, 'Belgium'); INSERT INTO DEPARTMENTS VALUES(113, 11, 'Luxembourg'); INSERT INTO DEPARTMENTS VALUES(114, 11, 'Spain'); INSERT INTO DEPARTMENTS VALUES(1101, 110, 'Berlin'); INSERT INTO DEPARTMENTS VALUES(1111, 111, 'Paris'); INSERT INTO DEPARTMENTS VALUES(1121, 112, 'Brussels'); INSERT INTO DEPARTMENTS VALUES(1141, 114, 'Madrid'); INSERT INTO DEPARTMENTS VALUES(1142, 114, 'Barcelona'); INSERT INTO DEPARTMENTS VALUES(1143, 114, 'Malaga'); INSERT INTO DEPARTMENTS VALUES(121, 12, 'China'); INSERT INTO DEPARTMENTS VALUES(20, 2, 'Car Insurance'); INSERT INTO DEPARTMENTS VALUES(21, 2, 'Home Insurance'); INSERT INTO DEPARTMENTS VALUES(22, 2, 'Family Insurance'); INSERT INTO DEPARTMENTS VALUES(200, 20, 'Bus'); INSERT INTO DEPARTMENTS VALUES(201, 20, 'Family car'); INSERT INTO DEPARTMENTS VALUES(2011, 201, 'Sub category for family car'); INSERT INTO DEPARTMENTS VALUES(202, 20, 'Sport car');
For example, the first record inserted into the table of limited means for the Department with id 4 take us 4 offspring. The strange thing is that the 11 node is a descendant of the node 11. And you override the value of its parent. At this level, substitute us the value and we accept only one descendant level.CREATE TABLE LIMITATIONS ( dpt_id NUMBER(10), lvl_cnt NUMBER(10) -- max descendants ); INSERT INTO LIMITATIONS VALUES(1, 4); INSERT INTO LIMITATIONS VALUES(11, 1); INSERT INTO LIMITATIONS VALUES(2, 2); INSERT INTO LIMITATIONS VALUES(20, 2);
The first example to delete the record from Berlin in the result.
The second pair of insertion is to have the second scenario I have to manage. Instead of substitute for a limitation of parent by reducing it, I must also support increasing values. A descendant node can
have more value than a parent one.
This second example keeps the Department with dpt_id = 2011. Even if I get only 2 descendant of the Department with id = 2.
Any suggestions on how I can proceed? I'm still using Oracle 10 g Release 2"LEVEL" "DPT_ID" "PARENT_ID" "LPAD('',LEVEL)||DPT_NAME" "1" "1" "" " Sales" "2" "10" "1" " Local Sales" "2" "11" "1" " European Sales" "3" "110" "11" " Germany" "3" "111" "11" " France" "4" "1111" "111" " Paris" "3" "112" "11" " Belgium" "4" "1121" "112" " Brussels" "3" "113" "11" " Luxembourg" "3" "114" "11" " Spain" "4" "1141" "114" " Madrid" "4" "1142" "114" " Barcelona" "4" "1143" "114" " Malaga" "2" "12" "1" " Asian Sales" "3" "121" "12" " China" "2" "13" "1" " South American Sales" "1" "2" "" " Insurance" "2" "20" "2" " Car Insurance" "3" "200" "20" " Bus" "3" "201" "20" " Family car" "4" "2011" "201" " Sub category for family car" "3" "202" "20" " Sport car" "2" "21" "2" " Home Insurance" "2" "22" "2" " Family Insurance" "1" "3" "" " Accounting" "1" "4" "" " R & D" "1" "5" "" " IT"
Thanks in advance,Hello
user13117585 wrote:
Imagine this data set:TRUNCATE table departments; INSERT INTO departments values(1, null, 'name 1'); INSERT INTO departments values(10, 1, 'name 10'); INSERT INTO departments values(100, 10, 'name 100'); INSERT INTO departments values(1000, 100, 'name 1000'); INSERT INTO departments values(10000, 1000, 'name 10000'); INSERT INTO departments values(100000, 10000, 'name 100000'); INSERT INTO departments values(1000000, 100000, 'name 1000000'); INSERT INTO departments values(10000000, 1000000, 'name 10000000');When you CONNECT BY
SELECT LEVEL, dpt_id, parent_id, LPAD(' ', LEVEL) || dpt_name FROM departments START WITH parent_id IS NULL CONNECT BY PRIOR dpt_id = parent_id;You have 6 different level.
I have 8 different levels, not 6. You use 'level' to mean something other than the 1st column in the query above? Explain.
Imagine that I put on the limits of table to the following folder:
truncate table limitations; INSERT INTO LIMITATIONS VALUES(1, 4);Then, select it I write should return only the first four results of my previous recordings (up to dpt_id = 1000).
But in the table, I should be able to establish a limit on any node in the tree. For example, insert a record for id = 100, then set it to a limitation of 2. And then, the limitation of the mother is overridden. This means that for 100 service, 2 other descending levels is recovered. (We assume that we cannot have broken trees. You can't say, add a limitation on the node with dpt_id = 1 to 1, then add a limitation on the 10000 to 1 node. Thats is not allowed).
SO if I add
INSERT INTO LIMITATIONS VALUES(100, 2);Level 5 first on my select must be indicated. Because I asked to recover more than two levels of node 100 which is already at level 3.
Why 5 levels and not 4? When limit you the output to four levels of 1, you were level 1 in other words, the four levels are 1, 2, 3 and 4. When you are limiting the output at two levels of level 3, why are they not at these two levels 3 and 4?
But the limits can be to increase the depth of the tree to recover from a particular node or cut the knots.
INSERT INTO LIMITATIONS VALUES(1, 10); -- get 10 descendent levels even if it only contains 6 levels.What do you want on the last 4 lines of output in this case?
INSERT INTO LIMITATIONS VALUES(10, 2); -- override previous limitation and returns only 2 descendents from level 10.Do you really mean level 10, or do you mean dpt_id 10?
If I have ass these limitations (and delete the previous ones), I would like to show only the first 3 levels. Because dpt_id 10 is alread at level one.
Is not dpt_it = 10 to level * 2 *? Dpt_id = 1 is at level 1.
The limitation is not an account on descendants, there is a limitation in the level.
Doesn't that contradict what you said above in this post:
the column name is not very clear. And as you say, it should be more descendant_cnt
?
If a node has 100 direct descendants (children) at level + 1, and the limitation is level + 2, it must return all nodes. The limitation is the depth of a given node.
I don't know if this is clearer?
No, sorry. Please answer the questions above.
Here is the answer to a problem of intresting. This isn't the problem that you have requested in this message, or the problem you asked in your first post, but it may be the problem that you wanted to post:
WITH got_limitations AS ( SELECT d.dpt_id , d.parent_id , d.dpt_name , l.lvl_cnt FROM departments d LEFT OUTER JOIN limitations l ON d.dpt_id = l.dpt_id ) , tree AS ( SELECT LEVEL AS lvl , dpt_id , parent_id , LPAD ( ' ' , LEVEL - 1 ) || dpt_name AS d_name , LEVEL || SYS_CONNECT_BY_PATH ( LEVEL + lvl_cnt - 1 , ',' ) AS max_lvl_path , ROWNUM AS r_num FROM got_limitations START WITH parent_id IS NULL CONNECT BY parent_id = PRIOR dpt_id ) SELECT lvl , dpt_id , parent_id , d_name FROM tree WHERE lvl <= TO_NUMBER ( REGEXP_SUBSTR ( RTRIM ( max_lvl_path , ',' ) , '[0-9]+$' -- Group of digits at the end ) ) ORDER BY r_num ;Given the sample of departments and these data within the limits:
INSERT INTO LIMITATIONS VALUES(1, 4);It returns the 4 rows.
With the same data in departments and in the limits:INSERT INTO LIMITATIONS VALUES(1, 4); INSERT INTO LIMITATIONS VALUES(100, 2);It produces 4 rows (not the 5 you asked).
If has limits ofINSERT INTO LIMITATIONS VALUES(1, 10);It returns 8 rows (not the 10 you asked).
-
Can we use FGA (Fine grain audit) edition standard oracle?
Hi all
I am looking for your help.
I put audit_trail db setting and when I tried to add the policy by using BEGIN
DBMS_FGA.add_policy... it shows ORA-00439: feature not enabled no: refined audit
SQL > select version of $ v; *
BANNER
----------------------------------------------------------------
Oracle Database 10g Release 10.2.0.4.0 - Production 64-bit
PL/SQL Release 10.2.0.4.0 - Production
CORE 10.2.0.4.0 Production
AMT for Linux: release 10.2.0.4.0 - Production
NLSRTL Version 10.2.0.4.0 - Production
SQL > select option $ v where PARAMETER in ('access control very specific', 'Fine grain audit'); *
VALUE OF THE PARAMETER
---------------------------------------------------------------- ----------------------------------------------------------------
FALSE fine-grained access control
Grain end FALSE audit
Thanks in advance :)
Published by: Oracle_2410 on August 9, 2011 03:00
Published by: Oracle_2410 on August 9, 2011 03:10
Published by: Oracle_2410 on August 9, 2011 03:13You are right.
The use of RLS is limited to tables of Portal metadata repository only when you use a standard edition.
I deleted the event line, maybe you can do the same thing.
Best regards
mseberg
Published by: mseberg on August 9, 2011 05:32
-
RMAN > unrecoverable report;
Files report requiring a backup due to unrecoverable operations
Type of file backup name required
---- ----------------------- -----------------------------------
22 full or incremental /u02/proddata/a_txn_data01.dbf
23 full or incremental /u02/proddata/a_txn_data02.dbf
24 full or incremental /u02/proddata/a_txn_data03.dbf
39 full or incremental /u02/proddata/a_txn_data04.dbf
each time indicates this value after the rman full backup
Why and what is the solutionHello
What should be the database logging or NOLOGGING mode.
Not to be confused with Operation FORESTIERE/NOLOGGING/ARCHIVELOG NOARCHIVELOG.
A database may be in ARCHIVELOG mode and have Tables / Tablespaces using the NOLOGGING to allow unregistered operations.
A non-logged operation can improve performance in some cases (heavy,...), but should be used with caution. If you need to recover a database in which there were a non documented DML, some blocks may be marked as corrupted.
NOLOGGING mode must therefore be limited to Tables that you can re-create and reload easily. For example, the temporary Tables that does not store permanent data.
Otherwise, avoid using the NOLOGGING mode in database Production.
Please find attached a very interesting link on this topic:
http://asktom.Oracle.com/pls/Apex/f?p=100:11:0:P11_QUESTION_ID:5280714813869
Hope this helps.
Best regards
Jean Valentine -
Table of index between the limits
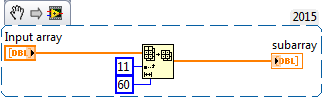
Hi all
I have a byte array that I need to extract information.
I need to extract 60 cells in the table, so using the index function to form a table under is not pretty (wiring in 60 constants). Is there another way to do this? i.e. to inex between limits?
Thank you
Richard.
You can use a subset of the table, where you need feed the starting index and length you need
-
Hi all
We have no limitation on the number of tables that can be created in the sqlite database.
In each table, what wouldn't be the maximum rows we can add... ?
as I have already said, you can have any number. lines and up to 2000 colums (according to the specifications of SQLite), but the limit is imposed on the size of the general datatbase, which is 512 KB in bb 5, 5 MB in bb 6.
SD is external memory no doubt, but DB size is limited by the fact that in time, we are opening connection db db all schema is loaded into RAM only, which is a limited resource.
Maybe you are looking for
-
First of all, I noticed that my send button disappeared. My thunderbird e-mail account is now entirely free tab no operation at all. How can I fix?
-
Help identify the Satellite Pro 2100 download driver
I have a Satellite Pro (marked below as a PS210E-00C3G-EN and a P4 2000/256/30 G, 15XT, CDW, LW). I think it's a satellite Pro 2100, whatever. Problem I have is that when it comes to downloading the drivers, I can't find anything approaching this mod
-
Start of Satellite L300-1 has 3 takes a lot of time
Dear Sirs I bought a laptop from 1 to 3 Satellite L300 there is little time and I noticed that it is too slow at startup. It takes sometimes more than any portable computer so that it starts. This model is like that, or it can be changed or may be do
-
printer hp deskjet advantage 5: Hp black ink 670
Hello I want to know if the black ink cartridge 670 hp would be able to work on my hp deskjet printer 5525 advantage or only the black ink cartridge 670xl who would be able to work.
-
HI, I just bought a T41 2373 7FU and can't do the adapter to power wireless Vista light is lit, but the software says that it is not on and I can't connect to anything I tried just use windows to manage the wireless, I also downloaded the driver from