regular expression: an integer in the range 0.100
What is the best regular expression to satisfy the need:(1) input string must be whole, the minimum value is 0, the maximum value is 100, no other symbols are allowed in the channel, no comma without a space.
The example data:
with T as
(select '-1' str from dual --not ok
union
select '0' str from dual --ok
union
select '1' str from dual --ok
union
select '100' str from dua --ok
union
select '1000' str from dual-- --not ok
union
select '101' str from dual --not ok
union
select '10.1' str from dual --not ok
union
select '10,1' str from dual --not ok
union
select 'a' str from dual --not ok)
select * from T
where regexp_like(str,'^[[:digit:]]{0,3}$');Hello
I think you hit the key to this solution; using regular expressions, it is better to make a special case of '100'.
You accept the numbers 1 and 2 digits that begin with '0'. would be unwise to accept 3 digit like '007' numbers, too?
Here's a regex solution that makes and also an inelegant way to achieve the same results without regular expressions:
SELECT ROWNUM
, str
, CASE
WHEN REGEXP_LIKE ( str
, '^' || -- Beginning of string
'(' || -- number, which is either
'(100)' || -- 100
'|' || -- or
'(0?' || -- optional leading 0
'\d{1,2})'|| -- 2 digits
')' || -- end number
'$' -- End of string
)
THEN 'Okay'
END AS regexp
, CASE
WHEN LENGTH (str) <= 3
AND TRANSLATE ( str
, 'X0123456789'
, 'X'
) IS NULL
AND LPAD ( str
, 3
, '0'
) <= '100'
THEN 'Okay'
END AS non_regexp
FROM t
;
Output:
ROWNUM STR REGE NON_
---------- ---- ---- ----
1 -1
2 0 Okay Okay
3 007 Okay Okay
4 08 Okay Okay
5 1 Okay Okay
6 10.1
7 100 Okay Okay
8 1000
9 101
10 999
11 a
12
I added these lines to the sample data:
union
select null str from dual
union
select '007' str from dual
union
select '08' str from dual
Tags: Database
Similar Questions
-
Regular expression as part of the page
Hello
I m doing a page using regular Expressions validation step, but my regular Expression is dynamic. I have another page element called VL_REGEXP where I put a value to the regular expression.
But when I write VL_REGEXP as a validation expression, he doesn´t the test condition. It tests only when I put the value of the regular expression.
So, what I would do to this dynamic Regular Expression for validation?
Example of my settings:
-Doesn´t work
Type of validation:
Point / 1 expression column matches a regular Expression in the Expression 2
Expression 1
P12_CD_ACCOUNT
Expression 2
P12_VL_REGEXP -that's what I need!
-It works
Type of validation:
Point / 1 expression column matches a regular Expression in the Expression 2
Expression 1
P12_CD_ACCOUNT
Expression 2
^ (\d\d\.\d\d\d\.\d)+$
Thank you
Bsalvador
Don't know if the required substitution treatment is supported in the validation expression, but if it is you need to reference the page element using the syntax of static text substitution:
Type of validation:
Point / 1 expression column matches a regular Expression in the Expression 2
Expression 1
P12_CD_ACCOUNT
Expression 2
& P12_VL_REGEXP.
-
regular expression to remove the zeros on the right
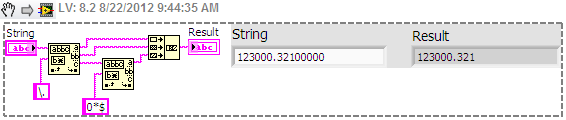
I need a regular expression to remove the zeros after the decimal point. I tried (?.)<=\.\d+?)0+(?=\D|$) but="" i="" get="" a="" error="" about="" look="" behind="" not="" a="" fixed="" length="" or="" something="" like="" that.="" i="" am="" not="" a="" regex="" expert="" and="" i="" was="" wondering="" just="" how="" to="" do="" this="" with="" regular="" expression="" or="" some="" other="">
Z.K. wrote:
[...] or some other way.
I tried and I tried but I couldn't crack with a regular expression, so I took the easy way. The first match found pattern the comma and the other removes the zeros to the right of the rest. It is not discriminate between numbers and all the rest, though.
-
The regular expression problem
Dear friends,
In my script I have some sections that test the contents of an edit field before it is processed further.
Perfectly things like the following:
var re_Def = /#[A-Za-z][A-Za-z0-9_]+/; // valid variable name ? items = ["#correct", "notcorrect", "#This_is4", "#thisIs", "@something", "#ALLOK", "", ]; // search 0 -1 -1!! -1!! -1 -1!! -1 <--- incorrect method // test true false true true false true false <--- correct method for (var j = 0; j < items.length; j++) { var item = items[j]; alert ("'" + item + "' ==> " + item.search(re_Def) + "\n" + re_Def.test(item)); } var re_Def = /(\[ROW +\d+\]|\[COL +\d+\]|\[CELL +\d+, +\d+\]|Left *\(\d*\)|Right *\(\d*\)|Above *\(\d*\)|Below *\(\d*\))/; items = ["[ROW 17]", "[Row n]", "[ROW n]", "[CELL 3, 9]", "[CELL 3 9]", "Abbove()", "Right(3)"]; // result true false false true false false true for (var j = 0; j < items.length; j++) { alert ("'" + items[j] + "' ==> " + re_Def.test(items[j])); }But what follows always returns false, independly of the content of the string element:
var re_Def = /{[EFJ]\d*}|{I}/; // valid format def? var item = "{E27}"; var result = re_Def.test(item); alert (result); // false !!RegEx buddy told me, that
-l' REGULAR expression is correct
-the result must be true, not false-The verbose definition of the RegEx is:
Match is the following regular expression (attempting the next alternative only if this one fails) "{\d* [EYF]}."
Match the character "{" literally "{}".
Match a single character present in the list "J" "[EYF]."
Match a single digit 0. 9 paper"\d*»
Between zero and unlimited times, as many times as possible, giving as needed (greedy) «*»
Match the character "}" literally "}".
Or match number 2 below (the entire match attempt fails if it cannot match) regular expression "{i}".
Match the characters "{i}" literally "{i}".Typo unrecognized? Test the faulty method?
Results are fake, as soon as I use the list of characters []] - but look at the first block of code: there are also lists of character they are treated properly.
The braces in the regular expression must be escaped to be taken literally:
var re_Def = /\{[EFJ]\d*\}/;Kind regards
JoH
-
Using the regular Expression of PL/SQL.
Has ' light, I'm braindead today and cannot understand this. I have data that may be in the following formats:
format 1:123 (A XXX)"
format 2:123 (A (XXX) Z)'
Formula 3:123 (A (XXX) Z) (B (YYY) Z)'
Looking for a regular expression that will analyze the data and return to:
result 1: "(un XXX)" "
result 2: "(un (XXX) Z)" "
result 3: "(un (XXX) Z)" "
Thanks for your help.Administer a shot:
SQL> WITH test_data AS 2 ( 3 SELECT '123 (A XXX)' AS TXT FROM DUAL UNION ALL 4 SELECT '123 (A (XXX) Z)' AS TXT FROM DUAL UNION ALL 5 SELECT '123 (A (XXX) Z)(B (YYY) Z)' AS TXT FROM DUAL 6 ) 7 SELECT REGEXP_SUBSTR 8 ( 9 TXT 10 , '\([[:alpha:]]{1} \(?[[:alpha:]]{3}\)? ?[[:alpha:]]?\)?' 11 ) AS NEW_TXT 12 FROM TEST_DATA 13 / NEW_TXT -------------------------- (A XXX) (A (XXX) Z) (A (XXX) Z)HTH!
-
regular expression - get the numbers from a string
Hello world
I'm trying to use regular expressions to get all the numbers in a string. The only problem is that the chain can vary.
For example:
It's my rope 3 and 8 I want 2 get out of those 7 numbers
Random text 9 with 5 for everyone weekend 8
How can I do?
Thanks in advance :)
Quote:
Posted by: Scott Stroz
#numbersOny #. Who will be only to crush all the numbers in a large number.
The attached code will return a nice list of numbers.
Though the numbers may contain commas or decimal points, the code can easily be adjusted -
Multiline - Regular Expression Match string
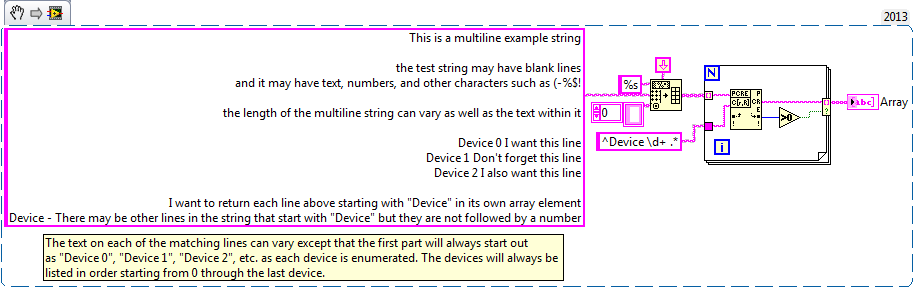
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
aaronb wrote:
I'm trying to understand the format of a regular expression to pull select off multi-line string lines and fill in these lines as the individual elements of an array of strings using regular expressions to Match. The total length of the multiline string may vary as well as the text in the string. The string can contain letters, numbers and special characters. I've attached an example VI. In the example of VI, I want to only return lines starting by "device #" in the table. The number of lines starting by "device #" can vary, but I want to capture them all.
Or is there a better functioning to be used instead of the corresponding regular Expression that will give me the desired result?
Corresponding regular expression works well for this.
Ben64
-
"Matches regular Expression" and "Model match" vi behaves differently
Hello
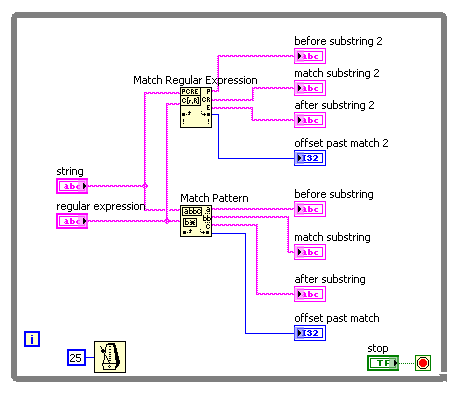
I need a simple matching chain and experimenting that found the "Regular Expression Match' and 'Correspondence model' vi behave a little differently. I guess that the entries of the regular expression on the two the same behavior. It's a difference that I discovered that the "|" character ("vertical" character, commonly used as an operator 'or') is recognized as such in the regex to Match vi, but not in the match vi model (where it is taken to the letter). Furthermore, I can't find any document using (online or in LabVIEW) on the ' | ' usage in regular expressions of character. Is - this documented anywhere?
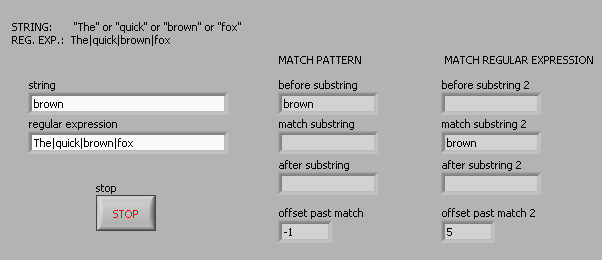
For example, suppose I want corresponding to one of the following 4 words: 'The' or 'fast' or 'brown' or 'fox '. The regular expression ' the | fast | Brown | Fox' (without the quotes) works for the vi Regular Expression Match but not the match pattern vi. Here is a photo of the block diagram and the results of the façade:
The Help explains that the vi Regular Expression Match performs a little more slowly the match vi pattern, so I started with the latter. But since he does not work for me, I'll use the old. But does anyone have an idea of the speed difference? I guess that's negligible in a simple example.
Thank you!

Thank you, Jeff. That's what I was looking for. BUT my version of LabVIEW 8.5, does NOT say "functionfor example, the Match model does not support the parenthesis or vertical bars (|) characters.«» !
See: http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_pattern/
and http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_regular_expression/
It is not mentioned in the help of special characters used for the match pattern : http://zone.ni.com/reference/en-XX/help/371361D-01/lvhowto/specialcharformatchpatt/
The only place | has 'talked', it is in the sentence: "some regular expressions that use alternating (such as (. |))". \s)*) require significant resources to deal with when it is applied to the large input strings. "But I'm not processing a large chain.
It seems that NEITHER fixed this omission. What version is your help?
Ed
-
regular expressions for numbers demical in a comma-delimited list
I have a table that lists the details of the occupation of the sites of a comma-delimited list:create table tenure_test)
number of site_number
tenure_detail varchar2 (255));insert into tenure_test values (1, ' Crown (Other) (0.15 ha), private (555.25 ha)');
insert into tenure_test values (2, ' private (5.76 ha)');
insert into tenure_test values (3, ' private (0.18 ha, Crown (3.25 hectares), Indeterminate (Leased) (5.85 ha)');)What I want to do is to use a regular expression to calculate the sum only numbers in the tenure_detail column.
For example, for site_number 1, it would be 0.15 + 555.25 = 555,4
I also have another regular expression that has just the numbers in a comma-delimited list.
For site_number 1: 0.15, 555.25
I tried this:
Select site_number, tenure_detail, regexp_substr (tenure_detail, "[0-9] + \.") ([0-9] {2}') under the name test1
of tenure_test;
but it lists only the first number.
Hello
996454 wrote:
I have a table that lists the details of the occupation of the sites of a comma-delimited list:
create table tenure_test)
number of site_number
tenure_detail varchar2 (255));insert into tenure_test values (1, ' Crown (Other) (0.15 ha), private (555.25 ha)');
insert into tenure_test values (2, ' private (5.76 ha)');
insert into tenure_test values (3, ' private (0.18 ha, Crown (3.25 hectares), Indeterminate (Leased) (5.85 ha)');)What I want to do is to use a regular expression to calculate the sum only numbers in the tenure_detail column.
For example, for site_number 1, it would be 0.15 + 555.25 = 555,4
I also have another regular expression that has just the numbers in a comma-delimited list.
For site_number 1: 0.15, 555.25
I tried this:
Select site_number, tenure_detail, regexp_substr (tenure_detail, "[0-9] + \.") ([0-9] {2}') under the name test1
of tenure_test;
but it lists only the first number.
Here's one way:
SELECT site_number
SUM (TO_NUMBER (REGEXP_SUBSTR (tenure_detail
, "\d+\.\d*" - see Note 1
) T
LEVEL
)
)
), Total
OF tenure_test
CONNECT BY LEVEL<= regexp_count="" (="">
, '\d+\.\d*'
)
AND PRIOR site_number = site_number
AND PRIOR SYS_GUID () IS NOT NULL
GROUP BY site_number
;
Output:
TOTAL OF SITE_NUMBER
----------- ----------
1 555,4
2 5.76
3 9.28
Note 1: what exactly makes a 'number '? I'm assuming it's 1 or more digits, followed by a comma, followed by 0 or more numbers. You can have a slightly different definition; in this case, change the arguments 2nd REGEXP_SUBSTR and REGEXP_COUNT.
I guess also that site_number is unique. If not, you will have to change the CONNECT BY and GROUP BY clauses, to refer to something (or a combination of things) which is unique.
Relational databases are designed for each column of each row contain 1 single piece of information, not a list delimited with a variable number of elements. It is so basic to the design of database he called the first normal form. If your first followed table form normal, this query (and many other queries that involve that table) would be much simpler to write, more efficient to run and less likely to have bugs. See if you can normalize this table. Any effort that you have to spend now to normalize the table will pay very quickly.
Thanks for posting the CREATE TABLE and INSERT statements; It is very useful.
Don't forget to tell what version of Oracle you are using. I tried the query in Oracle 11.2 above. You may need to CONNECT BY a little differently in earlier versions, and REGEXP_COUNT will not work in Oracle 10.
-
Regular expression - REGEXP_REPLACE
Hi all
I have a little problem with the regular expression. Look at the following example:
Don't pay attention to the regular expression I made. It is false.WITH T as (SELECT 'ABC' as a FROM dual UNION ALL SELECT 'ABC.Test' FROM DUAL UNION ALL SELECT 'XXX' FROM DUAL ) SELECT a, regexp_replace(a, '^(ABC)?(\.)?(.+)$','ABC.\3') FROM t
What I want is:
-When my channel start with anything other than ABC, it is replaced by the same chain with ABC. in front of it.
-When the string begins with ABC. something, nothing changes
-Once the ABC string (without the trailing dot) does not change the string.
No idea how I can do this by using regexp_replace? (I use Oracle 10 g)
Thank youodie_63 wrote:
Works very well except for the special cases 'AB' and 'A', which do not start with "ABC":You are right. In fact, even for Frank solution. In any case:
WITH T as (SELECT 'ABC' as a FROM dual UNION ALL SELECT 'ABC.Test' FROM DUAL UNION ALL SELECT 'ADC.Test' FROM DUAL UNION ALL SELECT 'ABD.Test' FROM DUAL UNION ALL SELECT 'XXX' FROM DUAL DUAL UNION ALL SELECT 'CCC.FOO' FROM DUAL UNION ALL SELECT 'A' FROM DUAL UNION ALL SELECT 'AB' FROM DUAL ) SELECT a, regexp_replace(a,'(^([^A]|A[^B]|AB[^C].*$)|^A$|^AB$)','ABC.\1') new_a FROM t / A NEW_A -------- -------------------- ABC ABC ABC.Test ABC.Test ADC.Test ABC.ADC.Test ABD.Test ABC.ABD.Test XXX ABC.XXX CCC.FOO ABC.CCC.FOO A ABC.A AB ABC.AB 8 rows selected. SQL>SY.
-
Indexing on search for regular expression for dynamic model
Hi all
Is it not possible to create an index for the regular expression search (REGEXP_LIKE) for the model 'dynamic '?
If the model is static, we can create FBI, but is it possible for dynamic diagrams? Please notify.
Kind regards
HariN °
The best option is an Oracle text index.
http://download.Oracle.com/docs/CD/E11882_01/text.112/e16594/TOC.htm -
Set-search-data-hiding-rule-prop-dn-regular-expressions setting targets
Hello. I'm trying to put in place a masking rule 6.3 DPS data. I want to have the data masking rule apply to any DN that ends with o = ny, c = us. I tried to adjust the target-dn-regular-expressions to ' o = ny, c = us$ '. I thought that if DPS used regular expression match, the $ at the end should serve as an anchor for this channel. But the rule is not fired. I proved it by assigning the expression regular votes to zero and then the target dns to exactly match the dn I'm back. Anyone know what I need to put in the phrase correspond to what I want? Thank youHello
Regular expressions must comply with the Java regular expression specificationa, available on [http://download.oracle.com/javase/6/docs/api/java/util/regex/Pattern.html]
For example, the regular expression (. *) c = us, o = ny filters out all o = ny, c = us tree.
Hope this helps
Sylvain
-
Hi guys,.
Let us say that I have given as ' Radha | Krishna | Sarma | 1. 2. I need a regular expression to replace all the pipes to the spaces, with the exception of those which has numbers on both sides. I tried a lot of things, but nothing seems to work.
I even tried to replace all direct to space first, then replace the space between the numbers to lead again.SQL> with t as 2 (select 'Radha|Krishna|Sarma|1|2' col 3 from dual 4 ) 5 select regexp_replace(col, '(\|)[^1-9]+\1', ' ') 6 from t 7 / REGEXP_RE --------- Radha 1|2 SQL> with t as 2 (select 'Radha|Krishna|Sarma|1|2' col 3 from dual 4 ) 5 select regexp_replace(col, '[1-9]+(\|)[1-9]+\1', ' ') 6 from t 7 / REGEXP_REPLACE(COL,'[1- ----------------------- Radha|Krishna|Sarma|1|2 SQL>
Please let me know if you have any solution.
See you soon
Sarma.Hi, Sarma,
You may need to do it in two steps: one to replace the hoses that come before everything except a number and another to replace the remaining tubes following anything except a number, like this:
REGEXP_REPLACE ( REGEXP_REPLACE ( col , '(\|)([^0-9]|$)' -- pipe, nondigit becomes ... , ' \1' -- space, nondigit ) , '([^0-9]|^)(\|)' -- nondigit, pipe becomes ... , '\1 ' -- nondigit, space )Sorry, I'm not a database now, so I can't test it.
-
It is possible to set the ranges of quantities?
I have this card, I put this ranges (300,350,400,450,500,550,600,650,700)
! http://img242.imageshack.us/img242/8468/rangosn.PNG!
I want to show the ranges by 100 (300,400,500,600,700)
I found in the documentary and I didn t find anything.
It's my code chart
chart:
< graphic depthAngle = "50" depthRadius = '8' pieDepth = "30" pieTilt = "20" seriesEffect = "SE_AUTO_GRADIENT" >
< LegendArea visible = "true" / >
< SeriesItems >
< series id = markerType '0' = "MT_BAR" color = "#eea16b" / >
< series id = '1' markerType = color "MT_BAR" = "#fae48f" / >
< series id = "2" markerType = "MT_MARKER" color = "#821616" lineStyle = "LS_SOLID" / >
< / SeriesItems >
< Y1ReferenceLine >
< ReferenceLine index = "0" visible = "true" lineWidth = '3' text = 'Media of Aragon' value = "500.0" displayedInLegend = "true" lineColor = "#ff11" / > < / Y1ReferenceLine >
< Y1Axis axisMinAutoScaled = "false" axisMinValue = "300" axisMaxAutoScaled = "false" axisMaxValue = "700" / >
"{((< LocalGridData colCount =" {count (xdoxslt:group (current - group (), ' Competencia))} "))}" rowCount = "2" >
.
.
.
< / LocalGridData > < / chart >
Thank youNow I understand
The values are hardcoded here, but you can reference your XML using max values and a feature tour
Tim
-
Using Regular Expressions in the Code of edge
Hello.
I am quite new to the Edge Code but find it quite interesting to use.
The find/replace feature is pretty but I got a little confused on how to use regular expression matching.
I tried to clean up the coordinates of a file Adobe Edge animate full of 120.17px (heavy and less accurate)
So basically you're looking \d+\.\d+px
First of all, she says "use /re/ for regex" even though I know the Code is made for developers who * courses * know that it took me a little time to understand I should just put my regex between slashes.
/\d+\.\d+PX/
then the time comes to replace them. ALT-cmd-F and it says "replace".
Puzzled again.
Will I type my full sentence there? Maybe a «...» "written up somewhere around would avoid this question because, there, of course, a second field to come.
And there, I got stuck.
I can not find how to get the replacement of the model.
tried to \1 $1 \1/ $1 / nothing seems to work... any hint of welcome.
Franck,
You are right that it does not work. I open a topic. Here is the link if you want to follow: https://github.com/adobe/brackets/issues/1861
FYI, I know exactly how you want to replace the search results, but here are a few tips:
You must set the text that you want to retrieve by using parentheses. Thus, for example, if you want the integer part of the number of the result, then your regexp would be: / (\d+)\.\d+px/
Then you must specify the first result using $1, so (when it's fixed), you can use something like: $1px
Thank you
Randy
Maybe you are looking for
-
Power surge and now the XBox will not turn on
We had a power surge, we blew a fuse, everything came back but the xbox. the remote flashes just all around, and the xbox does not turn on?
-
Installation of XP SP3 without internet availability.
I'm trying to install Xp service pack 3. The PC currently has service pack 0. I have no internet availability. Service Pack3 wants to install service pack 2 or service pack 1. How can I get the service pack 1 or 2 to install on the PC? I downloaded s
-
I got just my pc from vista to xp sp3... I have installed the audio driver realtek hd HD but no sound is coming... niether the audio icon in the bar spots... in the properties of the audio device (in the volume tab) is to show that no audio device...
-
Getting the Messenger - error 2203 and cannot uninstall or update
I have windows vista and installed messenger, but now I can't uninstall or update as it says: fatal error during installation. What should I do to uninstall or difficulty. PLS HELP!
-
Why my computer constantly goes into hibernation?
Hi all ~ Recently, I noticed that my computer goes into hibernation by itself when not used for a period of time. I confirmed that my power settings dictate this behavior so that plugged in or on battery power. Instances that I noticed this, mainly,