Regular expression pattern
Hi Experts,
I get a SQL in a table is of type CLOB. At the end of the sql statement look like below.
AND SUBSTR (NLS_LOWER (GCT. AVGROUPCODE), 1, 51) = SUBSTR (NLS_LOWER (CST. AVGROUPCODE), 1: 51)
AND SUBSTR (NLS_LOWER (GCT. DATAAREAID), 1, 7) = SUBSTR (NLS_LOWER (CST. DATAAREAID), 1, 7)
AND SUBSTR (NLS_LOWER (AVL. TO_MEMBERID), 1: 25) =? P_TO_NUM?
)
WHERE ODULSATIS > =? P_LIMIT?
ORDER BY ODULSATIS DESC
As you can see, I want to replace NULL for ' WHERE ODULSATIS > =? P_LIMIT? ' * NEW LINE * ORDER BY ODULSATIS DESC '. I try to catch him by regular expression, but I can't. I find the new symbol of the regex line.
l_sql : = regexp_replace (replace (replace (l_sql "(OÙ ODULSATIS > = \?)"))) P_LIMIT\?) (ORDER BY ODULSATIS DESC) \n', " " );
Kind regards.
Hi try it below:
l_sql: = regexp_replace (l_sql, ' (WHERE. * | chr (10) |)) (Order.*)');
(Or for exact string)
l_sql: = regexp_replace (l_sql, "(OÙ ODULSATIS > =?)") P_LIMIT? Chr (10) | (ORDER BY ODULSATIS DESC)');
SAMPLE DATA:
WITH T (STR) AS
(SELECT"
AND SUBSTR (NLS_LOWER (GCT. AVGROUPCODE), 1, 51) = SUBSTR (NLS_LOWER (CST. AVGROUPCODE), 1: 51)
AND SUBSTR (NLS_LOWER (GCT. DATAAREAID), 1, 7) = SUBSTR (NLS_LOWER (CST. DATAAREAID), 1, 7)
AND SUBSTR (NLS_LOWER (AVL. TO_MEMBERID), 1: 25) =? P_TO_NUM?
)
WHERE ODULSATIS > =? P_LIMIT?
ORDER BY ODULSATIS DESC' DOUBLE)
SELECT REGEXP_REPLACE (STR,'(WHERE. * | chr (10) |)) ORDER.*) ") T;"
OUTPUT:
STR
--------------------------------------------------------------------------------AND SUBSTR (NLS_LOWER (GCT. AVGROUPCODE), 1, 51) = SUBSTR (NLS_LOWER (CST. AVGROUPCODE),
1.51)
AND SUBSTR (NLS_LOWER (GCT. DATAAREAID), 1, 7) = SUBSTR (NLS_LOWER (CST. DATAAR
SAID), 1, 7)
AND SUBSTR (NLS_LOWER (AVL. TO_MEMBERID), 1: 25) =? P_TO_NUM?
)
Tags: Database
Similar Questions
-
Validation of regular expression delimiter alphanumeric and hose
I have a header in the file as below
EMP_ID | EMP_NAME | DEPARTMENT | SALARY | ACTIVE1
past to a string
String test = ' EMP_ID | EMP_NAME | DEPARTMENT | SALARY | ACTIVE1;
I need to check if the header is only of alphanumeric characters and pipedelimiter is allowed.
other than these, I need to trigger an error.
Any suggestions.
had the regular expression pattern
It's the string pattern = "^ ([a-zA-Z0-9 |]) '. +)$";
-
How can I refer to a variable in the regular expression
Hello friends,
I have this Regexp, extract the County code: (971)
Select regexp_replace (regexp_replace ('05-000971 7910-324324', '\D'),'^ 0 * (971)? 0?') of double;
It is very good and the need...
But, thinking about the future, someone may need to remove the country code (961), so it is better if I put the code in a variable, but
How can I list the County code via a variable since the Regexp:
but it does not work?declare a varchar2 (15); code number := 971; begin select regexp_replace(regexp_replace('000971 05 7910 - 324324','\D'),'^0*(code)?0?') into a from dual; dbms_output.put_line ( a); end;
Best regards
FatehYou must link the value of the variable code in the regular expression pattern
select regexp_replace(regexp_replace('000971 05 7910 - 324324','\D'),'^0*('||code||')?0?') into a from dual -
I know by logic box to get the output using the regular expression?
Hello
I am now only study the notion of Regexp. I had seen the best of Mr. Blus. Can I know how it works. I need this logic of the functionality of wildcards in sting matching Regexp (wildcard string Matching).
Please help me in this matter.SQL> ed Wrote file afiedt.buf 1 WITH test_data AS ( 2 SELECT 'c:\temp\folderA\fileA.txt' t FROM DUAL UNION ALL 3 SELECT 'c:\temp\fileA.txt' t FROM DUAL UNION ALL 4 SELECT '\\mymachine\A\fileB.txt' t FROM DUAL UNION ALL 5 SELECT '\\mymachine\A\B\fileB.txt' t FROM DUAL UNION ALL 6 SELECT '\\mymachine\A\B\C\image.jpg' t FROM DUAL UNION ALL 7 SELECT '\\mymachine\A\B\C\D\music.mpg' t FROM DUAL UNION ALL 8 SELECT 'c:\myfolder\folderD\folderE\4969-A.txt' t FROM DUAL 9 ) 10 select regexp_replace(t, '^.*[\]([^\]*)[\][^\]*$','\1') 11* from test_data SQL> / REGEXP_REPLACE(T,'^.*[\]([^\]*)[\][^\]*$','\1') ------------------------------------------------------------------ folderA temp A B C D folderE 7 rows selected. SQL>
IqbalSabrina wrote:
One last question what is the average ofThe final "\1" in
select regexp_replace(t, '^.*[\]([^\]*)[\][^\]*$','\1')Iqbal
It is a reference.
See here:
http://download.Oracle.com/docs/CD/B19306_01/AppDev.102/b14251/adfns_regexp.htm#CHDHCIGHand in the middle of the table here:
http://download.Oracle.com/docs/CD/B19306_01/AppDev.102/b14251/adfns_regexp.htm#CHDIEGEIMatches the nth previous subexpression, in other words, either grouped in parentheses, where n is an integer between 1 and 9. The parentheses cause > an expression be remembered; a backreference refers to him. A backreference account subexpressions from left to right, starting with the opening > bracket of each subexpression preceding. The expression is not valid if the source string contains less than n subexpressions preceding the \n.
Oracle supports the expression of backreference in the regular expression pattern and the replacement of the REGEXP_REPLACE function string.
The expression (abc: def) matches the strings abcxyabc and defxydef xy\1, but does not abcxydef or abcxy.A backreference allows you to search for a string repeated without knowing the actual string advance. For example, the expression ^(.*) \1$ > matches a line consisting of two adjacent instances of the same string.
As explained in table 4-2, backreferences store sub-expressions matched in a temporary buffer, which allows to reposition the characters. You access the pads with the notation \n, where \n is a number between 1 and 9. Each subexpression brackets and is numbered from left to right.
-
Regular expression matching is not what matches Pattern
I read a lot of posts on how match model does not match what match regular expressions will be due some characters does not.
However, I found a problem with the other way. A simple Reg - Ex who works in the match pattern but not regular Expression match.
What I have here is just an example. I want to use regular Expression Match then I can specify some matches under.
The reg - ex's: one or more non-numeric characters, a space, one or more numeric characters. At the beginning of the string.
How can I get this to work in regular expression matching? I work in LabVIEW 2010f2 32 bit. Here is the code snippet and the results:
Rob
One of the subtle differences is the operator of negation for the character classes. In match pattern is ~, but for the Match RegEx is ^.
-
pattern by using regular expressions match
I'm playing (and wrong) with regular expressions
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + > ') twice;
give < PSN > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.2 ') twice;
give < 231 > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.3 ') twice;
give < ABc > which confused me until I realized that < 3 25 > has not been matched, because it has a space inside
so I changed it to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ', 1.3) twice;
who gave a syntax error, so I changed it again to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ') twice;
that works, but gives < PSN > / # < 231 > # < 3 25 3 > / < ABc >
I guess because the. * corresponds to anyting that all but the last closure >
The question I have is how can I retrieve the text of mounting bracket included (even if it has multiple spaces)?
Hello
9c5dfde3-EAAE-45A7-80a1-bba8a71c826c wrote:
Thanks for that - is there a way to return all 4 surrounded by extracts of <> without resorting to PL/SQL?
Of course;
REGEXP_REPLACE (str
, '(^|>)[^<>
, '\1'
)
Returns a copy of str with all outside rafters removed, for example
<231><3 25=""> . It doesn't matter how many pairs of sharp hooks - there is.
-
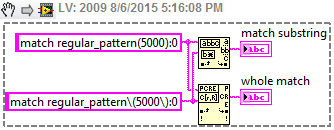
Use matching of regular expressions to search for parentheses
Hi all
I am currently looking for a particular pattern in a string, I can't display the exact string, but say its something like that. corresponds to regular_pattern (5000): 0
I'm also looking for the a different model at the same time, so I have to use the corresponding regular expression and the | function. I can't understand how to match this model because the regular expression function allows parentheses unless I put them in the legs, and that does not help me for this.
Any advice?
Thank you
Matt
Have you tried to escape the bracket?
-
regular expression for something that does not have a fixed sequence
Hello
Just having a little trouble with a regular expression. I have an input string and I want to find something that is not this string, so
Input = Hello
Match = Hello
Football game? = False
Entry = Hello1
Match = Hello
Football game? = False
Input = Hello
Match = goodbye
Football game? = True
As I thought that I understood it, to enter as a regular expression in the regular Expression.vi of Match would be ~ (Hello).
If I understand as well, I can't do this by using the match pattern.
Maybe you good people can correct me. Thank you!
-
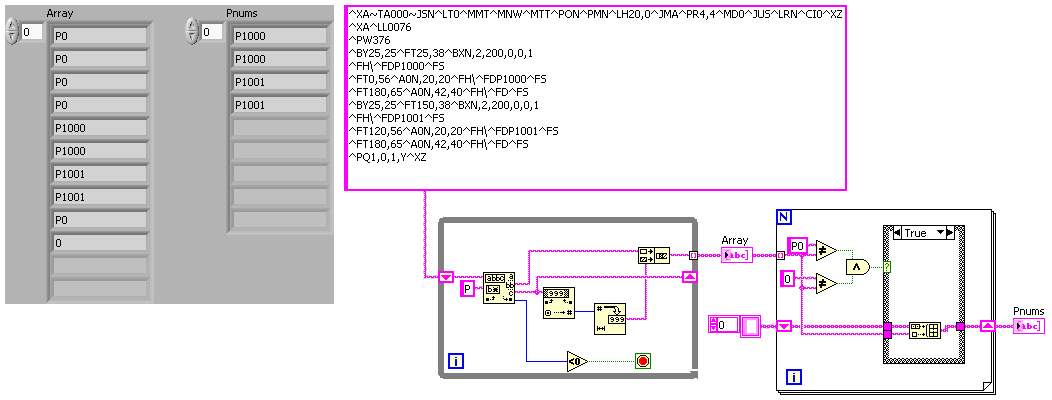
Hello
I have a string I want to use a regular expression to avoid a cascade of matching patterns, but I can't seem to make it work.
The string:
^ XA ~ TA000 ~ JSN ^ LT0 ^ TEM ^ MNW ^ MTT ^ PON ^ PMN ^ LH20, 0 ^ JMA ^ PR4, 4 ^ MD0 ^ JUICE ^ LRN ^ CI0 ^ XZ
^ XA ^ LL0076
^ PW376
^ 25, 25 ^ FT25, 38 ^ BXN, 2, 200, 0, 0, 1
^ FH\ ^ FDP1000 ^ FS
↑ FT0, 56 ^ A0N, 20, 20 ^ FH\ ^ FDP1000 ^ FS
^ FT180, 65 ^ A0N, 42, 40 ^ FH\ ^ FD ^ FS
^ 25, 25 ^ FT150, 38 ^ BXN, 2, 200, 0, 0, 1
^ FH\ ^ FDP1001 ^ FS
↑ FT120, 56 ^ A0N, 20, 20 ^ FH\ ^ FDP1001 ^ FS
^ FT180, 65 ^ A0N, 42, 40 ^ FH\ ^ FD ^ FS
↑ PQ1, 0, 1, O ^ XZI want to get out there is one instance of:
P1000
P1001
In this example. The numbered part will be different for the other channels, like P4567, PA34554, etc. He will never vary from P or PA. The section number can be 4 or 5 digits.
Each of these appear twice in the chain.
The regular expression, I tried to use is:
\^FD*\^FS
and then I was going to eliminate duplicates.
And now my brain doesn't give up.

Tay
This vi retrieves all P followed by numeric characters. You need to change to include AP
-
Search for a string using "Game Plan" or "Regular Expression to Match."
Hello
I would use the 'game plan' or the vi "Expression regular game" simply because the products that provide these vi. The result that interests me is the substring 'after '. I want to be able to specify a "substring" and get everything after the substring of the input string. However, I'm getting all confused and/or watered upward when it comes to "regular expressions". Is there a way to create a "regular expression" which acts as a 'substring' to find within the input string?
The substring is a path of partial directory that contains a colon, backslashes, etc. which are part of a directory path. If some how the "regular expression" entry must ingnore all special characters and simply to understand if the substring in the string entry and give me 'all things' after the substring in the output of 'after the string.
Use Regular Expression Match instead of match pattern; It's better.
-
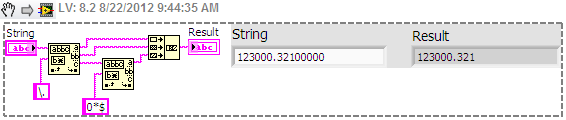
regular expression to remove the zeros on the right
I need a regular expression to remove the zeros after the decimal point. I tried (?.)<=\.\d+?)0+(?=\D|$) but="" i="" get="" a="" error="" about="" look="" behind="" not="" a="" fixed="" length="" or="" something="" like="" that.="" i="" am="" not="" a="" regex="" expert="" and="" i="" was="" wondering="" just="" how="" to="" do="" this="" with="" regular="" expression="" or="" some="" other="">
Z.K. wrote:
[...] or some other way.
I tried and I tried but I couldn't crack with a regular expression, so I took the easy way. The first match found pattern the comma and the other removes the zeros to the right of the rest. It is not discriminate between numbers and all the rest, though.
-
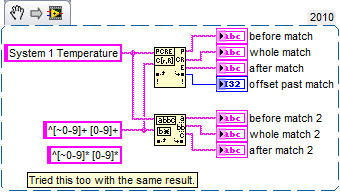
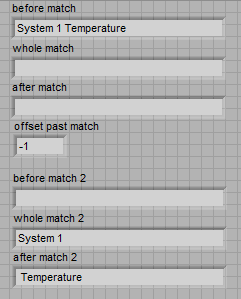
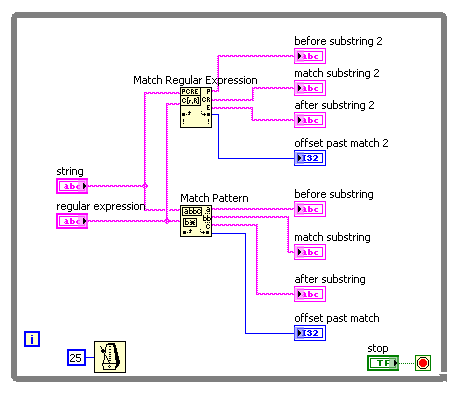
"Matches regular Expression" and "Model match" vi behaves differently
Hello
I need a simple matching chain and experimenting that found the "Regular Expression Match' and 'Correspondence model' vi behave a little differently. I guess that the entries of the regular expression on the two the same behavior. It's a difference that I discovered that the "|" character ("vertical" character, commonly used as an operator 'or') is recognized as such in the regex to Match vi, but not in the match vi model (where it is taken to the letter). Furthermore, I can't find any document using (online or in LabVIEW) on the ' | ' usage in regular expressions of character. Is - this documented anywhere?
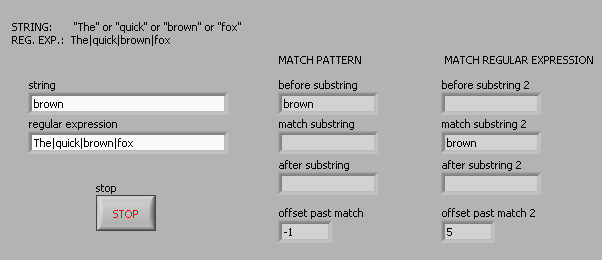
For example, suppose I want corresponding to one of the following 4 words: 'The' or 'fast' or 'brown' or 'fox '. The regular expression ' the | fast | Brown | Fox' (without the quotes) works for the vi Regular Expression Match but not the match pattern vi. Here is a photo of the block diagram and the results of the façade:
The Help explains that the vi Regular Expression Match performs a little more slowly the match vi pattern, so I started with the latter. But since he does not work for me, I'll use the old. But does anyone have an idea of the speed difference? I guess that's negligible in a simple example.
Thank you!

Thank you, Jeff. That's what I was looking for. BUT my version of LabVIEW 8.5, does NOT say "functionfor example, the Match model does not support the parenthesis or vertical bars (|) characters.«» !
See: http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_pattern/
and http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_regular_expression/
It is not mentioned in the help of special characters used for the match pattern : http://zone.ni.com/reference/en-XX/help/371361D-01/lvhowto/specialcharformatchpatt/
The only place | has 'talked', it is in the sentence: "some regular expressions that use alternating (such as (. |))". \s)*) require significant resources to deal with when it is applied to the large input strings. "But I'm not processing a large chain.
It seems that NEITHER fixed this omission. What version is your help?
Ed
-
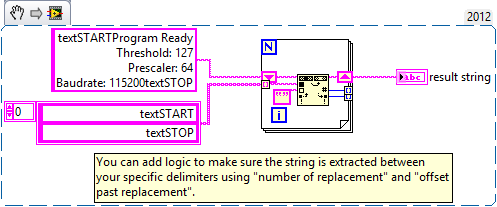
Regular expression for middle of string
Little background. I get the data (only the numbers) and text (can contain numbers) series. Since I don't know which I get and when it starts / ends, I do the sender send 'textSTART ###textSTOP' where ' # ' is what I want to extract. # can contain text, numbers, new line, carriage return or whatever.
The same for the data : "dataSTART ###dataSTOP", where # contains only numbers.
I think I should use the match pattern, but I don't know how to make my regular expression.
Any help is appreciated.
There are many solutions if you want to only extract the string between your specific delimiters. Here's a solution:
-
Regular Expressions do not work
With the help of sensors 4.X, VMS2.2
It seems that the normal regualar expressions are not accepted as valid by CiscoWorks. Example:
If I wanted to match for "Red Duck", but the number of spaces between each letter had to be 0-5 I would use spaces:
[R] {0-5} e [] {0-5} [d] {0-5} D {0-5} [] u] {0-5} [c] {0-5} k [] {0-5}
That the expression would be: R e d D uc k, Red D u c k and similar.
Why they are not allowed in String.TCP?
SO the question is, WHERE can find a list of regular expressions ACCEPTED, that works with sensors 4.X. I found a list that works with 3.X sensors... it did not work at all. Here, any help would be great.
Eric
Duck of red in google returns as red + duck in Google. Space will be replaced by a plus (+) sign or % 20 as it goes over HTTP (the browser for this).
The regular expression must be (including breaks):
[Rr] [+] * [Ee] [+] * [JJ] [+] * [JJ] [+] * [Uu] [+] * [Cc] [+] * [Kk]
You can't repeat a pattern of three characters like [%] 20.
-
Regular expression for invalid number
Hello world
I use version oracle as follows:
SQL > select * from v version $;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - production
PL/SQL Release 10.2.0.4.0 - Production
CORE 10.2.0.4.0 Production
AMT for 32-bit Windows: release 10.2.0.4.0 - Production
NLSRTL Version 10.2.0.4.0 - Production------------------------------------------------------------------------
I use a regular expression to replace invalid values in a table.
I got oracle error 'ORA-01722 invalid number '.
My query looks like this:
SELECT DISTINCT
MRC_KEY,
PURPOSE_CD,
RESIDENCE_DESC,
TO_NUMBER (regexp_replace (ICAP_GEN_MADAPTIVE, "..?")) 0? 0? (\d+) [-.] ((?', '\1')) as ICAP_GEN_MADAPTIVE,
Of
MRRC_INT
I don't know what are invalid values in the table, so I can write regexp accordingly.
Any guidance is appreciated!
Thanks in advance
J
Hello
Whenever you have a problem, please post a small example of data (CREATE TABLE and only relevant columns, INSERT statements) for all of the tables involved and also publish outcomes from these data.
Explain, using specific examples, how you get these results from these data. View of the code which is not what you want can be useful, but there niot enough by itself.
See the FAQ forum: https://forums.oracle.com/message/9362002Let's look at what you do:
REGEXP_REPLACE (icap_gen_madaptive
, '[+. ]' || -exactly 1 of these characters
'?0?0?' || -up to 2 ' 0 '
'(\d+)' || -some numbers (it comes to \1)
'[-.]?' -0 or 1 of these characters
, '\1'
)
Is it really what you want? A group of figures don't match, as the patten must start with a sign more, a point or a space. You want to allow a decimal point at the beginning and at the end, as in "." 9. '? If there are numbers before and after the decimal point, as in "1.2", you want only the digints before the comma? You never said what you want, but I'm guessing that these are things that you don't want.
If the pattern is found, this changes only the schema, so a string like "FU + 123 BAR" more than the model + 9 "" changed to "9" and the resulting string. "" "" FU9BAR"would be passed TO_NUMBER.
If the pattern is not found, as in "FOO", nothing is changed, and the entire string is passed to TO_NUMBER.
I suspect you want to use instead of REGEXP_REPLACE REGEXP_SUBSTR, or, if there is stuff to ignore before and/or after the number you want to include in the model, so that REGEXP_REPLACE will be replaced by nothing.
This looks like a good argument to use the NUMBER of columns to store numbers.

Maybe you are looking for
-
I always found the hypothesis iTunes to sort on "Album Artisit' rather than 'Artist' to be incongruos. If "Album Artist" is empty, as is likely (and is the historic norm than iTunes 7, I believe, when 'Artist album' for the first time), then sorting
-
Re: Where can I get preinstalled software?
After replacing the drive HARD defective (service) allowed, I have no software - emty HDD. Where can I get software (including Windows 7 and TOSHIBA utilities) preinstaled? THX
-
When I use Windows Defender or secruity of microsoft databases or more all secruity, I get an error message. try using microsoft s e., I get an error message 0 x 8007005. Please help.just get into computers.
-
MSKB article delete C:\Windows.Old?
Can someone point me in the direction of an article (with the number) in the MSKB which tells you how to remove the C:\Windows.Old folder with a command prompt? This is for a school project. I searched the MSKB and can't seem to find anything that te
-
Silverlight won't allow me to check
try watching netflex tells me to install silverlight whenever I have it try said unable already have this version