Simple regular expression
Hello
I need a simple check to validate if a string contains only letters and numbers.
The regular expression to test this should be
[A Za-z0-9]
or, to check out the entire string to start ebd
^ [A Za-z0-9] $
Now it is refined and the return match to search a string for the given expressions.
The first expression matches any character, anywhere in the string.
The second expression is not at all (although using regex validator test online).
How to do this correctly for my goal, namely, to validate if a string contains only letters and numbers.
Thank you!
I would like to know what regex testers online you used as the second regex actually worked for your needs. So I know to avoid them because they don't work well.
Your two regexes only to a single character. Then a second will match only one character alphanumeric strings. Want to make a game of several character, with a ' + '.
--
Adam
Tags: ColdFusion
Similar Questions
-
Need help with a simple regular expression replacement
Hello everyone,
He comes to the table that I have to work with.
My select statement isCREATE TABLE "TBL_ACCOMMODATION" ("ACCOMMODATION_ID" NUMBER, "HOTEL_NAME" VARCHAR2(100), "ADDRESS" VARCHAR2(200), "LOCATION" VARCHAR2(100), "PHONE" VARCHAR2(50), "EMAIL_ADDRESS" VARCHAR2(60), "CONTACT_PERSON" VARCHAR2(60), "STATUS" CHAR(1), "CREATED_BY" VARCHAR2(10), "CREATED_DATE" DATE, "MODIFIED_BY" VARCHAR2(10), "MODIFIED_DATE" DATE, "MOBILE" VARCHAR2(50)) REM INSERTING into TBL_ACCOMMODATION Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (147,'Testt','Auckalnd','Henderson','565756776','[email protected]','Jasmine','A',null,null,'JEEJJ',to_date('23/10/12','DD/MM/RR'),null); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (129,'Kirby Hotel','25A Aitken Street Wellington','Wellington','04 918 8513','[email protected]','Deahdoow Maharg','A',null,null,'LEAN',to_date('14/02/13','DD/MM/RR'),'027 356 4333'); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (167,'Avenue ee','10 Wellington Street Wellington','Wellington','4444444','[email protected]','James','A',null,null,'LEAN',to_date('21/02/13','DD/MM/RR'),null); Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (185,'Quadrant Hotel','10 Waterloo Quadrant, Auckland','Auckland','9555555','[email protected]','Quentin QQ','A',null,null,'LEAN',to_date('04/03/13','DD/MM/RR'),null);
I have to use the function replace twice. One is to replace the Chr (13) a comma is second band a comma where there are two commas.SELECT acc.hotel_name || '(' || replace(replace(acc.address,chr(13),', '),',,',',') || ')' FROM TBL_ACCOMMODATION acc inner join ijs_seminar s ON acc.accommodation_id = s.accommodation_id where s.seminar_id = :P27_SEMINAR_ID
I don't know much about regular expressions.
If someone can show me a better way to handle this using the regular expression rather than a heavy means above.
Thanks in advance
AnnHi, Ann.
Ann586341 wrote:
Hello everyone,He comes to the table that I have to work with.
CREATE TABLE "TBL_ACCOMMODATION" ("ACCOMMODATION_ID" NUMBER, "HOTEL_NAME" VARCHAR2(100), "ADDRESS" VARCHAR2(200), "LOCATION" VARCHAR2(100), "PHONE" VARCHAR2(50), "EMAIL_ADDRESS" VARCHAR2(60), "CONTACT_PERSON" VARCHAR2(60), "STATUS" CHAR(1), "CREATED_BY" VARCHAR2(10), "CREATED_DATE" DATE, "MODIFIED_BY" VARCHAR2(10), "MODIFIED_DATE" DATE, "MOBILE" VARCHAR2(50)) REM INSERTING into TBL_ACCOMMODATION Insert into TBL_ACCOMMODATION (ACCOMMODATION_ID,HOTEL_NAME,ADDRESS,LOCATION,PHONE,EMAIL_ADDRESS,CONTACT_PERSON,STATUS,CREATED_BY,CREATED_DATE,MODIFIED_BY,MODIFIED_DATE,MOBILE) values (147,'Testt','Auckalnd','Henderson','565756776','[email protected]','Jasmine','A',null,null,'JEEJJ',to_date('23/10/12','DD/MM/RR'),null); ...Thanks for posting the sample data. You post the results, but the validation of the existing query which I suppose, produced good results. I can't run this query, because it requires the ijs_seminar table and a connection variable that also has no post, but I can just comment on the join and the WHERE clause.
Is this really the best set of sample data for this question? This problem involves Chr (13) and repeated commas, but I don't see any s CHR (13) or repeated commas in the sample data. In addition, it seems that there are a lot of columns that play no role in this issue and just to make things difficult to read.
My select statement is
SELECT acc.hotel_name || '(' || replace(replace(acc.address,chr(13),', '),',,',',') || ')' FROM TBL_ACCOMMODATION acc inner join ijs_seminar s ON acc.accommodation_id = s.accommodation_id where s.seminar_id = :P27_SEMINAR_IDI have to use the function replace twice. We need to replace the Chr (13) by a comma,.
As posted, inside REPLACE replaces Chr (13) with a comma and a space which could be important if you then pick up consecutive commas.
second is the band a comma where there are two commas.
I don't know much about regular expressions.
If someone can show me a better way to handle this using the regular expression rather than a heavy means above.Assuming you want to replace Chr (13) with just a comma, then an equivalent would be:
SELECT acc.hotel_name || '(' || REGEXP_REPLACE ( acc.address , '[,' || CHR (13) || ']{1,2}' , ',' ) || ')' AS h FROM tbl_accommodation acc INNER JOIN ijs_seminar s ON acc.accommodation_id = s.accommodation_id WHERE s.seminar_id = :P27_SEMINAR_ID ;In the argument to REGEXP_REPLACE 2nd
[xy]{1,2}medium 1 to 2 characters of set of x and y. This could be
x or
there or it could be 2 characters
XY or the other way
YX or it could be the same characters 2
XX or
YYREGEXP_REPLACE is slower that REPLACE. Even if your original expression is longer, it may be more effective. (Performance may be not a problem in this case.)
-
the simple regular expression problem
Hello
I need assistance with regular expressions. I have a situation when I need to get data from one table to the other and I think that my problem can be solved using REG EXP, but I don't know how to use them properly.
I need to separate fileld varchar2 which is basically number/number in 2 separate number fields
I need to get the code in the co and po columns. I think the result should look something like this, but:CREATE TABLE tst (CODE VARCHAR2(10)); INSERT INTO tst VALUES('10/15'); INSERT INTO tst VALUES('13/12'); INSERT INTO tst VALUES('30'); INSERT INTO tst VALUES('15'); CREATE TABLE tst2 (po NUMBER, co NUMBER);
Any help appreciatedINSERT INTO tst2 SELECT regexp_substr(CODE 'something here to get the number before /') AS po, regexpr_substr(CODE 'something here to get number after') AS co FROM tst;Agree with the above,
However, if you really want to know how to do with regular expressions you can do it like this...
SQL> select regexp_substr('10/15','[^/]+',1,1) from dual; RE -- 10 SQL> select regexp_substr('10/15','[^/]+',1,2) from dual; RE -- 15 -
Hi all!
I am in need of a simple regular Expression for a validation of the APEX
I need a regular expression that validates the content of a variable is in the following form: 2 052 001
My validation is:
^ ([[: digit:]] + |) [[: digit:]] {1,3} (?: \,[[:digit:]]{3})+)$ but the validation does not work, but it works correctly javascript)
Help me!!
Any ideas?
Thank you!
I deleted the expression (?: \) and worked properly.
^ ([[: digit:]] + |) [[: digit:]] {1,3} (, [[:digit:]]{3}) +]]) $
Thank you!!
-
regular expression does not run DURATION
Hello adobe colleague,.
I am currently stumbling on a strange question about javascript to compress a string:
main function to compress any string, remove all non-alphabetiques characters and making the string lowercase
function compressString (input) {}
Patt var = new RegExp ("\\W","g");
Patt.Compile (Patt);
out of var = input.toLowerCase ().replace(patt,"") + "YES";
return output;
}
Somehow this code runs perfectly while only viewable in adobe creative 9.0.0.2 but DURATION all javascript runs with the exception of the above party.
I know that this part is executed because in the result, I see the string "YES" added to the response of this function.
Somehow the model is not compiled or executed DURATION...
I also tried several simple regular expressions but none of them actually worked.
For models that the client option is defined where them run javascript, although while testing options to resolve the issue is also tried both and the server. None provided the solution.
Can anyone provide any help... it is appreciated!
Thank you
Marcel
Hello
You can make your simple function.
function compressString (input) {}
(Return input.toLowerCase().replace(/\W/g,"") + "YESS"; "
}
-
According to the link below, TS supports regular expressions. Can anyone provide an example where to write regular expressions?
I might be easier to do via a plug-in of .net, but TS permitting, I might go with it.
http://zone.NI.com/reference/en-XX/help/370052N-01/tsref/infotopics/find_regular_expressions/
Hello
Yes, there is a member of the PropertyObject.Search, but the result is search results, so I wonder how to use in the execution sequence?
What a simple solution using only 4 lines in Exression statement to realize this split and trim?
Concerning
Jürgen
-
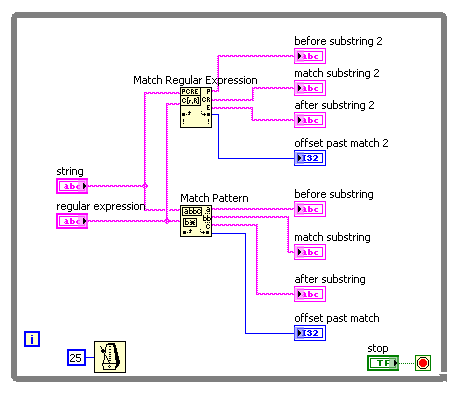
"Matches regular Expression" and "Model match" vi behaves differently
Hello
I need a simple matching chain and experimenting that found the "Regular Expression Match' and 'Correspondence model' vi behave a little differently. I guess that the entries of the regular expression on the two the same behavior. It's a difference that I discovered that the "|" character ("vertical" character, commonly used as an operator 'or') is recognized as such in the regex to Match vi, but not in the match vi model (where it is taken to the letter). Furthermore, I can't find any document using (online or in LabVIEW) on the ' | ' usage in regular expressions of character. Is - this documented anywhere?
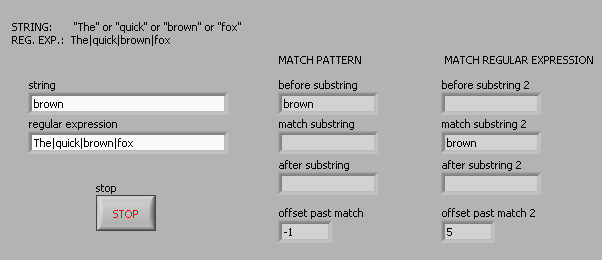
For example, suppose I want corresponding to one of the following 4 words: 'The' or 'fast' or 'brown' or 'fox '. The regular expression ' the | fast | Brown | Fox' (without the quotes) works for the vi Regular Expression Match but not the match pattern vi. Here is a photo of the block diagram and the results of the façade:
The Help explains that the vi Regular Expression Match performs a little more slowly the match vi pattern, so I started with the latter. But since he does not work for me, I'll use the old. But does anyone have an idea of the speed difference? I guess that's negligible in a simple example.
Thank you!

Thank you, Jeff. That's what I was looking for. BUT my version of LabVIEW 8.5, does NOT say "functionfor example, the Match model does not support the parenthesis or vertical bars (|) characters.«» !
See: http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_pattern/
and http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_regular_expression/
It is not mentioned in the help of special characters used for the match pattern : http://zone.ni.com/reference/en-XX/help/371361D-01/lvhowto/specialcharformatchpatt/
The only place | has 'talked', it is in the sentence: "some regular expressions that use alternating (such as (. |))". \s)*) require significant resources to deal with when it is applied to the large input strings. "But I'm not processing a large chain.
It seems that NEITHER fixed this omission. What version is your help?
Ed
-
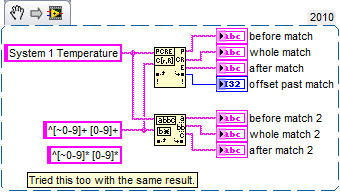
Regular expression matching is not what matches Pattern
I read a lot of posts on how match model does not match what match regular expressions will be due some characters does not.
However, I found a problem with the other way. A simple Reg - Ex who works in the match pattern but not regular Expression match.
What I have here is just an example. I want to use regular Expression Match then I can specify some matches under.
The reg - ex's: one or more non-numeric characters, a space, one or more numeric characters. At the beginning of the string.
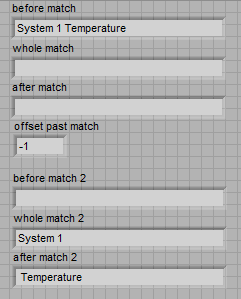
How can I get this to work in regular expression matching? I work in LabVIEW 2010f2 32 bit. Here is the code snippet and the results:
Rob
One of the subtle differences is the operator of negation for the character classes. In match pattern is ~, but for the Match RegEx is ^.
-
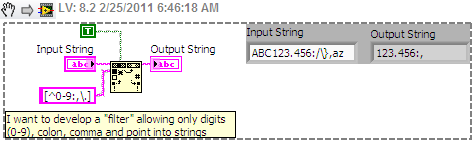
Allow specific characters - Regular Expression
Hello everyone
I am new to the regular expression and I have a very simple question. I use the function "read from the text file" to load a file delimited by tabs with 3 columns in my VI. Then, the string is converted to table and I use the values.
Nevertheless, I would like to develop a "filter" that allows only digits (0-9), colon, comma , and point to strings.
Using the function "matches regular expression", I tried a regular expression like this:
[^ 0-9] | [^\]. [|^:]| [^,]
But it does not work.
Could someone help me with this problem?
Thank you
Dan07
Use search and replace with regular Expression String selected.
-
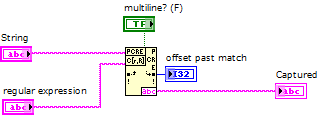
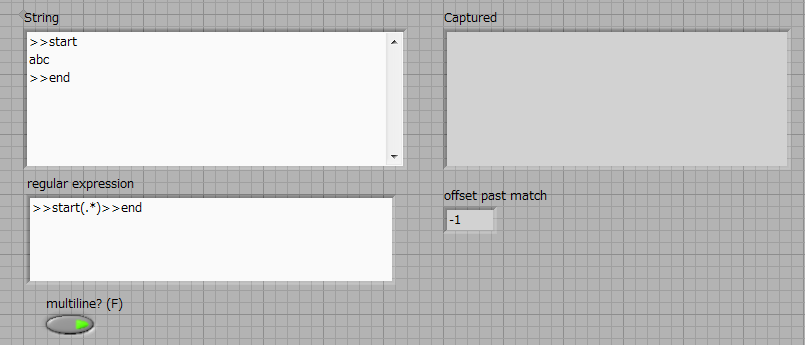
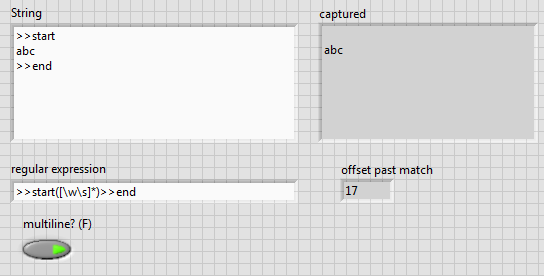
How to capture multiple line String using regular expressions?
Hello
I have a simple program like this:
What I want to accomplish is to capture everything between > start and > to end with a single regular expression matching node. It seems that the definition of multiples? true or False does not help.
I'm using LabVIEW 2012.
If it is impossible to capture using a single node, that's fine. But I want to assure you that I can make full use of this node without combining several others.
Thank you!
> start([\w\s]*) > end
A point matches any character except line break characters. You have two of them.
-
Can I do regular expressions or Boolean logic in the search?
Can I do regular expressions or Boolean logic in the search? (Windows + F) Suppose I want to search pdf files or text files. I can go * .txt | * .pdf?
I searched for about an hour for a simple answer to this and this is the closest, I came, but it still not answering the question.
Can I use expressions simple boolian in instant search and if yes what are.
I think that AND and WOULDN'T cover 90% of what I want.
I want to search for emails for things such as [Minutes AND project x]
Currently, this property returns all the messeges with minutes and all messages with project x.
Since I have minutes of many projects, and many emails with project x not the minutes that returns are many. I would use a simple AND to get the intersection.If and expression exist, I have found no reference to it.
According to me, the back had these expressions in the search function.
Thank you
-
regexp_substr: a regular expression for the separate comma operator of witn of string literals IN
The following regular expression separates simple values separated by commas (SELECT regexp_substr (: pCsv,'[^,] +', 1, level) FROM DUAL CONNECT BY regexp_substr (: pCsv, ' [^,] +', 1, level) IS NOT NULL); Exampple: 300100033146068, 300100033146071, 300100033146079 returns 300100033146068 300100033146071 300100033146079
This works very well if we use the regex with SQL IN operator select * from mytable where t.mycolumn IN (SELECT regexp_substr (: pCsv,'[^,] +', 1, level) FROM DUAL CONNECT BY regexp_substr (: pCsv, ' [^,] +', 1, level) IS NOT NULL);
But this query does not work if the comma-separated value is a single literal string 'one', 'two', 'three '.
Thanks for your reply. my request was mainly on regexp_substr. Need to request was simple: any table with a column of varchar type can be used. Next time I'll give you an example.
All ways working answer for my question is is SELECT regexp_substr (: pCsv,'[^, "] +', 1, level) FROM DUAL CONNECT BY regexp_substr (: pCsv, ' [^,"] +', 1, level) IS NOT NULL
-
regular expression replacement
Hi gurus,I have a requirement where I have to replace some characters in duplicate and retain the values of this column in order of alphabatic and digital control. Please find below examples of data
Thanks in advance
sample data:
SELECT 'ZZYYXXAAABBBDDDCCC' DOUBLE COL1
UNION ALL
SELECT 'DDDCCCAAA' OF THE DOUBLE
UNION ALL
SELECT 'SDBBACCCC' OF THE DOUBLE
UNION ALL
SELECT "99988866332154" DOUBLE
UNION ALL
SELECT "77663322996" DOUBLE
Expected:
ABCDXYZ
ADC
ABCD
12345689
23679
Hello
I don't think that regular expressions will help with that.
Here's a way to do it:
WITH single_characters AS
(
SELECT DISTINCT
col1
, SUBSTR (col1, LEVEL 1) AS a_char
OF sample_data
CONNECT BY LEVEL<= length="">
AND PRIOR col1 = col1
AND PRIOR SYS_GUID () IS NOT NULL
)
SELECT LISTAGG (a_char) WITHIN GROUP (ORDER BY a_char) AS expected
OF single_characters
GROUP BY col1
;
This assumes that col1 is unique. If this is not the case, use all that is unique, even something drift of ROWID or ROWNUM, in CONNECT BY and GROUP BY clauses.
The output I get is exactly what you posted:
EXPECTED
--------------------------------------------------------------------------------
23679
12345689
ACD
ABCD
ABCDXYZ
I guess that's what you really want.
Regular expressions can not re - organize a string so that the characters are in order; you need to split the string into pieces, order parts and then put back together them. Given that you have to do it just to get the characters in order, it's simple remove duplicates without problem with regular expressions.
-
regular expressions for numbers demical in a comma-delimited list
I have a table that lists the details of the occupation of the sites of a comma-delimited list:create table tenure_test)
number of site_number
tenure_detail varchar2 (255));insert into tenure_test values (1, ' Crown (Other) (0.15 ha), private (555.25 ha)');
insert into tenure_test values (2, ' private (5.76 ha)');
insert into tenure_test values (3, ' private (0.18 ha, Crown (3.25 hectares), Indeterminate (Leased) (5.85 ha)');)What I want to do is to use a regular expression to calculate the sum only numbers in the tenure_detail column.
For example, for site_number 1, it would be 0.15 + 555.25 = 555,4
I also have another regular expression that has just the numbers in a comma-delimited list.
For site_number 1: 0.15, 555.25
I tried this:
Select site_number, tenure_detail, regexp_substr (tenure_detail, "[0-9] + \.") ([0-9] {2}') under the name test1
of tenure_test;
but it lists only the first number.
Hello
996454 wrote:
I have a table that lists the details of the occupation of the sites of a comma-delimited list:
create table tenure_test)
number of site_number
tenure_detail varchar2 (255));insert into tenure_test values (1, ' Crown (Other) (0.15 ha), private (555.25 ha)');
insert into tenure_test values (2, ' private (5.76 ha)');
insert into tenure_test values (3, ' private (0.18 ha, Crown (3.25 hectares), Indeterminate (Leased) (5.85 ha)');)What I want to do is to use a regular expression to calculate the sum only numbers in the tenure_detail column.
For example, for site_number 1, it would be 0.15 + 555.25 = 555,4
I also have another regular expression that has just the numbers in a comma-delimited list.
For site_number 1: 0.15, 555.25
I tried this:
Select site_number, tenure_detail, regexp_substr (tenure_detail, "[0-9] + \.") ([0-9] {2}') under the name test1
of tenure_test;
but it lists only the first number.
Here's one way:
SELECT site_number
SUM (TO_NUMBER (REGEXP_SUBSTR (tenure_detail
, "\d+\.\d*" - see Note 1
) T
LEVEL
)
)
), Total
OF tenure_test
CONNECT BY LEVEL<= regexp_count="" (="">
, '\d+\.\d*'
)
AND PRIOR site_number = site_number
AND PRIOR SYS_GUID () IS NOT NULL
GROUP BY site_number
;
Output:
TOTAL OF SITE_NUMBER
----------- ----------
1 555,4
2 5.76
3 9.28
Note 1: what exactly makes a 'number '? I'm assuming it's 1 or more digits, followed by a comma, followed by 0 or more numbers. You can have a slightly different definition; in this case, change the arguments 2nd REGEXP_SUBSTR and REGEXP_COUNT.
I guess also that site_number is unique. If not, you will have to change the CONNECT BY and GROUP BY clauses, to refer to something (or a combination of things) which is unique.
Relational databases are designed for each column of each row contain 1 single piece of information, not a list delimited with a variable number of elements. It is so basic to the design of database he called the first normal form. If your first followed table form normal, this query (and many other queries that involve that table) would be much simpler to write, more efficient to run and less likely to have bugs. See if you can normalize this table. Any effort that you have to spend now to normalize the table will pay very quickly.
Thanks for posting the CREATE TABLE and INSERT statements; It is very useful.
Don't forget to tell what version of Oracle you are using. I tried the query in Oracle 11.2 above. You may need to CONNECT BY a little differently in earlier versions, and REGEXP_COUNT will not work in Oracle 10.
-
Regular expression - elimination of comments
Hello
I am trying to solve a problem, I remove the comment text of an individual raw text stored in an oracle table.
There is no special case. I mean several models of comment.
My Version of Oracle is: 11.2.0.4.
Could you help me?
Hello
You can solve this problem with the help of the regular expression REGEXP_REPLACE.
An example for this:
SELECT STRG
, REGEXP_REPLACE (strg, ' / \ * ([^(/\*) | ^(\*/)]) *------* /', ", 1, 0) AS STRG_NEW
(SELECT
"TextBlock: / * dog."
--
CAT
"* / normal / *" people * /.
text "STRG AS FROM DUAL)
;
Original text:
==============
TextBlock: / * dog
--
CAT
' * / normal / * ' people * /.
text
Result-text:
============
TextBlock: normal
text
With this selection, you can remove every comment blocks, but it doesn't work though if the comment template is not single quotes included!
It's a simple solution, that's maybe what you are looking for.
Kind regards
David Shepherd
Maybe you are looking for
-
E-mail messages cannot be marked as read automatically when they are read?
Instead of having to physically push a button to "Mark as read" after the opening of each email, why didn't they just mark themselves automatically as they are clicked on and read? Not which seems logical? All other mail clients I've ever used has be
-
British English Dictionary download in Firefox, but not seen in Thunderbird
Also used "more dictionaries" in the spelling Thunderbird checkbox. There is no download the English Dictionary of Britsh selected - just got a "rotating icon" as if she was trying to download - but didn't upload. Several attempts. Operating system:
-
If you don't wire the file path in the file i/o functions, you get a default view of the dialog box. Is there an easy way to fill the area to file with a default name name? Thank you
-
Hi knows all forum In the attached file, I have a VI called CheckFileSrvForGODialog.vi in the ModelSupport folder. When I try to add this file as 'Action' TestStand 4.1 stage I get an error-180002 "the VI is not executable. Most likely the VI is brok
-
I got an error message - driver error - restart. When I tried to reboot, I got a black screen after the HP logo. I tried f8, f12 etc., trying to find troubleshooting mode with no luck. I have a USB to recovery, but I don't know how to get the comput