single table hash clusters
I created a hash cluster single table like this:create tablespace mssm datafile 'c:\app\mssm01.dbf' size 100 m
Segment space management manual;
create the cluster hash_cluster_4k
(id number (2))
size 8192 single hash table is id hashkeys 4 tablespace mssm;
--Also created a table cluster with the line size such as single record corresponds to a block and inserted 5 records each with a separate key value
CREATE TABLE hash_cluster_tab_8k
(number (2) id,)
txt1 tank (2000).
txt2 tank (2000).
tank (2000) txt3
)
CLUSTER hash_cluster_8k (id);
Begin
because loop me in 1.5
Insert in the values of hash_cluster_tab_8k (i, 'x', 'x', 'x');
end loop;
end;
/
exec dbms_stats.gather_table_stats (WATERFALL of the USER 'HASH_CLUSTER_TAB_8K' = > true);
Now, if I try to access the folder with id = 1 - it shows 2 I / O (cr = 2) instead of the single e/s as provided in a hash cluster.
Rows Row Source operation
------- ---------------------------------------------------
1 ACCESS HASH_CLUSTER_TAB_8K HASH TABLE (cr = 2 pr = 0 pw = time 0 = 0 US)
If I run the query, even after the creation of a unique index on hash_cluster_tab (id), the execution plan specifies access hash and single e/s (cr = 1).
This means that for a single e/s in a single table hash cluster, we create a unique index? It will not create an additional burden to maintain an index?
What is the second I/o necessary for in the case where a unique index is absent?
I would be very grateful if gurus could explain this behavior.
Thanks in advance...
user12288492 wrote:
I ran the query with all 5 id values and the results have been more confusing.During the first inning, I had VC = 2 for two values of keys, the Czech Republic rest = 1
During the second inning, I = 2 for a key value, the Czech Republic cr rest = 1
In the third set, I had VC = 1 for all values of keys
The effects vary depending on the number of previous runs and the number of times you reconnect.
The extra CR is a cleansing of the block effect. If you check the access of the buffer (events 10200-10203), then you can see the details. Simplistically, if you create your data, then connect and interrogate one of the lines (but not id = 5, because that will be cleaned on the collection of statistics) you should be able to see the following numbers:
cleanouts only - consistent read gets 1
immediate (CR) block cleanout applications 1
commit txn count during cleanout 1
cleanout - number of ktugct calls 1
Commit SCN cached 1
redo entries 1
redo size 80
On the first block visited, Oracle made a visit to buffer to untangle a YVERT cleaning (ktugct - get the commit time). This cleans up the block and caches the acquired RCS. The rest of the blocks that visit you in the same session should not be cleaned because the session can use the updated SNA caching to avoid needing a cleanup operation. Finally all the blocks will have been cleaned up (which means that they will be written to the disk) and the extra CR stops happening.
There is a little quirk - drain plug seems to apply to the format block calls - and I do not understand why this was did not each row inserted thereafter.
Concerning
Jonathan Lewis
Tags: Database
Similar Questions
-
Table of clusters and the cluster is a bar counter, how can I change the color individually?
Table of clusters and the cluster is a bar counter, how do I change the color of the bar individual meter for each element of the array? I just realized that you cannot change the properties of an element of the array without changing everything. For scale, I had to make digital for each graduation of the scale indicators so that each measure meter in the table in the cluster has individual scales. I also had to do some calculations for each barmeter to display the correct proportions of 0 to 100% on the scale. Now, I'm stumped on the color of the bar counter. Basically, if the value exceeds a set value, the meter bar should turn red. It must be in a table to be infinitely scalable.
Thank you
Matt
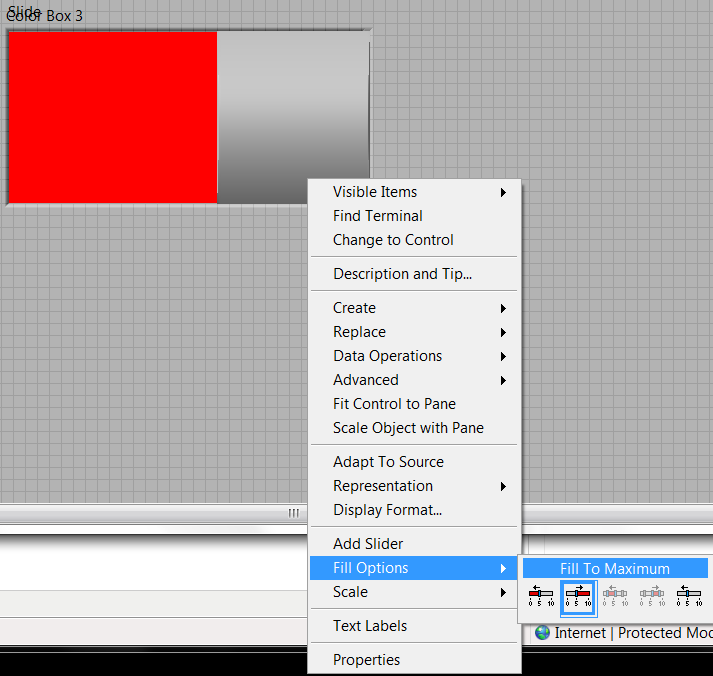
And yet anothr approach...
Right click on the bar of > Options to fill > maximum fill.
The fill color of the same color as the background color, then make the background color transparent.
Drop a box of color BEHIND the bar and the size correctly.
He has this strange background 3D with flat bar, but what the Hey, his relatives. If its important a custom color box.
Ben
-
issue with tables and clusters
Hello
Another issue with the tables and clusters. I have three engines thatI move on XYZ and then measure something. I need to draw on the 3D, the result of the measurement. How to draw real XYZ and not the index of the data table positions? (I can't actully how to build the matrices 2D forX, Y and Z). In the figures, I give an example of what I need.
Concerning
You have to break the data out of the cluster and to present them to the graph 3d to a separate bays for X, Y, Z and W where 'W' is your values measured at the locations described by X, Y, Z.
This thread shows how trace readings in space 3. The following image shows the data that the original author wanted to draw.

Have fun
Ben
-
Dreamweaver several graphs in single table cell
Dreamweaver is having problems when I try to combine multiple charts in a single table cell. Some are separated by two end just "" entries, while others do not accept these separators. Pleas you show me the right way to handle this.
Jack,
- Tables should not be used for web page layouts.
- Tables for tabular data such as spreadsheets and graphics only.
- Today, we use an external CSS file for the layout, typography and other styles.
Please show us what you are trying to do by copying and sticky code in a reply from the web forum.
Nancy O.
-
End of data collection on a single cluster other clusters in vRA6.2
End of data collection on a single cluster other clusters in vRA6.2
Please try to create a reserve in the same cluster and try. In the directory of vRA installed server IaaS / vmware/vcac/server/all.log check the error in the log file.
some time because if remove you a hard drive in the vcenter which information will not update in the vRA correctly.
during the maintenance window, please run the following SQL queries in SQL Management Studio to verify (and remove invalid disc VM) database.
NOTE: Remember to backup the SQL db before running any scripts!
1. SQL to find and list all the disks that have no storage or storage that is NULL:
----------------------------------------------------------------------------------------------------------------
SELECT h.HostName, vm. VirtualMachineName, vm. IsManaged, vm. StoragePath, vmd. DiskName, vmd. Capacity, vmd. DeviceID
FROM dbo. VMDiskHardware vmd
Join dbo. VirtualMachine vm
THE vmd. VirtualMachineID = vm. VirtualMachineID
JOIN host h
ON the virtual machine. ID host = h.HostID
WHERE vmd. HostToStorageID is null
----------------------------------------------------------------------------------------------------------------
2 SQL statement below to remove disks storage not having valid. Note: they're going to be remembered next inventory data collection. Recommend triggering data collection immediately after you run the script below.
----------------------------------------------------------------------------------------------------------------
REMOVE FROM VMDiskHardware
WHERE HostToStorageID IS NULL
----------------------------------------------------------------------------------------------------------------
3 run the first query to confirm the deletion succeeded. (non-NULL)
4. after data collection runs the query below, check the integrity of all disks.
----------------------------------------------------------------------------------------------------------------
SELECT COUNT (*) IN VMDiskHardware
WHERE HostToStorageID IS NOT NULL
----------------------------------------------------------------------------------------------------------------
-
How to restore a single table from a DP Export to a different pattern?
Environment:
Oracle 11.2.0.3 EE on Solaris
I was looking at documentation when importing DP trying to find the correct syntax to import a single table of an RFP to a different schema export.
So I want to load the table User1. Table1 in USER2. Table1 a DP Export.
Looking at the REMAP_TABLE options:
I can't see where to specify the name of the target schema. Examples were the new table name residing in the same pattern with just a new name.REMAP_TABLE=[schema.]old_tablename[.partition]:new_tablename OR REMAP_TABLE=[schema.]old_tablename[:partition]:new_tablename
I looked at the REMAP_SCHEMA but the docs say matter the entire schema in the new schema and I want only one 1 table.
All suggestions are welcome!
-garyI thought I tried this combination and it seemed to me that the REMAP_SCHEMA somehow too rolled TABLES = parameter > and started to load all the objects.
If it does not fail (and it shouldn't) then please post details here and I'll see what happens.
Let me back in the tray to sand and try again. I admit I was a bit of a rush when I did the first time.
We are all in a hurry, no worries. If it fails, please post the details and the log file.
Does make any sense that a parameter would be substitute another?
No, this should never happen. We have tons of audits to ensure that labour cannot have several meanings. For example, you can not say
Full schemas = y = foo - what you want, or a full export list export schema, etc.
Your suggestion was the first thing that I thought would work.
It should work. If this isn't the case, send the log with the command and the results file.
Dean
Thanks again for the help and stay tuned for my new attempt.-gary
-
multiple to single table replication
Hello
Is there a way we can replicate multiple tables at source on a single table to the target.
example: join table A and B on the source and put it in the table C.
Thank you!Yes it is possible. OGG can be used to get the data from the tables of the source and go in a single target table. But keep in mind if you are data fusion then PK conflict should be avoided otherwise, you can get any data problems.
-Koko
-
Repetition of groups nested in a single table - model RTF
Hi all
I have a little problem with RTF models. I try to use 2 recurring groups within a single table, but everything I'm not get data for the fields of the outer loop, or still getting only one record of the loop internal.
It is a model of report of cash requirements. My expandable outside group is G_VENDOR and internal is G_INVOICE. I'm at the stage where I pasted the table with the G_INVOICE details in another table (with the NAME of the SELLER in the first field). This has however a drawback - it is not to repeat the name of the seller if there is more than one G_INVOICE in G_VENDOR. I don't want tables repeated for each provider, one with all the data.
I had SR Oracle open, but they seem not to be very useful, makes me think it is a bug and not fixed will never be. I know that the XML flatenning would be an option, but I don't want be to redevelop all alone I need template for reports.
Someone has an idea?
Concerning
PiotrHi Piotr,
Ideally you would be that flatten, but if you are inside the loop of invoice you can still access the fields of the outer loop by changing the form field and by prefixing with... /.
for example becomes
Kind regards
Robert
-
How to combine the large number of tables of pair key / value in a single table?
I have a pair key / value tables of 250 + with the following features
(1) keys are unique within a table but may or may not be unique in the set of tables
(2) each table has about 2 million lines
What is the best way to create a single table with all unique key-values of all these paintings? The following two queries work up to about 150 + tables
with t1 as ( select 1 as key, 'a1' as val from dual union all select 2 as key, 'a1' as val from dual union all select 3 as key, 'a2' as val from dual ) , t2 as ( select 2 as key, 'b1' as val from dual union all select 3 as key, 'b2' as val from dual union all select 4 as key, 'b3' as val from dual ) , t3 as ( select 1 as key, 'c1' as val from dual union all select 3 as key, 'c1' as val from dual union all select 5 as key, 'c2' as val from dual ) select coalesce(t1.key, t2.key, t3.key) as key , max(t1.val) as val1 , max(t2.val) as val2 , max(t3.val) as val3 from t1 full join t2 on ( t1.key = t2.key ) full join t3 on ( t2.key = t3.key ) group by coalesce(t1.key, t2.key, t3.key) / with master as ( select rownum as key from dual connect by level <= 5 ) , t1 as ( select 1 as key, 'a1' as val from dual union all select 2 as key, 'a1' as val from dual union all select 3 as key, 'a2' as val from dual ) , t2 as ( select 2 as key, 'b1' as val from dual union all select 3 as key, 'b2' as val from dual union all select 4 as key, 'b3' as val from dual ) , t3 as ( select 1 as key, 'c1' as val from dual union all select 3 as key, 'c1' as val from dual union all select 5 as key, 'c2' as val from dual ) select m.key as key , t1.val as val1 , t2.val as val2 , t3.val as val3 from master m left join t1 on ( t1.key = m.key ) left join t2 on ( t2.key = m.key ) left join t3 on ( t3.key = m.key ) /A couple of questions, then a possible solution.
Why the hell you have 250 + tables pair key / value?
Why the hell you want to group them in a table containing one row per key?
You could do a pivot of all the tables, not part. something like:
with t1 as ( select 1 as key, 'a1' as val from dual union all select 2 as key, 'a1' as val from dual union all select 3 as key, 'a2' as val from dual ) , t2 as ( select 2 as key, 'b1' as val from dual union all select 3 as key, 'b2' as val from dual union all select 4 as key, 'b3' as val from dual ) , t3 as ( select 1 as key, 'c1' as val from dual union all select 3 as key, 'c1' as val from dual union all select 5 as key, 'c2' as val from dual ) select key, max(t1val), max(t2val), max(t3val) FROM (select key, val t1val, null t2val, null t3val from t1 union all select key, null, val, null from t2 union all select key, null, null, val from t3) group by keyIf you can do it in a single query, Union all 250 + tables, you don't need to worry about chaining or migration. It may be necessary to do this in a few passes, depending on the resources available on your server. If so, I would be inclined to first create the table, with a larger than normal free percent, making the first game as a right inset and other pass or past as a merger.
Another solution might be to use the approach above, but limit the range of keys with each pass. So pass we would have a like predicate when the key between 1 and 10 in every branch of the union, pass 2 would have key between 11 and 20, etc. In this way, everything would be straight inserts.
That said, I'm going back to my second question above, why the hell you want or need to do that? What is the company you want to solve. There could be a much better way to meet the requirement.
John
-
Hi all
I am using the command merge onto a single table. I want to check some values in the table, if they already exist I just update, thing that I want to insert.
For this I use the following code:
MERGE INTO my_table OLD_VAL
NEW_VAL in ASSISTANCE from (SELECT L_field1, L_field2, L_field3, DOUBLE L_field4)
WE (OLD_VAL.field1 = NEW_VAL. L_field1
AND OLD_VAL.field2 = NEW_VAL. L_field2
AND OLD_VAL.field3 = NEW_VAL. L_field3
)
WHEN MATCHED THEN
UPDATE SET OLD_VAL.field4 = NEW_VAL. L_field4
WHEN NOT MATCHED THEN
INSERT (Field1, Field2, field3, field4, sphere5)
VALUES (NEW_VAL. L_field1, NEW_VAL. L_field2, NEW_VAL. L_field3, NEW_VAL. L_field4, SYSDATE);
Fields starting with L_ here is my local variables inside my procedure.
It is giving error as ORA-00904: "NEW_VAL. "" L_field3 ": invalid identifier
Thank you all.SELECT L_field1, L_field2, L_field3, DOUBLE L_field4
1. you r select all values here?
2. try to give alias for all columns -
For a single table import failed...
Hello
On the production server, I reported a user db, let's call it PRD_USER, with tablespace PRD_TBL default.
On the development server, I reported a user db, let's call it PRD_USER, with tablespace DEV_TBL default.
On the production server, I use the db of exp utility to import as:
IMP System/Manager of the user PRD_USER touser = PRD_USER = ignore = file_name = «...» ' log = «...» ».
Succeeds the import for about 25 tables and indexes and constraints, but it fails for a single table with the error: {I don't remember the error ORA- and I do not have access currently} DEV_TBL tablespace does not exist.
Of course this tablespace does not exist on production env. But how this problem arises because the default tablespace for the user is not DEV_TBL but PRD_TBL...?
Do you have any idea what can be the cause and how can I overcome this problem when importing...? {Note: I gave a temporary solution... take the table creation sql script leaving aside the reference of the tablespace "DEV_TBL"}.
The two servers work in exactly the same version of DB...
Note: I use DB 10g v.2
Thank you
SIMIf the table has Partitions, import strives to create the Partitions (in the CREATE TABLE statement) on the original table space.
OR there is a LOB segment in the table import strives to create on the original table space.
Hemant K Collette
-
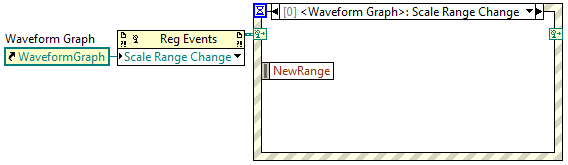
Table of clusters with graph - scale change event Y
Hello everyone
I have an array of Clusters with a graphic within each cluster. I need raise an event when the user, type a new value to the scale of the graphs Y and press "Enter" to apply the change. Any ideas how to trigger that?
I am not considering event 'mouse enter' because I have other events related to that already.
Thank you
Dan07
Given that the graph is in a table, you must dynamically record the event of change of scale. Typical static records are not allowed for the elements of the array, and it is not a good reason why they cannot be admitted, that's why I created an idea for allow static event registration of items in the array. I hope you go to the exchange of ideas and vote for this idea.
-
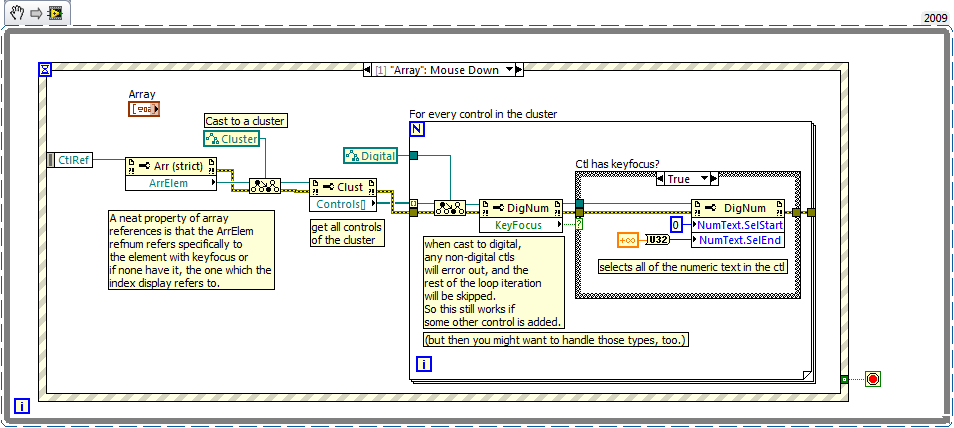
Control of "tab" on the keyboard in the table of Clusters
I'm trying to Polish some of my LabVIEW user interfaces so that my users can work faster in them and so that they follow more "user Windows interface standards" (or other).
I have an array of clusters. The cluster has 3 digits.
When a user "focuses" on the first digital in a cluster and press the tab key, it moves the focus to the second digital. Press tab again, and he climbs to 3rd digital. Hit the tab key a 3rd time and it jumps to the first digital in the cluster. I want to do is for the focus to move to the first digital in the element next to the table.
I started playing with the case "Key Down" event that has a conditional looking for "TAB" and then check the 'FindCtrlWithKeyFocus' with the last digital. My probes in this event show that detection of keys "TAB" works, but the "FindCtrlWithKeyFocus" never invoke a REAL output of the output of "CtrlFound?" of the node.
Even though I didn't know if the tab has been pressed in the last item, I know right how to move the focus to the first digital within the next cluster of the table element.
A table behaves appropriately. I was able to get the program to work as I want with a 2d numerical values table. However, each digital has different data entry parameters and there is also a loss of "free documentation. I would like to find a solution because it came with another, more complex, Bay of clusters that would not be solveable with an array of 2d from a base type.
Seems too complicated for me.
Bonus question: the default my digital is 0. When my user clicks on a digital the cursor is on each side of the value 0 and the user must remove 0 before their seizure. When a number is entered through the Tab key, the entire field is selected. When the whole field is selected, all user entries will replace the '0' original, which has been in the field. In any case, to have all of the selected field when the user uses the mouse?
Sorry for the post wall-of-text (and the hell of the preposition). Thanks for your comments.
and a snippet of code, if it is more useful for some:
-
Problem updating a table of clusters that contain some gauges
Hello
I have problems when I write to an array of clusters that contain some gauges.
I wrote an example program to illustrate the problem.
[I create a digital, digital picture].
I have complete 4 elements of the array with the data.
If I shoot each element with a function Index Array and write the data in 4 indicator groups independently, I have no problem.
If I have the wiring of the table of 4 elements in an array of clusters, the needles on the gauges redraw correctly.
However, simply by moving the mouse on the element table causes the display to redraw this element.
I played a bit with synchronous display and reporter Panel updates, but they do not seem to affect this behavior.
Any thoughts?
A picture of the problem and the VI are attached.
When something like this pops up I usually try covering the incriminated with a transparent 2D image control. Controls overlapping sometimes cause problems, sometimes they solve them.
-
Labview Newbie question: Table of clusters
1: I am a student
2: this isn't homework or a project classified
3: I'm a programmer capable enough, but it is in the textual languages. ;-)
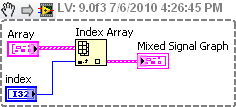
I have a sensor that contains 4 channels of power. I need to keep all 4 active channels, but I want to choose one of them to the chart at any given time. The data from the driver OR hardware comes in form of table of 2 elements 1 x 4 clusters.
Normally, I had just index for the item in table 1 x 4 and feed on this cluster to the right graphic tool, but I'm missing something. I had a display of the sample driver NI of VI element, but anytime I insert blocks between the stream and the graphic I get errors "bad connection".
I've been googling and book-research for several days now, nothing helps, I'd appreciate any help in this matter.
in the image to ( http://dl.dropbox.com/u/4286123/LabviewHelp.jpg ), this block can I insert in the wire highlighted in order to select and only one of the 4 data, a source-controlled channels integer graph?
Thank you very much.
Use the Index table funtion in the palette of Array. Wire in the index number of the wave that you want to display.
{kind=link}
Maybe you are looking for
-
I have a g motorcycle, and I can't do more then 4,30 hours with wifi and 3,20 hours with 3g screen. Is it normal? I read that g motorcycle can go up to 6-7 hours of projection on. Thanks for the reply, Sorry for my bad English, I'm Italian.
-
Touch pad to turn off Windows 7 when the mouse remotely installed as I could in Windows XP
In Windows XP, I could go to control pannel, mouse and click to Disable Touchpad when another mouse was attached. It would be automatically on the touch pad if no mouse was attached USB. I couldn't locate any method or the answer that allowed a cha
-
How can I control what how data services use on the network?
Recently, while I was not at my computer, something used 60GB of download on my network in the space of two hours of data. As far as I know, none of my programs should do that on their own. Is there some software or utilities that not only allows me
-
Bug - window Plan can't handle "UNPIVOT INCLUDE NULLS" (v. 4.0.1.14)
SQL-Developer has a problem with the command "UNPIVOT INCLUDE NULLS", when used in PL/SQL packages.This problem still exists in version 4.0.1.14 build 14.48When the command "UNPIVOT INCLUDE NULL values" is used, the preview window shows nothing, or s
-
How can I transfer the membership
I have a privat subscription which I want to change to a membership of the company. Is there an easy way to do this?