Size of array allocation on IBM DS3524
Hello world
It is a question of design on the size distribution of paintings I will deploy next year.
We will buy a DS3524 with 48 drives to meet several needs:
1 unit number logic of the transaction of a few DB VMs in RAID10 logs
1 unit logic for DBs in a RAID5 configuration number
1 for large files in RAID10 logical unit number
2 no intensive generic LUN VMs in a RAID5 configuration
1 unit number logic for some virtual machines from view in RAID10
It is more or less installation (you can make suggestions on this subject too if you want to), we will use 8Gb FC switched model SAN. We went to 2 GB cache on each controller. (Btw, I'm very curious to know what do do this software TURBO option?) I'm very curious to €6000 on a configuration of €25000!)
We will use vSphere 4.1.
I am eager to understand what Strip size to choose at the level of the table of these LUNs; AFAIK VMFS are automatically aligned so that they are created from the VI Client and size is 128 k (am I right here?)
Then I'll be lining up the file system of the VMS as described by the Vmware Documentation. My problem is that reccomands of Vmware to check all the documents of the seller to choose the block sizes, but I do not seem able to find everything from IBM on this disc matrix model (or any other what is important)
Anyone have any suggestions? Of course performance is the concern here.
Indication on the sizes cluster in virtual machines file systems are also welcome even if it is not so important, so I can compare with my ideas.
Thank you.
According to IBM RedBook http://www.redbooks.ibm.com/redpieces/pdfs/sg247914.pdf default is 128 k, however depending on your needs, you can read the 3.3.8 chapter to know what is best. The RedBook also makes recommendations for use with ESX.
André
Tags: VMware
Similar Questions
-
Hello, I have to install a DS3524 connected to a server with VMWARE installedESX4.0.4Update4 IBM.
The DS3524 is connected via SAS 12 are installed 300GB HD and 2 SD thecontroller is mounted in the cache of 2 GB.
I wanted to know if you must configure a RAID6 11HD and 1HD immediate replacement and if I can then create a single logical unit of 9 x 300 = 2.7 to?
Thank youNice day
There is, of course, ways around what appear to be limits. You can have a "logical unit" more than 2 TB if you use extensions. Go ahead and create a 2 TB LUN and a Go 700 LUN. Add the 2 TB LUN as a data store, and then increase the size of the data store in the vSphere Client. You should see your 700 GB available LUNS. In the properties of the data store, you should see something similar to the screenshot below.

And under Configuration > Storage, you will see the maximum available space is greater than 2 TB, as below.

Of course, these screenshots are from a vSphere environment 5, but these fine vSphere 4 and VMFS-3 will be similar. You will also always be limited to the size of 2 TB hard limit less 512 B.
Let me note there are some arguments against the use of the extensions, but it's not like you will encounter such a scenario. Check out this post for a demystification of VMFS myths, including the use of extensions: http://virtualgeek.typepad.com/virtual_geek/2009/03/vmfs-best-practices-and-counter-fud.html
See you soon,.
Mike
Mike
-
change the size of array without initializing
Hello
I'm trying to dynamically change the table size.
I'm doing a calibration of an instrument and from time to time I read 3 parameters and try to write in an empty array (do not reset) and caclulate interpolation polinom according to my measured data.
The table must be empty because I use the same table as input for the calibration procedure and it may not contain the zero but only the measured values and it will develop that my flow measurement.
I hope that my question is simple,
Kind regards
Sasa
Hello Sasa,
two options come to mind:
(1) use the BuildArray to 'grow' your table of measurement points. Add only "not null" points to the table...
(2) search the forum for discussions on 'remove items from the table', you will find something like this...
-
Initialization of an array to match another size of array using the formula node.
I want to get a few different pictures of the same length and constants in the formula node and output a table corresponding to their length after some minor calculations. Another post, I discovered that I can simply initialize the table as such:
float pp [100];
The problem is that I find myself with a much bigger picture than what I need. I want to do is something like:
float [n] pp.;
where n represents the entry of an array size in the form node or is something like:
n = sizeOfDim(td0,0); Here I use a table 1 d
None of these methods seem to work. How do I initialize my picture 'pp' such that it matches the length of array 1 d of "td0?
The more likely your initialization externally. Create an entry named pp and wire td0 inside as well. Now create an output with the pp even name and it will contain an array of the desired length. Of course, this assumes that you want to edit all items in pp. Otherwise, just use initialize the array to create a new table and feed in the length of td0, and whatever default value you want (ie. 0 or NaN). The blank values will keep this value after the node of the formula.
-
Size of array problem in Windows 7
Hi all
I have a VI through the opening in a new laptop, it shows a few tables inadequate controls (with a table diferent size), however I can´t put it right.
But when I'm doing an EXE of this VI and if I run the EXE in another computer, the façade seems aligned and Ok.
I m using the labview 2009 Sp1 with Windows 7, this vi have been created in another laptop in an older version and always with the Windows Xp, and every time that I updated the version of labview always seems correct on the laptop, until now when I changed the laptop computer and the operating system to Win7.
Any help/advice is much apreciated
Thank you
Make sure that you use the same font settings for all the controls you want to align. You might have some controls set a specific font name and others left the police to default Application. LabVIEW replaces the police request regardless of the default font of the system is on a particular computer.
Different fonts are by default and available on different versions of Windows then you can definitely get in trouble here if you mix families of fonts and the names in the same user interface.
If you request a specific font name and it is not available on some Windows machine will be replaced by another policy that he thinks looks like but the heuristics of this substitution can sometimes go really South of the Ecuador and just give the crazy results.
-
Why this DLL to double the size of array?
Here's some code for a simple DLL that I use as a test case. LabVIEW pré-alloue memory by initializing arrays of 19 and 21 items, but the output of the function is an array of 38 and an array of 42. Why would he do that?
_declspec (dllexport) int split_array (unsigned char * array_in, unsigned char * split1, unsigned char * split2);
int split_array (unsigned char * array_in, unsigned char * split1, unsigned char * split2)
{
int i;
for (i = 0; i< 19;="">{
Split1 [i] = array_in [i];
}
for (i = 19; I)< 40;="">
{
Split2 [(i-19)] = array_in [i];
}
return 0;
}
-
Input array allocated by the function even if it is not
I set it up to call the foalT table 4 times to combine with different results. foalT is a multidimensional array with each element of the element 4 long. It works perfectly the first time that the function is called foalTotal is correct. Other times foalT is empty. It seems that the problem happens when I use original.shift () and then call them recursively function but I have no idea why original happens in the foalT table. Any help would be appreciated.
var foalTotal:Array = handset (foalWA, foalT);
var foalTSC:Array = Combine(foalWASC,foalT);
var foalTDC:Array = Combine(foalWADC,foalT);
var foalTBC:Array = Combine(foalWABC,foalT);
Function Combine(cross:Array,original:Array):Array {}
var k: uint = 0;
total var: Array = new Array;
trace ("foalT length:" + original.length);
If {(original.length!==0)}
for (var i: uint = 0; i < cross.length; i ++) {}
for (var j: uint = 0; j < = 3; j ++) {}
total [k] = cross [i] .slice ();
total [k].push(original[0][j]);
k++;
} //end for
} //end external to
original.shift ();
(Combined (total, original)); return
} //end if
else
return (cross);
{ } / / end fuction
Flex has some degree of use of the references who know you in this case.
As noted in the previous poster, you must clone the object in this case.
-
After effects error: invalid size of array DICT
I'm running latest version of Mountain Lion on the retina of Mac Book Pro 15 ". I "ve validated all my fonts with Font Doctor. I've done everything on this link: http://helpx.adobe.com/x-productkb/global/troubleshoot-fonts-mac-os-x.html I used software cloning to backup my system disk in the hope, it generates an error log, but it found no errors. I've uninstalled and reinstalled all Adobe software on my computer. The problem persists?
This bug is corrected in the after effects CC (12.1) update:
http://Adobe.LY/AE_CC_12dot1_details
Let us know how it works when you tried with the new update.
-
I understand the need to align VM vmdk NTFS partitions to the limit of 64 k to match the size of array distribution - however, in the http://www.VMware.com/PDF/esx3_partition_align.PDF the document also States to set to 32 k allocation unit size - please someone can explain this to me?-what is the reason / advantage because I was under the impression that all that was necessary was partition alignment.
It is also important and adjustable, but it is not at the point of the document. It is common sense to try to adjust this to 64 k or try tunning it for better performance.
Marcelo Soares
VMWare Certified Professional 310/410
Technical Support Engineer
Globant Argentina
Review the allocation of points for "useful" or "right" answers.
-
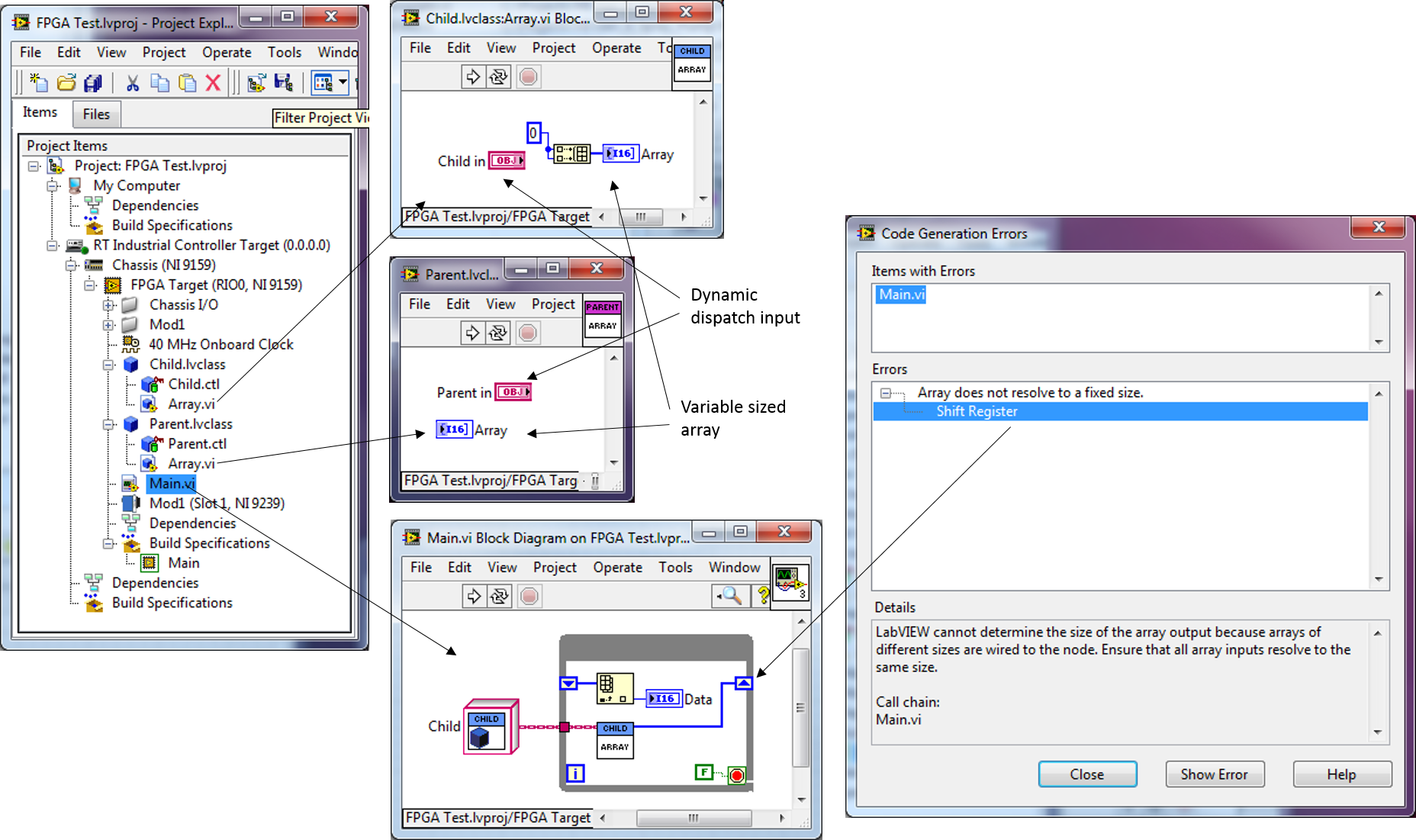
Dynamic release of variable size of dispatch class method array on FPGA
I have a parent on the FPGA class that will serve as a model/framework for future code which is developed. I had planned on creating a class of the child and by substituting a few methods. The child class constant would have fallen on the schema so that the compiler would have no trouble knowing which method (parent or child) should be used (i.e. the parent method will in fact never used and will not be compiled with the main code). The output of one of the methods is a table. This table will have a different size depending on the application. I set the size of array as a variable. In the method of the child, there is no doubt about the size of the array so that the compiler must be able to understand. However, when I try to compile, I get an error on the size of the array. I can't figure a way around it. Any thoughts would be greatly appreciated!
Thanks, Patrick
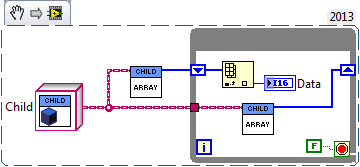
The question implies the use of the register shift unitialized. On the first iteration of the loop, the value that comes out of the shift register is the default value for the data type, which is an empty array for a table (size zero). Therefore, unless wire you a table empty for the shift register to the right, the size of the array cannot infer statically by the compiler.
To resolve this problem, you must feed an initial value for the table. Here, I just used the function of the matrix, but if you need to have a separate method that returns an array of default or the size of the array that will work as well.
-
default value for the size of the array
GDay,
I have a cluster with some values and an array of Boolean. I use the cluster in different screws, so I recorded it with a typedef.
I would like to add a required table for my table size 2-dimensional Boolean. How can I afford?
Thank you very much
bemvo
Store default values or using the table to really reshape does not execute the action to force a mandatory array size. You can't really set a size of array binding 'automatically '. A programmer can plop down your typedef on the block diagram and change the number of lines/columns in any way they want, regardless of whether it has default values. This way, your program must check each time the cluster is used. If you choose to generate a mistake is yours, depending on which means that data.
On a broader note, LVOOP (or similar) can be used for this sort of thing. By example, if you had an accessor function to set the table this accessor function can check that the size of the array.
You may also be able to do with XControls, but I don't know since I have very little familiarity with the people.
-
Cluster Hyper-V CSV allocation unit size
Hello. Is there any recommendation Dell when it comes to the size of the allocation unit of the NTFS volumes that serve as CSVs (Cluster shared Volumes) in a Hyper-V cluster?
Using EQL LUN in the background apparently.
Where should we go with the default using Windows (based on the size of the volume/LUN) or should I use something different to optimize performance, for example 64 k?
CSV store virtual machines with different workloads, nothing specific, such as SQL pure or web servers, etc..
Thanks in advance.
Hello
Cluster size when you format a volume must always be 64K. Which corresponds to the size on the spreadsheet. Writing in complete stripes is the most effective way, it reduces the overhead of RAID.
Kind regards
Don
-
Parsing XHTML and byte array size limit
Hello
I would like to analyze incoming e-mails on the device to retrieve information. The email format is XHTML and I use a sax parser to extract data (API version 4.2.1).
InputStream is = new ByteArrayInputStream(xhtml.getBytes(encoding)); _document = docBuilder.parse(is);
It works fine, but it seems there is a limit of size on arrays of bytes (max count = 1999) because I had an "unexpected end of file exception" when my string is too long.
Does anyone know how to overcome this size limit?
Kind regards
Stone
By default, I think that just the first 2K of a value of data associated with an email is delivered to the device. You need to ask for more to get the rest, I think. Could it be the problem? Take a look in the knowledge base for articles on this subject, I do not remember having seen that addressed this and describes how to get the remaining data.
-
Create endpoint network Stream - pre-allocation for strings
Hello
I would use really allocation entry mode to pre-allocate memory on my RT goal. My concern is how to allocate memory for the size of the string.
Because of the documentation
"pre-allocate specifies that memory allocation buffer occurs when the end point is created. Wired for the type of input data determines the amount of memory allocated for each item. If a greater element is added to the buffer during execution, the extra memory is allocated dynamically. "
I understand that if I am wiring constant string to the category data, 40 to the size of the buffer I receive buffer to 40 channels. String but how long? A single character?
I don't want to let the Manager of memory to run after the creation of endpoint, so I would allow large memory space (for example 40 string, 10 characters each).
Is it possible to do constant connection string (for example with 10 characters) or I have to put my string specific to the cluster size?
Another question of trival perhaps, is - it possible to check what size buffer was allocated by this VI?
Kamil
Hello
Here is some additional information on the allocation of memory for network streams:
http://www.NI.com/white-paper/12267/en/
My guess is that in order to pre-allocate buffers to not scalar data types, you'll write 'false' elements of the size desired in the stream to read or to flush out these elements "dummy" bevore using the flow in normally.
Best regards!
-
Write to the Cluster size in binary files
I have a group of data, I am writing to you in a file (all different types of numeric values) and some paintings of U8. I write the cluster to the binary file with a size of array prepend, set to false. However, it seems that there are a few additional data included (probably so LabVIEW can unflatten on a cluster). I have proven by dissociation each item and type casting of each, then get the lengths of chain for individual items and summing all. The result is the correct number of bytes. But, if I flattened the cluster for string and get this length, it is largest of 48 bytes and corresponds to the size of the file. Am I correct assuming that LabVIEW is the addition of the additional metadata for unflattening the binary file on a cluster and is it possible to get LabVIEW to not do that?
Really, I would rather not have to write all the elements of the cluster of 30 individually. Another application is reading this and he expects the data without any extra bytes.
At this neglected in context-sensitive help:
Tables and chains in types of hierarchical data such as clusters always include information on the size.
Well, it's a pain.


Maybe you are looking for
-
Satellite U400-138 - wireless network card does not appear in Device Manager
Hardware WiFi isn't in Device Manager.Win Vista 32 bit, Ultimate Realtek Semiconductor Corporation
-
enable all controls without property nodes
On my FP, there are controls/indicators that are in the hidden state. I know that I can make them visible with the nodes properties. However, I was wondering is there a way to do it with just a few clicks?
-
How to display all the mp3 files in the SD card in a listview in blackberry?
I want to display the mp3 files stored in the SD card in a listview in blackberry... How to make. ?
-
Is not not aware if I got any AV software on my Smartphone (BlackBerry 9320 OS: 7.1, build software: 1011), I tried a bunch of F-Secure (via Virgin Media) which offers licenses for up to 5 elements, such as a PC, tablets, Smartphones. I installed suc
-
I can't get the Adobe ProXI to quit smoking/uninstall after the end of the trial period. What should I do?