With tables nested loops
It's my current and outer cfloop. How many nested cfloops do I need to go on field data.current_version.en.text ? My guess is two loops, but I'm not sure about specifying the value for the 'to' in the cfloop.
< cfif structKeyExists (cfData, 'data') >
< cfoutput >
< cfloop index = "i" = "1" to = "#arrayLen (cfData.data) #" >
#cfData.data.searchTitle.en # < h1 > < / h1 >
#cfData.data.current_version.en.text # < p > < /p >
< / cfloop >
< / cfoutput >
< / cfif >
And this is what looks like the struct.

OK, got it working.
#cfData.data [i].current_version.en.text #.#cfData.data [i] .name #.
Tags: ColdFusion
Similar Questions
-
Hi all
Output:DECLARE TYPE ty_valid_prfx_sfx_list_nt IS TABLE OF VARCHAR2 (3); t_vld_prx_sfx_list ty_valid_prfx_sfx_list_nt := ty_valid_prfx_sfx_list_nt ('JR', 'SR', 'I', 'II', 'III', 'IV', 'V', 'RN', 'MD', 'MR', 'MS', 'DR', 'MRS', 'PHD', 'REV', 'ESQ') ; v_index NUMBER; v_curr_val VARCHAR2 (10); v_prev_val VARCHAR2 (10); v_next_val VARCHAR2 (10); BEGIN v_index := t_vld_prx_sfx_list.FIRST; WHILE v_index IS NOT NULL LOOP v_curr_val := t_vld_prx_sfx_list (v_index); v_prev_val := t_vld_prx_sfx_list.PRIOR (v_index); v_next_val := t_vld_prx_sfx_list.NEXT (v_index); DBMS_OUTPUT.put_line ('v_prev_val = ' || v_prev_val); DBMS_OUTPUT.put_line ('v_curr_val = ' || v_curr_val); DBMS_OUTPUT.put_line ('v_next_val = ' || v_prev_val); --DBMS_OUTPUT.put_line (t_vld_prx_sfx_list (v_index)); v_index := t_vld_prx_sfx_list.NEXT (v_index); END LOOP; END;
v_prev_val =
v_curr_val = JR
v_next_val =
v_prev_val = 1
v_curr_val = SR
v_next_val = 1
v_prev_val = 2
v_curr_val = I have
v_next_val = 2
v_prev_val = 3
v_curr_val = II
v_next_val = 3
v_prev_val = 4
v_curr_val = III
v_next_val = 4
v_prev_val = 5
v_curr_val = IV
v_next_val = 5
v_prev_val = 6
v_curr_val = V
v_next_val = 6
v_prev_val = 7
v_curr_val = RN
v_next_val = 7
v_prev_val = 8
v_curr_val = MD
v_next_val = 8
v_prev_val = 9
v_curr_val = MR
v_next_val = 9
v_prev_val = 10
v_curr_val = MS
v_next_val = 10
v_prev_val = 11
v_curr_val = DR
v_next_val = 11
v_prev_val = 12
v_curr_val = rsam
v_next_val = 12
v_prev_val = 13
v_curr_val = PhD.
v_next_val = 13
v_prev_val = 14
v_curr_val = REV
v_next_val = 14
v_prev_val = 15
v_curr_val = ESQ
v_next_val = 15
I'm getting an unexpected exit, please check and correct my program.
any help in this regard is highly appreciatedexpected output : 'JR' 'SR', 'I', 'II', 'III', 'IV', 'V', 'RN', 'MD', 'MR', 'MS', 'DR', 'MRS', 'PHD', 'REV', 'ESQ' fitst iteration : v_prev_val = v_curr_val = 'JR' v_next_val = 'SR', second iteration v_prev_val = 'JR' v_curr_val = 'SR' v_next_val ='I' Third iteration: v_prev_val = 'SR' v_curr_val = 'I' v_next_val ='II' . . . . .
Thank you
Prakash P
Published by: prakash on August 30, 2012 22:01An example:
SQL> declare 2 type TStringArray is table of varchar2(10); 3 array TStringArray := 4 new TStringArray( 'Tom', 'Commander', 'Harry', 'Sally' ); 5 begin 6 for i in 1..array.Count loop 7 DBMS_OUTPUT.put_line( '***************' ); 8 DBMS_OUTPUT.put_line( 'current='||array(i) ); 9 10 --//can also use: if array.Exists(i-1) then 11 if (i-1) >= 1 then 12 DBMS_OUTPUT.put_line( 'previous='||array(i-1) ); 13 end if; 14 15 --// can also use: if array.Exists(i+1) then 16 if (i+1) <= array.Count then 17 DBMS_OUTPUT.put_line( 'next='||array(i+1) ); 18 end if; 19 20 end loop; 21 end; 22 / *************** current=Tom next=Commander *************** current=Commander previous=Tom next=Harry *************** current=Harry previous=Commander next=Sally *************** current=Sally previous=Harry PL/SQL procedure successfully completed. SQL>The Exist() method is also one that is usually used with associative arrays. Here is an example of associative array. Note that the table is sorted according to the index value. And the index value is a string - not a sequential integer.
SQL> declare 2 type TStringArray is table of varchar2(10) index by varchar2(20); 3 array TStringArray; 4 i varchar2(20); 5 begin 6 array('Intel Officer') := 'Tom'; 7 array('Mission Lead') := 'Commander'; 8 array('Radio in Head') := 'Harry'; 9 array('Military Officer') := 'Sally'; 10 11 i := array.First(); 12 while array.Exists(i) loop 13 DBMS_OUTPUT.put_line( '***************' ); 14 DBMS_OUTPUT.put_line( 'current: '||i||'='||array(i) ); 15 16 if array.Exists( array.Prior(i) ) then 17 DBMS_OUTPUT.put_line( 'prior: '|| array.Prior(i) ); 18 end if; 19 20 if array.Exists( array.Next(i) ) then 21 DBMS_OUTPUT.put_line( 'next: '|| array.Next(i) ); 22 end if; 23 24 i := array.Next(i); 25 end loop; 26 end; 27 / *************** current: Intel Officer=Tom next: Military Officer *************** current: Military Officer=Sally prior: Intel Officer next: Mission Lead *************** current: Mission Lead=Commander prior: Military Officer next: Radio in Head *************** current: Radio in Head=Harry prior: Mission Lead PL/SQL procedure successfully completed. SQL> -
Bulk collect into a Table nested with Extend
Hi all
I want to get all the columns of the table emp and dept. So I use bulk collect into the concept of nested table.
*) I wrote the function in three different ways. EX: 1 and 2 (DM_NESTTAB_BULKCOLLECT_1 & DM_NESTTAB_BULKCOLLECT_2) does not give the desired result.
*) It only gives the columns of the EMP table. That means it takes DEPT & columns of the EMP table, but it only gives columns of table EMP.
) I think, there is something problem with nested table Extend.
) I want to know infested.
Can we use bulk collect into a table nested with extend?
If it is yes then fix the below codes (EX: 1 & EX: 2) and can you explain me please?
Codes are given below *.
CREATE OR REPLACE TYPE NEST_TAB IS TABLE OF THE VARCHAR2 (1000);
EX: 1:
----
-Bulk collect into a Table nested with Extend-
CREATE or replace FUNCTION DM_NESTTAB_BULKCOLLECT_1
RETURN NEST_TAB
AS
l_nesttab NEST_TAB: = NEST_TAB();
BEGIN
FOR tab_rec IN (SELECT table_name
From user_tables
WHERE table_name IN ('EMP', 'Department')) LOOP
l_nesttab.extend;
SELECT column_name
bulk collect INTO l_nesttab
Of user_tab_columns
WHERE table_name = tab_rec.table_name
ORDER BY column_id;
END LOOP;
RETURN l_nesttab;
EXCEPTION
WHILE OTHERS THEN
LIFT;
END DM_NESTTAB_BULKCOLLECT_1;
SELECT *.
TABLE (DM_NESTTAB_BULKCOLLECT_1);
OUTPUT:
-------
EMPNO
ENAME
JOB
MGR
HIREDATE
SAL
COMM
DEPTNO
* Only the EMP table columns are there in the nested table.
-----------------------------------------------------------------------------------------------------
EX: 2:
-----
-Bulk collect in the nested with Extend based on County - Table
CREATE or replace FUNCTION DM_NESTTAB_BULKCOLLECT_2
RETURN NEST_TAB
AS
l_nesttab NEST_TAB: = NEST_TAB();
v_col_cnt NUMBER;
BEGIN
FOR tab_rec IN (SELECT table_name
From user_tables
WHERE table_name IN ('EMP', 'Department')) LOOP
SELECT MAX (column_id)
IN v_col_cnt
Of user_tab_columns
WHERE table_name = tab_rec.table_name;
l_nesttab. Extend (v_col_cnt);
SELECT column_name
bulk collect INTO l_nesttab
Of user_tab_columns
WHERE table_name = tab_rec.table_name
ORDER BY column_id;
END LOOP;
RETURN l_nesttab;
EXCEPTION
WHILE OTHERS THEN
LIFT;
END DM_NESTTAB_BULKCOLLECT_2;
SELECT *.
TABLE (DM_NESTTAB_BULKCOLLECT_2);
OUTPUT:
-------
EMPNO
ENAME
JOB
MGR
HIREDATE
SAL
COMM
DEPTNO
* Only the EMP table columns are there in the nested table.
-------------------------------------------------------------------------------------------
EX: 3:
-----
-Collect in bulk in a nested Table to expand aid for loop.
CREATE or replace FUNCTION DM_NESTTAB_BULKCOLLECT_3
RETURN NEST_TAB
AS
l_nesttab NEST_TAB: = NEST_TAB();
TYPE local_nest_tab
THE VARCHAR2 ARRAY (1000);
l_localnesttab LOCAL_NEST_TAB: = LOCAL_NEST_TAB();
NUMBER x: = 1;
BEGIN
FOR tab_rec IN (SELECT table_name
From user_tables
WHERE table_name IN ('EMP', 'Department')) LOOP
SELECT column_name
bulk collect INTO l_localnesttab
Of user_tab_columns
WHERE table_name = tab_rec.table_name
ORDER BY column_id;
BECAUSE me IN 1.l_localnesttab. COUNTING LOOP
l_nesttab.extend;
L_NESTTAB (x): = L_LOCALNESTTAB (i);
x: = x + 1;
END LOOP;
END LOOP;
RETURN l_nesttab;
EXCEPTION
WHILE OTHERS THEN
LIFT;
END DM_NESTTAB_BULKCOLLECT_3;
SELECT *.
TABLE (DM_NESTTAB_BULKCOLLECT_3);
OUTPUT:
------
DEPTNO
DNAME
LOC
EMPNO
ENAME
JOB
MGR
HIREDATE
SAL
COMM
DEPTNO
* Now, I got the desired result set. DEP. and columns of the Emp Table are in the nested Table.
Thank you
AnnCOLLECTION BULK cannot add values to an existing collection. It can only crush.
-
Creating a table with a while loop
I want to create a table using a while loop but I don't know how to do it. Basically, I want to do the same thing as in the image of the example VI in LabVIEW VIs, called 'Graph XY Data Types.vi' example, but with a while loop instead of a for loop. The reason why I want to do with a while loop is because LabVIEW will not faint error or VISA data thanks to a for loop.
LabVIEW certainly enable you to pass out a mistake or VISA through a loop for. The default value is autoindex output and thus creating a table but is a simple right-click on the tunnel exit to change that. For recent versions, it changes the Tunnel mode to "last value". You can also use a shift register.
-
help join you a table nested with ordinary table
IM creating a nested table object prtcnpt_info codelist. In a block anonymous im saying t_code as type nested table codelist.
Now when I try to join the table nested to ordinary table oracle DB and I get the error: PL/SQL: ORA-00904: "COLUMN_VALUE": invalid identifier.
Please help me on this and provide link tutorial about this concepts... Here is the code I wrote
-Start code.
create or replace type prtcnpt_info as an object (identification number
, name varchar2 (200)
(, code varchar2 (30));
create type codelist is the prtcnpt_info table;
declare
t_code codelist.
Start
Select prtcnpt_info (b.pid, b.name, pt.code) in bulk collect into t_code
party pt
mc_code b
where pt.cd in ("AAA", "BBB")
and pt.ptype_id = b.pt_type_id;
INSERT INTO table (ID
RUN_ID
DATA
P_ID
)
SELECT id
run_id
data
prtct.id-> 1
IN table_2 t2
, (by selecting column_value in table (t_code)) prtct
WHERE prtct.id = t2. P_ID; -> 2
end;
-End code;
also of the anonymous block
1 = > is this right until you get the id value (b.pid) of the tablet_code nested as prtct alias?
2 = > is this right until you reach the nested with ordinary table table? I want to join the id column in the tables.
Published by: 914912 on April 30, 2012 02:11Write the insert like this and try
insert into table ( id , run_id , data , p_id ) select id, run_id, data, prtct.id from table_2 t2 table(t_code) prtct where prtct.id = t2.p_id; -
Save several bays of nested loops
Hello
My vi generates several bays in each iteration of the loop, and I would like to save the data. I did work with the files before recording, but it's never with nested loops. I don't know how to keep the information of the iteration of one loop at the other. I would like suggestions. I made this sample & simple vi (attached file) that simulates the question I have. I have a file with a time column and different columns of food beside him.
The first question I have is that I generate the time table only once, but a table of signal several times, so how can I keep the time table to drop several times? The other question, as stated above, saves the data in the table signal getting lost in the nested loops...
Thank you
A
1. the first element of the first matrix signal IS always zero. The Signal to simulate always starts at zero. You compare it to the indicator of "first date". Who got by converting the dynamic data type to a scalar. And it's always the last element of the actual data. And since the "first out" is replaced with each iteration of the inner loop, the number you see at the end is actually the latest iteration of the data. Look at "First release" in comparison with the last element of your last column of the table and you will see they are the same.
2. the reason why you have a first column that consists of the steps is because that's what you have wired to initialize the shift register. If you look at my example, you will see that I have an empty array. (The zero is gray.) You, the 0 is not dimmed meaning there is an element. Expand this table to view more items and expand the digital field and you will see more digits. They correspond to what is in your first column.
-
use OPT_ESTIMATE or CARDINALITY tip for correct estimation of nested loops
I'm using Oracle 11.2.0.3. Below the execution below plan, how can I use tip OPT_ESTIMATE or CARDINALITY to teach optimization E-lines for ID 9 (Nested Loop) 30553 instead of 6.
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | | 4604 (100)| | 30553 |00:00:02.56 | 208K| | | | | 1 | SORT ORDER BY | | 1 | 6 | 7044 | 4604 (1)| 00:01:05 | 30553 |00:00:02.56 | 208K| 41M| 2086K| 36M (0)| |* 2 | HASH JOIN OUTER | | 1 | 6 | 7044 | 4603 (1)| 00:01:05 | 30553 |00:00:02.10 | 208K| 38M| 3120K| 39M (0)| |* 3 | HASH JOIN OUTER | | 1 | 6 | 6870 | 4599 (1)| 00:01:05 | 30553 |00:00:01.97 | 208K| 38M| 3120K| 39M (0)| |* 4 | HASH JOIN OUTER | | 1 | 6 | 6744 | 4591 (1)| 00:01:05 | 30553 |00:00:01.85 | 208K| 37M| 3121K| 39M (0)| |* 5 | HASH JOIN OUTER | | 1 | 6 | 6570 | 4584 (1)| 00:01:05 | 30553 |00:00:01.74 | 208K| 37M| 3121K| 38M (0)| |* 6 | HASH JOIN OUTER | | 1 | 6 | 6414 | 4576 (1)| 00:01:05 | 30553 |00:00:01.60 | 208K| 37M| 3121K| 38M (0)| | 7 | NESTED LOOPS | | 1 | | | | | 30553 |00:00:01.44 | 208K| | | | | 8 | NESTED LOOPS | | 1 | 6 | 6318 | 4572 (1)| 00:01:05 | 30553 |00:00:01.31 | 182K| | | | | 9 | NESTED LOOPS | | 1 | 6 | 1830 | 4568 (1)| 00:01:04 | 30553 |00:00:01.11 | 124K| | | | |* 10 | HASH JOIN | | 1 | 2069 | 270K| 2499 (1)| 00:00:35 | 30646 |00:00:00.46 | 23738 | 6539K| 2033K| 7965K (0)| |* 11 | TABLE ACCESS BY INDEX ROWID | DSCLR | 1 | 5079 | 158K| 533 (1)| 00:00:08 | 91395 |00:00:00.28 | 6460 | | | | | 12 | BITMAP CONVERSION TO ROWIDS | | 1 | | | | | 197K|00:00:00.16 | 615 | | | | | 13 | BITMAP AND | | 1 | | | | | 4 |00:00:00.14 | 615 | | | | | 14 | BITMAP OR | | 1 | | | | | 4 |00:00:00.07 | 276 | | | | | 15 | BITMAP CONVERSION FROM ROWIDS| | 1 | | | | | 2 |00:00:00.02 | 69 | | | | |* 16 | INDEX RANGE SCAN | XIF913DSCLR | 1 | 274K| | 14 (0)| 00:00:01 | 68407 |00:00:00.01 | 69 | | | | | 17 | BITMAP CONVERSION FROM ROWIDS| | 1 | | | | | 4 |00:00:00.05 | 207 | | | | |* 18 | INDEX RANGE SCAN | XIF913DSCLR | 1 | 274K| | 42 (0)| 00:00:01 | 209K|00:00:00.03 | 207 | | | | | 19 | BITMAP CONVERSION FROM ROWIDS | | 1 | | | | | 5 |00:00:00.06 | 339 | | | | |* 20 | INDEX RANGE SCAN | XIF910DSCLR | 1 | 274K| | 67 (0)| 00:00:01 | 239K|00:00:00.04 | 339 | | | | | 21 | NESTED LOOPS | | 1 | | | | | 21749 |00:00:00.10 | 17278 | | | | | 22 | NESTED LOOPS | | 1 | 3404 | 339K| 1965 (1)| 00:00:28 | 22772 |00:00:00.03 | 1246 | | | | | 23 | TABLE ACCESS FULL | TMP_RPT_BD_STATE_DATA_DWNLD | 1 | 3255 | 257K| 11 (0)| 00:00:01 | 3255 |00:00:00.01 | 27 | | | | |* 24 | INDEX RANGE SCAN | XIE2OCRN | 3255 | 7 | | 1 (0)| 00:00:01 | 22772 |00:00:00.03 | 1219 | | | | |* 25 | TABLE ACCESS BY INDEX ROWID | OCRN | 22772 | 1 | 21 | 1 (0)| 00:00:01 | 21749 |00:00:00.06 | 16032 | | | | |* 26 | VIEW PUSHED PREDICATE | | 30646 | 1 | 171 | 1 (0)| 00:00:01 | 30553 |00:00:00.63 | 101K| | | | | 27 | WINDOW BUFFER | | 30646 | 1 | 21 | 1 (0)| 00:00:01 | 46946 |00:00:00.59 | 101K| 2048 | 2048 | 2048 (0)| |* 28 | TABLE ACCESS BY INDEX ROWID | DSCLR_FLNG | 30646 | 1 | 21 | 1 (0)| 00:00:01 | 46946 |00:00:00.32 | 101K| | | | |* 29 | INDEX RANGE SCAN | XIE1DSCLR_FLNG | 30646 | 2 | | 1 (0)| 00:00:01 | 46946 |00:00:00.21 | 59862 | | | | |* 30 | INDEX RANGE SCAN | XPKH760_RGLTY_ACTN_DSCLR | 30553 | 1 | | 1 (0)| 00:00:01 | 30553 |00:00:00.18 | 57541 | | | | | 31 | TABLE ACCESS BY INDEX ROWID | H760_RGLTY_ACTN_DSCLR | 30553 | 1 | 748 | 1 (0)| 00:00:01 | 30553 |00:00:00.11 | 26218 | | | | | 32 | TABLE ACCESS FULL | DSCLR_ST_TYPE_TBL | 1 | 4 | 64 | 4 (0)| 00:00:01 | 4 |00:00:00.01 | 5 | | | | | 33 | TABLE ACCESS FULL | RGLTY_RSLTN_TYPE_TBL | 1 | 12 | 312 | 7 (0)| 00:00:01 | 12 |00:00:00.01 | 10 | | | | | 34 | TABLE ACCESS FULL | INTTR_TYPE_TBL | 1 | 14 | 406 | 7 (0)| 00:00:01 | 14 |00:00:00.01 | 10 | | | | | 35 | TABLE ACCESS FULL | SNCTN_TYPE_TBL | 1 | 15 | 315 | 7 (0)| 00:00:01 | 15 |00:00:00.01 | 10 | | | | | 36 | TABLE ACCESS FULL | PRDCT_TYPE_TBL | 1 | 25 | 725 | 4 (0)| 00:00:01 | 25 |00:00:00.01 | 5 | | | | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Query Block Name / Object Alias (identified by operation id): ------------------------------------------------------------- 1 - SEL$A8B7A3F4 11 - SEL$A8B7A3F4 / D@SEL$13 23 - SEL$A8B7A3F4 / OH@SEL$1 24 - SEL$A8B7A3F4 / O@SEL$13 25 - SEL$A8B7A3F4 / O@SEL$13 26 - SEL$13512960 / DF@SEL$13 27 - SEL$13512960 28 - SEL$13512960 / DF1@SEL$14 29 - SEL$13512960 / DF1@SEL$14 30 - SEL$A8B7A3F4 / H7@SEL$2 31 - SEL$A8B7A3F4 / H7@SEL$2 32 - SEL$A8B7A3F4 / DS@SEL$9 33 - SEL$A8B7A3F4 / RST@SEL$11 34 - SEL$A8B7A3F4 / ITT@SEL$3 35 - SEL$A8B7A3F4 / ST@SEL$5 36 - SEL$A8B7A3F4 / PT@SEL$7 Outline Data ------------- /*+ BEGIN_OUTLINE_DATA IGNORE_OPTIM_EMBEDDED_HINTS OPTIMIZER_FEATURES_ENABLE('11.2.0.3') DB_VERSION('11.2.0.3') OPT_PARAM('optimizer_index_cost_adj' 20) ALL_ROWS OUTLINE_LEAF(@"SEL$13512960") PUSH_PRED(@"SEL$A8B7A3F4" "DF"@"SEL$13" 11) OUTLINE_LEAF(@"SEL$A8B7A3F4") ELIMINATE_JOIN(@"SEL$2D47CDEA" "DTT"@"SEL$13") OUTLINE(@"SEL$14") OUTLINE(@"SEL$A8B7A3F4") ELIMINATE_JOIN(@"SEL$2D47CDEA" "DTT"@"SEL$13") OUTLINE(@"SEL$2D47CDEA") MERGE(@"SEL$3FAACB6D") OUTLINE(@"SEL$15") OUTLINE(@"SEL$3FAACB6D") MERGE(@"SEL$11") MERGE(@"SEL$A1A6E401") OUTLINE(@"SEL$12") OUTLINE(@"SEL$11") OUTLINE(@"SEL$A1A6E401") MERGE(@"SEL$9") MERGE(@"SEL$BFB1842A") OUTLINE(@"SEL$10") OUTLINE(@"SEL$9") OUTLINE(@"SEL$BFB1842A") MERGE(@"SEL$7") MERGE(@"SEL$EEDE2B8C") OUTLINE(@"SEL$8") OUTLINE(@"SEL$7") OUTLINE(@"SEL$EEDE2B8C") MERGE(@"SEL$5") MERGE(@"SEL$A6B38458") OUTLINE(@"SEL$6") OUTLINE(@"SEL$5") OUTLINE(@"SEL$A6B38458") MERGE(@"SEL$171BE69E") MERGE(@"SEL$3") OUTLINE(@"SEL$4") OUTLINE(@"SEL$171BE69E") MERGE(@"SEL$AF02BF1E") OUTLINE(@"SEL$3") OUTLINE(@"SEL$2") OUTLINE(@"SEL$AF02BF1E") MERGE(@"SEL$13") OUTLINE(@"SEL$1") OUTLINE(@"SEL$13") FULL(@"SEL$A8B7A3F4" "OH"@"SEL$1") INDEX(@"SEL$A8B7A3F4" "O"@"SEL$13" ("OCRN"."ORG_PK" "OCRN"."DSCLR_DSCLB_FL" "OCRN"."DSCLR_RPTBL_FL")) BITMAP_TREE(@"SEL$A8B7A3F4" "D"@"SEL$13" AND(OR(1 1 ("DSCLR"."FORM_TYPE_CD") 2 ("DSCLR"."FORM_TYPE_CD")) ("DSCLR"."DSCLR_TYPE_CD"))) NO_ACCESS(@"SEL$A8B7A3F4" "DF"@"SEL$13") INDEX(@"SEL$A8B7A3F4" "H7"@"SEL$2" ("H760_RGLTY_ACTN_DSCLR"."FLNG_PK" "H760_RGLTY_ACTN_DSCLR"."DSCLR_PK" "H760_RGLTY_ACTN_DSCLR"."REC_SEQ_NB")) FULL(@"SEL$A8B7A3F4" "DS"@"SEL$9") FULL(@"SEL$A8B7A3F4" "RST"@"SEL$11") FULL(@"SEL$A8B7A3F4" "ITT"@"SEL$3") FULL(@"SEL$A8B7A3F4" "ST"@"SEL$5") FULL(@"SEL$A8B7A3F4" "PT"@"SEL$7") LEADING(@"SEL$A8B7A3F4" "OH"@"SEL$1" "O"@"SEL$13" "D"@"SEL$13" "DF"@"SEL$13" "H7"@"SEL$2" "DS"@"SEL$9" "RST"@"SEL$11" "ITT"@"SEL$3" "ST"@"SEL$5" "PT"@"SEL$7") USE_NL(@"SEL$A8B7A3F4" "O"@"SEL$13") NLJ_BATCHING(@"SEL$A8B7A3F4" "O"@"SEL$13") USE_HASH(@"SEL$A8B7A3F4" "D"@"SEL$13") USE_NL(@"SEL$A8B7A3F4" "DF"@"SEL$13") USE_NL(@"SEL$A8B7A3F4" "H7"@"SEL$2") NLJ_BATCHING(@"SEL$A8B7A3F4" "H7"@"SEL$2") USE_HASH(@"SEL$A8B7A3F4" "DS"@"SEL$9") USE_HASH(@"SEL$A8B7A3F4" "RST"@"SEL$11") USE_HASH(@"SEL$A8B7A3F4" "ITT"@"SEL$3") USE_HASH(@"SEL$A8B7A3F4" "ST"@"SEL$5") USE_HASH(@"SEL$A8B7A3F4" "PT"@"SEL$7") SWAP_JOIN_INPUTS(@"SEL$A8B7A3F4" "D"@"SEL$13") INDEX_RS_ASC(@"SEL$13512960" "DF1"@"SEL$14" ("DSCLR_FLNG"."DSCLR_PK" "DSCLR_FLNG"."BLLBL_FL")) END_OUTLINE_DATA */This plan gives you an idea of why your initial synchronization has been long - most of your readings are one-piece readings and you have read 53 724 blocks. If you estimate 1 centisecond by read (which could be on a reasonable charge system) then it is 537 seconds. to 5 milliseconds per read, it's still 268 seconds or 4 minutes and 30 seconds.
A quick break down of some (the worst case) potential time - only you can say whether or not some of these readings will be always/often/never being cached in the file or at the SAN level.
Line 11 - physical reads 6 400 done - it's a tree bitmap then the readings are in the order of physical table with no. rereads. Call 5ms by read-online 32 seconds. L
| * 11 | TABLE ACCESS BY INDEX ROWID | DSCLR | 1. 5079. 158K | 533 (1) | 00:00:08 | 91395 | 00:00:01.27 | 6460. 6400 | | | |
The hash join takes us from 6 400 to 11 788 because it joins, lines 21 to 25 (nested loop) in which most of the work is the random access table with some automatic caching: 26 seconds. Do a search here rather than indexed 22 000 access? Which would be faster, which would charge less.
| * 25. TABLE ACCESS BY INDEX ROWID | OCRN | 22050. 1. 21. 1 (0) | 00:00:01 | 21059 | 00:01:04.74 | 15634 | 5280. | | |
Three nested loops that introduce more readings:
11788 9-> 26386:14 600 of the predicate view pushed which some lies but a very large index and a table of random access 73 seconds
8 26386-> 33783:7 400 index line 30 - big clue about 37 seconds Access hides
33783 7-> 53691:19 900 31 table access - large table line, not much caching, 100 seconds.
In each case, you can ask if an analysis would take less time than all of these random reads.
NOTE - all I'm pointing our here where you potentially use a lot of time so that you can ask whether or not you should do little of the query in this way, or if there is an alternative, or if the work you're doing is absolutely necessary. If you want to optimize the query you should consider the intent of the query and think your way through a reasonable join order to see if you can imagine an effective way to get the same data. I have written a few articles and presentation on an approach that begins by drawing - here is a link to an article I wrote for a group of SQL Server: https://www.simple-talk.com/sql/performance/designing-efficient-sql-a-visual-approach/
and a video I did with Kyle Hailey, while he was working for Embarcadero:Tune in for the ultimate SQL Tune-off | Landing pages
Concerning
Jonathan Lewis
-
Help to find the best way to interior design (Nested Loops of sliders?)
Oracle 11G
First here the table I work with, for example data
ID FID ANNOTATION DESIGNATION LOW HIGH SEQ 1 1008755360 FC1053, 81-82 FC1053 81 82 1 2 1008755360 XD, 3-24 XD 3 24 2 3 1008756293 FC1053, 81-82 FC1053 81 82 1 4 1008756293 XD, 3-24 XD 3 24 2 Each FID is a different line, these two lines are connected physically, that's why I've shown them here on the table. Each line has a 'meter', in this case, each line has 2 lines of account that are the same.

From there, we can say that FC1053, 81 and 82 are connected between the 2 cables. XD DESIGNATION means that cables are connect not really so I can't ignore those.
We have a different way to show that they connect other than only those data and I need to connect each other too much. For this I need the Info
FID1 LOW HIGH FID2 1008755360 81 82 1008756293 So my first design was the hepatitis hase sliders 2 with the data in the table, as shown above. I would then have a nested loop. The first slider to select the first record, then go down to the second loop where I compare all other records the first record and then go back in the outer loop to move to the next record, then return once again to the inner loop to compare the values again.
LOOP1
LOOP 2
If LOOP1. IDF! LOOP2 =. IDF THEN
IF LOOP1. ANNOTATION = LOOP2. ANNOTATION THEN
-CONNECT THE DATA
ON THE OTHER
IF LOOP1. DESCRIPTION = LOOP2. DESIGNATION THEN
IF LOOP2. LOW BETWEEN LOOP1. LOW AND LOOP1. THEN HIGH
IF LOOP2. HIGH BETWEEN LOOP1. LOW AND LOOP1. HGH THEN
-CONNECT THE DATA
END IF;
END IF;
END IF;
END IF;
END IF;
END LOOP;
-Open and close done to reset the cursor to the front/top
CLOSE CURSOR LOOP2;
OPEN CURSOR LOOP2
END LOOP;
The problem with this approach is once the outside loop moves the next value of the IDF, that logic will connect them once again, but this time with the FIDs reverse which is essentially the same thing as it does not matter the direction in which they are connected. I almost feel that once I found the link I need to remove that line from the cursor (which isn't possible).
FID1 LOW HIGH FID2 1008755360 81 82 1008756293 1008756293 81 82 1008755360 I was able to
1. make a list of all those I have connected and check against that
2 use some kind of collection
3. use a temporary table to hold the data
4 something that I have not yet thought
I really appreciate in advance for any help I get.
If your query mapping is correct, this is the result of your query with the addition of the values of sum for the strand/down running. Manually change the incorrect in the output bit numbers so that we can move on to find another solution.
with gc_count like)
Select
Sum(current_high-current_low+1) on strand_high (g3e_fid seq order partition),
Sum(current_high-current_low+1) more (partition of g3e_fid order of seq).
strand_low (current_high-current_low),
t.* from b$ gc_count t
)
Select
a.g3e_fid, a.current_designation, a.current_low, a.current_high, a.strand_high, a.strand_low,
b.g3e_fid, b.current_designation, b.current_low, b.current_high, b.strand_high, b.strand_low
gc_count a, gc_count b
where a.g3e_fid in (1008757155,1008757159,1009999655)
and in b.g3e_fid (1008757155,1008757159,1009999655)
and a.g3e_fid > b.g3e_fid
and ((a.count_annotation = b.count_annotation)
or (a.current_designation = b.current_designation
and a.current_low b.current_low and b.current_high and a.current_high between b.current_low and b.current_high)
order of b.seq
/
G3E_FID CURRENT_DESIGNATION CURRENT_LOW CURRENT_HIGH STRAND_HIGH STRAND_LOW G3E_FID CURRENT_DESIGNATION CURRENT_LOW CURRENT_HIGH STRAND_HIGH STRAND_LOW
---------- --------------------- ----------- ------------ ----------- ---------- ---------- --------------------- ----------- ------------ ----------- ----------
GAGA GAGA 1008757159 1008757155 1 1 2 2 1 2 2 1
1008757159 3 8 8 3 1008757155 3 8 8 3 F1DM F1DM
1008757159 9 10 10 9 1008757155 9 10 10 9 F2 F2
1008757159 11 14 14 11 1008757155 11 14 14 11 F1DM F1DM
1009999655 17 18 6 5 1008757155 15 18 18 15 F2 F2
1008757159 15 16 16 15 1008757155 15 18 18 15 F2 F2
1009999655 21 24 4 1 1008757155 21 24 24 21 F2 F2
7 selected lines.
Elapsed time: 00:00:00.06
-
Not the same State (<>) of nested loops
Hi gurus and Experts.
I need advice/suggestion on the query plan below. This plan is go for Nested Loops, am not able to force to go to the hash join or Merge Join with tips.
Can someone help me please what is happening, and it is possible to escape from nested loops.
I don't want to take the help of index for this scenario.
D/B: Oracle 11 g 2,
create table parent as with main as (select --+materialize round(dbms_random.value(low=>1,high=>100)) SAMPLE_ID,dbms_random.string(opt=>'U',len=>10) SAMPLE_TEXT,rownum id from dual connect by level<=100000) select sample_id,rpad(sample_text,10,'*') padding,sample_text,id from main order by idcreate table child as with main as (select --+materialize round(dbms_random.value(low=>1,high=>100)) SAMPLE_ID,dbms_random.string(opt=>'U',len=>10) SAMPLE_TEXT,rownum id from dual connect by level<=10000) select sample_id,rpad(sample_text,10,'*') padding,sample_text,id from main order by idselect --+use_hash(p c) p.id from parent p,child c where p.id<>c.idPlan SELECT STATEMENT ALL_ROWSCost: 973,076 Bytes: 8,999,910,000 Cardinality: 999,990,000 3 NESTED LOOPS Cost: 973,076 Bytes: 8,999,910,000 Cardinality: 999,990,000 1 TABLE ACCESS FULL TABLE APP.CHILD Cost: 12 Bytes: 40,000 Cardinality: 10,000 2 TABLE ACCESS FULL TABLE APP.PARENT Cost: 97 Bytes: 499,995 Cardinality: 99,999902629 wrote:
I need advice/suggestion on the query plan below. This plan is go for Nested Loops, am not able to force to go to the hash join or Merge Join with tips.
You will not be able to use a hash join
http://docs.Oracle.com/CD/E11882_01/server.112/e16638/optimops.htm#i36043
>
The optimizer uses hash join to join two tables if they are added by using an equijoin and if one of the following conditions are met:
>You may be able to force a sort merge join, it does not mention if different will work, I don't see how it would be
http://docs.Oracle.com/CD/E11882_01/server.112/e16638/optimops.htm#i49183
>
Sort merge joins are useful when the join condition between two tables is a condition of inequality such as <,> <=,>, or > =. Fusion type joints are more successful than joins loops nested for large sets of data. You cannot use hash joins unless there is a condition of equality.
>I can't imagine this treatment an antijoin more efficiently than nested If loops.
-
Hello
A fundamental question about Nested Loops, what is the number of rows in the inner table means (4 in this example)? This is the average number of lines that oracle had to read by loop?
Thank you.
SYS> SHOW PARAMETER optimizer_features_enable NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ optimizer_features_enable string 11.2.0.1 HR> EXEC DBMS_STATS.GATHER_TABLE_STATS (USER , 'EMPLOYEES' , CASCADE => TRUE ) PL/SQL procedure successfully completed. HR> EXEC DBMS_STATS.GATHER_TABLE_STATS (USER , 'DEPARTMENTS' , CASCADE => TRUE ) PL/SQL procedure successfully completed. HR> SELECT COUNT(*) FROM employees ; COUNT(*) ---------- 107 HR> SELECT COUNT(*) FROM departments ; COUNT(*) ---------- 27 SELECT /*+ USE_NL(e d) */ e.last_name , d.department_name FROM employees e , departments d WHERE e.department_id = d.department_id; Execution Plan ---------------------------------------------------------- Plan hash value: 2968905875 ------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost | ------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 106 | 2862 | 24 | | 1 | NESTED LOOPS | | 106 | 2862 | 24 | | 2 | TABLE ACCESS FULL| DEPARTMENTS | 27 | 432 | 2 | |* 3 | TABLE ACCESS FULL| EMPLOYEES | *4* | 44 | 1 | ------------------------------------------------------------------Hello
A fundamental question about Nested Loops, what is the number of rows in the inner table means (4 in this example)? This is the average number of lines that oracle had to read by loop?
Hello
in fact, it's exactly what it is, with the exception of is not the true Oracle number was read, it is an estimate.
You can track 10053 and see how the optimizer reach these numbers. The optimizer calculates the cardinality of the join using the following formula:
cardinality (employees) * *(join selectivity) cardinality (departments).
and join selectivity is essentially 1/greater (num_distinct (departments.department_id), (departments.department_id) num_distinct), adjusted for null values (not NULL values in this particular case, so no adjustment is necessary).
If you plug the values you get for the cardinality of the join:
107 * 27 * join selectivity, which join selectivity = 1/greater(11, 27) = 1/27 = 0.036691, so 107 * 27 * 0.036 ~ = 106.
4 comes from this number by dividing the cardinality expected join (106) by the estimated number of iterations of the nested loop (27).
It is not true the optimizer assumes an even distribution here - if it did, then it should get to 11 employees by Department, not 4 (because num_distinct (employees.department_id) = 11, not 4).
If you are interested in these issues, please refer to the excellent book by Jonathan Lewis "Cost based fundamentals", is all explained quite well in there.
Best regards
Nikolai -
We never seen anything like this?
I wrote 2 nested loops at the end of which an object is added to a table.
But for some reason, when everything is done, all objects in the table are exactly the same, it has mutiple, but they all have the same values and the reference number... I'm really confused as to why this would happen, I must have it over a thousand times and never seen anywhere else. I got the other guy that flex look as well... and he did not see why either, in fact he said that he «did more than a thousand times...» "And you get the picture.
Here's my segment of the loop if anyone can see why this happens please tell me. Thank you.
It's the Flex 3 version:
------------------------------------------------------------------
to loop through the grid
var i: int = 0
for (i = 0; i < gridData.length; i ++) {}
loop if date of deliverables and enter values where they exist for each project or line of gridData
var gTemp:Object = Object (gridData.getItemAt (i)); //gridDataVO
var j: int = 0;
for (j = 0; j < tempQueue.length; j ++) {//loop through tempQueue, holds deliverables }
var qTemp:Object = Object (tempQueue.getItemAt (j));
inspect all deliverables for each project line and create a new object and push in table.
var s:string = ce . parentApplication.mGrid.elGetAppName (qTemp.eventID); //This function retrieves just the value of appfield
if (gTemp [s] == null | gTemp [s] .length == 0) {}
qTemp =
null ; //do nothing
}
else {
qTemp.projectID = gTemp.pdNO;
qTemp.dueDate = gTemp [s];
workQueue.addItem (qTemp);
qTemp =
null ;
}
//
}
for
gTemp =
null ;
}
for outdoor
----------------------------------------------------------------------
essentially the collection of table leader ends with still objects when this is done.
While tempqueue was already the same object?
-
Partition pruning, nested loops
Hello
I'm having a problem with obtaining the size of partition in a query. I managed to dumb down the problem to the two tables and a minimum query (see below).
Basically I have a partitioned table "Made each year" and a table of assistance 'Current year' that contain always 1 row. The sole purpose of this line is to say which is the year curent, it was the previous year and that next year will be. (In the real problem, there is no standard timeperiods, so we can't calculate just previous and next by adding/subtraction 1 as would be possible in this example).
The following query is executed as I want.
It runs a scan on current_year and then nested loop on the facts. And the size of the partition that was happening.
The following query is where I have my problem.select sum(decode(a.year_key, b.curr_year, some_measure)) as curr_year_measure from yearly_fact_t a ,current_year b where a.year_key = b.curr_year; ------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | ------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | 39 | 4 (0)| 00:00:01 | | | | 1 | SORT AGGREGATE | | 1 | 39 | | | | | | 2 | NESTED LOOPS | | 1 | 39 | 4 (0)| 00:00:01 | | | | 3 | INDEX FAST FULL SCAN | SYS_C00247890 | 1 | 13 | 2 (0)| 00:00:01 | | | | 4 | PARTITION RANGE ITERATOR| | 1 | 26 | 2 (0)| 00:00:01 | KEY | KEY | |* 5 | TABLE ACCESS FULL | YEARLY_FACT_T | 1 | 26 | 2 (0)| 00:00:01 | KEY | KEY | ------------------------------------------------------------------------------------------------------------ Predicate Information (identified by operation id): --------------------------------------------------- 5 - filter("A"."YEAR_KEY"="B"."CURR_YEAR")
The xplan base is the same, but for some reason any cbo abandoned and decide to analyze all the partitions, which was not highly scalable data on production :)
I would have thought that the plan would be the same.
select sum(decode(a.year_key, b.curr_year, some_measure)) as curr_year_measure ,sum(decode(a.year_key, b.prev_year, some_measure)) as prev_year_measure from yearly_fact_t a ,current_year b where a.year_key = b.curr_year or a.year_key = b.prev_year; ------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | ------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 52 | 13 (0)| 00:00:01 | | | | 1 | SORT AGGREGATE | | 1 | 52 | | | | | | 2 | NESTED LOOPS | | 4 | 208 | 13 (0)| 00:00:01 | | | | 3 | TABLE ACCESS FULL | CURRENT_YEAR | 1 | 26 | 4 (0)| 00:00:01 | | | | 4 | PARTITION RANGE ALL| | 4 | 104 | 9 (0)| 00:00:01 | 1 | 6 | |* 5 | TABLE ACCESS FULL | YEARLY_FACT_T | 4 | 104 | 9 (0)| 00:00:01 | 1 | 6 | ------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 5 - filter("A"."YEAR_KEY"="B"."CURR_YEAR" OR "A"."YEAR_KEY"="B"."PREV_YEAR")
What can I do to get the size of partition that you want to occur in the second query?-- drop table yearly_fact_t purge; -- drop table current_year purge; create table current_year( curr_year number(4) not null ,prev_year number(4) not null ,next_year number(4) not null ,primary key(curr_year) ,unique(prev_year) ,unique(next_year) ); insert into current_year(curr_year, prev_year, next_year) values(2010, 2009, 2011); commit; create table yearly_fact_t( year_key number(4) not null ,some_dim_key number not null ,some_measure number not null ) partition by range(year_key)( partition p2007 values less than(2008) ,partition p2008 values less than(2009) ,partition p2009 values less than(2010) ,partition p2010 values less than(2011) ,partition p2011 values less than(2012) ,partition pmax values less than(maxvalue) ); insert into yearly_fact_t(year_key, some_dim_key, some_measure) values(2007,1, 10); insert into yearly_fact_t(year_key, some_dim_key, some_measure) values(2008,1, 20); insert into yearly_fact_t(year_key, some_dim_key, some_measure) values(2009,1, 30); insert into yearly_fact_t(year_key, some_dim_key, some_measure) values(2010,1, 40); commit;
Or better yet, what is it in my query that prevents it from happening?
We do not have Oracle Database 10 g Enterprise Edition Release 10.2.0.4.0 - 64 bit.
Best regards
RonnieI think that the decision of condition influenced gold optimizer. You can rewrite your query to use UNION ALL to see if it helps.
select sum(decode(year_key, curr_year, some_measure)) as curr_year_measure ,sum(decode(year_key, prev_year, some_measure)) as prev_year_measure from (select a.year_key, b.curr_year, some_measure from yearly_fact_t a ,current_year b where a.year_key = b.curr_year UNION ALL select a.year_key, b.curr_year, some_measure from yearly_fact_t a ,current_year b where a.year_key = b.prev_year);Published by: user503699 on February 17, 2010 14:59
-
Producer consumer with the third loop model
Hello everyone and thank you for looking at this.
I have a problem that I thought for a while now on the execution of a third loop in a design model of producer consumer (with events).
I use this type of model for a UI and am happy with how it works. However if I want to add a continuis loop model to test for example how can I control the loop?
In my example (see table), I use a local variable to run them (or stop) the test and the same to close the application.
I don't know why, but this feels wrong to me. Is there a better way?
Thanks in advance
Chuck
Nickelback says:
Is the problem with the consumer loop only runs when it receives a message from producer loops event.
Nothing says that you can't have a consumer loop enqueue States to itself. Of course, this is more in a State Machine in queue with the possibility for another loop to the States of the queue.
-
Why the execution time increases with a while loop, but not with "run continuously?
Hi all
I have a problem of severe weather that I don't know how to fix it because I don't know exactly where it comes from.
I order two RF switches via a data acquisition card (NI USB-6008). One job at the same time can be selected on each switch. Basically, the VI created for this feature (by a colleague) resets all the outputs of acquisition data and active then those desired. It has three entrances, two chain simp0le controls and a cluster table, that contains the list of all the outputs and some practical information to know what is connected (specific to my application).
I use this VI in a complex application, and I have some problems with the execution time, which increased whenever I said the VI, so I did a test VI (TimeTesting.vi) to determine where the problem came. In this special VI I record the execution time in a csv file to analyze then with excel.
After several tries, I found that if I run this criterion VI with the while loop, execution on every cycle time increases, but if I remove the while loop and use the funtionnality "Continuous run", the execution time remains the same. In my high level application, I have while loops and events, and so the runtime increases too.
I someone could explain to me why execution time increases and how can we avoid this? I have attached my VI test and the necessary subVIs, as well as an image of a graph that shows the execution time with a while loop and «run permanently»
Thanks a lot for your help!
Your SetReset_DO VI creates a channel whenever it is called. And that you never delete a task.
When running continuously, that it's as if it only runs once and LabVIEW has internal mechanisms to close references that will not be used again. When a VI is used as a Subvi, LV does not know if she will be called again, and lacks these things until the first level VI stops. You have a memory leak.
Just as you open and close your file outside the loop for, create your channel out of the loop.
Lynn
-
help with table in spreadsheet string
Hello
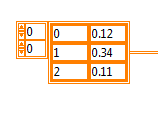
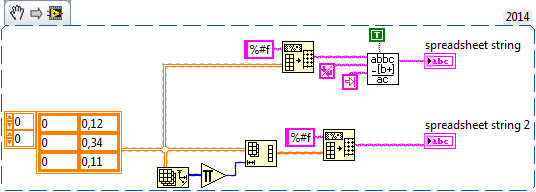
I need assistance to format my 2D in a string table.
I have a 2D DBL like this chart:
and I want it in a format string like this "0.12 0, 1 0.34, 2 0.11.
Line 0 pass 0 0 Col 1
Row line 1 Col 0 line 1 Col 1 line 2, column 0 line 2 Col 1... and so on Is this feasible with 'Table to a spreadsheet string' function or do I have to use a loop for format in this way?
Thank you
Ritesh
Here are 2 ways to do it without loop.
Ben64
EDIT: just realized, you want a comma to separate lines, and replace the tab with a comma in solution 1. (2 will not work in this case)

Maybe you are looking for
-
How do I allow a pop-up from a trusted site IE chat from my internet provider Help Center?
I need help with a problem with Shaw.ca- my internet provider. They have a chat online Help Center which I can't access because Firefox is blocing their popup. I can't find anything about him on my computer but I'm not very computer literate. I can't
-
PROTECTED Z930 Power adapter, flashing
The power adapter light flashes in orange and I can't turn on my laptop. It seems to blink 7 times and then 1 time before a long pause. Any ideas on how to get the laptop on again?
-
HP pavilion 2305tx g6: drver problem intel graphichs
in my pc hp laptop pavilion g6 2305tx @ windows 7 ultimate x 64 bit my intel hd graphichs 4000 drver install it says your pc lacks the minimum requirement to install the driver. I t has worked before you reinstall windows. http://support.HP.com/us-en
-
OUTLOOK EXPRESS 'out going mail' gets stuck and it then sends 3 to 5 times
OUTLOOK EXPRESS e-mail. When an email is sent, it goes to the Outbox and remains. Later he was sent to the recipients up to 4 times. It remains in the Outbox.
-
Vista not loading - just get a white screen with the mouse pointer
Hi using Vista for a while now, 4 years, no probs real. Then two days the PC crashes, and trying to restart the option repair (recommended) came, or start Windows normally, selected repair option, opens Windows screen, then a mouse pointer and that