Avoid blank lines at the top of the column
So I create posts of all the two weeks and I had a question that would make my job easer.
I've been messing around with the widow and orphans, but I have a slightly different problem.
We use returns between paragraphs (a blank line between paragraphs), and I was wondering if there was a way to use GREP or showing something to automatically prevent blank lines at the top of a column.
Right now, I have remove and re-add returns throughout the editing process, which as you can guess, can become messy and easy to miss.
I wish I had where I don't have to do it all on my own, so the empty lines would be 'hide' automatically if at the top of a column, but would return if things get moved around.
Thoughts?
Thanks for the help.
kwilly_1572 wrote:
We use returns between paragraphs.
.. can get messy and easy to miss.
It's a reason that should not do this way. Correctly using the space before and/or after the space solves your problem.
Tags: InDesign
Similar Questions
-
Insert a blank line in the result set
Hi friends,
SELECT * FROM EMPLOYEES ORDER BY DEPARTMENT_ID;
As a result of the foregoing, I need to INSERT a blank line in the result for each department_id. for example, the result should resemble the following:
EMP_ID - NAME - SALARY - DEPARTMENT_ID
101 - Albert - 10 000 - 10
102 - Benjamin - 8 000 - 10
103 - Chitra - 10 500 - 20
104 - David - 4 500-20
105 - Elango - 6 000 - 20
106 - faye - 6 000 - 30
107 - Ganga - 9 000 - 30
etc.
I don't want to insert into the table. I need a blank line just on the screen.
Thanks in advance.
Published by: James on March 8, 2010 11:37Something like this->
satyaki> satyaki>select * from v$version; BANNER -------------------------------------------------------------------------------- Oracle Database 11g Enterprise Edition Release 11.1.0.6.0 - Production PL/SQL Release 11.1.0.6.0 - Production CORE 11.1.0.6.0 Production TNS for 32-bit Windows: Version 11.1.0.6.0 - Production NLSRTL Version 11.1.0.6.0 - Production Elapsed: 00:00:00.00 satyaki> satyaki> satyaki>select m.empno, 2 m.ename, 3 m.sal, 4 case 5 when sal is null 6 and empno is null 7 and ename is null then 8 null 9 else 10 m.deptno 11 end deptno 12 from ( 13 select k.empno, 14 k.ename, 15 k.sal, 16 k.deptno 17 from ( 18 select empno, 19 ename, 20 sal, 21 deptno 22 from emp 23 ) k 24 union all 25 select t.* 26 from ( 27 select distinct null empno, null ename, null sal, deptno 28 from emp 29 ) t 30 order by 4 31 ) m; EMPNO ENAME SAL DEPTNO ---------- ---------- ---------- ---------- 7782 CLARK 2450 10 7839 KING 5000 10 7934 MILLER 1300 10 7566 JONES 2975 20 7369 SMITH 800 20 7902 FORD 3000 20 7876 ADAMS 1100 20 7788 SCOTT 3000 20 EMPNO ENAME SAL DEPTNO ---------- ---------- ---------- ---------- 7900 JAMES 950 30 7499 ALLEN 1600 30 7844 TURNER 1500 30 7654 MARTIN 1250 30 7521 WARD 1250 30 7698 BLAKE 2850 30 17 rows selected. Elapsed: 00:00:00.03 satyaki> satyaki>Kind regards.
LOULOU.
-
lines to the column and summation
Hi everyone, I am using oracle 10g consider the following data:
WITH the data as {}
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code "SPRING", 123.23 amount OF double UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code "SPRING", 111.23 amount OF double UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code to 'PAY', 666.23 amount OF the dual UNION ALL
SELECT 'XTR' mntrid, ctid 'AAA', ' hi tech' description, code to 'PAY', 888.23 amount OF the double UNION
SELECT "XTR2' mntrid, ctid 'BBB', ' Hi tech2' description, code to 'PAY', 333.23 amount OF the dual UNION ALL
SELECT "XTR2' mntrid, ctid 'BBB', ' Hi tech2' description, code to 'PAY', 222.23 amount OF double UNION ALL
SELECT mntrid "XTR3", "CCC" ctid, ' hi tech 3 ' description, code 'PC', 777.23 amount OF double
}
I would like secret lines at column and add the amounts. my output should be like this
MNTRID CTID DESCRIPTION MAIN PC PAYROLL
XTR AAA hi tech 234,46 1554.46
XTR2 BBB Hi tech2 555.46
CCC XTR3 Hi Tech 3 777.23
what I do is converting lines to the column and the display of the sum. for example, for mntrid = XTR I get the sum of all MAIN lines and the lines all PAY and PC.
Since there is no line of PC for XTR I display null.
can someone help me write a query that displays the output in oracle 10g above?
Hello
elmasduro wrote:
It's great Frank. Thank you very much.
I have a request. What happens if I want to add total main grad, wages, the pc? How would I do that.
output
Total general AFFID CTID DESCRIPTION MAIN PAY PC
XTR AAA hi tech 234.46 1554,46 1788.92
XTR2 BBB Hi tech2 555,46 555.46
CCC XTR3 Hi Tech 3 777,23 777.23
It's just plain old garden-variety SUM:
SELECT Mntrid
ctid
Description
, SUM (CASE WHEN code = "MAIN" THEN rise END) AS main
, SUM (CASE code WHEN = "SALARY" THEN rise END) AS pay
, SUM (CASE WHEN code = 'PC', THEN rise END) AS pc
, The SUM of (amount) AS grand_total-* NEW *.
FROM the data
GROUP BY mntrid
ctid
Description
;
-
lines to the column for large number of files
my version of the database is 10 gr 2
I want to transfer the lines to the column... .i have seen examples of small no records, but how can it be done if there are more the 1,000 records in a table...?
Here is the example of data I'd like to change to column
SQL> / NE RAISED CLEARED RTTS_NO RING --------------- ------------------------------ ------------------------------ -------------- ----------------------------------------------------------------------------------- 10100000-1LU 22-FEB-2011 22:01:04/28-FEB-20 22-FEB-2011 22:12:27/28-FEB-20 SR-10/ ER-16/ CR-25/ CR-29/ CR-26/ RIDM-1/ NER5/ CR-31/ RiC600-1 11 01:25:22/ 11 02:40:06/ 10100000-2LU 01-FEB-2011 12:15:58/06-FEB-20 05-FEB-2011 10:05:48/06-FEB-20 RIMESH/ RiC342-1/ 101/10R#10/ RiC558-1/ RiC608-1 11 07:00:53/18-FEB-2011 22:04: 11 10:49:18/18-FEB-2011 22:15: 56/19-FEB-2011 10:36:12/19-FEB 17/19-FEB-2011 10:41:35/19-FEB -2011 11:03:13/19-FEB-2011 11: -2011 11:08:18/19-FEB-2011 11: 16:14/28-FEB-2011 01:25:22/ 21:35/28-FEB-2011 02:40:13/ 10100000-3LU 19-FEB-2011 20:18:31/22-FEB-20 19-FEB-2011 20:19:32/22-FEB-20 INR-1/ ISR-1 11 21:37:32/22-FEB-2011 22:01: 11 21:48:06/22-FEB-2011 22:12: 35/22-FEB-2011 22:20:03/28-FEB 05/22-FEB-2011 22:25:14/28-FEB -2011 01:25:23/ -2011 02:40:20/ 10100000/10MU 06-FEB-2011 07:00:23/19-FEB-20 06-FEB-2011 10:47:13/19-FEB-20 101/IR#10 11 11:01:50/19-FEB-2011 11:17: 11 11:07:33/19-FEB-2011 11:21: 58/28-FEB-2011 02:39:11/01-FEB 30/28-FEB-2011 04:10:56/05-FEB -2011 12:16:21/18-FEB-2011 22: -2011 10:06:10/18-FEB-2011 22: 03:27/ 13:50/ 10100000/11MU 01-FEB-2011 08:48:45/22-FEB-20 02-FEB-2011 13:15:17/22-FEB-20 1456129/ 101IR11 RIMESH 11 21:59:28/22-FEB-2011 22:21: 11 22:08:49/22-FEB-2011 22:24: 52/01-FEB-2011 08:35:46/ 27/01-FEB-2011 08:38:42/ 10100000/12MU 22-FEB-2011 21:35:34/22-FEB-20 22-FEB-2011 21:45:00/22-FEB-20 101IR12 KuSMW4-1 11 22:00:04/22-FEB-2011 22:21: 11 22:08:21/22-FEB-2011 22:22: 23/28-FEB-2011 02:39:53/ 26/28-FEB-2011 02:41:07/ 10100000/13MU 22-FEB-2011 21:35:54/22-FEB-20 22-FEB-2011 21:42:58/22-FEB-20 LD MESH 11 22:21:55/22-FEB-2011 22:00: 11 22:24:52/22-FEB-2011 22:10:could you do something like that?
with t as (select '10100000-1LU' NE, '22-FEB-2011 22:01:04/28-FEB-2011 01:25:22/' raised , '22-FEB-2011 22:12:27/28-FEB-2011 02:40:06/' cleared from dual union select '10100000-2LU', '01-FEB-2011 12:15:58/06-FEB-2011 07:00:53/18-FEB-2011 22:04:56/19-FEB-2011 10:36:12/19-FEB-2011 11:03:13/19-FEB-2011 11:16:14/28-FEB-2011 01:25:22/', '05-FEB-2011 10:05:48/06-FEB-2011 10:49:18/18-FEB-2011 22:15:17/19-FEB-2011 10:41:35/19-FEB-2011 11:08:18/19-FEB-2011 11:21:35/28-FEB-2011 02:40:13/' from dual ) select * from( select NE, regexp_substr( raised,'[^/]+',1,1) raised, regexp_substr( cleared,'[^/]+',1,1) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,2) , regexp_substr( cleared,'[^/]+',1,2) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,3) , regexp_substr( cleared,'[^/]+',1,3) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,4) , regexp_substr( cleared,'[^/]+',1,4) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,5) , regexp_substr( cleared,'[^/]+',1,5) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,6) , regexp_substr( cleared,'[^/]+',1,6) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,7) , regexp_substr( cleared,'[^/]+',1,7) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,8) , regexp_substr( cleared,'[^/]+',1,8) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,9) , regexp_substr( cleared,'[^/]+',1,9) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,10) , regexp_substr( cleared,'[^/]+',1,10) cleared from t union select NE, regexp_substr( raised,'[^/]+',1,11) , regexp_substr( cleared,'[^/]+',1,11) cleared from t ) where nvl(raised,cleared) is not null order by neNE RAISED CLEARED 10100000-1LU 28-FEB-2011 01:25:22 28-FEB-2011 02:40:06 10100000-1LU 22-FEB-2011 22:01:04 22-FEB-2011 22:12:27 10100000-2LU 28-FEB-2011 01:25:22 28-FEB-2011 02:40:13 10100000-2LU 19-FEB-2011 10:36:12 19-FEB-2011 10:41:35 10100000-2LU 19-FEB-2011 11:03:13 19-FEB-2011 11:08:18 10100000-2LU 19-FEB-2011 11:16:14 19-FEB-2011 11:21:35 10100000-2LU 06-FEB-2011 07:00:53 06-FEB-2011 10:49:18 10100000-2LU 01-FEB-2011 12:15:58 05-FEB-2011 10:05:48 10100000-2LU 18-FEB-2011 22:04:56 18-FEB-2011 22:15:17You should be able to do without all these unions using a connection by but I can't quite make it work
the following does not work, but perhaps someone can answer.select NE, regexp_substr( raised,'[^/]+',1,level) raised, regexp_substr( cleared,'[^/]+',1,level) cleared from t connect by prior NE = NE and regexp_substr( raised,'[^/]+',1,level) = prior regexp_substr( raised,'[^/]+',1,level + 1)Published by: pollywog on March 29, 2011 09:38
Here it is with the type clause that gets rid of all unions.
WITH t AS (SELECT '10100000-1LU' NE, '22-FEB-2011 22:01:04/28-FEB-2011 01:25:22/' raised, '22-FEB-2011 22:12:27/28-FEB-2011 02:40:06/' cleared FROM DUAL UNION SELECT '10100000-2LU', '01-FEB-2011 12:15:58/06-FEB-2011 07:00:53/18-FEB-2011 22:04:56/19-FEB-2011 10:36:12/19-FEB-2011 11:03:13/19-FEB-2011 11:16:14/28-FEB-2011 01:25:22/', '05-FEB-2011 10:05:48/06-FEB-2011 10:49:18/18-FEB-2011 22:15:17/19-FEB-2011 10:41:35/19-FEB-2011 11:08:18/19-FEB-2011 11:21:35/28-FEB-2011 02:40:13/' FROM DUAL) SELECT * FROM (SELECT NE, raised, cleared FROM t MODEL RETURN UPDATED ROWS PARTITION BY (NE) DIMENSION BY (0 d) MEASURES (raised, cleared) RULES ITERATE (1000) UNTIL raised[ITERATION_NUMBER] IS NULL (raised [ITERATION_NUMBER + 1] = REGEXP_SUBSTR (raised[0], '[^/]+', 1, ITERATION_NUMBER + 1), cleared [ITERATION_NUMBER + 1] = REGEXP_SUBSTR (cleared[0], '[^/]+', 1, ITERATION_NUMBER + 1))) WHERE raised IS NOT NULL ORDER BY NEPublished by: pollywog on March 29, 2011 10:34
-
How to query start a new line in the column?
How to query start a new line in the column?
Exam
SELECT ID, username | host name, details of xxx;
on the 2 column, I need result below:
Username ID | hostname in detail
1 user1 xxxxxx
host1
2 user2 xxxxxx
host2
Kind regards
SuradechSomething like that?
SQL> WITH tbl AS (SELECT 1 id,'user1' uname,'xxx' dtl,'host1' hname FROM DUAL UNION ALL 2 SELECT 2 id,'user2' uname,'yyy' dtl,'host2' hname FROM DUAL UNION ALL 3 SELECT 3 id,'user3' uname,'zzz' dtl,'host3' hname FROM DUAL 4 ) 5 SELECT id,uname||dtl||chr(10)||hname FROM tbl; ID UNAME||DTL||CH ---------- -------------- 1 user1xxx host1 2 user2yyy host2 3 user3zzz host3 -
APEX do not allow to change the lines of the columns that are the primary key?
I have pictures:
http://img508.imageshack.us/my.php?image=21269582oe8.jpg
Book (id_book - 'Primary key', title, year); book_author (id_author id_book - 'Primary key', - 'Primary key'); author (id_author - "Primary key", name)
I created a new page-> Form-> form of 'author' table because I want to add new authors, modification and deletion. During the creation of this page, I have chosen column 'id_author' as '1 primary key column' and everything is OK (I can't edit the 'id_author' column - this column is autoincrement and I can change the 'name' column).
BUT I also created a new page-> Form-> table for table "book_author" because I like to write numbers like id_book and id_author, change and remove them (so add relations between tables: book, book_author and author). During the creation of this page, I have chosen column 'id_book' as '1 primary key column' and 'id_author' as 'column primary key 2'. And on the Web site, I can't edit these fields. And I can not add also new line because I see in each new line: (null).
http://img444.imageshack.us/my.php?image=11324615yk9.jpg
APEX do not allow to change the lines of the columns that are the primary key? It's stupid... What can I do?
Edited by: user10731158 2008-12-20 11:40Column unique and not meaningful if you ever want to update. In the case of your example, you need to add an ID column in the intersection of book_author table. Honestly, I was so blown away (and pleasantly surprised) by the absence of rebuttal and the "thx" I advanced and set up an example of how I would define the book_author table:
create table book_author (id varchar2(32), book_id varchar2(32), author_id varchar2(32), modified_on date, modified_by varchar2(255), constraint book_author_pk primary key (id), constraint book_auth_book_fk foreign key (book_id) references books(id), constraint book_auth_author_fk foreign key (author_id) references authors(id) ) / create unique index book_author_uq on book_author (book_id,author_id) / create or replace trigger biu_book_author before insert or update on book_author for each row begin if inserting then :new.id := sys_guid(); end if; modified_on := sysdate; modified_by := nvl(v('APP_USER'),user); end; /Good luck
Tyler -
Word RTF Tem [plate - insert a blank line in the loop
I'm entering my template like this XML data (this is just an example of dumbed down):
<? XML version = "1.0"? >
< LABEL_TEST >
< LIST_G_TEST >
< G_LABEL_HEADER >
< NAME > Parent 1 < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > Kid 1 < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > Parent 2 < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > Parent 3 < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > 4 Parent < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > Kid 4 < / NAME >
< / G_LABEL_HEADER >
< / LIST_G_TEST >
< / LABEL_TEST >
In summary, I have a list of Parents, and if they have a child, the name of their children is below. Not all parents have children.
If the data is a bit like this:
Name of the parent
Name of the child
Name of the parent
Name of the parent
Name of the parent
Name of the child
When I loop data in my RTF model, I want to be able to insert a blank line before all of the lines 'Parent '. A bit like this:
Name of the parent
Name of the child
Name of the parent
Name of the parent
Name of the parent
Name of the child
I tried to do this by adding an empty xml tag in the list, like this:
<? XML version = "1.0"? >
< LABEL_TEST >
< LIST_G_TEST >
< G_LABEL_HEADER >
< NAME > Parent 1 < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > Kid 1 < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > Parent 2 < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > Parent 3 < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > 4 Parent < / NAME >
< / G_LABEL_HEADER >
< G_LABEL_HEADER >
< NAME > Kid 4 < / NAME >
< / G_LABEL_HEADER >
< / LIST_G_TEST >
< / LABEL_TEST >
But that doesn't seem to work.
Manny
I found a solution that works very well.
I added a new XML field to my data called
. In my model, this field is inserted in the line, but in a location where there is no data being printed. And it is formatted as white text, so that it basically just does not appear. So essentially, it's what I have now:
Parent 1 . Child 1 . . Parent 2 . . Parent 3 . . Mother 4 . Child 4 . If the data is a bit like this:
The name of the parent.
The name of the child.
.
The name of the parent.
.
The name of the parent.
.
The name of the parent.
The name of the child.
When I loop data in my RTF model, the '. ' is a white text, then I get this:
Name of the parent
Name of the child
Name of the parent
Name of the parent
Name of the parent
Name of the child
-
Insert a blank line in the query output
Is it possible to insert a blank line between two rows of the query output?
In the EMP table, the column LINES is as follows:
LINES
1
2
3
4
1
2
3
1
2
3
4
5
I want to insert a blank line after every 1
Please suggest.
SanjayI'm quite puzzled why you need rows in the dataset returned by a select statement that is empty.
If you are using Oracle reports to the release date, you define the presentation of the report to have spaces between the rows returned by the select and have do not need to have the select statement returns a blank line after each line of data. If the output should be obtained by using another client, I think that the customer will have facilities for output formatting.Admit that you really need "blank lines" between data lines, I see only one way: use a temporary table and do an insert into select temporary_table (...) ... from... where... Then, in this temporary table, you can insert 'empty rows', which is actually not really empty, because they must have some fields that give the order of the rows. And then select in temporary_table, you place your order by the columns that are used to give the order for the release.
Thusinsert into temporary_table ( .... ) select ... from ... where ... ; for r in ( select col1, col2, col3 -- columns used for order by from temporary_table order by col1, col2, col3 ) loop insert into temporary_table (col1, col2,col3, col4) values (r.col1,r.col2,r.col3, null); end loop; -- this way, a select * from temporary_tabel order by col1, col2, col3, col4 will return a blank row after each data row -
How to integrate a mp.3 background without having a blank line above the header?
Hello
, I have integrated a Mp3 file that plays very well when loading the home page, however he created this white line above the header of the home page. You can see it at http://rotorooterhsv.com
I've embedded the file under page properties / metadata / HTML for < head >: < embed src = "music/Roto - RooterJingleFemaleSinger.mp3" autostart = "true" loop = "false" hidden = "true" > < / embed >. (The header also contains GA and a few other scripts)
Thanks in advance for any advice!

HTML code for
is not where you need to insert. As the audio player is already hidden, try to place somewhere in the page by using the object-> the option Insert HTML code. And using layers, you can place it in the back.Please see the following article on what labels can be added to the head section - http://www.w3schools.com/html/html_head.asp.
Thank you
Vinayak
-
Have blank lines on the page open automatically
Hello
Is it possible to have empty lines when the page is rendered as a table? It is a wizard that is generated in a table.
Thank you
MaryCreate a process
Choose the type of data handling processes
Select Add lines slot table form
Select on the laundry front header
Enter the number of lines to addKind regards
Shijesh -
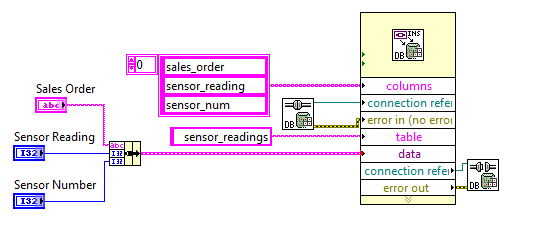
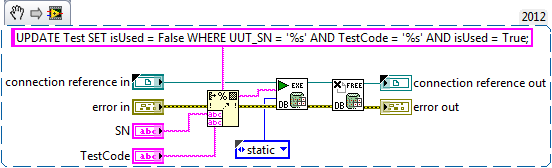
Update line in the column-based database
Hello
I am trying to find a way to update a row that has a SQL database based on two columns. If the command and the match number sensor order number and sales sensor that already exists in the database, I want to update the column of reading of the sensor. If not exists then I want that it creates a new line. How would I go to do this?
Thank you
Chris
You can use the tools of DB Query.vi Execute. Here is an example of a MS Access 2010 database where a column value is updated in all rows satisfying the WHERE conditions.
Ben64
-
ADF: how to insert the character of new line in the column of VO?
Hello world
IM using Jdev 11 G.
I have a VO with 5 columns appear on the page of the ADF. (VO a total 8 columns)
column 1 is the combination of 3 columns. I concatenated 3 columns and add the new line character after each column Chr (13).
VO query works very well as a toad. the columnn displays each column value concatenated after a newline character, but the same query does not work in the ADF.
The column that is the concatenation of the 3 columns and should display with the new line character does not display the new line character its just concatenation of the 3 values and display on the page.
Wat could be the solution for this in the ADF?
Thank you.Column does not have the property to escape. It is part of the output text.
Something like
Arun-
-
RESULT DATE1 POINT
-------------------------------------------
XYZ F 1 JUNE 07
F 1 JULY 07 XYZ
F 1 JULY 07 XYZ
F 1 JULY 07 XYZ
XYZ F 1 JUNE 07
ABC F 1 JUNE 07
ABC F 1 JUNE 07
F 1 JULY 07 ABC
F 1 JULY 07 ABC
P 1 JULY 07 ABC
P 1 JULY 07 ABC
ABC OF JUNE 1: 07 P
ABC OF JUNE 1: 07 P
ABC OF JUNE 1: 07 P
the above lines must be transposed to the columns as below table from the above. That takes the number total of RESULTS, County of 'F', 'P' County, based on the month and the product.
DATE1 POINT TOTALCOUNT COUNT_OF_F COUNT_OF_P
---------------------------------------------------------------------------------------------------------------------------------------------------
1ST JUNE 07 XYZ 2 2 0
1 JULY 07 XYZ 3 3 0
1ST JUNE 07 5 2 3 ABC
1 JULY 07 4 2 2 ABC
Thank youuser9370033 wrote:
RESULT DATE1 ITEM ------------------------------------------- F 01-JUN-07 XYZ F 01-JUL-07 XYZ F 01-JUL-07 XYZ F 01-JUL-07 XYZ F 01-JUN-07 XYZ F 01-JUN-07 ABC F 01-JUN-07 ABC F 01-JUL-07 ABC F 01-JUL-07 ABC P 01-JUL-07 ABC P 01-JUL-07 ABC P 01-JUN-07 ABC P 01-JUN-07 ABC P 01-JUN-07 ABC the above rows has to be transposed to columns like below table from the above one. Which takes the total count of RESULT, count of "F" , count of "P" based on month and Product. DATE1 ITEM TOTALCOUNT COUNT_OF_F COUNT_OF_P --------------------------------------------------------------------------------------------------------------------------------------------------- 01-JUN-07 XYZ 2 2 0 01-JUL-07 XYZ 3 3 0 01-JUN-07 ABC 5 2 3 01-JUL-07 ABC 4 2 2Thank you
You can do like this
select date1, item, count(*) totalcount, count(decode(result,'F',1,null)) count_of_f, count(decode(result, 'P',1, null)) count_of_p fromgroup by date1, item
- Hi all, I have two tables with data as described below.
what I want to do is to join these two tables and get the values of the table Details
and fill in the data table in the columns that are null. Data table must remain with one
line.
WITH the data AS
(
SELECT "a34" id, "pat smith" name, 234 compid, NULL returned, NULL, NULL prod FROM dual UNION all
SELECT "a35" id name "case jon", dual 543 compid, NULL, NULL, NULL FROM prod revenue business
)
Details such AS
(
SELECT "a34' id code 'craft', 123 idvalue FROM double UNION all
SELECT "a34' id, 'rev' code, 456 idvalue FROM double UNION all
SELECT "a34' id, 'product' code, 789 idvalue FROM dual UNION all
SELECT "a35' id code 'craft', 294 idvalue FROM double UNION all
SELECT "a35' id, 'rev' code, 546 idvalue FROM double UNION all
SELECT "a35' id, 'product' code, 654 double idvalue
)
the output of this query should be
ID name compid prod turnover
A34 pat smith 234 123 456 789
A35 case jon 543 294 546 654
can someone help write a query that gives me not the above result? Thank youThis gives a shot:
WITH data AS ( SELECT 'a34' id, 'pat smith' name, 234 compid, NULL business, NULL revenue, NULL prod FROM dual UNION all SELECT 'a35' id, 'jon case' name, 543 compid, NULL business, NULL revenue, NULL prod FROM dual ), details AS ( SELECT 'a34' id, 'business' code, 123 idvalue FROM dual UNION all SELECT 'a34' id, 'rev' code, 456 idvalue FROM dual UNION all SELECT 'a34' id, 'product' code, 789 idvalue FROM dual UNION all SELECT 'a35' id, 'business' code, 294 idvalue FROM dual UNION all SELECT 'a35' id, 'rev' code, 546 idvalue FROM dual UNION all SELECT 'a35' id, 'product' code, 654 idvalue FROM dual ), unpivot_details AS ( SELECT ID , MAX(DECODE(CODE,'business',IDVALUE)) AS BUSINESS , MAX(DECODE(CODE,'rev',IDVALUE)) AS REVENUE , MAX(DECODE(CODE,'product',IDVALUE)) AS PROD FROM DETAILS GROUP BY ID ) SELECT DATA.ID , NAME , COMPID , NVL(DATA.BUSINESS,UD.BUSINESS) AS BUSINESS , NVL(DATA.REVENUE,UD.REVENUE) AS REVENUE , NVL(DATA.PROD,UD.PROD) AS PROD FROM DATA JOIN unpivot_details UD ON DATA.ID = UD.IDI did take your DETAILS and UNPIVOT table data turning rows of columns. I used this result to join the DATA table. Once the tables were joined, I used the function NVL will only display the DETAILS table data if the data in the DATA table is NULL.
If you have more values of 'code', you will need to add them manually to the UNPIVOT_DETAILS view.
HTH!
- I create a report that lists a training topic and current employees who must complete the course. I would like to add a number any white lines (part of the page) to the bottom of the report to accommodate non-registered participants. This report will be printed, signed and then used as input to record the training.
I know I can do a UNION at the bottom of the report, but I would like to than the number of lines to set using a hard rather than coded page element. Someone at - it an idea?
I tried
but this gives me a line no matter what.... union select NULL, NULL, NULL, NULL, NULL from EMPLOYEES where rownum <= :P1727_BLANKS... union all select null, null, null, null, null from dual connect by rownum <= :P1727_BLANKSMaybe you are looking for
-
Windows 7 can not find my Toshiba STORE. E. ALU 3.5 "
LS, I can't connect my external hard drive - a Toshiba STORE. E ALU 3.5 "to my Windows7 system.With XP I had no problems. How can I connect this drive to my Windows 7 computer? Thanks for the help, Neusbeertje
-
Satellite A135-SP4796: XP drivers for required display brightness control
Hello, thanks for reading of this I managed to find all the XP drivers for my model A135-SP4796, but whatever the hoy of many drivers, I tried, I couldn't find any one who operate the FN keys. I'm only interested in setting the brightness of the scre
-
can I put a 'not activated' version of XP to Windows 7?
I recently installed on the OEM of XP version on an old laptop to see if it (the cell) worked and something that children can use. I of course can't activate the version of XP, but she wondered if I upgraded to windows 7, would this work? Put anoth
-
What is the difference in performance?
-
E-mail account of decoupling of lost phone blackBerry Smartphones
Hi everyone, I need your help. I recently lost my blackberry and I had connected my hotmail account to the phone. Is there a way I can disassociate it now? I myself have retired to the fact that theres nothing I can do on the card memory and messages
- Hi all, I have two tables with data as described below.