Bitmap Vs domain of index for large tables
I have a DB warehouse which consists of very large tables.
I have two questions:
1 can I use Bitmap or field type index?
2. use a different tablespace for storing the indices? This would improve performance?
Please give me advice to improve the performance of queries for these large tables (more than 300 M record).
Concerning
When to use bitmap indexes
------------------------------
-The column has a low cardinality: little separate value
-Bitmap indexes are particularly useful for complex with ad-hoc queries
long WHERE clauses or applications of aggregation (containing SUM, COUNT, or other
aggregate functions)
-The table contains the number of lines (1,000,000 lines with 10,000 distinct values)
may be acceptable)
-There are frequent, possibly ad hoc queries on the table
-L' environment is focused on the data warehouse (System DSS). Bitmap indexes are
not ideal for due processing (OLTP) environments transactional online
their locking behavior. It is not possible to lock a single bitmap.
The smallest amount of a bitmap that can be locked is a bitmap segment, which
can be a block of data up to half size. Changing the value of a row results in
a bitmap segment becomes locked, blocking to force change on a number of lines.
This is a serious drawback when there are several UPDATE, INSERT or DELETE
statements made by users. It is not a problem when loading data or
updated to the stock in bulk, as in data warehouse systems.
-Bitmap join indexes are a new method of 9.0 by which joins can be avoided in
pre-creation index bitmap on the join criteria.
The BJI is an effective way of space reduction in the volume of selected data.
The data resulting from the join operation and restrictions are
kept permanently in a BJI. The join condition is a join, equi-internal between the
column/columns in primary key of the dimension and the foreign key tables
column or columns in the fact table.
When to use domain indexes
---------------------------------------
https://docs.Oracle.com/CD/E11882_01/AppDev.112/e41502/adfns_indexes.htm#ADFNS00504
Tags: Database
Similar Questions
-
Paging query needed help for large table - force a different index
I use a slight modification of the pagination to be completed request to ask Tom: [http://www.oracle.com/technology/oramag/oracle/07-jan/o17asktom.html]
Mine looks like this to extract the first 100 lines of everyone whose last name Smith, ordered by join date:
The difference between this and ask Tom is my innermost query returns just the ROWID. Then, in the outermost query we associate him returned to the members table ROWID, after that we have cut the ROWID down to only the 100 piece we want. This makes it MUCH more (verifiable) fast on our large tables, because it is able to use the index on the innermost query (well... to read more).SELECT members.* FROM members, ( SELECT RID, rownum rnum FROM ( SELECT rowid as RID FROM members WHERE last_name = 'Smith' ORDER BY joindate ) WHERE rownum <= 100 ) WHERE rnum >= 1 and RID = members.rowid
The problem I have is this:
It will use the index for the column predicate (last_name) rather than the unique index that I defined for the column joindate (joindate, sequence). (Verifiable with explain plan). It is much slower this way on a large table. So I can reference using one of the following methods:SELECT rowid as RID FROM members WHERE last_name = 'Smith' ORDER BY joindateSELECT /*+ index(members, joindate_idx) */ rowid as RID FROM members WHERE last_name = 'Smith' ORDER BY joindate
Whatever it is, it now uses the index of the column ORDER BY (joindate_idx), so now it's much faster there not to sort (remember, VERY large table, millions of records). If it sounds good. But now, on my outermost query, I join the rowid with the significant data in the members table columns, as commented below:SELECT /*+ first_rows(100) */ rowid as RID FROM members WHERE last_name = 'Smith' ORDER BY joindate
As soon as I did this join, this goes back to the use of the index of predicate (last_name) and perform the sort once he finds all the corresponding values (which can be a lot in this table, there is a cardinality high on some columns).SELECT members.* -- Select all data from members table FROM members, -- members table added to FROM clause ( SELECT RID, rownum rnum FROM ( SELECT /*+ index(members, joindate_idx) */ rowid as RID -- Hint is ignored now that I am joining in the outer query FROM members WHERE last_name = 'Smith' ORDER BY joindate ) WHERE rownum <= 100 ) WHERE rnum >= 1 and RID = members.rowid -- Merge the members table on the rowid we pulled from the inner queries
My question therefore, in the query full above, is it possible that I can get to use the ORDER of indexing BY column to prevent having to sort? The join is what makes go back to using the predicate index, even with notes. Remove the join and just return the ROWID for these 100 records and it flies, even over 10 millions of documents.
It would be great if there was some generic hint that could accomplish this, such as if we change the table/column/index, do not change the indicator (indicator FIRST_ROWS is a good example of this, while the INDEX indicator is the opposite), but any help would be appreciated. I can provide explain plans for the foregoing, if necessary.
Thank you!
-
Collect table statistics take longer for large tables
Version: 11.2
I noticed brings his stats (via dbms_stats.gather_table_stats) takes more time for the large tables.
As number of rows must be calculated, collection of statistics on the table a big would naturally be a little longer (running COUNT (*) SELECT internal).
But for a table not partitioned with 3 million lines, it took 12 minutes to retrieve the stats? Outside the County info and the row index what other information is collected for the table stats gather?
Size of the Table is actually important for the collection of statistics?USER_TABLES DESC
and also
USER_IND_STATISTICS
USER_PART_COL_STATISTICS
USER_SUBPART_COL_STATISTICS
USER_TAB_COL_STATISTICS
USER_TAB_STATISTICS
USER_TAB_STATS_HISTORY
USER_USTATS
USER_TAB_HISTOGRAMS
USER_PART_HISTOGRAMS
USER_SUBPART_HISTOGRAMS -
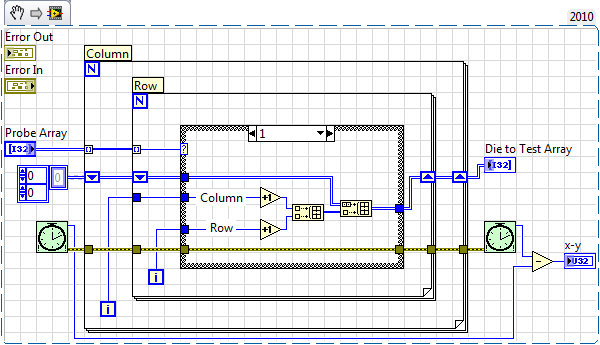
Request: Make these more fast screws for large tables
Hey everybody,
Did anyone mind take a look at these two screws? They work very well for small data sets, but they are starting to take up to 200ms each for large arrays (~ 5000 rows x 2 columns). The first actually sends data to the 2nd, so the total delay when running these screws may be 400, 500 ms. Too much to use them in real time.
Reminder of how they are used:
The user can click or click-and - dragging on a graph of intensity to create a card to die to test. These VI are run to update a list of that die are selected and a list of how the machine will move. In mode click - drag, these VI create a very big delay in the response of the public Service.
First VI:
The entrance is a 2D table 1 or 0, indicating the test or not test. The output is a 2D line (Nx2) table, column numbers should be probed.
Second VI:
The entrance is a table 2D (Nx2) R, C numbers (from the 1st VI). This VI calculates a relative movement of the current matrix with the following matrix. The output is a table 2D (Nx2) of the relative motions (Y, X). Example: ((2,4), (5.1)) back in ((0,0), (3, -3)).
I've already cut the running time up to half of what it was, but it is still not fast enough. And Yes, the limits of error are not connected, I know :-)
Screws (also attached):
So, what do you think? Is there some Subvi I don't know which completely replaces the 1st VI? Is one of the Subvi I use inherently slow?
-
Creating indexes for the table
can someone help me how to create indexes in the table. I m creating own table... I need to select a particular field in the table. So I need to calculate the index position. I use my code like this,
This will returnthe number of columns in the table.
Class array
{
private int Table_Index()
{
for (int x = 0; x)<>
{
table_index = x;
}
Return table_index;
}}
MainClass can I get this length of Index
Table T1;
int t1 is T1. Table_Index();
This property returns my length (4) of table column
Using this index (t1) I HAV to see what position I'm at table now...
someone help me...
You can use a listfield, he supports methods to get the selected row and its contents.
-
How to use partitioning for large table
Hello
******************
Oracle 10 g 2/Redhat4
RAC database
ASM
*******************
I have a TRACE table that will also grow very fast, in fact, I 15,000,000 lines.
TRACES (IDENTIFICATION NUMBER,
NUMBER OF COUNTRY_NUM
Timestampe NUMBER,
MESSAGE VARCHAR2 (300),
type_of_action varchar (20),
CREATED_TIME DATE,
DATE OF UPDATE_DATE)
Querys who asked for this table are and make a lot of discs!
--------------------------------------------------------
Select count (*) as y0_
TRACES this_
where this_. COUNTRY_NUM =: 1
and this_. TIMESTAMP between: 2 and: 3
and lower (this_. This MESSAGE) as: 4;
---------------------------------------------------------
SELECT *.
FROM (SELECT this_.id,
this_. TIMESTAMP
Traces this_
WHERE this_. COUNTRY_NUM =: 1
AND this_. TIMESTAMP BETWEEN: 2 AND: 3
AND this_.type_of_action =: 4
AND LOWER (this_. MESSAGE) AS: 5
ORDER BY this_. TIMESTAMP DESC)
WHERE ROWNUM < =: 6;
-----------------------------------------------------------
I have 16 distinct COUNTRY_NUM in the table and the TIMESTAMPE is a number that the application is inserted into the table.
My question is the best solution to resolve this table is to use partitioninig for a smal parts?
I have need of a partitioning using a list by date (YEAR/month) and COUNTRY_NUM, is there a better way for her?
NB: for an example of TRACES in my test database
1 Select COUNTR_NUM, count (*) traces
Group 2 by COUNTR_NUM
3 * order by COUNTR_NUM
SQL > /.
COUNTR_NUM COUNT (*)
194716 1
3 1796581
4 1429393
5 1536092
6 151820
7 148431
8 76452
9 91456
10 91044
11 186370
13 76
15 29317
16 33470Hello
Yes and part is that you can remove the whole score once you don't need "of them. I think you should be good to go. Let me know if you have any other questions.
Concerning
-
The fastest way to import data for large tables
Hi friends,
I recently joined a billing product put up a team for TELECOM giant. Under the procedure of installation/initial tests, we have huge data (size of almost 1.5 billion records / ~ 200 GB of data) in some tables. Currently I use impdp to import. It takes a long time (almost > 9 hours to load these data).
I tried the ways below to import the data (all of these tables is partitioned):
1. normal impdp (single thread that is, parallel = 1): it takes a long time (> 24 hours).
2. normal impdp but partition-wise. It was completed in relatively less amout of time compared to the 1st method.
3 fall drop the index, framed adding another scheme in the same forum that includes data, and then recreate the index (whole process takes about 9 hours)
My questions at all:
1. is there any other way/trick in the book that I can try to put the data in less time
2. what I pointed out that even if I give parallel = 8 or more, sometimes parallel workers are laid and sometimes not. Can someone tell me why?
3. How can I come to know (before running the impdp) that my parallel article will spawn parallel workers or not. As to how I will come to find out, I searched this topic but without success.
I don't know what strategy to follow, because it is an involved and repetitive task for me. Because of the task above, I am not able to focus on other DBA tasks because of what comes to me.
See you soon,.
Malikaassuming that you have a table with 3 clues, then create a script for each index (reblace index_name_n with your index name) and start them at the same time, after the importation of the table is complete
DUMPFILE=or NETWORK_LINK= DIRECTORY=DATA_PUMP_DIR LOGFILE= CONTENT=ALL PARALLEL=1 JOB_NAME=IMP_ INCLUDE=TABLE_EXPORT/TABLE/INDEX:"IN(' ')" TABLES= . Change the following settings when importing:
increase pga_aggregate_target
increase db_writer_processes
db_block_checking = false
db_block_checksum = falsethe value undo and temporary ts autoextend
Set noarchivelogmode
create logs of restoration of 4 GBHTH
appropriate using index for the execution of the parallel statement
Hi all
I created indexes for my table
That was before I started thinking about the execution of the parallel statement. As far as I've heard I need to change my correct use with parallel hint index. Could you please suggest the way forward?CREATE INDEX ZOO.rep184_med_arcdate ON ZOO.rep184_mediate(arcdate);Marco wrote:
Hi allI created indexes for my table
CREATE INDEX ZOO.rep184_med_arcdate ON ZOO.rep184_mediate(arcdate);That was before I started thinking about the execution of the parallel statement. As far as I've heard I need to change my correct use with parallel hint index. Could you please suggest the way forward?
When all else fails, read the Fine
http://download.Oracle.com/docs/CD/E11882_01/server.112/e17118/sql_elements006.htm#autoId63
How to cut the large table into pieces
I'm trying to derive some of generic logic that would be cut into pieces of defined size a large table. The goal is to perform the update into pieces and avoid questions too small restoration. The full table on the update scan is inevitable, given that the update target each row of the table.
The BIGTABLE has 63 million lines. The purpose of the bellow SQL to give ID all 2 million rows. So I use the rownum 'auto line numering field' and run a test to see I could. I expected the piece of fist to have 2 million rows, but in fact, it is not the case:
Here is the +(NOTE I had many problems with quotes, so some ROWID appears without their enclosing quotes or they disappear from current output here) code +:
Amzingly, this code works perfectly for small tables, but fails for large tables. Does anyone has an explanation and possibly a solution to this?select rn, mod, frow, rownum from ( select rowid rn , rownum frow, mod(rownum, 2000000) mod from bigtable order by rn) where mod = 0 / SQL> / RN MOD FROW ROWNUM ------------------ ---------- ---------- ---------- AAATCjAA0AAAKAVAAd 0 4000000 1 AAATCjAA0AAAPUEAAv 0 10000000 2 AAATCjAA0AAAbULAAx 0 6000000 3 AAATCjAA0AAAsIeAAC 0 14000000 4 AAATCjAA0AAAzhSAAp 0 8000000 5 AAATCjAA0AABOtGAAa 0 26000000 6 AAATCjAA0AABe24AAE 0 16000000 7 AAATCjAA0AABjVgAAQ 0 30000000 8 AAATCjAA0AABn4LAA3 0 32000000 9 AAATCjAA0AAB3pdAAh 0 20000000 10 AAATCjAA0AAB5dmAAT 0 22000000 11 AAATCjAA0AACrFuAAW 0 36000000 12 AAATCjAA6AAAXpOAAq 0 2000000 13 AAATCjAA6AAA8CZAAO 0 18000000 14 AAATCjAA6AABLAYAAj 0 12000000 15 AAATCjAA6AABlwbAAg 0 52000000 16 AAATCjAA6AACBEoAAM 0 38000000 17 AAATCjAA6AACCYGAA1 0 24000000 18 AAATCjAA6AACKfBABI 0 28000000 19 AAATCjAA6AACe0cAAS 0 34000000 20 AAATCjAA6AAFmytAAf 0 62000000 21 AAATCjAA6AAFp+bAA6 0 60000000 22 AAATCjAA6AAF6RAAAQ 0 44000000 23 AAATCjAA6AAHJjDAAV 0 40000000 24 AAATCjAA6AAIR+jAAL 0 42000000 25 AAATCjAA6AAKomNAAE 0 48000000 26 AAATCjAA6AALdcMAA3 0 46000000 27 AAATCjAA9AAACuuAAl 0 50000000 28 AAATCjAA9AABgD6AAD 0 54000000 29 AAATCjAA9AADiA2AAC 0 56000000 30 AAATCjAA9AAEQMPAAT 0 58000000 31 31 rows selected. SQL> select count(*) from BIGTABLE where rowid < AAATCjAA0AAAKAVAAd ; COUNT(*) ---------- 518712 <-- expected around 2 000 000 SQL> select count(*) from BIGTABLE where rowid < AAATCjAA0AAAPUEAAv ; COUNT(*) ---------- 1218270 <-- expected around 4 000 000 SQL> select count(*) from BIGTABLE where rowid < AAATCjAA0AAAbULAAx ; COUNT(*) ---------- 2685289 <-- expected around 6 000 000
Here's the complete SQL code that is suppposed to generate all the predicates, I need to add update statements in order to cut into pieces:
Nice but not accurate...select line from ( with v as (select rn, mod, rownum frank from ( select rowid rn , mod(rownum, 2000000) mod from BIGTABLE order by rn ) where mod = 0), v1 as ( select rn , frank, lag(rn) over (order by frank) lag_rn from v ), v0 as ( select count(*) cpt from v) select 1, case when frank = 1 then ' and rowid < ''' || rn || '''' when frank = cpt then ' and rowid >= ''' || lag_rn ||''' and rowid < ''' ||rn || '''' else ' and rowid >= ''' || lag_rn ||''' and rowid <'''||rn||'''' end line from v1, v0 union select 2, case when frank = cpt then ' and rowid >= ''' || rn || '''' end line from v1, v0 order by 1) / and rowid < AAATCjAA0AAAKAVAAd and rowid >= 'AAATCjAA0AAAKAVAAd' and rowid < 'AAATCjAA0AAAPUEAAv'' and rowid >= 'AAATCjAA0AAAPUEAAv' and rowid < 'AAATCjAA0AAAbULAAx'' and rowid >= 'AAATCjAA0AAAbULAAx' and rowid < 'AAATCjAA0AAAsIeAAC'' and rowid >= 'AAATCjAA0AAAsIeAAC' and rowid < 'AAATCjAA0AAAzhSAAp'' and rowid >= 'AAATCjAA0AAAzhSAAp' and rowid < 'AAATCjAA0AABOtGAAa'' and rowid >= 'AAATCjAA0AAB3pdAAh' and rowid < 'AAATCjAA0AAB5dmAAT'' and rowid >= 'AAATCjAA0AAB5dmAAT' and rowid < 'AAATCjAA0AACrFuAAW'' and rowid >= 'AAATCjAA0AABOtGAAa' and rowid < 'AAATCjAA0AABe24AAE'' and rowid >= 'AAATCjAA0AABe24AAE' and rowid < 'AAATCjAA0AABjVgAAQ'' and rowid >= 'AAATCjAA0AABjVgAAQ' and rowid < 'AAATCjAA0AABn4LAA3'' and rowid >= 'AAATCjAA0AABn4LAA3' and rowid < 'AAATCjAA0AAB3pdAAh'' and rowid >= 'AAATCjAA0AACrFuAAW' and rowid < 'AAATCjAA6AAAXpOAAq'' and rowid >= 'AAATCjAA6AAA8CZAAO' and rowid < 'AAATCjAA6AABLAYAAj'' and rowid >= 'AAATCjAA6AAAXpOAAq' and rowid < 'AAATCjAA6AAA8CZAAO'' and rowid >= 'AAATCjAA6AABLAYAAj' and rowid < 'AAATCjAA6AABlwbAAg'' and rowid >= 'AAATCjAA6AABlwbAAg' and rowid < 'AAATCjAA6AACBEoAAM'' and rowid >= 'AAATCjAA6AACBEoAAM' and rowid < 'AAATCjAA6AACCYGAA1'' and rowid >= 'AAATCjAA6AACCYGAA1' and rowid < 'AAATCjAA6AACKfBABI'' and rowid >= 'AAATCjAA6AACKfBABI' and rowid < 'AAATCjAA6AACe0cAAS'' and rowid >= 'AAATCjAA6AACe0cAAS' and rowid < 'AAATCjAA6AAFmytAAf'' and rowid >= 'AAATCjAA6AAF6RAAAQ' and rowid < 'AAATCjAA6AAHJjDAAV'' and rowid >= 'AAATCjAA6AAFmytAAf' and rowid < 'AAATCjAA6AAFp+bAA6'' and rowid >= 'AAATCjAA6AAFp+bAA6' and rowid < 'AAATCjAA6AAF6RAAAQ'' and rowid >= 'AAATCjAA6AAHJjDAAV' and rowid < 'AAATCjAA6AAIR+jAAL'' and rowid >= 'AAATCjAA6AAIR+jAAL' and rowid < 'AAATCjAA6AAKomNAAE'' and rowid >= 'AAATCjAA6AAKomNAAE' and rowid < 'AAATCjAA6AALdcMAA3'' and rowid >= 'AAATCjAA6AALdcMAA3' and rowid < 'AAATCjAA9AAACuuAAl'' and rowid >= 'AAATCjAA9AAACuuAAl' and rowid < 'AAATCjAA9AABgD6AAD'' and rowid >= 'AAATCjAA9AABgD6AAD' and rowid < 'AAATCjAA9AADiA2AAC'' and rowid >= 'AAATCjAA9AADiA2AAC' and rowid < 'AAATCjAA9AAEQMPAAT'' and rowid >= 'AAATCjAA9AAEQMPAAT'' 33 rows selected. SQL> select count(*) from BIGTABLE where 1=1 and rowid < AAATCjAA0AAAKAVAAd ; COUNT(*) ---------- 518712 SQL> select count(*) from BIGTABLE where 1=1 and rowid >= 'AAATCjAA9AAEQMPAAT'' ; COUNT(*) ---------- 1846369The problem is that your query implies that ROWID, and ROWNUM are classified in the same way. For small tables it is very often the case, but not for the larger tables. Oracle does not guarantee return records in the order the rowid. However usually it works this way.
You could test ensuring that get you the rownum after you ordered. And see if it works then.
select rn, mod, frow, rownum from (select rn, rownum frow, mod(rownum, 2000000) mod from (select rowid rn from bigtable order by rn) order by rn ) where mod = 0 /index of output table and show what LOCAL indexes and who are
I read the view of ALL_INDEXES here:
http://www.Stanford.edu/dept/ITSS/docs/Oracle/10G/server.101/b10755/statviews_1061.htm
But I still don't know how to query follows:
1. display the name of the table, the index name and flag Y/N 'Is the local index' and a flag "is the overall index.
The application should output table index and show what indexes are LOCAL and which are not.
How to write this query?
My original request:
2 I understand that global index for partitioned tables is a chunk of data referencing all the partitions table in the single room, but Local index is partitioned itself there are several parts each one or more partitions to reference table?select table_name, Index_Name, Uniqueness, Partitioned, decode(Partitioned, 'NO', 'Global','Local') GlobalOrLocal from all_indexes where table_name = 'MyTABLE'
Published by: CharlesRoos on October 6, 2010 12:45 AMCharlesRoos wrote:
I read the view of ALL_INDEXES here:
http://www.Stanford.edu/dept/ITSS/docs/Oracle/10G/server.101/b10755/statviews_1061.htm
But I still don't know how to query follows:1. display the name of the table, the index name and flag Y/N 'Is the local index' and a flag "is the overall index.
The application should output table index and show what indexes are LOCAL and which are not.
How to write this query?
My original request:
select table_name, Index_Name, Uniqueness, Partitioned, decode(Partitioned, 'NO', 'Global','Local') GlobalOrLocal from all_indexes where table_name = 'MyTABLE'That seems Ok to me.
2 I understand that for partitioned tables index global is a big piece of data referencing all the partitions table in the single room,
Yes.
but the Local index is partitioned itself there several pieces for each reference one or several partitions table?
Almost right: each refers to score exactly one table. I.e. index partitioning is 'aligned' with the partitioning of the table.
How to call user B to drop/create an indexes on a table owned by the user has?
Hello!
We have the following situation:
= > user B has a table that has an index
= > user connects to the database and must have sufficient privileges or the ability to drop/create an index for a table owned by the user B.
Since there are several different schemas in the database, it is not possible to grant the privilege "to create any index' or 'delete any index '.
for the user.
= > to do even more complicated: the necessary procedure must not belong to user B
I tried to solve this problem with a stored procedure (which belongs to user C). Why do we use user C? C the user has several packages,
procedures and functions that get used by other users (for example for purposes of logging, refresh materialized views,...)
So the logic is:
= > user A calls user procedure C. In this procedure the call "run immediately" ALTER SESSION SET CURRENT_SCHEMA = B' "»
is executed successfully. The next step, the < drop index B.i1 > statement would get executed. But this statement fails with the
exception ' ORA-01031: insufficient privileges ".
If this procedure is created in the schema of the user B then everything works fine - but because of our current design of the database, this procedure
must belong to the user C.
Does anyone know a solution to this problem?
Any help will be appreciated
Rgds
JHI think you need the privilege DROP_ANY_INDEX directly to user C.
Need help on rewriting query for the DOMAIN CONTEXT index
Hello
I'd be really grateful if someone could give me a tip how to rewrite the query so that the DOMAIN INDEX is executed as the last and not the first... According to the plan to explain it...
What I want: I want to index FIELD CONTAINS search for text ONLY for ITEMS that are extracted from the inner query (table MS_webarticlecache)...
Because it seems now DOMAIN INDEx is executed first on all the MS_ARTICLE table and then filtered by inner query ID's...
This query execution time is now around 86seconds... Inner query has all the indexes for SID_SUBCLIPPING and DATE_ARTICLE... (seen in line 3 of explain plan) If this one is fast and returns the unique id by grouping it and concating keywords...
Without text... search results are retrieved in 3 seconds...
DOMAIN index is created with Oracle 11 g FILTER BY ID, ART_DATE... and is on the MS_ARTICLE table and the ORATEXT seen on the sql column...
Table MS_ARTICLE has 1.8mil lines...
MS_WEBCACHEARTICLE table has cca. 2 lines of millet
SQL:
SELECT A.*, B.KEYWORDS OF
MS_ARTICLE HAS
JOIN THE
(SELECT be, wm_concat (keywords) "KEY words" FROM MS_webarticlecache WHERE SID_SUBCLIPPING IN ('LEK', "KRKA") AND DATE_ARTICLE > = TRUNC(SYSDATE-400) AND DATE_ARTICLE < = TRUNC (SYSDATE) GROUP BY be) B
WE
A.ID = B.ID_ARTICLE AND CONTAINS (A.ORATEXT, 'IMMUNAL', 1) > 0
Here is explain plan:
Plan
SELECT STATEMENT ALL_ROWSCost: 1 K bytes: cardinality K 16: 237
1 FIELD INDEX INDEX (DOMAIN) PRESCLIP. ART_IDX cost: 120
TABLE 2 ACCESS BY INDEX ROWID TABLE PRESCLIP.MS_ARTICLE cost: cardinality K bytes: 5 775: 237
3 INDEX RANGE SCAN INDEX PRESCLIP. WEBCACHE_SUBCLIPDATE cost: cardinality 10: 964
TABLE ACCESS BY INDEX ROWID TABLE PRESCLIP.MS_WEBARTICLECACHE cost 4: 250 octets: 45 K cardinality: 931
5 INLIST ITERATOR
Cost of 6 HASH JOIN: 1 K bytes: cardinality K 16: 237
7 FILTER
GROUP 8 SORT BY cost: 1 K bytes: cardinality K 16: 237
Thank you very much for the help.
KrisNo, dbms_stats.gather_index_stats should be enough I think. From RECONSTRUCTION vs FULL - on rebuilding mode Oracle rebuilt just the table $I from scratch (it creates a temporary table, fills and then current exchanges and the new tables). It should be much faster that the FULL optimization, where the picture remains the same and only its content changes. The resulting table will be more compact, too.
Indexing for loop while seizing the unique values in table
Hi all
I have another question. Overall, I have a table and I want to take each element of this array. My thoughts of how do are the following:
I use a loop for the indexing of my table. Then I create a local variable outside of the loop in order to get the individual elements of the array. But it does not work I think because the local variable is not updated at each iteration.
Also, it feels like there is a more elegant way to do what I want to do.
Can someone give me some advice to solve my problem?
Thank you very much.
Best regards
Tresdin
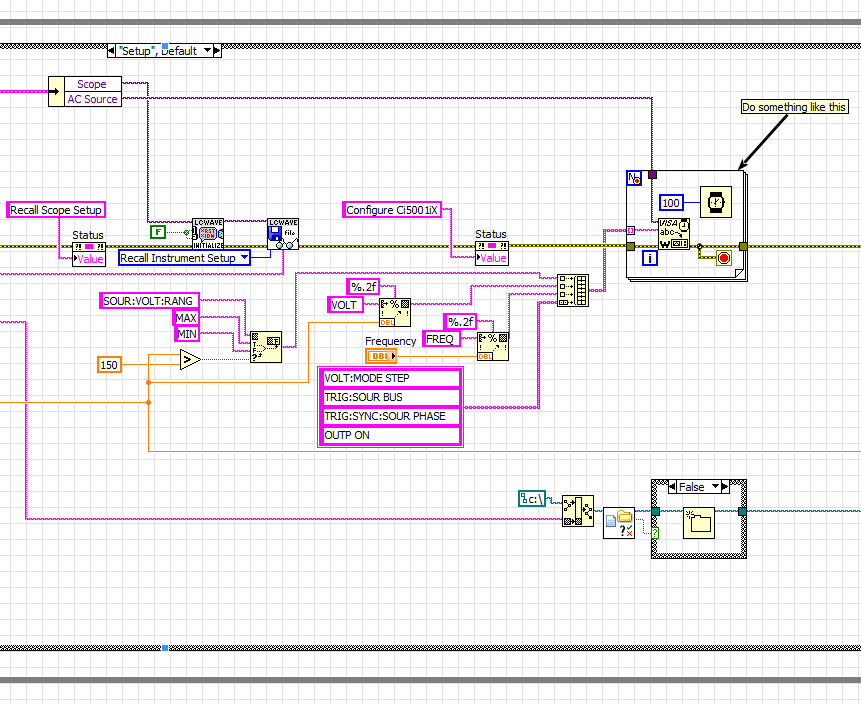
I don't know why you are so hung up with a local variable to send sequential orders of VISA.
Here's what I do:
That sends commands to the SCPI 7 to my AC source with a delay of 100 ms between each command sent.
Hello
I have a loop 'for' which can take different number of iterations according to the number of measures that the user wants to do.
Inside this loop, I'm auto-indexation four different 1 d arrays. This means that the size of the tables will be different in the different phases of the execution of the program (the size will equal the number of measures).
My question is: the auto-indexation of the tables with different sizes will affect the performance of the program? I think it slows down my Vi...
Thank you very much.
My first thought is that the compiler to the LabVIEW actually removes the Matlab node because the outputs are not used. Once you son upward, LabVIEW must then call Matlab and wait for it to run. I know from experience, the call of Matlab to run the script is SLOW. I also recommend to do the math in native LabVIEW.
Parent index for the data in a table?
Is there a way to index a child table with a function to include a column from a parent table?
Example:
I want to see how many children live in a zip code (and their address is listed with their parents)
Select count (*)
class c of child, parent p
where c.parent_id = p.parent_id
and p.zipcode = "12345"
Is there a way to make an index of children with a function that gets parents zip code?
Thanks for the help?
An index on the child table can reference only the columns of the child table. You can't have an index on the child table that is based on information from the parent table.
There are the function-based index, but they may involve only constants and deterministic functions (and, of course, the columns of the table). For example, the child table could have a clue on UPPER (name), where last_name is a column of the table, but he could not have a clue about get_zip (parent_id), where get_zip is a function defined by the user who queries the parent table.
Well - you "might" have a functional indication if you did to be deterministic, but it is not recommended because if the changed zip_code parent would really not deterministic and the change would not be included in the index.
This apart from this code will work properly if the zip_code data does not change:
CREATE TABLE parent (COL1 number primary key, zip VARCHAR2 (5))
create the child table (col1 number, parent_key number);create or replace function get_zip (number p_key) return deterministic varchar2 as
v_zip varchar2 (5);
Start
Select zip from v_zip of the parent where col1 = p_key;
Return v_zip;
end;/
create indexes on children (get_zip (parent_key)) child_zip;
Maybe you are looking for
-
Bookmarks imported into IE but only 1 file migrated
I tried to import my bookmarks from IE 8 following the process described. It seemed to work until I looked at the imported list and saw that only the first record of my many favorites is listed under imported IE Favorites. How can I get the rest of m
-
EOS Rebel T3 Led display has two lines black and white grainy to and controls are frozen help
When the unit is powered on any of the controls development works and the LED screen has only black and white grainy lines above. Tried to remove the battery to restart made no difference. If you have an idea of what happens to your help would be app
-
Photosmart Premium C310a worked wireless for 2 years is suddenly dissconnected
I have been successfully using my Photosmart C310a for 2 years. I used a day earlier this week, and the next he said: it is disconnected. The State of the network printer shows that it is connected to my network - the same network, use my laptop and
-
Tunnel of IOS Interface IKE aggressive mode
I had a pen test scan on a few of my routers and she claims that IKE aggressive Mode of operation are my IOS routers. I'm having a problem to know how to disable this option in the version of IOS 12.4 (24) T. I can find it on other platforms, but not
-
VPN site to Site between 6.3 (3) PIX and PIX 7.0 (1)
Hi all I am configuring a VPN site-to site between my office and a new site. This is my first time doing a real VPN site to site, in the past we have always just used MS PPTP VPN. My office firewall is a 6.3 (3) 506th PIX running, and unfortunately t