Example usage of 'ctx_doc.markup '?
I am new to Oracle and I'm not sure how to use the function "ctx_doc.markup".I tried the example on the right: highlighted in the document by using the ctx_doc.highlight procedure , but I get the following error:
Error starting at line 6 in command:
declare markedup clob default empty_clob();
begin
ctx_doc.markup(index_name => 'text_index', textkey => '11885', text_query => '{FUZZY({hello},,,W),FUZZY({john},,,W)}', restab => markedup, tagset => 'HTML_DEFAULT');
end;
Error report:
ORA-20000: Oracle Text error:
DRG-50857: oracle error in drvdoc.reslob_chk
ORA-22275: invalid LOB locator specified
ORA-06512: at "CTXSYS.DRUE", line 160
ORA-06512: at "CTXSYS.CTX_DOC", line 2198
ORA-06512: at line 3
20000. 00000 - "%s"
*Cause: The stored procedure 'raise_application_error'
was called which causes this error to be generated.
*Action: Correct the problem as described in the error message or contact
the application administrator or DBA for more information.Edit: Also, should I use memory or table markup-ing? In memory seems better, but I don't really know the difference.
Published by: 981243 on February 1, 2013 12:12 AM
I guess you use multibyte characters, and this is a problem with
amt number := 200;
line varchar2(200);
VARCHAR2 (200) is measured in bytes, default, but 200 characters may require more than 200 bytes to store.
If change you it to:
amt number := 200;
line varchar2(400);
It then works OK?
Tags: Database
Similar Questions
-
How can I better make ctx_doc.markup for a lot/set of documents?
Hello
I'm working on a system that stores chat messages in a table where the body of the message is stored in a CLOB column. I start to implement a message text using Oracle text search and seeks to use the functionality of ctx_doc.markup to the markup for the search terms. The message table is a bit like:
(Message) CREATE TABLE
ID NUMBER (19.0),.
sender NUMBER (19.0),.
beneficiary, NUMBER (19.0),.
received_at TIMESTAMP (6).
CLOB data,
)
and we have an index of text in context on the 'data' column and 'contains' queries against it work very well. When I was looking to add capacity to the markup for the search terms, I was a little surprised that there doesn't seem to be an easy way to markup a range of results.
What I plan to do is essentially:
Start
ctx_doc. Markup (index_name = > 'MESSAGE_DATA_TXT_IDX',)
textkey = > '2523992',
text_Query = > "test" ', "
restab = > "message_search_result_markup"
query_id = > '4',
tagset = > 'TEXT_DEFAULT');
end
So in my case, a search can lead to hundreds of returned messages. Now in order to tag each one, I have to do a "ctx_doc.markup" for each of them, which is hundreds of times that seems horribly inefficient. Keep in mind that all this is done in a Java web service.
So my first question is, why "tagging" does not have a list of IDs to be passed to the 'textkey? That would make things much simpler as:
ctx_doc. Markup (index_name = > 'MESSAGE_DATA_TXT_IDX',)
textkey = > '2523992,2523993,2523994,2523995',
text_Query = > "test" ', "
restab = > "message_search_result_markup"
query_id = > '4',
tagset = > 'TEXT_DEFAULT');
who would then end with 4 rows with query_id 4 in the message_search_result_markup table.
Then I thought well, since I generate the code SQL in Java, I can add it as a lot of these calls in the begin/end block
Start
ctx_doc. Markup (...);
ctx_doc. Markup (...);
ctx_doc. Markup (...);
ctx_doc. Markup (...);
end
Basically, one for each message. But now I have the problem of linking a net result towards the actual message from the strong result does not store the primary key of the message that is passed as the 'textkey. If the schema of the table of restab would be something like
create the table message_search_result_markup (query_id number, varchar2, clob document textkey);
So I have a unique query_id for each request and be able to easily retrieve all results of markup and return them along with other data of the corresponding messages such as sender, recipient, timestamp, etc..
So now I think it's for each "textkey' I have, I have to create a unique query_id which is not so simple because everything is multithreaded and multiprocess and different queries can return the same messages, so I couldn't just use the textkey as the query_id.
Does anyone have any better suggestions/ideas?
Remember I want to minimize the number of SQL queries, I have to do Java, ideally only have to do 1 query for the message, 1 search query markup messages found and 1 more request for the marked results.
You can write a function defined by the user to the ctx_doc.markup procedure, so that you can use it in a SQL query. Please see the demo below.
Scott@orcl12c >-table data and the index to test:
Scott@orcl12c > CREATE TABLE message
2 (id NUMBER (19.0),)
3 sender NUMBER (19.0),.
4 recipient NUMBER (19.0),.
5 received_at TIMESTAMP (6).
6 CLOB data)
7.
Table created.
Scott@orcl12c > INSERT ALL
2 IN THE VALUES of the message (id, data)
3 (1, ' I "m work on a system that stores chat messages in a table where the body of the message)
4 stored in a CLOB column. I'm starting to implement a message using Oracle's full-text search
5 text and I want to use the functionality of ctx_doc.markup to the markup for the search terms.
6 the message table is a bit like :')
7 IN VALUES message (id, data)
8 (2, ' and we have a hint of context on queries column text and "contains" "data" against her)
9 work very well. When I was looking to add capacity to the markup for the search terms, I was a little
10 surprised that there doesn't seem to be an easy way to markup a range of results. ')
11 SELECT * FROM DUAL
12.
2 rows created.
Scott@orcl12c > CREATE INDEX message_data_idx message WE (data) INDEXTYPE IS CTXSYS. FRAMEWORK
2.
The index is created.
Scott@orcl12c >-function defined by the user to the ctx_doc.markup procedure:
Scott@orcl12c > your_markup FUNCTION to CREATE or REPLACE
2 (p_index_name IN VARCHAR2,
3 p_textkey in VARCHAR2,
4 p_text_query IN VARCHAR2,
5 p_plaintext IN DEFAULT BOOLEANTRUE,
6 p_starttag IN VARCHAR2 DEFAULT '<>
7 p_endtag IN VARCHAR2 DEFAULT ' > '.
8 p_key_type IN VARCHAR2 DEFAULT 'ROWID')
9 BACK CLOB
10 AS
11 v_clob CLOB.
BEGIN 12
13 CTX_DOC. SET_KEY_TYPE (p_key_type);
14 CTX_DOC. MARKUP
15 (index_name-online p_index_name,
16 textkey-online p_textkey,
17 text_query-online p_text_query,
18 restab-online v_clob,
19 in clear-online p_plaintext,
starttag 20-online p_starttag,
21 endtag-online p_endtag);
22 RETURN v_clob;
23 END your_markup;
24.
The function is created.
Scott@orcl12c > SHOW ERRORS
No errors.
Scott@orcl12c >-query:
Scott@orcl12c > kwic FORMAT A60 WORD_WRAPPED COLUMN
Scott@orcl12c > SELECT id,.
2 your_markup
3 ("message_data_idx",
4 ROWID,
KWIC 'column' 5)
Message 6 OF
7 WHERE CONTAINS (data, "column") > 0
8.
ID KWIC
---------- ------------------------------------------------------------
1 I'm working on a system that stores chat messages in a
table where the body of the message is
stored in a CLOB
>. I started to implement a message using Oracle full text search
Text and I try to use the ctx_doc.markup function for
the markup for the search terms.
The message table is a bit like:
2 and we have an index of text in context on the 'data'
> and "contains a" queries against it
work very well. When I was looking to add the ability to
markup for the search terms, I was a little
surprised that there doesn't seem to be an easy way to
tag a range of results.
2 selected lines.
-
Example usage of CaptionSource_MacroExpression anywhere?
I use Visual c# to develop a custom user interface and I'm trying to understand how to move an expression of format (IE. "% ProgressTextLongName % ProgressPercentLongName %') using CaptionSources.CaptionSource_MacroExpression"
Method of ConnectCaption() of AxExecutionViewMgr and FormatExpression of the CaptionConnection property. I use the following code to do it:
CaptionConnection cc = axExecutionViewMgr.ConnectCaption(axLabel2, CaptionSources.CaptionSource_MacroExpression, true); cc.FormatExpression = "%ProgressTextLongName% %ProgressPercentLongName%";
But all the label says "the expression cannot be empty. He says this even though I perform an execution of a sequence. Are there examples that show how to use this expression of macro anywhere?
Just a guess, but since it is an expression, it probably takes quotes to make a valid string expression:
CC. FormatExpression = "\"%ProgressTextLongName% % ProgressPercentLongName%\'. » ;
-
CTX_DOC. MARKUP in the html section groups
Hi all
Running Oracle 9.2.0.8 on AIX...
I created full-text indexes Oracle by using the following parameters:
Now, my question is... I want to stress the terms of the query, using the CTX_DOC.markup procedure. It comes, since I was a user_data_store that combines 3 columns of data in a CLOB with sections HTML predefined, what is the best way to extract individual sections for display?ctx_ddl.create_preference( 'crt_user_datastore_en', 'user_datastore' ); ctx_ddl.set_attribute( 'crt_user_datastore_en', 'procedure', 'ctxsys_multi_index_en_prc' ); ctx_ddl.set_attribute('crt_user_datastore_en', 'output_type', 'CLOB'); ctx_ddl.create_preference( 'crt_user_datastore_fr', 'user_datastore' ); ctx_ddl.set_attribute( 'crt_user_datastore_fr', 'procedure', 'ctxsys_multi_index_fr_prc' ); ctx_ddl.set_attribute('crt_user_datastore_fr', 'output_type', 'CLOB'); CTX_DDL.create_preference('CRT_PREF_EN','BASIC_WORDLIST'); ctx_ddl.set_attribute('CRT_PREF_EN','FUZZY_MATCH','ENGLISH'); ctx_ddl.set_attribute('CRT_PREF_EN','STEMMER','ENGLISH'); ctx_ddl.set_attribute('CRT_PREF_EN','SUBSTRING_INDEX','TRUE'); CTX_DDL.create_preference('CRT_PREF_FR','BASIC_WORDLIST'); ctx_ddl.set_attribute('CRT_PREF_FR','FUZZY_MATCH','FRENCH'); ctx_ddl.set_attribute('CRT_PREF_FR','STEMMER','FRENCH'); ctx_ddl.set_attribute('CRT_PREF_FR','SUBSTRING_INDEX','TRUE'); CTX_DDL.create_section_group('CRT_HTML_SECTION','HTML_SECTION_GROUP'); CTX_DDL.add_zone_section('CRT_HTML_SECTION', 'title', 'TITLE'); CTX_DDL.add_zone_section('CRT_HTML_SECTION', 'body', 'BODY'); ctx_ddl.create_preference('CRT_LEXER_EN', 'BASIC_LEXER'); ctx_ddl.set_attribute('CRT_LEXER_EN', 'skipjoins', '-'); ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'index_text', 'YES'); ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'base_letter', 'YES'); ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'index_stems', 'ENGLISH'); ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'index_themes', 'YES'); ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'theme_language', 'ENGLISH'); ctx_ddl.create_preference('CRT_LEXER_FR', 'BASIC_LEXER'); ctx_ddl.set_attribute('CRT_LEXER_FR', 'skipjoins', '-'); ctx_ddl.set_attribute ( 'CRT_LEXER_FR', 'index_text', 'YES'); ctx_ddl.set_attribute ( 'CRT_LEXER_FR', 'base_letter', 'YES'); ctx_ddl.set_attribute ( 'CRT_LEXER_FR', 'index_stems', 'FRENCH'); ctx_ddl.set_attribute ( 'CRT_LEXER_FR', 'index_themes', 'YES'); ctx_ddl.set_attribute ( 'CRT_LEXER_FR', 'theme_language', 'FRENCH'); end; CREATE INDEX MULTI_CONTENT_EN_IDX ON CONTENTS (top_html_content_en) INDEXTYPE IS CTXSYS.CONTEXT parameters ('filter ctxsys.null_filter DATASTORE crt_user_datastore_en LEXER CRT_LEXER_EN wordlist CRT_PREF_EN section group CRT_HTML_SECTION'); CREATE INDEX MULTI_CONTENT_FR_IDX ON CONTENTS (top_html_content_fr) INDEXTYPE IS CTXSYS.CONTEXT parameters ('filter ctxsys.null_filter DATASTORE crt_user_datastore_fr LEXER CRT_LEXER_fr wordlist CRT_PREF_fr section group CRT_HTML_SECTION');
The reason for my dilemma is that the front-end .NET application assembles the page content into pieces, by injecting a content server here and there and I can just refer all marked content pieces as a CLOB.
is this just a bad design from me approach? Is the only solution, given the implementation a CLOB, using a combination of instr and substr on the CLOB to extract the part I need?
Another solution that has just occurred to me... instead of creating groups of sections html in my user_data_store procedure, I could inject more XML, then use a xml_section_group, so I can take advantage of some features of XML on the clob which are perhaps more effective than simply instr/substr combination?
Thanks for advice/ideas...
Edited by: pl_sequel may 4, 2010 15:34If you spend at least 10g, you can use ctx_doc.snippet. In 9i, you can use ctx_doc.highlight to get the offsets and lengths, instead of using substr and InStr. You can use it to write your own code snippet function. Please see the example below.
SCOTT@orcl_11g> -- test environment: SCOTT@orcl_11g> create table contents 2 (id number primary key, 3 title varchar2 (15), 4 body clob, 5 top_html_content_en varchar2 (1)) 6 / Table created. SCOTT@orcl_11g> insert all 2 into contents values (1, 'title1 test', 'word3 word2 body1 test word1 word2 word3', null) 3 into contents values (2, 'title2 tests', 'word3 word2 word1 body2 tested word1 word2 word3', null) 4 into contents values (3, 'title3 test', 'word3 word2 word1 body3 testing word1 word2 word3', null) 5 select * from dual 6 / 3 rows created. SCOTT@orcl_11g> create or replace procedure ctxsys_multi_index_en_prc 2 (p_rowid in rowid, 3 p_clob in out nocopy clob) 4 as 5 begin 6 for r in 7 (select * from contents 8 where rowid = p_rowid) 9 loop 10 dbms_lob.writeappend (p_clob, 4, ''); 11 dbms_lob.writeappend (p_clob, length (r.id), r.id); 12 dbms_lob.writeappend (p_clob, 5, ' '); 13 dbms_lob.writeappend (p_clob, 7, ''); 14 dbms_lob.writeappend (p_clob, length (r.title), r.title); 15 dbms_lob.writeappend (p_clob, 8, ' '); 16 dbms_lob.writeappend (p_clob, 6, ''); 17 dbms_lob.append (p_clob, r.body); 18 dbms_lob.writeappend (p_clob, 7, ''); 19 end loop; 20 end ctxsys_multi_index_en_prc; 21 / Procedure created. SCOTT@orcl_11g> show errors No errors. SCOTT@orcl_11g> begin 2 ctx_ddl.create_preference( 'crt_user_datastore_en', 'user_datastore' ); 3 ctx_ddl.set_attribute( 'crt_user_datastore_en', 'procedure', 'ctxsys_multi_index_en_prc' ); 4 ctx_ddl.set_attribute('crt_user_datastore_en', 'output_type', 'CLOB'); 5 6 CTX_DDL.create_preference('CRT_PREF_EN','BASIC_WORDLIST'); 7 ctx_ddl.set_attribute('CRT_PREF_EN','FUZZY_MATCH','ENGLISH'); 8 ctx_ddl.set_attribute('CRT_PREF_EN','STEMMER','ENGLISH'); 9 ctx_ddl.set_attribute('CRT_PREF_EN','SUBSTRING_INDEX','TRUE'); 10 11 CTX_DDL.create_section_group('CRT_HTML_SECTION','HTML_SECTION_GROUP'); 12 CTX_DDL.add_zone_section('CRT_HTML_SECTION', 'title', 'TITLE'); 13 CTX_DDL.add_zone_section('CRT_HTML_SECTION', 'body', 'BODY'); 14 15 ctx_ddl.create_preference('CRT_LEXER_EN', 'BASIC_LEXER'); 16 ctx_ddl.set_attribute('CRT_LEXER_EN', 'skipjoins', '-'); 17 ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'index_text', 'YES'); 18 ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'base_letter', 'YES'); 19 ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'index_stems', 'ENGLISH'); 20 ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'index_themes', 'YES'); 21 ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'theme_language', 'ENGLISH'); 22 end; 23 / PL/SQL procedure successfully completed. SCOTT@orcl_11g> CREATE INDEX MULTI_CONTENT_EN_IDX ON CONTENTS 2 (top_html_content_en) 3 INDEXTYPE IS CTXSYS.CONTEXT 4 parameters 5 ('filter ctxsys.null_filter 6 DATASTORE crt_user_datastore_en 7 LEXER CRT_LEXER_EN 8 wordlist CRT_PREF_EN 9 section group CRT_HTML_SECTION') 10 / Index created. SCOTT@orcl_11g> -- 10g method: SCOTT@orcl_11g> begin 2 ctx_doc.set_key_type ('PRIMARY_KEY'); 3 end; 4 / PL/SQL procedure successfully completed. SCOTT@orcl_11g> select id, 2 ctx_doc.snippet 3 ('MULTI_CONTENT_EN_IDX', 4 id, 5 '$test') 6 keywords_in_context 7 from contents 8 where contains (top_html_content_en, '$test') > 0 9 / ID KEYWORDS_IN_CONTEXT ---------- --------------------------------------------- 1 1 title1 test word3 word2 body1 test word1 word2 word3 2 2 title2 tests word3 word2 word1 body2 tested word1 word2 word3 3 3 title3 test word3 word2 word1 body3 testing word1 word2 word3 SCOTT@orcl_11g> -- 9i method: SCOTT@orcl_11g> create or replace function my_snippet 2 (p_index_name in varchar2, 3 p_primary_key in number, 4 p_query in varchar2, 5 p_context in number default 0) 6 return varchar2 7 as 8 v_document clob; 9 v_hightab ctx_doc.highlight_tab; 10 v_start varchar2 (2000); 11 v_end varchar2 (2000); 12 v_keyword varchar2 (2000); 13 v_kwic varchar2 (2000); 14 begin 15 ctx_doc.set_key_type ('PRIMARY_KEY'); 16 ctx_doc.filter ('MULTI_CONTENT_EN_IDX', p_primary_key, v_document, TRUE); 17 ctx_doc.highlight ('MULTI_CONTENT_EN_IDX', p_primary_key, p_query, v_hightab, TRUE); 18 for i in 1 .. v_hightab.count loop 19 if p_context > 0 then 20 v_start := substr (v_document, 1, v_hightab(i).offset - 1); 21 if i > 1 then 22 v_start := substr (v_start, v_hightab(i-1).offset + v_hightab(i-1).length); 23 end if; 24 v_start := ' ' || rtrim (v_start); 25 v_start := substr (v_start, instr (v_start, ' ', -1, p_context)); 26 if i < v_hightab.count then 27 v_end := substr (v_document, 1, v_hightab(i+1).offset - 1); 28 else 29 v_end := v_document; 30 end if; 31 v_end := substr (v_end, v_hightab(i).offset + v_hightab(i).length); 32 v_end := ltrim (v_end) || ' '; 33 v_end := substr (v_end, 1, instr (v_end, ' ', 1, p_context) - 1); 34 end if; 35 v_keyword := ' ' || substr (v_document, v_hightab(i).offset, v_hightab(i).length) || ' '; 36 v_kwic := v_kwic || v_start || v_keyword || v_end || ' ... '; 37 end loop; 38 return substr (rtrim (v_kwic, '...'), 1, 2000); 39 end my_snippet; 40 / Function created. SCOTT@orcl_11g> show errors No errors. SCOTT@orcl_11g> variable words number SCOTT@orcl_11g> exec :words := 0 PL/SQL procedure successfully completed. SCOTT@orcl_11g> column keywords_in_context format a45 word_wrapped SCOTT@orcl_11g> select id, 2 my_snippet 3 ('MULTI_CONTENT_EN_IDX', 4 id, 5 '$test', 6 :words) 7 keywords_in_context 8 from contents 9 where contains (top_html_content_en, '$test') > 0 10 / ID KEYWORDS_IN_CONTEXT ---------- --------------------------------------------- 1 test ... test ... 2 tests ... tested ... 3 test ... testing ... SCOTT@orcl_11g> exec :words := 1 PL/SQL procedure successfully completed. SCOTT@orcl_11g> / ID KEYWORDS_IN_CONTEXT ---------- --------------------------------------------- 1 title1 test word3 ... body1 test word1 ... 2 title2 tests word3 ... body2 tested word1 ... 3 title3 test word3 ... body3 testing word1 ... SCOTT@orcl_11g> exec :words := 2 PL/SQL procedure successfully completed. SCOTT@orcl_11g> / ID KEYWORDS_IN_CONTEXT ---------- --------------------------------------------- 1 1 title1 test word3 word2 ... word2 body1 test word1 word2 ... 2 2 title2 tests word3 word2 ... word1 body2 tested word1 word2 ... 3 3 title3 test word3 word2 ... word1 body3 testing word1 word2 ... SCOTT@orcl_11g> exec :words := 3 PL/SQL procedure successfully completed. SCOTT@orcl_11g> / ID KEYWORDS_IN_CONTEXT ---------- --------------------------------------------- 1 1 title1 test word3 word2 body1 ... word3 word2 body1 test word1 word2 word3 ... 2 2 title2 tests word3 word2 word1 ... word2 word1 body2 tested word1 word2 word3 ... 3 3 title3 test word3 word2 word1 ... word2 word1 body3 testing word1 word2 word3 ... SCOTT@orcl_11g> -
DRG-11101 on several simultaneous searches with CTX_DOC. MARKUP.
I use 11 GR 2 XE with .NET.
I'm getting the following exception on my DOMARKUP the stored procedure call that calls ctx_doc.markup:
NEM DOMARKUP:{"ORA-20000: Oracle Text error: DRG-11101: failed to open file C:\\Windows\\TEMP\\drgib3 \nORA-06512: at \"CTXSYS.DRUE\", line 160 ORA-06512: at \"CTXSYS.CTX_DOC\", line 2198 ORA-06512: at \"ME.DOMARKUP\", line 9 ORA-06512: at line 1"}
The circumstances are as follows. Quite simply, I (the user) am search my search engine. When I perform several searches at the same time, this error occurs. I feel that the ctx_doc.markup is read/write from/to a temporary file for some reason any and the same one who!create or replace PROCEDURE DOMARKUP ( C OUT CLOB , ID IN VARCHAR2 , Q IN VARCHAR2 ) AS BEGIN ctx_doc.markup(index_name => 'text_index', textkey => ID, text_query => Q, restab => C, tagset => 'HTML_DEFAULT'); END DOMARKUP;
Published by: 981243 on February 27, 2013 23:24
Published by: 981243 on February 27, 2013 23:25The bulk has been reported with excerpt - so I guess that all the ctx_doc functions are affected.
I'm not aware of any workaround, but highly recommend to contact support to ask this question and try to get the scaling bug.
-
Hi all
Is it possible to markup text in pdf or doc with ctx_doc.markup files?:) I had this error several times. Because your table markup is not structured according to the directives of the Oracle. See here
http://download.Oracle.com/docs/CD/B19306_01/text.102/b14218/arestab.htm#i635134 -
ctx_doc. Markup html if break keywords found in the html tags
Running Oracle 9.2.0.8
I said to me the following indexes:
In my user data store, I build an XML representation of the content, by wrapping each column with a XML tag clob value and the content of CLOB is ignored with CDATA blocks, as it contains various html tags.DROP INDEX MULTI_CONTENT_EN_IDX; DROP INDEX MULTI_CONTENT_FR_IDX; Begin CTX_DDL.drop_preference('CRT_PREF_EN'); CTX_DDL.drop_preference('CRT_PREF_FR'); CTX_DDL.drop_section_group('CRT_XML_SECTION'); ctx_ddl.drop_preference('crt_user_datastore_en'); ctx_ddl.drop_preference('crt_user_datastore_fr'); ctx_ddl.drop_preference('CRT_LEXER_FR'); ctx_ddl.drop_preference('CRT_LEXER_EN'); ctx_ddl.create_preference( 'crt_user_datastore_en', 'user_datastore' ); ctx_ddl.set_attribute( 'crt_user_datastore_en', 'procedure', 'ctxsys_multi_index_en_prc' ); ctx_ddl.set_attribute('crt_user_datastore_en', 'output_type', 'CLOB'); ctx_ddl.create_preference( 'crt_user_datastore_fr', 'user_datastore' ); ctx_ddl.set_attribute( 'crt_user_datastore_fr', 'procedure', 'ctxsys_multi_index_fr_prc' ); ctx_ddl.set_attribute('crt_user_datastore_fr', 'output_type', 'CLOB'); CTX_DDL.create_preference('CRT_PREF_EN','BASIC_WORDLIST'); ctx_ddl.set_attribute('CRT_PREF_EN','FUZZY_MATCH','ENGLISH'); ctx_ddl.set_attribute('CRT_PREF_EN','STEMMER','ENGLISH'); ctx_ddl.set_attribute('CRT_PREF_EN','SUBSTRING_INDEX','TRUE'); CTX_DDL.create_preference('CRT_PREF_FR','BASIC_WORDLIST'); ctx_ddl.set_attribute('CRT_PREF_FR','FUZZY_MATCH','FRENCH'); ctx_ddl.set_attribute('CRT_PREF_FR','STEMMER','FRENCH'); ctx_ddl.set_attribute('CRT_PREF_FR','SUBSTRING_INDEX','TRUE'); CTX_DDL.create_section_group('CRT_XML_SECTION','XML_SECTION_GROUP'); CTX_DDL.add_zone_section('CRT_XML_SECTION', 'title', 'title'); CTX_DDL.add_zone_section('CRT_XML_SECTION', 'content', 'content'); ctx_ddl.create_preference('CRT_LEXER_EN', 'BASIC_LEXER'); ctx_ddl.set_attribute('CRT_LEXER_EN', 'skipjoins', '-'); ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'index_text', 'YES'); ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'base_letter', 'YES'); ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'index_stems', 'ENGLISH'); ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'index_themes', 'YES'); ctx_ddl.set_attribute ( 'CRT_LEXER_EN', 'theme_language', 'ENGLISH'); ctx_ddl.create_preference('CRT_LEXER_FR', 'BASIC_LEXER'); ctx_ddl.set_attribute('CRT_LEXER_FR', 'skipjoins', '-'); ctx_ddl.set_attribute ( 'CRT_LEXER_FR', 'index_text', 'YES'); ctx_ddl.set_attribute ( 'CRT_LEXER_FR', 'base_letter', 'YES'); ctx_ddl.set_attribute ( 'CRT_LEXER_FR', 'index_stems', 'FRENCH'); ctx_ddl.set_attribute ( 'CRT_LEXER_FR', 'index_themes', 'YES'); ctx_ddl.set_attribute ( 'CRT_LEXER_FR', 'theme_language', 'FRENCH'); end; CREATE INDEX MULTI_CONTENT_EN_IDX ON CONTENTS (top_html_content_en) INDEXTYPE IS CTXSYS.CONTEXT parameters ('filter ctxsys.null_filter DATASTORE crt_user_datastore_en LEXER CRT_LEXER_EN wordlist CRT_PREF_EN section group CRT_XML_SECTION'); CREATE INDEX MULTI_CONTENT_FR_IDX ON CONTENTS (top_html_content_fr) INDEXTYPE IS CTXSYS.CONTEXT parameters ('filter ctxsys.null_filter DATASTORE crt_user_datastore_fr LEXER CRT_LEXER_fr wordlist CRT_PREF_fr section group CRT_XML_SECTION');
My point culminating procedure resembles the following:
I use SQLXML to retrieve the nodes (since I'm on XML_SECTION_GROUP), and stripping the CDATA blocks... then copy it into the out CLOB, back to the appellant.PROCEDURE highlight_query_result ( p_query_string_in IN VARCHAR2, p_index_name_in IN VARCHAR2, p_pk_id_in IN NUMBER, p_top_content_html_out IN OUT NOCOPY CLOB, p_content_html_out IN OUT NOCOPY CLOB, pn_error_ind_out OUT error_logs.error_log_id%TYPE ) IS l_clob CLOB; l_cdata_start_len INTEGER := LENGTH ('<![CDATA['); l_cdata_end_len INTEGER := LENGTH (']]>'); l_top_content CLOB; l_bottom_content CLOB; l_len INTEGER; xmldoc XMLTYPE; PROCEDURE cleanuptemplobs IS BEGIN IF DBMS_LOB.istemporary (l_top_content) = 1 THEN /* Free the temporary LOB locator: */ DBMS_LOB.freetemporary (l_top_content); END IF; IF DBMS_LOB.istemporary (l_bottom_content) = 1 THEN /* Free the temporary LOB locator: */ DBMS_LOB.freetemporary (l_bottom_content); END IF; END cleanuptemplobs; BEGIN pn_error_ind_out := 0; DBMS_LOB.createtemporary (l_top_content, TRUE); DBMS_LOB.createtemporary (l_bottom_content, TRUE); ctx_doc.markup (index_name => p_index_name_in, textkey => ctx_doc.pkencode (p_pk_id_in), text_query => p_query_string_in, restab => l_clob, plaintext => false, tagset => 'HTML_DEFAULT', starttag => '<span class="highlight">', endtag => '</span>' ); xmldoc := XMLTYPE.createxml (l_clob); IF xmldoc IS NOT NULL THEN IF xmldoc.EXISTSNODE ('//bottom_content/text()') = 1 THEN l_bottom_content := xmldoc.EXTRACT ('//bottom_content/text()').getclobval (); l_len := DBMS_LOB.getlength (l_bottom_content); DBMS_LOB.COPY (p_content_html_out, l_bottom_content, l_len - (l_cdata_start_len + l_cdata_end_len), 1, l_cdata_start_len + 1 ); END IF; IF xmldoc.EXISTSNODE ('//top_content/text()') = 1 THEN l_top_content := xmldoc.EXTRACT ('//top_content/text()').getclobval (); l_len := DBMS_LOB.getlength (l_top_content); DBMS_LOB.COPY (p_top_content_html_out, l_top_content, l_len - (l_cdata_start_len + l_cdata_end_len), 1, l_cdata_start_len + 1 ); END IF; END IF; -- cleanup to avoid memory leaks... cleanuptemplobs; EXCEPTION WHEN OTHERS THEN -- cleanup to avoid memory leaks... cleanuptemplobs; pn_error_ind_out := SQLCODE; log_package_error_prc ('search_pkg.highlight_query_result', SQLERRM, pn_error_ind_out ); END highlight_query_result;
Everything seems to work fine, until I find myself with a culmination of the keyword in a HREF... which basically breaks the page with no html tags valid on exit... such as:
I have the feeling that this could be due to CDATA and XML block... being escaped on output html tags, and even if null_filter is used for indexing, it ignores the html escape characters and indexes all content stream.<a href="http://www.linktowebsite.com/<span class="highlight">keyword</span>.shtml#obtain">How to request a copy of a <span class="highlight">keyword</span> already issued</a>
Any ideas?If what you have is html and you must keep intact, then it makes sense to use html_section_group instead of xml_section_group. The following creates a minimal test environment, reproduces the problem with the xml_section_group, and fixes the problem by using html_section_group. Lists of multiples and lexers words are not necessary to reproduce the problem. Markup draws in the field index tables, so what you do afterwards are not relevant to the problem. What follows is therefore only of creating the table with primary key, the insertion of a row of data, the creation of the Group of sections and index, display of chips and markup output. If refine you the code like this, which makes it much easier to understand and reproduce the problem and refine the cause.
SCOTT@orcl_11g> -- test environment: SCOTT@orcl_11g> -- table and data: SCOTT@orcl_11g> CREATE TABLE CONTENTS_TEST 2 (CONTENT_ID NUMBER(10) PRIMARY KEY, 3 CONTENT_HTML_CONTENT CLOB) 4 / Table created. SCOTT@orcl_11g> SET DEFINE OFF SCOTT@orcl_11g> Insert into CONTENTS_TEST 2 (CONTENT_ID, CONTENT_HTML_CONTENT) 3 Values 4 (1, 5 '<![CDATA[AIG - Program Overview]]> Introduction
6 Apprenticeship 7 ]]><![CDATA[AIG - Program Overview]]> Introduction
apprenticeship.html">Apprenticeship ]]><![CDATA[AIG - Program Overview]]> Introduction
Apprenticeship ]]> -
CTX_DOC. Limit size of MARKUP?
I use ctx_doc.markup to highlight the key word (s) within the clob column. When the clob column contains only less than 4,000 characters, he has no problem, but when faced with with more than 4000 clob column, I get
ORA-06502: PL/SQL: digital or value error: character string buffer too small
Anyone, any idea?
Thank youNever mind, I changed this line to
str := str || 'b ';Yes, I think it's because you call it from a select statement. The following works fine:
declare foo varchar2(32767); begin foo := highlight_keyword('ctx_test', '3999', 'b'); end; /When it is used in a select statement, you are now in a SQL rather than PL/SQL environment. Varchar2s SQL is limited to 4000 characters, and the error, try to copy a PL/SQL variable in a variable SQL that are not large enough.
-
Football game and the characters as markup. ? and!
I posted a few questions a few weeks ago on the same system I'm working on. It's basically a bunch of chat messages that are archived that we want to search. At this point, I'm trying to understand why Oracle Text behaves the way when it comes to some punctuation as characters I thought I configured the text with all index so that he would return and tagging these. Here are some examples of SQL that has the same issues:
I use the following function to the markup, so I can use it as part of a select query:
CREATE OR REPLACE FUNCTION my_markup (p_index_name IN VARCHAR2, p_textkey IN VARCHAR2, p_text_query IN VARCHAR2, p_plaintext IN BOOLEAN DEFAULT TRUE, p_starttag IN VARCHAR2 DEFAULT '<<<', p_endtag IN VARCHAR2 DEFAULT '>>>', p_key_type IN VARCHAR2 DEFAULT 'primary_key') RETURN CLOB AS v_clob CLOB; BEGIN CTX_DOC.SET_KEY_TYPE (p_key_type); CTX_DOC.MARKUP (index_name => p_index_name, textkey => p_textkey, text_query => p_text_query, restab => v_clob, plaintext => p_plaintext, starttag => p_starttag, endtag => p_endtag); RETURN v_clob; END my_markup;
Here is the sample table and some sample data:
create table search_test ( data_id number(19), test_data clob ); alter table search_test add constraint search_test_pk primary key ( data_id ) ; insert into search_test values (1, 'this is, the first. test sentence ?? with ., some ??? content! '); insert into search_test values (2, 'The quick, brown fox > jumps < over the lazy dog.'); insert into search_test values (3, 'Some !@#$%%^&*(()),.<>;:''"[]{}-_=+~ crazy char string '); insert into search_test values (4, 'this is, the first test sentence ?? with ., some ??? content! '); insert into search_test values (5, 'this is, the first; test sentence ?? with ., some ??? content! '); insert into search_test values (6, 'this is, the first: test sentence ?? with ., some ??? content! '); insert into search_test values (7, 'this is, the first? test sentence ?? with ., some ??? content! '); insert into search_test values (8, 'this is, the first! test sentence ?? with ., some ??? content! '); insert into search_test values (9, 'this is, the first@ test sentence ?? with ., some ??? content! '); insert into search_test values (10, 'this is, the first# test sentence ?? with ., some ??? content! '); insert into search_test values (11, 'this is, the first$ test sentence ?? with ., some ??? content! '); insert into search_test values (12, 'this is, the first% test sentence ?? with ., some ??? content! '); insert into search_test values (13, 'this is, the first^ test sentence ?? with ., some ??? content! '); insert into search_test values (14, 'this is, the first& test sentence ?? with ., some ??? content! '); insert into search_test values (15, 'this is, the first* test sentence ?? with ., some ??? content! '); insert into search_test values (16, 'this is, the first( test sentence ?? with ., some ??? content! '); insert into search_test values (17, 'this is, the first) test sentence ?? with ., some ??? content! '); insert into search_test values (18, 'this is, the first[ test sentence ?? with ., some ??? content! '); insert into search_test values (19, 'this is, the first] test sentence ?? with ., some ??? content! '); insert into search_test values (20, 'this is, the first{ test sentence ?? with ., some ??? content! '); insert into search_test values (21, 'this is, the first} test sentence ?? with ., some ??? content! '); insert into search_test values (22, 'this is, the first< test sentence ?? with ., some ??? content! '); insert into search_test values (23, 'this is, the first> test sentence ?? with ., some ??? content! '); insert into search_test values (24, 'this is, the first- test sentence ?? with ., some ??? content! '); insert into search_test values (25, 'this is, the first_ test sentence ?? with ., some ??? content! '); insert into search_test values (26, 'this is, the first= test sentence ?? with ., some ??? content! '); insert into search_test values (27, 'this is, the first+ test sentence ?? with ., some ??? content! '); insert into search_test values (28, 'this is, the first| test sentence ?? with ., some ??? content! '); insert into search_test values (29, 'this is, the first!! test sentence .. with ., some && content! ');And here's the text index definition:
BEGIN CTX_DDL.CREATE_PREFERENCE('test_lexer', 'BASIC_LEXER'); CTX_DDL.SET_ATTRIBUTE('test_lexer', 'printjoins', '~!@#$%^*()_-+={}[]:;<>,.?/'); CTX_DDL.CREATE_PREFERENCE('test_wordlist', 'BASIC_WORDLIST'); CTX_DDL.SET_ATTRIBUTE('test_wordlist', 'SUBSTRING_INDEX', 'YES'); CTX_DDL.SET_ATTRIBUTE('test_wordlist', 'PREFIX_INDEX', 'TRUE'); CTX_DDL.SET_ATTRIBUTE('test_wordlist', 'PREFIX_MIN_LENGTH', '3'); CTX_DDL.SET_ATTRIBUTE('test_wordlist', 'PREFIX_MAX_LENGTH', '6'); END; / CREATE INDEX search_test_text_idx on search_test(test_data) INDEXTYPE IS CTXSYS.CONTEXT PARAMETERS (' DATASTORE CTXSYS.DEFAULT_DATASTORE FILTER CTXSYS.NULL_FILTER STOPLIST CTXSYS.EMPTY_STOPLIST LEXER test_lexer SYNC (EVERY "sysdate+(10/(24*60*60))") WORDLIST test_wordlist');Therefore, since the index uses an empty list and all special characters are defined in the lexer as joins impression, I expected to research which one '. «, » ! 'or'?' to correspond to these, but this is not the case. E.e. when I run:
select data_id, my_markup('search_test_text_idx', data_id, 'first\?') from search_test where contains(test_data, 'first\?', 1) > 0Then, I get the following results:
DATA_ID MY_MARKUP('SEARCH_TEST_TEXT_IDX',DATA_ID,'FIRST\?') ------------------- -------------------------------------------------------------------------------- 1 this is, the <<<first>>>. test sentence ?? with ., some ??? content! 4 this is, the <<<first>>> test sentence ?? with ., some ??? content! 7 this is, the <<<first>>>? test sentence ?? with ., some ??? content! 8 this is, the <<<first>>>! test sentence ?? with ., some ??? content! 14 this is, the <<<first>>>& test sentence ?? with ., some ??? content! 28 this is, the <<<first>>>| test sentence ?? with ., some ??? content! 29 this is, the <<<first>>> !! test sentence .. with ., some && content! 7 rows selectedI expect not to see that line with id 7 and I expected the '?' to be included in the tag. Why does it return all of these lines and is at - it something I can do to get what I expected?
A second thing, I stumbled on who is probably related to this issue/question looking for multiples of these characters in a line, for example, a search for '?'. The markup still mark an inferior is specified in the search expression contains it:
select data_id, my_markup('search_test_text_idx', data_id, 'first. test sentence \?\?') from search_test where contains(test_data, 'first. test sentence \?\?', 1) > 0This returns:
DATA_ID MY_MARKUP('SEARCH_TEST_TEXT_IDX',DATA_ID,'FIRST.TESTSENTENCE\?\?') ------------------- -------------------------------------------------------------------------------- 1 this is, the <<<first. test sentence ?>>>? with ., some ??? content! 4 this is, the <<<first test sentence ?>>>? with ., some ??? content! 7 this is, the <<<first? test sentence ?>>>? with ., some ??? content! 8 this is, the <<<first! test sentence ?>>>? with ., some ??? content! 14 this is, the <<<first& test sentence ?>>>? with ., some ??? content! 28 this is, the <<<first| test sentence ?>>>? with ., some ??? content! 6 rows selectedAgain I have only see line with id 1 and all the two? in the end to be included in the tag. Why is not what I expected?
Okay, I think I can see what is happening. The doc:
- If a printjoins character is also defined as a punctuation character, the character is only treated as an alphanumeric character if the character immediately following it is a standard alphanumeric character or has been defined as a character printjoins and skipjoins.
... and...
- punctuation
- Specify the non-alphanumeric characters which, when they appear at the end of a Word, indicate the end of a sentence. The default values are period '. ', question mark'?' and exclamation mark "!".
- Characters which are defined as punctuation marks are removed from a token before full-text indexing. However, if a punctuation character is also defined as a printjoins character, the character is removed only when it is the last character in the token.
So question mark is getting charged at the end of chips. The solution for this is to erase punctuation. You can't really define punctuation NULL or a string empty, but you can set it to a space which has the same effect:
CTX_DDL. SET_ATTRIBUTE ('test_lexer', 'punctuation', ');
Your second question is because you have two question mark characters. In this case, the last is stripped, and it is indexed as a question mark. Try to set punctuation as above, and I think it will solve these two issues.
-
MARKUP (highlighted) and MULTI_COLUMN_DATASTORE
I'm passing a text index index_name parameter of MARKUP, which is a dummy field to MULTI_COLUMN_DATASTORE. However, MARKUP only returns the CLOB to the dummy field, not the rest of the columns.
What is the best way to MARKUP a "document" which is stored in a table, in several columns (columns are either VARCHAR2 in CLOB). I need each column would be markup (or HIGHLIGHT would be).
Otherwise, I can do the markup-ing myself, but in this case I would like to know, if there is a way to get all the terms that Oracle tried with. I use the ora-text FUZZY operator a lot, so I need to get the additional conditions that are generated (expanded?) by the FUZZY operator.
Published by: 981243 on February 4, 2013 05:22That doesn't sound right. The text via the data store, markup must pick up and you should get all the columns. See the example below - the index is created on 'firstname', but you can still see the text highlighted in the column 'name '.
SQL> drop table cust_catalog; Table dropped. Elapsed: 00:00:00.04 SQL> create table cust_catalog ( 2 id number(16) primary key, 3 firstname varchar2(80), 4 surname varchar2(80), 5 birth varchar2(25), 6 age numeric ); Table created. Elapsed: 00:00:00.00 SQL> INSERT ALL 2 INTO cust_catalog VALUES ('1','John','Smith','Glasgow','52') 3 INTO cust_catalog VALUES ('2','Emaily','Johnson','Aberdeen','55') 4 SELECT * FROM DUAL; 2 rows created. Elapsed: 00:00:00.01 SQL> EXEC CTX_DDL.DROP_PREFERENCE ('my_datastore') PL/SQL procedure successfully completed. Elapsed: 00:00:00.00 SQL> EXEC CTX_DDL.CREATE_PREFERENCE ('my_datastore', 'MULTI_COLUMN_DATASTORE') PL/SQL procedure successfully completed. Elapsed: 00:00:00.00 SQL> EXEC CTX_DDL.SET_ATTRIBUTE ('my_datastore', 'COLUMNS', 'firstname, surname') PL/SQL procedure successfully completed. Elapsed: 00:00:00.00 SQL> CREATE INDEX context_idx ON cust_catalog (firstname) 2 INDEXTYPE IS CTXSYS.CONTEXT PARAMETERS('datastore my_datastore'); Index created. Elapsed: 00:00:00.10 SQL> set serverout on SQL> declare 2 markuptext clob; 3 begin 4 ctx_doc.set_key_type( 'PRIMARY_KEY' ); 5 ctx_doc.markup( 'context_idx', '1', 'john OR smith', markuptext ); 6 dbms_output.put_line( markuptext ); 7 end; 8 /<< >> << >> -
How to dynamically add new FlowElement elements to existing through markup TLF TextFlow
Is there a way to create a new item of FlowElement (for example a DivElement) of markup text without having to go through the TextFilter.importToFlow function?
What I'm trying to accomplish is the following:
I have an already built TextFlow.
I get a text I want to inject into the TextFlow as a new item somewhere in the existing TextFlow.
The method I use to achieve this is to create a second TextFlow from markup via the importToFlow function. Can I get the second flow element and make a deepCopy of it in a new item 'not known '. Finally, I use this new 'owner' element in my main code by adding it as a child of the original TextFlow.
My function that focused.
Thank you.
TimThere isn't anyway to do today without the help of importToFlow.
Looks like what you want is similar to innerHTML and innerXHTML. Ideally, TLF would be offered to the implementations for getInnerTLFMarkup and setInnerTLFMarkup for use as described below. I also suspect that if TLF should implement these features today we would use importToFlow under the hood.
read the markup
var flowElement:FlowElement = getFlowElement();
var tlfMarkup:String = getInnerTLFMarkup (flowElement);write the tag
var flowElement:FlowElement = getFlowElement();
var tlfMarkup:String = getTLFMarkup();
setInnerTLFMarkup (element flowElement, tlfMarkup); -
Need help to highlight the query text in the document
Hi, I'm trying to load files into the blob column and try to create the text index.
I need to query the blob column in the original glass by a string, which should return the relevant documents with the query string, highlighted with some color.
Can you please help me with an example of the above.
Thanks in advance.SCOTT@orcl_11gR2> -- table: SCOTT@orcl_11gR2> CREATE TABLE document_tab 2 (document_col BLOB) 3 / Table created. SCOTT@orcl_11gR2> -- procedure to load documents: SCOTT@orcl_11gR2> CREATE OR REPLACE PROCEDURE load_document 2 (p_dir IN VARCHAR2, 3 p_file IN VARCHAR2) 4 AS 5 v_blob BLOB; 6 v_bfile BFILE; 7 BEGIN 8 INSERT INTO document_tab (document_col) 9 VALUES (EMPTY_BLOB()) 10 RETURNING document_col INTO v_blob; 11 v_bfile := BFILENAME (UPPER (p_dir), p_file); 12 DBMS_LOB.FILEOPEN (v_bfile, DBMS_LOB.LOB_READONLY); 13 DBMS_LOB.LOADFROMFILE (v_blob, v_bfile, DBMS_LOB.GETLENGTH (v_bfile)); 14 DBMS_LOB.FILECLOSE (v_bfile); 15 END load_document; 16 / Procedure created. SCOTT@orcl_11gR2> SHOW ERRORS No errors. SCOTT@orcl_11gR2> -- load documents (directory and files must be on server, not client): SCOTT@orcl_11gR2> CREATE OR REPLACE DIRECTORY my_dir AS 'c:\my_oracle_files' 2 / Directory created. SCOTT@orcl_11gR2> BEGIN 2 load_document ('my_dir', 'banana.pdf'); 3 load_document ('my_dir', 'english.doc'); 4 load_document ('my_dir', 'sample.txt'); 5 END; 6 / PL/SQL procedure successfully completed. SCOTT@orcl_11gR2> -- confirm files were loaded: SCOTT@orcl_11gR2> SELECT DBMS_LOB.GETLENGTH (document_col) 2 FROM document_tab 3 / DBMS_LOB.GETLENGTH(DOCUMENT_COL) -------------------------------- 222824 22016 60 3 rows selected. SCOTT@orcl_11gR2> -- text index: SCOTT@orcl_11gR2> CREATE INDEX document_idx 2 ON document_tab (document_col) 3 INDEXTYPE IS CTXSYS.CONTEXT 4 / Index created. SCOTT@orcl_11gR2> -- confirm files were indexed: SCOTT@orcl_11gR2> SELECT COUNT(*) FROM dr$document_idx$i 2 / COUNT(*) ---------- 319 1 row selected. SCOTT@orcl_11gR2> -- function to return highlighted document: SCOTT@orcl_11gR2> CREATE OR REPLACE FUNCTION your_markup 2 (p_index_name IN VARCHAR2, 3 p_textkey IN VARCHAR2, 4 p_text_query IN VARCHAR2, 5 p_plaintext IN BOOLEAN DEFAULT TRUE, 6 p_tagset IN VARCHAR2 DEFAULT 'HTML_DEFAULT', 7 p_starttag IN VARCHAR2 DEFAULT '*', 8 p_endtag IN VARCHAR2 DEFAULT '*', 9 p_key_type IN VARCHAR2 DEFAULT 'ROWID') 10 RETURN CLOB 11 AS 12 v_clob CLOB; 13 BEGIN 14 CTX_DOC.SET_KEY_TYPE (p_key_type); 15 CTX_DOC.MARKUP 16 (index_name => p_index_name, 17 textkey => p_textkey, 18 text_query => p_text_query, 19 restab => v_clob, 20 plaintext => p_plaintext, 21 tagset => p_tagset, 22 starttag => p_starttag, 23 endtag => p_endtag); 24 RETURN v_clob; 25 END your_markup; 26 / Function created. SCOTT@orcl_11gR2> SHOW ERRORS No errors. SCOTT@orcl_11gR2> -- query that returns highlighted document: SCOTT@orcl_11gR2> VARIABLE string VARCHAR2(100) SCOTT@orcl_11gR2> EXEC :string := 'test AND demonstration' PL/SQL procedure successfully completed. SCOTT@orcl_11gR2> SELECT your_markup ('document_idx', ROWID, :string) 2 AS highlighted_text 3 FROM document_tab 4 WHERE CONTAINS (document_col, :string) > 0 5 /HIGHLIGHTED_TEXT
--------------------------------------------------------------------------------
It is a document test of demonstration to highlight.1 selected line.
Scott@orcl_11gR2 >
-
Import excel 2003 and 2007 files that contains numbers and text in LabVIEW
Hello
I try to import *.xlsx files (2007) containing numbers and text in LabVIEW and som *.xls (2003), but I can't make it work. First column with the text and the second with numbers.
Can someone help me with a small example? Is there an easy way?
FYI
I have access to all packages and addons for LabVIEW through my work (University)
Best regards
Simon
There is an example usage of the reporting tool.
http://decibel.NI.com/content/docs/doc-4965
It should give you a starting point.
I hope this helps.
-
How to place a (strict) reference of a cluster in a control of Type def?
Example usage: for example queue message handler it is holding cluster of the references to the controls and lights on the front panel.
I have a cluster of façade of type-def'ed, I need to add to this cluster of references.
In the typedef for the controls on the front panel (above), I place a control refnum then
Make a right click-> Select the class Vi Server-> generic-> GObject-> control->-> Cluster Cluster.However, this does not produce a typedef of strict type I need.
How I handled this?
I managed to place controls in the cluster of typedef of common simple types (numbers, strings, etc.) by placing a refnum control in the cluster and (for the reference of control chain)
Make a right click-> Select the class Vi Server-> generic-> GObject-> control-> String-> String
Think it works because they do not need to be strictly typed.Delete an instance of your cluster type def on the FP, then drag it to the referance.
-
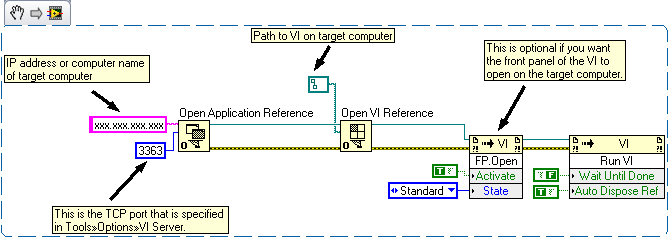
use of the server for executable files VI
Hi all
I tried to find a good explanation and example usage of VIserver to launch executables on client PC (XP) via a LAN to a PC (Win7) process controller. Basically, what I found for the controller is specified in this code snippet:
The following was placed in the .ini file of the target at the time of construction to allow VIserver using an executable file (?):
Server.TCP.Enabled = True
Server.TCP.Access = "' + * '"
Server.TCP.port = 3364
Server.TCP.ACL = "290000000A000000010000001D00000003000000010000002A10000000030000000000010000000000"
Server.VI.Access =""
server.vi.callsEnabled = True
server.vi.propertiesEnabled = TrueIf a reference to an instance of application LV is open on the computer command on a specified port, and then a VI reference target
for the .vi file (another instance?) opens on the same target for manipulation of knot VI. So what was lost for me is the executable
I am trying to run the file. May not be wired to the terminal way to "ref Open VI". This implementation requires the .exe version and the version of VI
I am trying to run the code? I launched with success of executable files over a LAN using plink with a script file. Problem is that I can't find a way
get the target executables once loaded. There is most likely a C solution for this (I'll take it if anyone knows!), but since has VIserver of tools
to control the execution, I would use it. Also, I want to understand the version of VI of the programme and the .exe in this case (s) link
Version. Any help would be greatly appreciated.
lb
Ben OK,
Your messages made me a technique to load with distance and running an exe file, built in LV8.5:
1. to load: the controller emits a "tasklist" command to a target. The objective produces an output file of tasklist which is read by the controller. If it concludes that the target is already loaded, the controller will execute it with an invoke command node 'run a VI '.
2. If the target is not loaded, then a script file is executed on the target via plink of the controller. This command will also start running.
3. all the subVIs must reside on the target, as you said, even if (as in my case), the target has no LV Developer Suite installed. I placed Traoré versions of files and folders to exe in the same folder.
4. the .ini file in the compilation has changed as shown in the first post of this thread. No special settings were used in the compilation.
This probably isn't the exact technique you had in mind, but it doesn't seem to work... Thanks again for your help.
lb
Maybe you are looking for
-
Satellite L670 loses internet connection
Hello, since a few days my laptop loses its internet connection when I move a few meters or put me behind a window. In this case, I am sitting the router to 2 meters maximum. The power of wireless transmission is very good according to the screen, bu
-
[b] Satellite M30 bluetooth software - works no-advice needed! [/ b]
My SM-30 has a bluetooth software. Before that I never used it. I reformatted the laptop and I now want to use the laptop to connect to the Nokia 6230 phone via bluetooth. I downloaded the battery Bluetooth on the site of toshiba, but when I run the
-
Satellite L - How to install the latest Intel graphics drivers?
Tired of waiting for Toshiba releasing the latest Intel graphics drivers (have problem with Aero if want to install the latest drivers). Intel Installer recognizes that it is a Toshiba and bombs out telling me that I have to get the drivers of Toshib
-
Bluetooth automated shut-off valve, possible disk external hard usb
We bought a new iMac, retina 5K 27 "end 2015 when it came out. Since the first day we have been faced with a problem where the bluetooth disconnects, Magic Mouse 2 Magic Keyboard are disconnected and then reconnected. The mouse freezes, and about 3 t
-
Officejet 5610 on computer, he says no dected device hp with Setup on 5610 - it says no connection.
HP Officejet 5610 on Vista home 32-bit operating system When I click on incontinence, it says no device detected & When I installed on the printer, it says no computer not connected But, I can print from programs ect... (cannot sweep)