Impacts of EMP data latency
Hello
I'm having a problem with a PMC 11.1.2.4 installation of environment is VERY slow, even if resource consumption is reported to be low.
I have no errors in newspapers and, very slowly, but everything seems to work, for example connection takes several minutes, but creating the sample application never ends (but I have good logs spooled slowly).
Then I started thinking it might be a network related issue, and I found that the assigned data base is far away.
The ping command on the database computer is ~ 90ms while the tnsping against the instance is ~ 200ms.
This latency is acceptable, or is what is causing the system perform very bad?
Thank you
bidi
A simple way might be to generate a few SQL queries from the EMP environment and measure the timings, similar to Bryan Blog of Oracle: Oracle and latency with small packets of networking
See you soon
John
Tags: Business Intelligence
Similar Questions
-
Pool and the Volume of data latency does not match the SanHQ
Using some PS6000 (Sata and SAS) as a back-end for ESXi and looking at the graph view on SanHQ and the raw data on export, but I'm not able to give a sense of latency information.
Generally for fields, the data in the column pool or member matches very closely to the sum of the parts of the volume (for IOPS / s, flow, read, write, etc.)
However, latency is not, nor is he anywhere near average either.
In the graphical display we noticed high (20-40 ms) latency playback of our pools and members, but the volumes that make up these pools are all less than 10ms. During a storage vmotion, we will see a huge spike in IOPS / s and latency and sizes KB will drop to almost nothing during the copy rebound back at high levels as the traffic goes down.
Makes a lot of sense to me (except perhaps if seq I/O is reduced to deal with latency)
To monitor latency, it seems that I need to watch the largest volume of latency of a given pool, but not the pool itself or asymmetric information.
I would get a few reports of MS Log Parser against export CSVs, but I need to make sense of this first. Latency is a KPI is no not a lot of sense.
When you see the IOPS rise and the latency goes down, it's actually a normal thing. It is called Nagle algorithm. It makes pretty much the TCP packets wait until they are full before sending them. Here is a document that can be useful, what explains the algorithm more in detail.
http://SearchNetworking.TechTarget.com/definition/Nagles-algorithm
Until reporting problem you're talking about I would recommend making sure that the last FW is installed on all members of the Group and ensure well the last version of SAN HQ are also installed. Just curious you have configured replication? I can't wait to hear back on your part.
-
At what level is the store of data latency measured?
Hello
I have a question about latency of data store. I see that, generally, 20 to 30 ms latency limit before having the performance issue, but at what level is this limit? It is the seat of the latency of the VM? See vsphere?...
In Vcops, when I select a data store and access operation - details see read/write latency: see comments AVG or device AVG? (see image below)

When I select a VM in Vcops to see the latency time "of virtual machine", what is the difference between latency vDisk and the VM latency data store?


I know there are a lot of questions in one thread, thank you in advance to those who take the time to answer.
As esxtop counters, you have different counters to measure different parts of the stack. If you have latency at a disk level your queues will be filled and reflected. Latency of disk order is good enough to pick up underlying storage latency, but it depends what resource you are watching. The attributes derived from 'latency' exist here and there which are calculated based on the type of storage/etc to simplify your life and give you one place to search.
When you start to look at the latency of the queue, you must keep in mind that focuses only on the queue. Take a look at the Duncan article (ESXTOP - bricks yellow) on it and your questions will probably be kept clear with regard to what are the bits/s and for the disk counters.
-
Question about the impact of a data file missing
Oracle Version: 10 gr 2
If a data file (not a data file belonging to the tablespace SYSTEM or any other data file associated with Oracle Internals) is lost, I can bring the database up somehow?Nichols wrote:
Keita,
What happens if I don't have a backup of the data file that is lost?OK understood
If you do not have a backup of your database and that you have lost a data file, then you must re - create control file (which will contain the names of data inside files) without indicating lost data file name
You must create the controlfile creation script and remove the line of lost data file name and create a controlfile. After that, you should be able to open your database successfully
- - - - - - - - - - - - - - - - - - - - -
Kamran Agayev a. (10g OCP)
http://kamranagayev.WordPress.com
[Step by step installation Oracle Linux and automate the installation by using Shell Script | http://kamranagayev.wordpress.com/2009/05/01/step-by-step-installing-oracle-database-10g-release-2-on-linux-centos-and-automate-the-installation-using-linux-shell-script/] -
data transfer labview to the web app server
Community of LabView greetings!
I have what I think, it's a simple question:
How can we transfer (real-time) and store acquired data (e.g., time, temperature and so suite..) of a labview VI to a server over the internet so it can be used for a mobile application.
Thanks in advance!
You will need to your data in your LabVIEW application on a server:
-Customer HTTP screws
-TCP/IP
-WebSockets
Server might have a LV application on it, or you can use a web server with a scripting language (for example PHP/ASP/Node.js).
You will need to write something on the server to listen to your LabVIEW application and contain the data :
-Database
-File
-Memory
You will need to write a few API/interface for push/recovery of data for example JSON/POST/XML - take a look at 'RESTful API.
The choice of one of them to go for depends on how 'real time' you're talking about - how often you want to update data, latency, etc..
If you don't want to do it all yourself, there are 3 third-party vendors that can store data in this way for you - there is a free (but limited) race one by SparkFun - https://data.sparkfun.com/ but I don't know there are other services.
-
Smart way to save large amounts of data using the circular buffer
Hello everyone,
I am currently enter LabView that I develop a measurement of five-channel system. Each "channel" will provide up to two digital inputs, up to three analog inputs of CSR (sampling frequency will be around 4 k to 10 k each channel) and up to five analog inputs for thermocouple (sampling frequency will be lower than 100 s/s). According to the determined user events (such as sudden speed fall) the system should save a file of PDM that contains one row for each data channel, store values n seconds before the impact that happened and with a specified user (for example 10 seconds before the fall of rotation speed, then with a length of 10 minutes).
My question is how to manage these rather huge amounts of data in an intelligent way and how to get the case of error on the hard disk without loss of samples and dumping of huge amounts of data on the disc when recording the signals when there is no impact. I thought about the following:
-use a single producer to only acquire the constant and high speed data and write data in the queues
-use consumers loop to process packets of signals when they become available and to identify impacts and save data on impact is triggered
-use the third loop with the structure of the event to give the possibility to control the VI without having to interrogate the front panel controls each time
-use some kind of memory circular buffer in the loop of consumer to store a certain number of data that can be written to the hard disk.
I hope this is the right way to do it so far.
Now, I thought about three ways to design the circular data buffer:
-l' use of RAM as a buffer (files or waiting tables with a limited number of registrations), what is written on disk in one step when you are finished while the rest of the program and DAQ should always be active
-broadcast directly to hard disk using the advanced features of PDM, and re-setting the Position to write of PDM markers go back to the first entry when a specific amount of data entry was written.
-disseminate all data on hard drive using PDM streaming, file sharing at a certain time and deleting files TDMS containing no abnormalities later when running directly.
Regarding the first possibility, I fear that there will be problems with a Crescent quickly the tables/queues, and especially when it comes to backup data from RAM to disk, my program would be stuck for once writes data only on the disk and thus losing the samples in the DAQ loop which I want to continue without interruption.
Regarding the latter, I meet lot with PDM, data gets easily damaged and I certainly don't know if the PDM Set write next Position is adapted to my needs (I need to adjust the positions for (3analog + 2ctr + 5thermo) * 5channels = line of 50 data more timestamp in the worst case!). I'm afraid also the hard drive won't be able to write fast enough to stream all the data at the same time in the worst case... ?
Regarding the third option, I fear that classify PDM and open a new TDMS file to continue recording will be fast enough to not lose data packets.
What are your thoughts here? Is there anyone who has already dealt with similar tasks? Does anyone know some raw criteria on the amount of data may be tempted to spread at an average speed of disk at the same time?
Thank you very much
OK, I'm reaching back four years when I've implemented this system, so patient with me.
We will look at has a trigger and wanting to capture samples before the trigger N and M samples after the outbreak. The scheme is somewhat complicated, because the goal is not to "Miss" samples. We came up with this several years ago and it seems to work - there may be an easier way to do it, but never mind.
We have created two queues - one samples of "Pre-event" line of fixed length N and a queue for event of unlimited size. We use a design of producer/consumer, with State Machines running each loop. Without worrying about naming the States, let me describe how each of the works.
The producer begins in its state of "Pre Trigger", using Lossy Enqueue to place data in the prior event queue. If the trigger does not occur during this State, we're staying for the following example. There are a few details I am forget how do ensure us that the prior event queue is full, but skip that for now. At some point, relaxation tilt us the State. p - event. Here we queue in the queue for event, count the number of items we enqueue. When we get to M, we switch of States in the State of pre-event.
On the consumer side we start in one State 'pending', where we just ignore the two queues. At some point, the trigger occurs, and we pass the consumer as a pre-event. It is responsible for the queue (and dealing with) N elements in the queue of pre-event, then manipulate the M the following in the event queue for. [Hmm - I don't remember how we knew what had finished the event queue for - we count m, or did you we wait until the queue was empty and the producer was again in the State of pre-event?].
There are a few 'holes' in this simple explanation, that which some, I think we filled. For example, what happens when the triggers are too close together? A way to handle this is to not allow a relaxation to be processed as long as the prior event queue is full.
Bob Schor
-
Best practices to create diagrams for mounting of the EMP
Hi all
What is advised to create patterns for EMP installation and configuration if you use Oracle for EMP data.
1. create the dedicated tablespace and table Temp space dedicated for each schema
or
2. create a dedicate tablespace and dedicates space temporary table for all schemas and another separate for HFM schema.
or
3. just use default tablespace and a tablespace temp.
Kind regards
Dattatray Mate
It's like I said products like FM, FDMEE, DRM and perhaps RAF depending on what happens to be stored should be considered for there own tablespace, other products, not so and can be combined in say a tablespace.
These are all just guidelines and there is no good answer.
See you soon
John
-
Financial close management on EMP existing domain configuration
I have EMP 11.1.2.3 workplace, with hfm, planning as main components. I need to install and configure the financial close management, but SOA before that. Suite OBE for 'Installation and configuration of Oracle® Hyperion financial close management 11.1.2.2.000 in a multi-node Environment' However this and almost all the OBE, creates the new logical Web domain. Is it a necessity? If I already have EMP field 'EPMSystem' can I extend it? I chose field Extend and selected "E:\Oracle\Middleware\user_projects\domains\EPMSystem". However on 'Configure JDBC data source' it shows all EMP schema, but does not show that I created using the remote control for SOA.
Anyone has any experience to extend the existing SOA EMP field? Wanted to know the steps, looks, I might create the JDBC database manually in the weblogic administration console.
It is possible to do the reverse and deploy EMP first and then extend it to include SOA in the field of the EMP
The JDBC for SOA component schema must be after the EMP data sources configuration screen.
See you soon
John
-
Get data from performance CPU with PowerCLI
Can I use powerCLI to do the following:?
-Get 2 virtual machines.
-Get the following metric: "Application (MHz) CPU" for the last week
-Export data to CSV
It is indeed a compromise between the statistical data, you want to keep it online and the capacity of storage-performance on your vCenter server.
For me there is no rule of universal thumb, you will need to find the ideal configuration for your environment and your specific needs.
In my environment, the works of config 4, 4, 2, 2. Impact on minimum performance and I can get online reports I need.
Don't forget that you can change the time and frequency of the aggregation jobs that run on the database, you don't have to stick with the default values.
But be aware of the impact on the data available in each historical interval.
And there are alternatives, as I mentioned in my answer to another of your son: Re: Getting pics of use with get-stat
-
Incremental time based on column date
Hello
My database is 11g. I want to generate incremental time according to the date column column. Help, please:
for example:
SQL> select date from emp order by 1; DATE ---------- 02/12/2012 02/12/2012 02/12/2012 02/12/2012 24/12/2012 24/12/2012 24/12/2012
I want to add values to a time column that contains the values to a number 6 (hhmmss) as follows:
SQL> select date, time from emp; DATE TIME ---------------------------------------- 02/12/2012 000000 02/12/2012 000001 02/12/2012 000002 02/12/2012 000003 24/12/2012 000000 24/12/2012 000001 24/12/2012 000002 . . . 24/12/2012 000059 24/12/2012 000100
The time should reset itself as the date changes.
Why you store DATE and TIME in the form of two different columns? So is TIME column is VARCHAR2 data type?
You can do it
merge into e emp
a_l'_aide_de)
Select empid
, to_char (excerpt (numtodsinterval time (NWR, 'the other')), "fm09")
|| TO_CHAR (extract (minute of numtodsinterval (NWR, 'the other')), "fm09")
|| TO_CHAR (extract ((deuxieme from numtodsinterval (NWR, 'the other')), "fm09") time_value
de)
Select empid
row_number() over (partition by order by empid date_column) rno
WCP
)
) t
on)
e.EmpID = t.empid
)
When matched then
update set e.time_column = t.time_value;
-
Hi all the language!
can someone guide me how to import and export data? would be greatly appreciated and thanks in advance
I use windows xp Service Pack 3 and database version 10.2.0.1.0
Sarah
Published by: SarahSarahSarah on August 14, 2009 14:30Hi sarah,.
Try like this, symbol of $ use prior to export and provide the path for the data to be dumped in.
SQL > $exp scott/sara1 leader = D:\emp.dmp log = D:\emp.log tables = emp rows = Yes indexes = noThe code above makes the table emp data exported to D drive.
Hope this can help u.
Geeta-
-
The first batch of phones is conducted! Be sure to check your email for tracking numbers.
No change on my order page status and I ordered during the first 20 minutes!
Configurations we choose must more than when we commissioned an impact the delivery date...
-
Hello
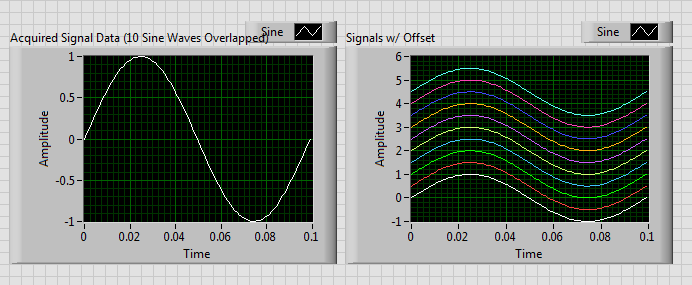
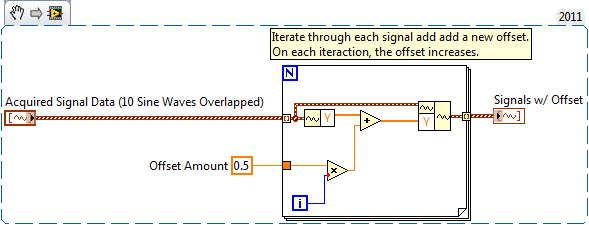
I would draw Let's say 30 EEG signals on a single waveform chart. Without the route option stacked, the signals that I can cross eachother but must have a lag... Is there a standard way to do this? I can give each signal a time lag, but I was wondering if there is some waveform table "xcontrol" out there with these features? Each EEG Viewer has its graphics of teas ways.
Best regards
Thijs
You could provide by program each EEG waveform with a lag, if she's not an impact on your data. My thought is that you can browse your waveform data table and gradually add known offset at each curve, which grows in proportion to the number of iterations.
Something like below:
-
Program with the Office Outlook program
I am running Windows 7 and I can minimize is no longer my e-mail Office Outlook to the taskbar program. Also, when I restart the e-mail program a Windows box appears and asks me "do you want the following program to make changes to this computer? The program does not start if I click on 'yes '. These two problems seemed to have started at the same time. Any ideas on how to solve these problems?
Uninstalling a version of Office has no impact on the data.
But a uninstall/reinstall necessarily will not heal anything
A msg to outlook error not implemented can be caused by your program integrated anti-virus, or if you had installed a later version of Office to trial it.
-
Minimum flow rate: what is the best?
Hello
I have a scenario where the minimum 802. 11b / g data rate has been set at 1 MB/s required on WISN model stored on WCS.
We believe that it is allowing customers to try to connect to the network wirelessly with a very tenuous link, resulting in a performance very poor.
We also believe that this poor performance will affect the experience for all users of the wireless access point which are close enough to talk to a more reasonable speed wireless.
Are we correct in this thinking?
If we change the mandatory connection to 5.5 Mbps speed, what are the effects, if he go there, we see that we have problems we create a few holes in coverage, and if we did, they would be huge?
Is there a way to model?
If we do, the increase in the performance of the network for the many outweigh the disadvantages of a hole of covergae?
Thanks for any help/comments, I'm putting a folder to get the data back to 5.5 Mbps throughput at least but am Zenith mgmt resistance.
Thank you
Bryn
Bryn,
There are a number of factors that can impact/influence the data rates, you select; as AP density, client devices and protocols supported. It is also important to understand the difference between agent and supported when you configure data rates.
Usually it's ok for 5.5 Mbps required, which means you need to get a 5.5 Mbps or greater connection to associate the once associated access point you can resign at 1 Mbps or 2 Mbps if they are configured as supported.
Personally without knowing how your design looks in terms of density of access points wireless and with knowing what types of clients your race: laptops, PDAs and phones VOIP, vocera badges. I had set as mandatory 5.5 Mbps and put the rest to support and test from there, don't forget the cover holes are data rates more than they are signal levels. The thing to remember with coverage holes is that your wireless network must be a 2 ways communication between the client and the access point, many facilities you may encouter scenarios where the machine client (ie: phone or laptop) can hear the AP very well but the AP never hears the client machine, this translates the cover holes and huge performance problems. This happens because the majority of client devices are limited to the maximum transmit power of 25 to 30 mw, while the AP year is capable of 100mw (802 11b), 30mw (802.11 g), 40 MW (802 11A).
As you progress through this question, it is important to take into account not only the data rates, but the overall design and make sure that your do not meet a real cover in question.
Hope this helps
Kayle



Maybe you are looking for
-
Time for the Ipad 2, 64 GB of charge air
I bought an Ipad 2 64 gb air, but it takes 6 to 7 hours at full load. Is this normal?
-
How do you define a date formula in a column?
I write the dates of publication for books in my numbers and want to format a column to a single date. This way I can write the date in some way and it would be to convert to the date I selected. For example: the format would, however, on September 1
-
Android 5.0.1 is now available for nexus.
Android 5.0.1 is now available for nexus. Deployment of motorola can direct the 5.0.1 or 5.0 first then 5.0.1?
-
Can anyone assist me with this STOP error blue screen? IRQL_NOT_LESS_OR_EQUAL
Hello Yesterday, my measure PC worked fine. To market today, about twenty seconds after startup, I got a blue screen (seen below) and get that since then. However, I am able to run very well Safe Mode. I read on the installation of a patch and instal
-
Problem of refresh/re-install Windows 8
I have a Dell laptop, Inspiron, which is not too good these days. It is a year and is come pre-installed with Win 8.je had created a recovery media after the purchase. So I try to update my phone but I get this error, "some files are missing. Your in