Odd number of nodes in the Cluster controller NSX
Why odd number of knots are required in the controller NSX Cluster?
The election of the master for each role requires a vote by a majority of all active and inactive nodes in the cluster. This is the main reason why a Cluster controller must always be deployed based on an odd number of nodes.
See Page 10-11 of this guide for more information: https://www.vmware.com/files/pdf/products/nsx/vmw-nsx-network-virtualization-design-guide.pdf
Tags: VMware
Similar Questions
-
Host cannot communicate with all other nodes in the cluster virtual SAN allowed
I get this error after you apply the latest patch:- http://kb.vmware.com/selfservice/microsites/search.do?language=en_US & cmd = displayKC & externalId = 2135115
So all the hosts are now review: VMware ESXi, 6.0.0 3380124
After the reboot, I get the error message on the host cannot communicate with all other nodes in the cluster active virtual san...
However, the VSAN health check is green, 'get esxcli vsan cluster' shows all 6 members of the cluster ok... and if I reboot a crowd happens ok without the error... so if I reboot another host, it will come without the error... but then the host on which I rebooted before it displayed the error...? So I can't ever get more than 1 host without the error after a reboot.
I checked multicast that removes ok, in fact all of the checks in contradiction with the fact that why I get this error...
Someone at - it ideas? Could this be the latest patch...
Paul...
Hello, this has been repeated here: 6.0 U1b - hosts cannot communicate thanks, Zach.
-
Error "host cannot communicate with all other nodes in the cluster of enabeld VSAN.
Hello community,
We have a problem (?).
We have a cluster VSAN enabled with four hosts. Everything seems perfect,
-the configuration is good,
-Displays the page state VSAN "network status: (green arrow) Normal."
-Displays the disk management page "status: healthy" for all of our groups of disks.
-Same 'esxcli vsan cluster get"on each host returns a 'HEALTHY '.
But we have a yellow exclamation littly on each host 'host cannot communicate with all other nodes in the cluster of enabeld VSAN.
Anyone with the same problem? Anyone with an idea or a hint?
Thank you!
Update vcenter to the latest version and the error disappears. Problem solved! The 'old' version of vcenter performed since September 2014, strange.
Thank you very much for your help!
-
A single node of the cluster cannot start
Hello all,.
I hope you can help me. We have a 2 node rac. the first node cannot be started due to:
[cssd (16558)] CRS-1714: impossible to discover all files with right to vote, a new attempt of discovery in 15 seconds; Details at (: CSSNM00070 :) in /pkg/app/11.2.0/grid/log/defr2elvhms01/cssd/ocssd.log)
2015-09-28 14:45:19.038:
[cssd (16558)] CRS-1714: impossible to discover all files with right to vote, a new attempt of discovery in 15 seconds; Details at (: CSSNM00070 :) in /pkg/app/11.2.0/grid/log/defr2elvhms01/cssd/ocssd.log)
2015-09-28 14:45:34.059:
[cssd (16558)] CRS-1714: impossible to discover all files with right to vote, a new attempt of discovery in 15 seconds; Details at (: CSSNM00070 :) in /pkg/app/11.2.0/grid/log/defr2elvhms01/cssd/ocssd.log)
the crs is the OCR disk, it is visible it the log file:
2015-09-28 14:46:49.120: Lib [SKGFD] [2107098880]: ASM:/opt/oracle/extapi/64/asm/orcl/1/libasm.so: handle 0x7fec68140800 for closing disk: ORCL:REDO:
2015-09-28 14:46:49.120: [CSSD] [2107098880] clssnmvDiskVerify: discovery of a potential voting file
2015-09-28 14:46:49.120: [SKGFD] [2107098880] handful 0x7fec68140dd0 to lib: ASM:/opt/oracle/extapi/64/asm/orcl/1/libasm.so: disc: ORCL:OCR1:
2015-09-28 14:46:49.121: [CSSD] [2107098880] clssnmvDiskVerify: table of contents format offset expected (0x634c7373 0x546f636b), found(0x434c5366 0x0000)
2015-09-28 14:46:49.121: Lib [SKGFD] [2107098880]: ASM:/opt/oracle/extapi/64/asm/orcl/1/libasm.so: handle 0x7fec68140dd0 for closing disk: ORCL:OCR1:
2015-09-28 14:46:49.121: [CSSD] [2107098880] clssnmvDiskVerify: Discovery successful record 0
2015-09-28 14:46:49.121: [CSSD] [2107098880] clssnmCompleteInitVFDiscovery: completing the first discovery of the file with the right to vote
2015-09-28 14:46:49.121: [CSSD] [2107098880] clssnmvFindInitialConfigs: no vote files found
2015-09-28 14:46:49.121: [CSSD] [2107098880](:CSSNM00070:) clssnmCompleteInitVFDiscovery: vote fichier non trouvé.) A new attempt of discovery in 15 seconds
The failed node can be started in exclusive mode, and I'm able to connect to the asm, but of course without disks. When I am trying to mount starts, I get the following:
SQL > alter the data carrier diskgroup.
change data diskgroup mount
*
ERROR on line 1:
ORA-15032: not all changes made
ORA-15017: diskgroup 'DATA' cannot be mounted
ORA-15063: ASM discovered an insufficient number of drives for diskgroup "DATA".
ORA-15085: ASM disk "" the size of incompatible sector.
We seem to be affected by the similar problem as written:
After SAN Firmware Upgrade , ASM starts (using ASMLIB) not be mounted Due To ORA-15085: ASM disk "" the size of incompatible sector. (Doc ID 1500460.1()
kernel cannot be updated thus affecting the ORACLEASM_USE_LOGICAL_BLOCK_SIZE is not possible.
What we do not understand why the failed node has different physical block size / logic. Why the oracle on the failed node linux recognize different value? If it was the same thing, no doubt the cluster could start up:
[root@defr2elvhms02 ~] # rpm - qa | grep-i asm
oracleasmlib - 2.0.4 - 1.el6.x86_64
oracleasm-support - 2.1.8 - 1.el6.x86_64
[root@defr2elvhms02 ~] # uname - a
Linux defr2elvhms02 2.6.32 - 400.37.1.el6uek.x86_64 #1 SMP Thu Feb 5 14:58:47 PST 2015 x86_64 x86_64 x86_64 GNU/Linux
[root@defr2elvhms02 ~] #.
[root@defr2elvhms02 ~] # oracleasm querydisk d OCR1
Disc 'OCR1' is a valid ASM disk device [8.1]
[root@defr2elvhms02 ~] # oracleasm querydisk d OCR2
Disc 'OCR2' is a valid ASM disk device [8.17]
[root@defr2elvhms02 ~] # oracleasm querydisk d OCR3
Disc 'OCR3' is a valid ASM disk device [8.33]
[root@defr2elvhms02 ~] # ls-l/dev/sda1
BRW - rw-. Disc 1 root 8, 1 Sep 29 16:21 / dev/sda1
[root@defr2elvhms02 ~] # ls-l/dev/sdb1
BRW - rw-. Disc 1 root 8, 17 Sep 29 16:21 / dev/sdb1
[root@defr2elvhms02 ~] # ls-l/dev/sdc1
BRW - rw-. Disc 1 root 8: 33 Sep 29 16:21 / dev/sdc1
[root@defr2elvhms02 ~] # fdisk-l/dev/sda
Disk/dev/sda: 10.7 GB, 10737418240 bytes
Heads of 64, 32 sectors/track, 10240 cylinders
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical or physical): 512 bytes / 512 bytes
Size of the e/s (minimum/maximum): 512 bytes / 512 bytes
Disk identifier: 0x20700d2b
Device boot start end blocks Id system
/ dev/sda1 10 10240 10476544 83 Linux
[root@defr2elvhms02 ~] # fdisk-l/dev/sda1
Disk/dev/sda1: 10.7 GB, 10727981056 bytes
Heads of 64, 32 sectors/track, 10231 bottles
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical or physical): 512 bytes / 512 bytes
Size of the e/s (minimum/maximum): 512 bytes / 512 bytes
Disk identifier: 0x00000000
[root@defr2elvhms02 ~] # fdisk-l/dev/sdb
Disk/dev/sdb: 10.7 GB, 10737418240 bytes
Heads of 64, 32 sectors/track, 10240 cylinders
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical or physical): 512 bytes / 512 bytes
Size of the e/s (minimum/maximum): 512 bytes / 512 bytes
Disk identifier: 0x62515b34
Device boot start end blocks Id system
/ dev/sdb1 10 10240 10476544 83 Linux
[root@defr2elvhms02 ~] # fdisk-l/dev/sdb1
Disk/dev/sdb1: 10.7 GB, 10727981056 bytes
Heads of 64, 32 sectors/track, 10231 bottles
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical or physical): 512 bytes / 512 bytes
Size of the e/s (minimum/maximum): 512 bytes / 512 bytes
Disk identifier: 0x00000000
[root@defr2elvhms02 ~] # fdisk-l/dev/sdc
Disk/dev/sdc: 10.7 GB, 10737418240 bytes
Heads of 64, 32 sectors/track, 10240 cylinders
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical or physical): 512 bytes / 512 bytes
Size of the e/s (minimum/maximum): 512 bytes / 512 bytes
Disk identifier: 0xc254acd9
Device boot start end blocks Id system
/ dev/sdc1 10 10240 10476544 83 Linux
[root@defr2elvhms02 ~] # fdisk-l/dev/sdc1
Disk/dev/sdc1: 10.7 GB, 10727981056 bytes
Heads of 64, 32 sectors/track, 10231 bottles
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical or physical): 512 bytes / 512 bytes
Size of the e/s (minimum/maximum): 512 bytes / 512 bytes
Disk identifier: 0x00000000
-------------------------------------------------------------------------------
-------------------------------------------------------------------------------
[root@defr2elvhms01 ~] # uname - a
Linux defr2elvhms01 2.6.32 - 400.37.1.el6uek.x86_64 #1 SMP Thu Feb 5 14:58:47 PST 2015 x86_64 x86_64 x86_64 GNU/Linux
[root@defr2elvhms01 ~] # rpm - qa | grep-i asm
oracleasmlib - 2.0.4 - 1.el6.x86_64
oracleasm-support - 2.1.8 - 1.el6.x86_64
[root@defr2elvhms01 ~] # oracleasm querydisk d OCR1
Disc 'OCR1' is a valid ASM disk device [8.1]
[root@defr2elvhms01 ~] # oracleasm querydisk d OCR2
Disc 'OCR2' is a valid ASM disk device [8.17]
[root@defr2elvhms01 ~] # oracleasm querydisk d OCR3
Disc 'OCR3' is a valid ASM disk device [8.33]
[root@defr2elvhms01 ~] # ls-l/dev/sdb1
BRW - rw-. Disc 1 root 8, 17 Sep 29 15:32 / dev/sdb1
[root@defr2elvhms01 ~] # ls-l/dev/sda1
BRW - rw-. Disc 1 root 8, 1 Sep 29 15:32 / dev/sda1
[root@defr2elvhms01 ~] # ls-l/dev/sdb1
BRW - rw-. Disc 1 root 8, 17 Sep 29 15:32 / dev/sdb1
[root@defr2elvhms01 ~] # ls-l/dev/sdc1
BRW - rw-. Disc 1 root 8: 33 Sep 29 15:32 / dev/sdc1
[root@defr2elvhms01 ~] # fdisk-l/dev/sda
Disk/dev/sda: 10.7 GB, 10737418240 bytes
Heads of 64, 32 sectors/track, 10240 cylinders
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical or physical): 512 bytes / 4096 bytes
The e/s (minimum/maximum) size: 4096 bytes / 65536 bytes
Disk identifier: 0x20700d2b
Device boot start end blocks Id system
/ dev/sda1 10 10240 10476544 83 Linux
[root@defr2elvhms01 ~] # fdisk-l/dev/sda1
Disk/dev/sda1: 10.7 GB, 10727981056 bytes
Heads of 64, 32 sectors/track, 10231 bottles
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical or physical): 512 bytes / 4096 bytes
The e/s (minimum/maximum) size: 4096 bytes / 65536 bytes
Disk identifier: 0x00000000
[root@defr2elvhms01 ~] # fdisk-l/dev/sdb
Disk/dev/sdb: 10.7 GB, 10737418240 bytes
Heads of 64, 32 sectors/track, 10240 cylinders
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical or physical): 512 bytes / 4096 bytes
The e/s (minimum/maximum) size: 4096 bytes / 65536 bytes
Disk identifier: 0x62515b34
Device boot start end blocks Id system
/ dev/sdb1 10 10240 10476544 83 Linux
[root@defr2elvhms01 ~] # fdisk-l/dev/sdb1
Disk/dev/sdb1: 10.7 GB, 10727981056 bytes
Heads of 64, 32 sectors/track, 10231 bottles
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical or physical): 512 bytes / 4096 bytes
The e/s (minimum/maximum) size: 4096 bytes / 65536 bytes
Disk identifier: 0x00000000
[root@defr2elvhms01 ~] # fdisk-l/dev/sdc
Disk/dev/sdc: 10.7 GB, 10737418240 bytes
Heads of 64, 32 sectors/track, 10240 cylinders
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical or physical): 512 bytes / 4096 bytes
The e/s (minimum/maximum) size: 4096 bytes / 65536 bytes
Disk identifier: 0xc254acd9
Device boot start end blocks Id system
/ dev/sdc1 10 10240 10476544 83 Linux
[root@defr2elvhms01 ~] # fdisk-l/dev/sdc1
Disk/dev/sdc1: 10.7 GB, 10727981056 bytes
Heads of 64, 32 sectors/track, 10231 bottles
Units = cylinders of 2048 * 512 = 1048576 bytes
Sector size (logical or physical): 512 bytes / 4096 bytes
The e/s (minimum/maximum) size: 4096 bytes / 65536 bytes
Disk identifier: 0x00000000
Thank you for the help
I have changed accounts.
We managed to find the reason. First of all, it is a virtual machine. An expert colleague told me to check the hardware of vmware. We managed to find out that there is a difference of ILO to host vmware hardware. Even if the guest OS virtual material seem to be the same, but the difference between the results of operating system host different logical and physical size of block on 2 nodes. This is the reason.
We had to update the kernel to apply the setting ORACLEASM_USE_LOGICAL_BLOCK_SIZE to repair the block size for clusterware difference. Everyone was puzzled about why, but the most important is the host VMware system in this issue.
Thanks for the help
Attila
-
Dear all,
OS: RHEL 4
DB = 10.2.0.4.0
Storage file system: OCFS2
Cluster software and database has been added, but when I try to add my cluster instance I get following error message.
The directory "/ database/archivelog ' MANDATORY DB_UNIQUE_NAME ROUVRIR = timsis not on the cluster file system shared between the nodes 'ud1 UD2.
Thanks and greetings
Jean Louis
Hello
Please check the value of the parameter of log_archive_dest_1, this problem occurs when the location has already been added to another instance.
Please check the value of the setting above and re run the following command:-
ALTER system set log_archive_dest_1 = "LOCATION = / data/archivelog = (ALL_LOGFILES, ALL_ROLES) db_unique_name =
valid_for" scope = mΘmoire Concerning
Jihane Narain Sylca
-
Hellocan someone explain what are leaf nodes in cluster flex? documentation, I see that they are nodes that do not have access to the storage and they communicate with hub nodes.
Can have the oracle db instances? If yes how data is transferred between the hub and leaf nodes? Through interconnection? It does not overload the interconnection?
Thank you
Soumahoro
The RAC instances are supposed to be present on Hub nodes as they are supposed to be used as DB nodes. This would make the concept of Fusion Cache similar to what we have in previous versions. On the management of the nodes, you must explicitly set, the nodes would be considered to be leaf nodes in the list of the available total nodes.
HTH
Aman...
-
Equivalent of PowerShell for script following VBScript determine the active node of the cluster?
Hello world
I wonder if there is another similar Powershell script that can determine the currently active node of an MSCS?
What follows is done on VBScript
strClusterWMINameString = "winmgmts:\\ExchangeServerCluster01\root\cimv2" Set objWMISvc = GetObject( strClusterWMINameString ) Set colItems = objWMISvc.ExecQuery( "Select * from Win32_ComputerSystem", , 48 ) For Each objItem in colItems strComputerName = objItem.Name WScript.Echo "The Cluster " & strClusterWMINameString & " active node is " & strComputerName Next
Any kind of help is appreciated.
Thank you.
In PowerShell, you can do this with:
(Get-WmiObject Win32_ComputerSystem - SIEXCLU01 of the computer). Name
Best regards, Robert
-
Number of nodes in the Group Rep
Hi all
All Rep groups have the same number of storage nodes.
But we can add or remove nodes as administrative task.
Does this mean that we can have Rep groups with a different number of storage nodes?
Thank you.user962305 wrote:
Hi allAll Rep groups have the same number of storage nodes.
But we can add or remove nodes as administrative task.
Does this mean that we can have Rep groups with a different number of storage nodes?Generally, no. However, if a node goes down either because the system or media failure, you can replace it with another node. But change the replication factor is not allowed in this release.
Charles Lamb
-
Cannot start the instance after adding nodes to the cluster
Hello world
After you add a third node to my group, I can't start instance. Error:
Additional information:ORA-01078: failure in processing system parameters ORA-01565: error in identifying file '+DATA/gwt/spfilexxxx.ora' ORA-17503: ksfdopn:2 Failed to open file +DATA/gwt/spfilexxxx.ora ORA-01034: ORACLE not available ORA-27123: unable to attach to shared memory segment Linux-x86_64 Error: 13: Permission denied
I use Centos 5.8 and Oracle 11.2.0.3. Thanks in advance[grid@nodedc3 ~]$ crsctl query css votedisk ## STATE File Universal Id File Name Disk group -- ----- ----------------- --------- --------- 1. ONLINE 7887e29070204f52bfda4091940f4672 (ORCL:VOTE_OCR) [OCR_VOTE] Located 1 voting disk(s). [grid@nodedc3 ~]$ srvctl status asm -a ASM is running on nodedc3,nodedc2,nodedc1 ASM is enabled. [grid@nodedc3 ~]$ ps -ef | grep lsnr | grep -v 'grep' | grep -v 'ocfs' | awk '{print $9}' LISTENER_SCAN2 LISTENER [grid@nodedc3 ~]$ olsnodes -n nodedc1 1 nodedc2 2 nodedc3 3 [grid@nodedc3 ~]$ crs_stat -t -v Name Type R/RA F/FT Target State Host ---------------------------------------------------------------------- ora.DATA.dg ora....up.type 0/5 0/ ONLINE ONLINE nodedc1 ora.FRA.dg ora....up.type 0/5 0/ ONLINE ONLINE nodedc1 ora....ER.lsnr ora....er.type 0/5 0/ ONLINE ONLINE nodedc1 ora....N1.lsnr ora....er.type 0/5 0/0 ONLINE ONLINE nodedc2 ora....N2.lsnr ora....er.type 0/5 0/0 ONLINE ONLINE nodedc3 ora....N3.lsnr ora....er.type 0/5 0/0 ONLINE ONLINE nodedc1 ora....VOTE.dg ora....up.type 0/5 0/ ONLINE ONLINE nodedc1 ora.asm ora.asm.type 0/5 0/ ONLINE ONLINE nodedc1 ora.cvu ora.cvu.type 0/5 0/0 ONLINE ONLINE nodedc1 ora.gsd ora.gsd.type 0/5 0/ OFFLINE OFFLINE ora.gwt.db ora....se.type 0/2 0/1 ONLINE ONLINE nodedc1 ora....network ora....rk.type 0/5 0/ ONLINE ONLINE nodedc1 ora....SM1.asm application 0/5 0/0 ONLINE ONLINE nodedc1 ora....C1.lsnr application 0/5 0/0 ONLINE ONLINE nodedc1 ora....dc1.gsd application 0/5 0/0 OFFLINE OFFLINE ora....dc1.ons application 0/3 0/0 ONLINE ONLINE nodedc1 ora....dc1.vip ora....t1.type 0/0 0/0 ONLINE ONLINE nodedc1 ora....SM2.asm application 0/5 0/0 ONLINE ONLINE nodedc2 ora....C2.lsnr application 0/5 0/0 ONLINE ONLINE nodedc2 ora....dc2.gsd application 0/5 0/0 OFFLINE OFFLINE ora....dc2.ons application 0/3 0/0 ONLINE ONLINE nodedc2 ora....dc2.vip ora....t1.type 0/0 0/0 ONLINE ONLINE nodedc2 ora....SM3.asm application 0/5 0/0 ONLINE ONLINE nodedc3 ora....C3.lsnr application 0/5 0/0 ONLINE ONLINE nodedc3 ora....dc3.gsd application 0/5 0/0 OFFLINE OFFLINE ora....dc3.ons application 0/3 0/0 ONLINE ONLINE nodedc3 ora....dc3.vip ora....t1.type 0/0 0/0 ONLINE ONLINE nodedc3 ora.oc4j ora.oc4j.type 0/1 0/2 ONLINE ONLINE nodedc1 ora.ons ora.ons.type 0/3 0/ ONLINE ONLINE nodedc1 ora.scan1.vip ora....ip.type 0/0 0/0 ONLINE ONLINE nodedc2 ora.scan2.vip ora....ip.type 0/0 0/0 ONLINE ONLINE nodedc3 ora.scan3.vip ora....ip.type 0/0 0/0 ONLINE ONLINE nodedc1 [grid@nodedc3 ~]$ crs_stat -t -v | grep ams [grid@nodedc3 ~]$ crs_stat -t -v | grep asm ora.asm ora.asm.type 0/5 0/ ONLINE ONLINE nodedc1 ora....SM1.asm application 0/5 0/0 ONLINE ONLINE nodedc1 ora....SM2.asm application 0/5 0/0 ONLINE ONLINE nodedc2 ora....SM3.asm application 0/5 0/0 ONLINE ONLINE nodedc3 [grid@nodedc3 ~]$ ocrcheck Status of Oracle Cluster Registry is as follows : Version : 3 Total space (kbytes) : 262120 Used space (kbytes) : 3068 Available space (kbytes) : 259052 ID : 1523128137 Device/File Name : +OCR_VOTE Device/File integrity check succeeded Device/File not configured Device/File not configured Device/File not configured Device/File not configured Cluster registry integrity check succeeded Logical corruption check bypassed due to non-privileged user
Edited by: 922736 2013-05-13 23:51Hello
Sometimes, we are not able to access ASM for creation of database due to permissions on a file ' Gride_Home/bin/oracle' owner should be like this:
-rwsr-s - x 1 grid oinstall 152462728 October 12, 2012 /u01/app/11.2.0/grid/bin/oracle
-
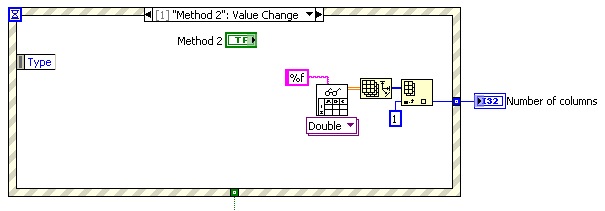
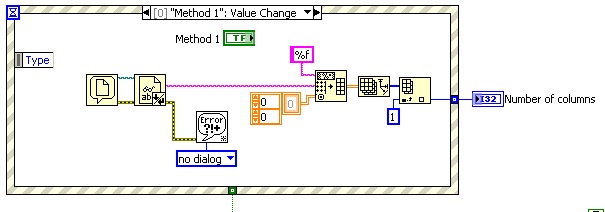
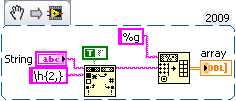
Odd number of columns in the text file
Hello everyone
From an Excel (.xls) file, I saved (tabs-delimited text) file and open in Labview. The file has only 2 columns (apparently), but my VI says he has 12! I tried to find any character 'lost' in the file but it's all in the first two columns.
However, if I open the .xls file, save the text file delimited tab, open this tab delimited text file using excel, hit save and then open in my VI, the VI will tell me that the file has only 2 columns. Strange.
Enclosed please find my VI (I tried two different methods to load the file and got the same results).
Thank you
Dan07
Around this line, you will notice a bunch of tabs:
240.4926373\t507.1851226\t\t\t\t...
Edit: I would like to clean up the source, but if you're stuck here is a way to clean:
-
Remove the node from the Cluster
Hello, I followed Metalink Doc-ID 466975.1 vip remains online, but how do I remove vip entrance? I work with 10.2.0.4 version.
Thanks in advance!Looks like the entrance is not excluded from OCR.
Use crsctl unregister command to remove it from the OCR.
Also take a backup of the OCR prior to this operation.
Concerning
Rajesh -
Is there such a thing as the node master RAC cluster?
The GI version: 11.2.0.4
Operating system: Linux/Unix platforms
Cluster CARS being an ACTIVE configuration / ASSET, is there such a thing as master node in a RAC cluster?
If there is such a thing as a master node, in a 4-node RAC cluster, how can I find which is the "master" node and why it is called a "master node"?
Unlike some cluster systems, it is not really a "master node" for Oracle Grid Infrastructure. This link of @rchem to the Uwe Hesse blog entry contain information about a master node but note carefully the specific tasks for this master.
Oracle clustered systems have resources. Everything is a resource. The listener is a resource. The instance is a resource. A block of data is a resource. Each resource has a master node and that node may be all in the cluster. And resources of the same type can have different masters. If just because Node1 is the master of the resource for blockXYZ does mean that Node1 is the master of the resource for all blocks. BlockABC can have his mastery of the resource on Node2.
Most people think of a master node like the one that makes decisions for the rest of the cluster. For example, here is a link to a Dell article: http://en.community.dell.com/techcenter/high-performance-computing/w/wiki/hpc-cluster-nodes
In this article, it says "the General function of the master node must be the mastermind behind the group." However, GI of Oracle cluster doesn't have this concept. There is no a node responsible for the rest of them. All decisions that need to be made are distributed on all nodes of the cluster, piece meal.
HTH,
Brian
-
The number of nodes of BPEL table + xpath
Hello
Try to get the size or the number of the group to the node, but get the error of selection, an idea?
below variableentree date node < ns1:error > is table and I use the xpath query,
County (bpws:getVariableData('outputVariable','payload','/ns1:transaction/ns1:exceptions[1]/ns1:error[1]')) to count the number of nodes of the error, but get selection error
< status = taskId 'dia' = '1' txnPriority = '1' >
< ns1:txnIdentification >
DG of < ns1:txnId > < / ns1:txnId >
DG of < ns1:instanceId > < / ns1:instanceId >
DG of < ns1:processName > < / ns1:processName >
DG of < ns1:branchCode > < / ns1:branchCode >
Hg < ns1:moduleCode > < / ns1:moduleCode >
godu < ns1:currentUser > < / ns1:currentUser >
Hg < ns1:txnComment > < / ns1:txnComment >
< ns1:stage >: < / ns1:stage >
Lisette < ns1:taskOutcome > < / ns1:taskOutcome >
Hg < ns1:operation > < / ns1:operation >
< ns1:realm > gh < / ns1:realm >
< / ns1:txnIdentification >
< ns1:transactionData >
Lisette < ns1:moduleData > < / ns1:moduleData >
< / ns1:transactionData >
< ns1:exceptions >
< ns1:error >
< ns1:ecode > 1 < / ns1:ecode >
< ns1:etype > 1 < / ns1:etype >
< ns1:edesc > 1 < / ns1:edesc >
< / ns1:error >
< ns1:error >
< ns1:ecode > 1 < / ns1:ecode >
< ns1:etype > 1 < / ns1:etype >
< ns1:edesc > 1 < / ns1:edesc >
< / ns1:error >
< / ns1:exceptions >
< ns1:txnAuditDetails >
Thank you
< ns1:prevRemarks > fg < / ns1:prevRemarks >
< ns1:currRemarks > fg < / ns1:currRemarks >Ora:countNodes('outputVariable','payload','/ns1:transaction/ns1:exceptions/ns1:error)
use the expression in the expression builder above and assign to the variable on the right side...
Thank you
N -
List/number of nodes in a CCR cluster
Hello
Perhaps these questions already been asked and answered - is there a way to know how many knots (or list of names of the nodes) in a RAC cluster? I found the command SRVCTL who can tell which instance of a RAC database is running on node/server but I just want to know the names including the RAC cluster.
ConcerningPlease use olsnodes command from any node in the cluster. Lists all the nodes of the RAC cluster.
-
Why drives with voting rights are always an odd number
I have a query that why voting disk are always recommended in odd numbers.
The voting disk must reside on a shared disk that is accessible by all nodes in the cluster. For high availability, Oracle recommends that you have several disks with voting rights. Oracle Clusterware can be configured to manage records with multiple voting rights (multiplexing), but you must have an odd number of voting records, such as three, five and so on. Oracle Clusterware supports a maximum of 32 disks with voting rights. If you set a single voting disk, then you must use external mirror to provide redundancy.
A node must be able to access more than half the disks with right to vote at any time. For example, if you have five voting disks configured, then a node must be able to access at least three drives with right to vote at any time. If a node cannot access the required minimum number of discs with right to vote, it is expelled or removed from the cluster.
Here I have a table:
Total number of vdisk (n) Minimum vdisk required by nodes (> n/2) no vdisk can be failed at the same time
1 1 0
2 1 1
3 2 1
4 2 2
5 3 2
6 3 3
7 4 3
Here, it is clear that it does not matter as the vdisk 4 or 5, the number of vdisk can be failed at the same time would be 2. So, not sure why an odd number of voting records are recommended.
Please suggest.
Kind regards
Dheeraj van Voorde(1) why don't we not create an odd number of voting record?
With regard to the vote of the disks are concerned, a node must be able to access exclusively more than half of the discs with the right to vote at any time. So if you want to be able to tolerate a failure of n disks to vote, you must have at least 2n + 1 configured. (n = 1 means 3 discs with voting rights). You can configure up to 32 drives with right to vote, providing protection against the 15 simultaneous disk failures.
Oracle recommends that customers use drives 3 or more with right to vote in Oracle RAC 10g Release 2. Note: For best availability, 3 files of voting should be separate physical disks. It is recommended to use an odd number as 4 drives will be more highly available than 3 disks, 3 1/2 is 1.5... rounded up to 2, 4 1/2 is 2, once we lose 2 discs, our cluster fails with 4 disks with voting rights or 3 discs with right to vote.(2) only the cluster checks actually for the counting of the votes before node eviction? If so, could you expain this process briefly?
Yes. If you lose half or more than all your discs with right to vote, then nodes get evicted from the cluster, or nodes to expel from the cluster.(3) what is the logic behind the documentaion note which says "each node must be able to see more than half the disks with right to vote at any time"?
The answer to the first question is will also answer this question.answered by: Silva
Reference: Question on voting drive
Question on voting drive
Maybe you are looking for
-
"Scratch" feature Sports Watch :)
Hi all! Already 6 months to my 'Sport Watch 42'. I really like it, but there's one thing large 'print to spoil. ION - x glass is a low point in this very good product (I already agreed battery of low capacity and the weakness "to life".) I'm really f
-
I can't get my godaddy imap email working. I checked the settings again and again. When I use the same setings on my Droid X, they work without problem. The error I get is "password" or incorrect user name but they are correct. This would be a matter
-
Image with my .iagonal 6 d line problems.
Hello, my name is Lindy and I'm new to this forum. I had a problem with my Canon 6 d which translates some of my images appear with a diagonal black line in the upper left corner. I have seen this problem with my L 100mm lens and my 16-35mm lens. If
-
Hello support, I downloaded an ISO image of the ACS and test it on my vmware. I tried to integrate my acs with my active directory which is also inside my vmware. I configured the NTP ACS pointing to my AD server server. But the connection failed whe
-
So. A few months later, I myself brought a phone. It went perfectly, but he had some problems. Next to my 3 G symbol, I had this little picture that looked like a bb logo. And when I have internet access, I can use it for data things. (2 weeks later)