Passage of data with multiple senders to multiple rates for forest exploitation
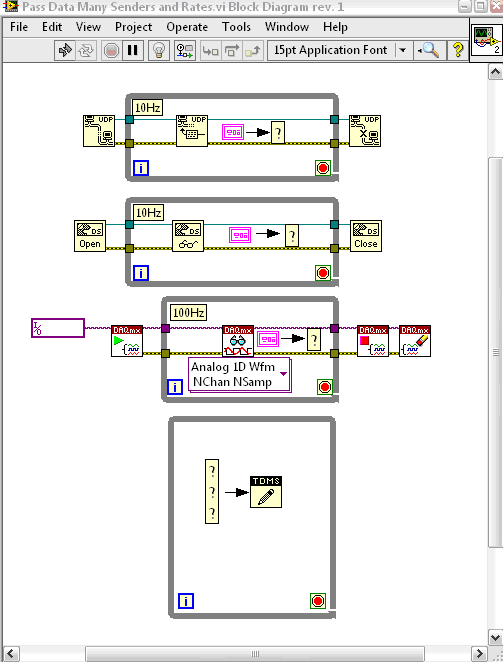
The image above shows my situation. I have a 10 Hz Datasocket read, reading UDP 10 Hz and 100 Hz DAQmx read. I need assemble all these data in a single stream for logging. If I'm waiting for my network stuff, I won't be able to collect the data (because of the dependencies of data stream). If I set waiting periods (10 ms to 100 Hz), playback of the UDP will throw an error. So if I ignore the error, I never found out if the network actually times out. Any help is appreciated.
The code is obviously here for representation and not intended to be an element of code work
Tags: NI Software
Similar Questions
-
Separation of data with multiple headers
Hello
I have a data set that has 6 columns with headers containing information for a cycle of some (data file is attached). About 200 lines later, so that I have a different set of data with 6 columns cycle 2 with a space and a new header and any other 400 lines later I data for cycle 5 with a space and a new header. This pattern is repeated throughout the data set.
I need a way to separate this data so that I can trace different cycles. When I import this data set in Diadem with the Wizzard use it does not recognize the spaces and the new headers. He label spaces and headers "NO value", there are discontinuities in the data. Is there a way to separate the cycles in this dataset in tiara?
For example, I would have 215 lines thru 220 630 thru 6 lines, lines 635 thru 1046, lines 1051 to 1462, etc.. This way I can trace different cycles against the execution time.
Hi wils01,
Here's a use I created that loads your file data in each cycle in a separate group of the data portal.
Brad Turpin
Tiara Product Support Engineer
National Instruments
-
Problems with multiple monitors for critical update Windows 7
Since the update critical October 1, I can no longer run multiple monitors.
According to the record, this update made changes at the same time the driver for my AMD Radeon 7470 and Dell monitor 1.1 card, and I've updated the software.
Devices for work and when I pass cables or remove cables. Yet they are simply not recognized as connected.
Hello Kent,
Thanks for posting your question on the Microsoft community.
Thank you for details on the issue.
This problem may occur because of corrupted or incorrect display settings.
I suggest you run the hardware and devices Troubleshooter and check.
Reference:
Open the hardware and devices Troubleshooter
http://Windows.Microsoft.com/en-us/Windows7/open-the-hardware-and-devices-TroubleshooterPlease also read this article and check.
Work and play better with multiple monitors
http://Windows.Microsoft.com/en-us/Windows7/work-and-play-better-with-multiple-monitorsI hope this information helps.
Please let us know if you need more help.
Thank you
-
SearchIndex.FindByIP () for VM with multiple NICs for
If a virtual machine has multiple vNIC and each vNic has its own IP address, the SearchIndex.FindByIp () can support
VM search based on any of the IP address of the interface of the virtual machine, or the API only supports
VM look after the IP corresponding host name of the virtual machine?
Hypothesis: VMware Tools is running on the virtual machine (which is not the case in my lab environment, where)
I can't test out easily).
Thank you.
Hello - I have tested in my lab - SearchIndex.FindByIP () is able to find another IP VM - not just a primary address-based
The virtual machine tools has been installed on the guest operating system
HTH
-
date max with multiple joins of tables
Looking for expert advice on the use of max (date) with multiple joins of tables. Several people have tried (and failed) - HELP Please!
The goal is to retrieve the most current joined line of NBRJOBS_EFFECTIVE_DATE for each unique NBRJOBS_PIDM. There are several lines by PIDM with various EFFECTIVE_DATEs. The following SQL returns about 1/3 of the files and there are also some multiples.
The keys are PIDM, POSN and suff
Select NBRJOBS. NBRJOBS.*,
NBRBJOB. NBRBJOB.*
of POSNCTL. Inner join of NBRBJOB NBRBJOB POSNCTL. NBRJOBS NBRJOBS on (NBRBJOB. NBRBJOB_PIDM = NBRJOBS. NBRJOBS_PIDM) and (NBRBJOB. NBRBJOB_POSN = NBRJOBS. NBRJOBS_POSN) and (NBRBJOB. NBRBJOB_SUFF = NBRJOBS. NBRJOBS_SUFF)
where NBRJOBS. NBRJOBS_SUFF <>'LS '.
and NBRBJOB. NBRBJOB_CONTRACT_TYPE = 'P '.
and NBRJOBS. NBRJOBS_EFFECTIVE_DATE =
(select Max (NBRJOBS1. NBRJOBS_EFFECTIVE_DATE) as 'EffectDate '.
of POSNCTL. NBRJOBS NBRJOBS1
where NBRJOBS1. NBRJOBS_PIDM = NBRJOBS. NBRJOBS_PIDM
and NBRJOBS1. NBRJOBS_POSN = NBRJOBS. NBRJOBS_POSN
and NBRJOBS1. NBRJOBS_SUFF = NBRJOBS. NBRJOBS_SUFF
and NBRJOBS1. NBRJOBS_SUFF <>'LS '.
and NBRJOBS1. NBRJOBS_EFFECTIVE_DATE < = to_date('2011/11/15','yy/mm/dd'))
order of NBRJOBS. NBRJOBS_PIDMWelcome to the forum!
We don't know what you are trying to do.
You want all of the columns in the rows where NBRJOBS_EFFECTIVE_DATE is the date limit before a given date (November 15, 2011 in this example) for all rows in the result set with this NBRJOBS_PIDM? If so, here is one way:with GOT_R_NUM as ( select NBRJOBS.NBRJOBS.*, NBRBJOB.NBRBJOB.* -- You may have to give aliases, so that every column has a unique name , rank () over ( partition by NBRJOBS.NBRJOBS_PIDM order by NBRJOBS.NBRJOBS_EFFECTIVE_DATE desc ) as R_NUM from POSNCTL.NBRBJOB NBRBJOB inner join POSNCTL.NBRJOBS NBRJOBS on (NBRBJOB.NBRBJOB_PIDM = NBRJOBS.NBRJOBS_PIDM) and (NBRBJOB.NBRBJOB_POSN = NBRJOBS.NBRJOBS_POSN) and (NBRBJOB.NBRBJOB_SUFF = NBRJOBS.NBRJOBS_SUFF) where NBRJOBS.NBRJOBS_SUFF != 'LS' -- Is this what you meant? and NBRBJOB.NBRBJOB_CONTRACT_TYPE ='P' and NBRJOBS.NBRJOBS_EFFECTIVE_DATE <= to_date ('2011/11/15', 'yyyy/mm/dd') ) select * -- Or list all columns except R_NUM from GOT_R_NUM where R_NUM = 1 order by NBRJOBS_PIDM ;Normally this site does not display the <>inequality operator; He thinks it's some kind of beacon.
Whenever you post on this site, use the other inequality operator (equivalent), *! = *.I hope that answers your question.
If not, post a small example of data (CREATE TABLE and INSERT, only relevant columns instructions) for all the tables involved and the results desired from these data.
Explain, using specific examples, how you get these results from these data.
Always tell what version of Oracle you are using.
You will get better results faster if you always include this information whenever you have a problem. -
Aggregation of data from multiple sources with BSE
Hello
I want to aggregate data from multiple data sources with a BSE service and after this call a bpel with a process of construction of these data.
1 read data from the data source (dbadapter-select-call)
2. read data from the data source B (dbadapter-select-call)
3 assemble the data in xsl-equiped
4. call bpel
Is this possible? How can I get data from the first call and the second call to conversion data? If I receive data from the second call, the first call data seem to be lost.
Any ideas?
GregorGregor,
It seems that this aggregation of data is not possible in the BSE. This can be done in BPEL too using only assigned but not using transformations. I tried to use transformations by giving the third argument to the function ora: processXSLT. But couldnot get the desired result.
For more information on the passage of a second variable (of another schema) as a parameter to xslt pls refer to the post office
http://blogs.Oracle.com/rammenon/2007/05/
and the bug fix 'passage BPEL Variable content in XSLT as parameters'.
Hope this helps you.
Thank you, Vincent.
-
Indicator of waveform data dashboard with multiple locations
I have a chart in waveform with multiple locations on my main VI running.
I use the Application Dashboard data 2.2.1 on my Ipad to monitor table of wave shape of my running app. I placed a marker on my Ipad and also related waveform with my waveform array variable. I can't play my data dashboard application because it shows unable to connect to the server. I noticed that it is because of multiple plots being plotted on my table of waveform.
I could only play the App data dashboard when it is just a single parcel related to an indicator on the App.
My question is if it's possible to have a graphical indicator of waveform on a data dashboard that has several plots being plotted and not only a single square, and how to configure it?
Thank you.
Click on Bravo and select as an accepted answer. You are welcome.
-
Problems with multiple worksheets XY plotting (program generates repeated data)
Hello
I want to make a small program that will reduce the amount of time to go forward with the measurement data. I get data into .dat format, where all the files consist of frequency measurement with an X and a Y column. The problem is that I made 4 experiments (X column is the same for each experience) with 15 measures file each and more than 500 points of measurement in each file. I would like to make a simple manipulation and this copy that information to a file with same X column and multi-column, later I could use these data with Excel or origin (do it manually, it's frustrating and time consuming).
At the beginning my program reads the background information with X and Y (b), and after I open the worksheet to insert the X and data of Y (n). (make a simple manipulation, like dividing Y (n) /Y (b), program show a graph of the current data and another graph multiple data, which are stored and must be exported in .txt, .dat or directly to Excel (which is more preferable)). I'm OK with the opening of several files of data, but which are not okay with copy/paste file and handle all that data manually, but that's my motivation for this program.
The attached example can do all this (except for the entry in the file). He draws multiple charts on a XY chart using cluster and travel records. It is even possible to extract data in Excel, all that graphic, but the real problems comes with data are always added because of the loop. This gives a lot of empty and repeated data later. I'm jonesing to get rid of this. I have also attached several files of measure: 1 background and 3 measures.
P.S. I tried to save time thanks to this program, but now, I spent more time than if I did it manually

Your program absolutely no sense. What is the purpose of the structure of sequence? It just sits there, operating both in parallel to the while loop. Probably that you read from the local variables before other parts of the program had a chance to write valid data for them.
In the while loop, you have a case of timeout that adds the same data over and over again, every 50ms. Why?
Your mechanical actions "switch release" are misguided. Use actions to latch and remove structures deal as part of the event.
Try to rethink the problem once the mode, and then solve the problem with 20% of your current code. See how far you get.
-
How to query the data of Contact with multiple fields
How can I query the data of Contact with multiple fields?
For example, I'll get contacts which are changed after a point at the specified time and whose country is US. How could I make the chain of research of the SOAP API "Query"?
And I also want to know how to make a search term for RESTful API for contacts above.
Any suggestions?
Thank you.
Hi Biao,
The following document describes how query for multiple fields using the SOAP API: request a Contact from several fields.
And you can search multiple fields using the REST API with the & operator. For example, to search for a Contact by e-mail address and date of creation:
- " emailAddress ='[email protected]' & converted > = '1369828886'".
Hope this helps and please let us know if you need more information.
Thank you
Fred
-
tablespace with multiple data files
Hi all
We have RHEL4 server with oracle 10 g 2 inside.
can we create a tablespace with multiple data files? I mean while creating a tablespace itself, we should be able to create two or more data files (should not use ALTER tablespace command).
If possible, please give me the SQL to do this (assume that I need to create a tablespace with two data files).
Thanks in advance...Not so difficult isn't it?
create tablespace datafile test
'1.dbf' size 1 m REUSE AUTOEXTEND ON NEXT 32 M MAXSIZE 1500 M,
'2.dbf' size 1 M REUSE AUTOEXTEND ON NEXT 32 M MAXSIZE 1500 M
EXTENT MANAGEMENT SEGMENT LOCAL SPACE MANAGEMENT AUTO; -
Can transport data in multiple graphs
Hey,.
Right now I'm working on a project of analogue data of feedback from sensors on a petblowing machine to a pc at the office.
So far, I can send messages with a different id... The messages of 4 part Arb ID, ID seen, length (Yes), value.
The intension is to separate data on different graphics. As ID 32 goes to figure 3 and 16 ID goes to figure 2. Now it's my problem.
The values are similar 0-255, and they must also be monitored. So I had 4 plots on a graph to change the color on the value.
But when I want to redirect messages to the different graphics that I receive all my data but the double. Or when I send the data to a chart the
another past and if I look at with my probe he values changing if nothing was happening. So far, it works when I show my
data on a graph and proceed with a deal that leaves an id to pass so that the graph can be drawn. Someone an idea how I can make it work with multiple
graphs?
If you want to take a look at the code all also.
Thanks in advance...
OK so I'm done today of the VI... Normally, everything should work as it should.
I want to thank demux for the great support and everybody to watch...
The final VI is attached...
-
Gears - error when you try to insert values into a table with multiple columns
Hello
I started playing with the gears and SQlLite today and I get an error when I try to insert values into a table with multiple columns.
I have:
var db = google.gears.factory.create('beta.database'); db.open('developerSet'); db.execute('create table if not exists Developers (DeveloperName text, DeveloperAge int)'); var devName = "Davy" var devAge = 32; try { db.execute('insert into Developers values (?, ?)', [devName, devAge]); alert('success'); } catch (e) { alert(e); }I get the error:
net.rim.device.api.database.DatabaseException; insert into developers values (?,?): SQL logic error or missing database.
I use this reference: http://code.google.com/apis/gears/api_database.html
Everything works if I have only one field as:
var db = google.gears.factory.create('beta.database'); db.open('developerSet'); db.execute('create table if not exists Developers (DeveloperName text)'); var devName = "Davy" var devAge = 32; try { db.execute('insert into Developers values (?)', [devName]); alert('success'); } catch (e) { alert(e); }I use the plug-in Visual Studio 2.0 for 2008 that are running Windows XP SP and Simulator 2.13.0.56
Thank you
Davy
Yes, a SQLite database will persist between battery pulls. The database is registered either to internal MEM or removable media (not the device memory), depending on which is available on your device.
In general, its not considered a best practice to remove your table as soon as it is empty and re - create it again when you want to add data. This adds extra overhead fresh for the final, delete and insert first for a given table. Instead, define and finalize your drawing before you create your table. Once created, review the static schema.
That being said, for development purposes, it may be easier to provide an easy way to drop your tables while you develop your schema.
See you soon,.
Adam
-
Two entities with multiple relationships
We have problems with features including multiple relationships. We use data version 4.0.3.853 maker
I saw the problem with a simple example.
I create a PERSON entity with primary key ID

I create another PARENT table with a ratio of 1-1 identification with ANYONE

An ID attribute correctly created on the PARENT entity

Now, I create another 1-n PERSON_HAS_PARENT of PARENT (1 side) relationship to ANYONE (north face)

I would expect Data Modeler to create a separate attribute on the PERSON table for the new relationship
Instead the Panel attributes FK remains empty and if I engineer the model to a relational model I find that
two foreign keys PARENT_IS_PERSON and PERSON_HAS_PARENT insist on the same attributes.

In addition, I can't find any way to force the Data Modeler to use a separate target for the relationship of PERSON_HAS_PARENT attribute.
Hello
Version 4.1 has been published and includes a fix for this problem.
David
-
Is possible to write the INSERT statement that fills two columns: 'word' and 'sense' of the file text with multiple lines - in each line is followed word that is the meaning?
Hello
2796614 wrote:
Is possible to write the INSERT statement that fills two columns: 'word' and 'sense' of the file text with multiple lines - in each line is followed word that is the meaning?
Of course, it is possible. According to what the text file looks like to, you can create an external table that treats the text file as if it were a table. Otherwise, you can always read the file in PL/SQL, using the utl_file package and INSERT of PL/SQL commands.
You have problems whatever you wantt? If so, your zip code and explain what the problem is.
Whenever you have any questions, please post a small example of data (CREATE TABLE and only relevant columns, INSERT statements) for all of the tables involved and the exact results you want from these data, so that people who want to help you can recreate the problem and test their ideas. In this case, also post a small sample of the text involved file.
If you ask about a DML operation, such as INSERT, then INSERT statements, you post should show what looks like the tables before the DML, and the results will be the content of the table changed after the DML.
Explain, using specific examples, how you get these results from these data.
Always say what version of Oracle you are using (for example, 11.2.0.2.0).
See the FAQ forum: Re: 2. How can I ask a question on the forums?
-
With multiple vcenter inventory
Hi guys,.
Try to get connected with multiple vcenter inventory,
Have problems with the release of some VM are attributed to wrong Vcenter and running OS is not always correct.
Can anyone help?
Here's the script:
$VmInfo = Foreach ($vcenter in $global: DefaultVIServers) {}
ForEach ($Datacenter in (Get-Data Center |)) Sort - Object - property name)) {}
ForEach ($Cluster in ($Datacenter |)) Get-Cluster | Sort - Object - property name)) {}
ForEach ($VM in ($Cluster |)) Get - VM | Sort - Object - property name)) {}
ForEach ($HardDisk to ($VM |)) Get-hard drive | Sort - Object - property name)) {}
"" | Select-Object - property @{N = "VM"; E = {$VM. Name}},
@{N = 'Vcenter'; E = {$vcenter. Name}},
@{N = "OS"; E = {$vm. Guest.OsFullName}},
@{N = 'Center'; {E = {$Datacenter.Name}}.
@{N = 'Cluster'; E = {$cluster. Name}},
@{N = 'Host'; E = {$vm. VMHost.Name}},
@{N = "HostVersion"; E = {$vm. VMHost.version}}
}
}
}
}
}
$VmInfo | Export-Csv - NoTypeInformation - UseCulture-Path "D:\report.csv".
Try like this.
-What is produced fewer lines?
$VmInfo = Foreach ($vcenter in $global: DefaultVIServers) {}
ForEach ($Datacenter in (Get-Data Center-Server $vcenter |)) Sort - Object - property name)) {}
ForEach ($Cluster in ($Datacenter |)) Get-Cluster-Server $vcenter | Sort - Object - property name)) {}
ForEach ($VM in ($Cluster |)) Get-VM-Server $vcenter | Sort - Object - property name)) {}
ForEach ($HardDisk to ($VM |)) Get-disk hard-Server $vcenter | Sort - Object - property name)) {}
"" | Select-Object - property @{N = "VM"; E = {$VM. Name}},
@{N = 'Vcenter'; E = {$vcenter. Name}},
@{N = "OS"; E = {$vm. Guest.OsFullName}},
@{N = 'Center'; {E = {$Datacenter.Name}}.
@{N = 'Cluster'; E = {$cluster. Name}},
@{N = 'Host'; E = {$vm. VMHost.Name}},
@{N = "HostVersion"; E = {$vm. VMHost.version}}
}
}
}
}
}
$VmInfo | Export-Csv - NoTypeInformation - UseCulture-Path "D:\report.csv".





Maybe you are looking for
-
Once I change my browser proxy works very well. The problem is whenever I open the program.
-
Enter key does not not on internet explore
on internet explorer, if I hit the return/enter key to confirm a url, nothing happens. same problem if I click on 'GO '. However, I can use Explorer wide band BT ok, and by clicking on the links on the page internet explore seems to be good too. I th
-
HP ENVY laptop - 15-ae103na: HP Envy 15 AE-103NA fingerprint reader
SO, since having a HP laptop, I had one for 4 months and then HP gave me this beautiful machine... Unfortunately questions... maybe my fault this time well! So, I deleted windows 10, installed a Samsung 1 TB SSD and installed my genuine copy of Windo
-
I disable my touchpad on HP laptop 15 with windows 10 it works but then when I turn my computer off voltage and turn that back on the touchpad is enabled and I have to go and turn it off again. I go through this every day. Can not turn off the touc
-
I want to do more than one check box at run time. So I did it with listbox, but I can't check it out. How can I do? Help, please I have attached my VI. Thanks in advance.