Regular expressions - remove a Timestamp?
I have hundreds of simple HTML pages. I want to remove the timestamp from them, which looks like this:[19:45]
I tried to use the generic functionality, but the problem is, I want MEDIA, as well past. Unfortunately, I only managed to remove either the last bracket (with the opening bracket and time still intact) or all my data completely. How can I successfully delete the various moments and their media without touching the rest of my data?
Find/replace, with the use of regular expressions in motion:
To find:
[\[\D\d?:\ d\d?------]
Replace:
(leave blank)
--
E. Michael Brandt
www.divaHTML.com
www.divahtml.com/Products/scripts_dreamweaver_extensions.php
According to the standard scripts and the Dreamweaver Extensions
www.valleywebdesigns.com/vwd_Vdw.asp
JustSo PictureWindow
JustSo PhotoAlbum, and alia
--
Tags: Dreamweaver
Similar Questions
-
regular expression to remove the zeros on the right
I need a regular expression to remove the zeros after the decimal point. I tried (?.)<=\.\d+?)0+(?=\D|$) but="" i="" get="" a="" error="" about="" look="" behind="" not="" a="" fixed="" length="" or="" something="" like="" that.="" i="" am="" not="" a="" regex="" expert="" and="" i="" was="" wondering="" just="" how="" to="" do="" this="" with="" regular="" expression="" or="" some="" other="">
Z.K. wrote:
[...] or some other way.
I tried and I tried but I couldn't crack with a regular expression, so I took the easy way. The first match found pattern the comma and the other removes the zeros to the right of the rest. It is not discriminate between numbers and all the rest, though.
-
Regular expression to remove the space in the HTML tag
Hi all
My HTML string is as below.
Select ' < CityName > RICHMOND < / Nom_ville > < StateCd > ABCD CDE < StateCd / > < CtryCd > CAN < / CtryCd > < CtrySubDivCd > BC < / CtrySubDivCd > ' double Str Output desired is
< CityName > RICHMOND < / Nom_ville > < StateCd > ABCD CDE < StateCd / > < CtryCd > CAN < / CtryCd > < CtrySubDivCd > BC < / CtrySubDivCd > I want to remove these spaces of the tag value box with only spaces otherwise leave it as what. Please help to implement the same using regular expressions.
Hello
We don't know what you want. This site seems to be formatting your message in a weird way.
As the statement
SELECT «...» "THE DOUBLE;
without formatting, to show your entry and after the exact output desired friom as, with as little in shape as possible. It might be useful if you use some character like ~ instead of spaces (just for viewing; we will find a solution that works for spaces).
To remove the text which consists of spaces and nothing else between the tags, you can say
REGEXP_REPLACE (str
, '> +<>
, '><>
)
How is this string generated? Maybe there is an easier and more effective way to keep the bad wrtings sub off the chain in the first place.
-
Regular expression to remove space after the tag < a... >?
Hello
I'm relatively new to using regular Expressions, but am in need who will help me find all the tags < a... > with space immediately after this tag and replace it with the exact same tag, but not space after the tag < a... >.
Thus, for example, a regular expression that there is:
< a href = "somelink.html" > Somelink < /a >
as well as:
"< a href =" # "MM_swapImgRestore" onmouseover = "MM_swapImage (' sub-nav_button_professional_portal',", ' images/sub-nav_button_ professional_portal_f2.png', 1 ') "> Somelink < /a >
And just remove the space in the hyperlink. Does anyone know how to do this?
Find-
\
Replace-
Post edited by: Murray * CPA *.
-
Regular expression to remove a single carriage return character
Hi all
What is the regular expression to remove only one character to return to a text string. I have something like this:
1
(two returns)
2
and I want to delete only one of the characters turn it over so I'll go
1
2 (one after the other
I know / r but ot deletes all of the text string.
Thanks a lot for any help
Try something like:
(in my message window):
s = "a" & RETURN & RETURN & "two".
placed s
l = [s]
put re_replace (l, "(?)")<=\r)\r", "g",="">
Place the [1]
(exit):
-"a".two ".
-1
-"a".
two ".I don't know how effective the situation described above could be for research, but
You can also try:
put re_replace (l, "\r\r", "g", RETURN)
or:
put re_replace (l, "\r{2"}, "g", RETURN)
However, these last 2 only work in the situation where there
exactly 2 returns you want to replace with a single DECLARATION - the first
replaces any number of multiple returns with one RETURNIt is possibly more effective than the first - it will replace again
all multiple with a single; but it will unnecessarily replace one
RETURN character with one character in RETURN - but I'm not a regular expression
Expert:
put re_replace (l, "\r+", "g", RETURN) -
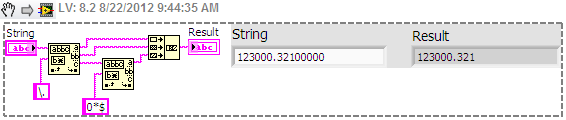
Build a regular expression for data series of Arduino.
All,
I have a few Arduinos Council integrated into a test configuration that I can't save the data of. I now need to be able to see my data in real-time as it comes on the serial port. I found a VI that seems like it should work, my problem is that I can't get a regular expression to work.
The VI is not mine, but if I can get this working, I can easily put it in my VI.
Here's my Arduino code; This is the timestamp, followed four data points, with delimiters tab. It prints on the serial port as
190876 762314 814437 1108235 1091719
Serial.print(sTime); //Serial.print(", "); Serial.print("\t"); data = getdata(dataRead); data = data>>4; Serial.print(data); //Serial.print(", "); Serial.print("\t"); data = getdata(dataRead1); data = data>>4; Serial.print(data); //Serial.print(", "); Serial.print("\t"); data = getdata(dataRead2); data = data>>4; Serial.print(data); //Serial.print(", "); Serial.print("\t"); data = getdata(dataRead3); data = data>>4; Serial.println(data);I think it is especially a problem with regular expression. Any advice or pointers would be great.
I wish there was a place where you just have to copy and paste my thong in and get a regular expression.
Do not use bytes to the port!
Take advantage of the termination character you have. Activate it on the series set up and set it to the newline character.
Now the VISA Read will wait until she has the entire line (or timeout if it does not). Then you can analyze your data out there.
I think the problem with your code, it's that you're looking for a backslash n. Not a line break. Turn it on the style of display of this constant and you will see it is fixed for normal display and backslash is no bar display.
-
Regular expression - get longer channel number
I think it's easy, but I can't get it. Lets say I have a string "A1_1000", I would like to remove the 1000 using regular expressions. When I fed regular expression Match I get '1', which is not the longest number. I know other ways to do it, but I want to clean the solution in one step. Anyone know the regular expression to the right to achieve this? Thank you!
ceties wrote:
It is the best solution I've been able to come. I wonder if there are "more smooth way" without the cycle of.Since several checks are needed, I would tend to beieve we must travel opportunities. in this example

I start to check at '0' offset in the string to a number. Provided that I have find a number, I check if it is longer that any previous number, I found and if so, store the new number more in the shift register.
Have fun!
Ben
-
How can I the date and time using regular expressions
Hi all
I have depolyed filtering the log agent. While setting properties, I would like to recover the file that is generated at the present time, but along the way, I am unable to define, what regular expression that I provide retireves date and time specific file...
Leave with kindness, men know is it possible to do?
Thanks in advance.
Shiva
This seems to be the same question I can't add a timestamp in logfilter, so I'll answer in this thread. Please check the two wires as "Answered" when the issue has been resolved.
Kind regards
Brian Wheeldon
-
Validation using regular expressions or oracle fn
Hello
I want to apply validation to a column. I'm trying to see if I can use the regexp_replace function to find a boss and see if I can replace it to a better format. Can someone help me with these rules?
1. only the characters a - z, A - Z, 0-9, ', - is allowed. If there are no other characters, then these characters must be removed.
2. name should not begin with a symbol.
3. If there is any symbol permitted in the name, (for example the hyphen) then the hyphen should be preceded and followed by a space.
I would like to know if the above can be obtained by regular expressions or any other function will be useful to achieve the same.
Thank you very muchCherkaoui
HI, Charan,
Whenever you have a problem, please post a small example data (CREATE TABLE and only relevant columns, INSERT statements) of all the tables involved, so that people who want to help you can recreate the problem and test their ideas.
Also post the exact results you want from this data, as well as an explanation of how you get these results from these data, with specific examples. Post in this case, maybe 5 or 10 strings, and what you would like to see (a string corrected, or a 'yes' / 'No' flag saying if this string follows rules.)
Always say what version of Oracle you are using (for example, 11.2.0.2.0).
See the FAQ forum: Re: 2. How can I ask a question on the forums?
2784427 wrote:
Hello
I want to apply validation to a column. I'm trying to see if I can use the regexp_replace function to find a boss and see if I can replace it to a better format. Can someone help me with these rules?
1. only the characters a - z, A - Z, 0-9, ', - is allowed. If there are no other characters, then these characters must be removed.
2. name should not begin with a symbol.
3. If there is any symbol permitted in the name, (for example the hyphen) then the hyphen should be preceded and followed by a space.
I would like to know if the above can be obtained by regular expressions or any other function will be useful to achieve the same.
Thank you very much
Cherkaoui
Sorry, we don't know what you want to do.
1 seems to mean you want to change the given string so that it follows the rules. (What exactly are special characters? Are there only 2 special characters: single quotation mark and hyphen?)
2 seems to tell us that you want to check if it meets the rules
3. can be a
I'll assume that you want to modify the string so that the returned value corresponds to rules. This means that if the given string violates, 2 symbols will be removed from the beginning of the string, and if it violates 3, then spaces will be added.
I don't think that there is a way to do this with a regular expression.
You can make each with a separate REGEXP_REPLACE corrections, and make all in the same query by one nesting inside each other, like this:
SELECT REGEXP_REPLACE (REGEXP_REPLACE (REGEXP_REPLACE (: str)))
, "[^ a-zA-Z0-9 cm-]"
)
, '^[''-]+'
)
, ' *([''-]) *'
, ' \1 '
) AS new_str
OF the double
;
of course, I can't test it, until post you some sample data and the exact results you want from these data.
Here, the inner REGEXP_REPLACE rule 1 applies. It deletes all characters except a to z small letters, capital letters A to Z, numbers, spaces, single quotes and hyphens.
Rule 2 applies the REGEXP_REPLACE middle. It removes the single quotes and hyphens that appear at the beginning of the string.
The external REGEXP_REPLACE rule 3. It guarantees that each single quotation mark or a hyphen is preceded and followed by a space. If there is already a space (or several spaces) before and/or after the special symbol, they are replaced by a single space. If this isn't what you want, it can be fixed, but it will make the expression even messier.
You might consider to write a user-defined function to normalize strings. In a function procedure, you can apply the rules one after the other. you need not nesting complicated like that. Of course, a user-defined function will be slower, but maybe it's not a problem.
Still, the above query converts the string so that the production rules.
If you just want to check whether a string conforms to the rules, you can compare the original string to the output of the above expression. If they are identical, then the string is in accordance with the rules.
-
pattern by using regular expressions match
I'm playing (and wrong) with regular expressions
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + > ') twice;
give < PSN > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.2 ') twice;
give < 231 > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.3 ') twice;
give < ABc > which confused me until I realized that < 3 25 > has not been matched, because it has a space inside
so I changed it to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ', 1.3) twice;
who gave a syntax error, so I changed it again to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ') twice;
that works, but gives < PSN > / # < 231 > # < 3 25 3 > / < ABc >
I guess because the. * corresponds to anyting that all but the last closure >
The question I have is how can I retrieve the text of mounting bracket included (even if it has multiple spaces)?
Hello
9c5dfde3-EAAE-45A7-80a1-bba8a71c826c wrote:
Thanks for that - is there a way to return all 4 surrounded by extracts of <> without resorting to PL/SQL?
Of course;
REGEXP_REPLACE (str
, '(^|>)[^<>
, '\1'
)
Returns a copy of str with all outside rafters removed, for example
<231><3 25=""> . It doesn't matter how many pairs of sharp hooks - there is.
-
regular expression replacement
Hi gurus,I have a requirement where I have to replace some characters in duplicate and retain the values of this column in order of alphabatic and digital control. Please find below examples of data
Thanks in advance
sample data:
SELECT 'ZZYYXXAAABBBDDDCCC' DOUBLE COL1
UNION ALL
SELECT 'DDDCCCAAA' OF THE DOUBLE
UNION ALL
SELECT 'SDBBACCCC' OF THE DOUBLE
UNION ALL
SELECT "99988866332154" DOUBLE
UNION ALL
SELECT "77663322996" DOUBLE
Expected:
ABCDXYZ
ADC
ABCD
12345689
23679
Hello
I don't think that regular expressions will help with that.
Here's a way to do it:
WITH single_characters AS
(
SELECT DISTINCT
col1
, SUBSTR (col1, LEVEL 1) AS a_char
OF sample_data
CONNECT BY LEVEL<= length="">
AND PRIOR col1 = col1
AND PRIOR SYS_GUID () IS NOT NULL
)
SELECT LISTAGG (a_char) WITHIN GROUP (ORDER BY a_char) AS expected
OF single_characters
GROUP BY col1
;
This assumes that col1 is unique. If this is not the case, use all that is unique, even something drift of ROWID or ROWNUM, in CONNECT BY and GROUP BY clauses.
The output I get is exactly what you posted:
EXPECTED
--------------------------------------------------------------------------------
23679
12345689
ACD
ABCD
ABCDXYZ
I guess that's what you really want.
Regular expressions can not re - organize a string so that the characters are in order; you need to split the string into pieces, order parts and then put back together them. Given that you have to do it just to get the characters in order, it's simple remove duplicates without problem with regular expressions.
-
Regular expression - elimination of comments
Hello
I am trying to solve a problem, I remove the comment text of an individual raw text stored in an oracle table.
There is no special case. I mean several models of comment.
My Version of Oracle is: 11.2.0.4.
Could you help me?
Hello
You can solve this problem with the help of the regular expression REGEXP_REPLACE.
An example for this:
SELECT STRG
, REGEXP_REPLACE (strg, ' / \ * ([^(/\*) | ^(\*/)]) *------* /', ", 1, 0) AS STRG_NEW
(SELECT
"TextBlock: / * dog."
--
CAT
"* / normal / *" people * /.
text "STRG AS FROM DUAL)
;
Original text:
==============
TextBlock: / * dog
--
CAT
' * / normal / * ' people * /.
text
Result-text:
============
TextBlock: normal
text
With this selection, you can remove every comment blocks, but it doesn't work though if the comment template is not single quotes included!
It's a simple solution, that's maybe what you are looking for.
Kind regards
David Shepherd
-
How can I refer to a variable in the regular expression
Hello friends,
I have this Regexp, extract the County code: (971)
Select regexp_replace (regexp_replace ('05-000971 7910-324324', '\D'),'^ 0 * (971)? 0?') of double;
It is very good and the need...
But, thinking about the future, someone may need to remove the country code (961), so it is better if I put the code in a variable, but
How can I list the County code via a variable since the Regexp:
but it does not work?declare a varchar2 (15); code number := 971; begin select regexp_replace(regexp_replace('000971 05 7910 - 324324','\D'),'^0*(code)?0?') into a from dual; dbms_output.put_line ( a); end;
Best regards
FatehYou must link the value of the variable code in the regular expression pattern
select regexp_replace(regexp_replace('000971 05 7910 - 324324','\D'),'^0*('||code||')?0?') into a from dual -
Helps the understanding of regular Expressions
Hello people,
I need help to understand Regular Expressions.
Can someone help me understand why second query not returning ", CA, '?-- This returns the Expected string from the Source String. ", Redwood Shores," SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA,aa', ',[^,]+,', 1, 1) "REGEXPR_SUBSTR" FROM DUAL; REGEXPR_SUBSTR ------------------------------- , Redwood Shores, However, when the query is changed to find the Second Occurrence of the Pattern, it does not match any. IMV, it should return ", CA," SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA,aa', ',[^,]+,', 1, *2*) "REGEXPR_SUBSTR" FROM DUAL; REGEXPR_SUBSTR ------------------------------- NULL
I did research on this forum and found the link on the thread "https://forums.oracle.com/forums/thread.jspa?threadID=2400143" for the basic tutorials.
Kind regards
P.The reason is that the comma between 'Redwood Shores' and 'CA' already represents the first occurrence.
So it can not match the second occurrence at the same time.You can replace to (remove the trailing ',' in the regex):
SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA,aa',',[^,]+', 1, 1) REGEXPR_SUBSTR FROM DUAL; SELECT REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA,aa',',[^,]+', 1, 2) REGEXPR_SUBSTR FROM DUAL;Published by: hm on 14.06.2012 00:52
When you remove also the leading comma you get to the BlueShadows solution.
-
Hi @ all,
I need a regular expression more difficult, I don't know Don t.
I have a big file with many pages .htm (800-1000) and I have to do the following:
http://www.domain.de/ AB % 32-xyz? myshop = 123
I have to delete the "ab % 32-xyz", the problem is, that it is, it could be each symbol, the letter or digit.
Then the area between " " http://www.domain.de/ ' 'and'? myshop = 123 "(these 2 areas are identical in all documents each time) should be removed.
Anyone could tell me how to do this with regular expressions in dreamweaver?
Thank you
Felix
P.S.: Sorry, my English is not so good, I m from the Germany
You want to replace the random text with anything?
If this is not the case, this is how you do in DW:
- Make a backup of the folder that you want to change, just in case something goes wrong
- Edition > search and replace
- In the find and Replace dialog box, select the folder in the menu drop-down "search in" and select the folder that you want to use.
- Select the Source Code from the drop-down search menu.
- Place the following code in the search text box:
(http://www \.domain\.de/) [^?] +(\? MYshop = 123) - Place the following code in the text box replace:
$1$ 2 - In Options, select the checkbox "use regular expression.
- Click on replace all. Dreamweaver warns you that the operation cannot be undone in pages that are not currently open. As long as you have made a backup, click OK to run the operation.
Maybe you are looking for
-
My MAC friends tell me NOT to use icloud email address.
My MAC friends tell me NOT to use icloud email address. They advised me that because they claim that icloud email address cannot be deleted. I speak no deletion of an Apple or iCloud account. I'm simply talking about the ability to delete an icloud
-
Re: Satellite L500D - speed wireless worsens considerably with lid closed
Hello The last 3 days have been nerve wrecking for me. I am the owner of a Satellite L500 D and at the moment, I decided to connect it to an external monitor, to enjoy a better visual experience, until I have buy a desktop computer. Well, day 1, I ha
-
I ran a program for the acquisition of data on LabVIEW 2011 32 bit and used 5-6% CPU according to the Task Manager. I ran the same program on LabVIEW 2013 64 bit and it uses processor 8-9% according to the Task Manager. I thought that the 64 bit vers
-
MORE OF MY UP FAILED DATES 8000FFFF error code... HOW DO I CAN NOT FIND INFORMATION ONLINE
8000FFFF ERROR FAILURE OF MOST OF MY DATES OF HIGH CODE... WHAT SHOULD I DO
-
APPCRASH with games, having windows vista home premiun 32 bit
Hi, I have a problem with a game (assasin greed). When I install the game (original), and then upgrade later for this patch version. When to start the game, I see the intro, then it is closed due to a problem. And this pops up: Firma del problema Adi