Authenticate endpoint via AD
Hello together,
We implement a Win 2 k 8 AD Server. X 7 scheme is being implemented and the VCS has joined the domain.
I followed the instructions of the Cisco_VCS_Authenticating_Devices_Deployment_Guide_X7 - 1.pdf
VCSConfiguration--> record--> Configuration--> = directory Restriction policy
VCSConfiguration-->--> devices--> Configuration--> Database Type = LDAP authentication
VCSConfiguration-->--> devices--> Configuration--> = Auto NTLM authentication
What I am doing wrong?
Thank you all.
Jens,
Please configure the restriction policy to 'None', 'AllowList' or "DenyList", according to your needs, I believe that the parameter 'Directory' is planned for future use for deployments using the internal directory of the VCS Services feature.
If you want to authenticate registration of endpoints regular, appearing the default subfield (and other relevant sub-areas) "Check powers", this means that endpoints trying to save this VCS would get challenged for credentials.
Once you have done this, you will need to configure your point of termination with credentials match those in the ad.
Now, if you have problems registering endpoints, you should be able to find log entries relevant to these attempts failed registration in the event on the VCS log via status > newspapers > event log.
If you need more detailed logs to resolve this, you can go to maintenance > Diagnostics > diagnostic logging, define the network log level to DEBUG and launch the journal.
When the paper is running, try to register an endpoint and when this does not work, stop the log and download it. The journal will show you the attempt of registration as well as VCS communication with the LDAP server, and that should tell you more in detail why registration / authentication fails.
If you are not able to solve the problem using these logs, I recommend that you get a TAC case open for additional troubleshooting.
Concerning
Andreas
Tags: Cisco Support
Similar Questions
-
I can authenticate 2FA via SMS message, but not using iOS device.
Codes using 4-digit SMS works well, but not if I choose another option to use an iOS device, I get no messages this way. I have iPhone 6 more, but if I lost my iPhone and had an iPad, I wouldn't have no way to receive the two factor code.
You turn on the new authentication to older two factors or two steps checking?
Here's how you can make a difference:
Two-factor authentication can be turn on only using parameters of iCloud on iOS devices running iOS 9 or Mac OS X running El Capitan (10.11) or later.
Two-step verification can only be enabled when you go to the web page of my Apple ID.
If you receive only codes by SMS, then my guess is that you are using the older two-step verification.
First be sure that you are connected to iCloud on your iPhone and iPad using the same account that you are using for the two-step verification.
Then, make sure you have find my activation of the iPhone on your iPhone and my iPad to find on your iPad. You will find the switch in iCloud decoration on both devices.
Then, connect to your Apple ID account on the web page of my Apple ID. From there, you will need to check each device you want to receive codes by sending a verification code to each device.
-
TMS directory system endpoints source folder
Hello
I came across a rather baffling problem with a few cases of TMS and I can't for the life in me know as to why this is happening.
I get the following.
in the option for creating source directory Cisco TMS, I create a new directory and link with the MSDS files and select the folder where all the end points, this creates the entries in the phone book for me as I expect with one exception, I will detail below.
H.323 = [email protected] / * /
H.323 = [email protected] / * /< this="" is="" where="" the="" issue="">
IP = IP address
I find that on some systems (this doesn't happen to all systems) in the second entry of H.323, the H.323 entry where I expect to see the directory (also known as E.164 number) number I see a URI where a field has been added at the end of the number, I'll give you a few examples below.
DN = 1234
set field = @video.net
random field = @newdomain.com
IP = 10.10.10.1
I expect to see the following.
H323 = [email protected] / * /
H323 = 1234
IP 10.10.10.1
but I don't actually see
H323 = [email protected] / * /
IP 10.10.10.1
I have purged the TMS systems and added, I searched through the xconfig for the NouveauDomaine which is invalid and I can't find anything anywhere other than on the list of areas configured SIP VCS parameters in the second area, endpoints have disabled by default SIP and in both cases I expect to see that under a SIP entry not an H.323 entry
This is the origin of the problem of when a user tries to call via the Directory site remote also responds to busy VCS is unable to find the appropriate directory number because the location request contains the domain as well as the DN.
I worked around this by adding a transform to the VCS who sees the patter of specific numbering and the bands of the area, so the calls work, but I still need to understand as to what is causing this behavior.
If I had to create the directory entries by importing information from the record of the VCS seem to be correct, its only when I try to import the entries of the endpoint via the system folder in TMS (or more exactly to import the information stored in the file on the endpoint system) I see the problem.
a very popular Adviser.
See you soon
Dave
Hello
Picked up that the case with David and it seemed that at least on the systems the international denomination on the mxp MXP has been configured. The area of intellectual property also has a configured domain uri that has caused the other symptoms. We where able to erase the questions but still yet to see if the client is actually affected by the same configuration "mistakes".
/ Magnus
Sent by Cisco Support technique iPhone App
-
Difficulties of transmission C40 to MSE 8510 via H323
Nice day
I currently have intermittent problems between a codec C40 and my MCU. When the device is composed in the bridge it does not have audio or video, it passes however.
There is no shortage of receive audio or video when composed through SIP (MCU) or dial directly from another endpoint via H323.
The unit was stable until I upgraded to TC6.2.0. I upgraded C40s all across the country and no other issues brought to the point. The problem persisted after that I get the system back to 6.1.2.
After the failure of the downgrade I upgraded to 6.2.0 and resetting the device. Once reset, I did a restore of the TMS system.
The unit is problematic since the installation. I have known problems that the unit could not pick up thermometers grounded which caused the device past security mode and increase the speed of the fans. In order to solve the problem, I upgraded the software twice. Currently, the unit may not in standby mode. I also found the camera freezes and needs a reboot to restore functionality.
System details:
C40: TC6.2.0.20b1616
MSE 8510: 4.4 (3.42)
VCS C/E: X7.2.2
Just a few comments on that for those who are interested.
This is a bug in x 6.2 and 6.1.1
https://Tools.Cisco.com/bugsearch/bug/CSCui47228
TC6.2 fail to send ack of the OLC to MCU intermittently
Description
Symptom:
TC6.2 not send OLC ack to MCU intermittently.
Conditions:
call with the MCU, intermittently receive no video and audio of MCU
Workaround solution:
try to reconnect to the call once againLast modification:
Ms 9,2013
Status:
Fixed
Severity:
Serious 2
Product:
Cisco Telepresence System Integrator C series
Support requests:
0
Known affected releases:
6.2.x
6.1.1
Known fixed releases:
6.3
6.2.1
-
Devices video reg. appellant outside outside H323 IP via Highway RMS
Hello
I just put in place devices video reg (e.g. DX80 / SX10) calling the outside direct VC IP H323 endpoint via the RMS highway.
It is a success for the appeal reg device. CM outside IP H323 endpoint outside CM IP H323. But that can not display caller correctly as SIP address ID, for example [email protected] / * / ... That showed the 3899 @
, for example [email protected]/ * /. Use the script of sip standardization? I discovered the CM have a vcs-interoperability sip standardization script to change as Interworking caller ID?
The calling party number is displayed as [email protected] / * /? You haven't configured the 'Top Level Domain organization' & 'Cluster FQDN"company setting in CUCM to match your domain name? Make sure that you configure these settings, you can use the script of VCS-interop on the SIP trunk to VCS.
-
HP Thin Client running Windows Embedded don't profile with attributes DHCP
My company has a large population of HP Thin Clients that are not attached to our AD domain and therefore cannot do dot1x because they have no certificates.
We decided to do the profiling for these devices. We present a few attributes, two of these DHCP attributes.
About 90% of our profile of thin clients, as expected, but the other 10% will refuse to work. We need to statically assign them to a group of identity to authenticate properly.
A lot of troubleshooting reduced us to query DHCP the thin client sent was not received by the strategy node. A TAC engineer looked over the config switch, IP helper address configuration and said that everything seems to be configured correctly.
The only explanation is that it seems that these specific thin clients were not finishing the DHCP process before reassigned switch the VLAN of the port. So when the dhcp request has been sent, the thin client was already in our vlan "invited" who does not dhcp to the ISE.
It's very strange, because we have so many thin clients that works properly. It's only a handful that do not. We have not been able to further refine to something specific. They are running Windows Embedded Standard 7 and a majority of them are HP t5740. I don't see Windows or HP updates available for these units and not sure if there are any registry hacks available to expedite the DHCP process.
Has anyone ever come across something similar to this?
It's pretty obvious to me, the end point isn't you get profiled before there was authenticted, which means that you do not correspond to the profiling conditions defined in rules 6 and 7, which means it will match the rule 11 (I think, having not seen your real rules). What I expected this, is that endpoint gets profiled, if ISE receives the attributes of this endpoint via dhcp e.g. forwarding help. Then, what should happen is, that it should issue a certificate of authenticity to the switch, which will lead to the passage to be re - authenticate this ending point, which now must have customization attributes you are trying to match. However if the DHCP packet never reaches ise, it won't work. That's why I think you should do a trace of package on the ise server, to see if the packets actually reach ise. If they don't you will probably need to find another way to profile, or activate dhcp for assistance on your guest virtual local network. Have you looked at the attributes of endpoint maybe after 30 seconds? They change?
-
How can I erase the active sessions and / or authenticated at a granular level?
When I visit a Web site and I authenticate either via username or certificate / States PKI, identification and authentication information is stored somewhere. I want to know where that somewhere, so I can cancel these one at a time manually.
I understand that I can go into the Options and clear browsing data - and Yes, this will accomplish the same sorta thing - however, it will kill ALL my sessions authenticated through ALL my tabs. I would like to know if there is a manual way where I can do BY the site, while it is not a such brute force method.
Last note: I don't want to close all my tabs (Firefox completely quit). Nor do I want to go through the options to do. If I can be educated to know where is my session store location and authentication, then this will answer my question.
I am an advanced user and have no problem working my way around my system to fit my needs, I don't know where to find this database store.
It is likely not possible since it is to disconnect from the secret decoder ring (CSD) and the sending of a notification to close all http and ftp sessions (net: clear active connections).
See 'sessions' in chrome://browser/content/sanitize.js
-
I am trying to create a mechanism of robust communication between a cRIO and a desktop application HMI. I tried to use the network stream I could avoid a lot of pitfalls in the management of a TCP connection. My RT code must be written to operate, and must recover gracefully network disconnections and brutal power loss. I can simulate these things quite effectively pulling the Ethernet cable or hit the button to Abort in LV
My goal of RT has a drive with the endpoint name ' commlink/drive '. My HMI has a burner with the name "commlink/recorder. HMI tries to establish the connection: he gave the Player URL ' / /
If you follow the above, I think that you are 90-95% of the way. As the article you link above mentions, there are additional considerations to take into account if you need to tolerate the application crashes / accidents of remote endpoint. In these scenearios, you basically have one of the three results of the application that always uses the end point which don't collide:
- Demand will start to return errors: In some scenarios, we can detect the remote application is crashed, abnormally terminated, or whatever. In these cases, the read/write will return an error and the same pattern described above should work.
- The flow will introduce a disconnected state and stay offline: This would generally happen with a fall in demand. In these cases, we cannot tell if the connectivity loss is due to a problem with the application or poor network conditions / remote computer. If you need to detect and recover from this scenario, you can do as a section of the link recommend you and write a timer that resets the stream network if the flow remains disconnected for a period of time. This could be incorporated in step 2 of the above state machine quite easily.
- The flow will continue to make a State connected, even if the remote application is no longer functional: This should rarely occur and would occur only when the application on the remote computer hung or an impasse, but the network computer stack is still in operational condition. In this case, we cannot differentiate between a suspended application and the other simply has all the data to send. If you need to detect and recover from this condition, the best thing to do is probably to create a second timer that resets the stream if it's too long you've changed successfully read/written all the data.
I must emphasize scenarios 2 and 3 can be greatly simplified if you care to detecting the crash & block until another application attempts to connect to the application that is still ongoing. For example, restarting the application has crashed/hung will recreate an end point and try to re-establish the connection of flow. At this point, the application which is still running will go account he communicated with endpoint remote must have crashed and raises an error. At this point, the same state machine mentioned above should be sufficient to re-establish the connection. I think that this part could be more difficult in LV 2010 since the first attempt to apply newly restarted it also throw an error when you try to reconnect to the remote application. This will occur until the endpoint in the live application was also destroyed which means that you would have to execute a loop on creating calling until she succeeded. In 2011, we changed the behavior so the call to create the newly restarted application would cause the remote application to start return errors, but now we are still trying to establish the connection on the newly restarted application for up to the timeout limit. If you use a state similar to the above machine, you should be able to reconnect without having to write a loop around the call to Create in the newly restarted application.
-
Hello world
I read so many lines and topics related to this BinaryRead I wonder how could I not make it work properly.
Shrtly I have a LXI instrument I used via TCPIP interface. The LXI instrument is called hollow driver an IVI - COM who use NI-VISA COM.
SCPI sending back answers without problem. The problem start when I need to read a block of IEEE of the VXI instrument. My driver is based on VISA-COM library and implemented a few interfaces formatted as IFormattedIO488, IMessage, but no ISerial that I don't need to use the interface series. The binary response from the instrument is: #41200ABCDABCDXXXXXXXXXX0AXXXXXXXXX which is made of 1200 bytes representing 300 float numbers.
To avoid getting the Stop 0x0A character which is part of the binary data stream, I turn off the character of endpoint using the IMessage interface and by setting TerminationCharacterEnabled = FALSE.
When I read the bit stream of the ReadIEEEBlock is always stop playback at character 0x0A anything.
I read al of the places in this forum that read binary stream properly by any instrument requires two parameters not only one that I have just mentioned.
The first, I'm able to control is on EnableTerminationCharacter to FALSE.
The NDDN is the VI_ATTR_ASRL_END_IN attribute that could be put in a pit ISerial interface only and I couldn't access this interface of my IVI - COM driver.
As we do not expect to use the interface series with our instruments of TCP/IP what other options I have to allow reading full of the binary stream of bytes, even when a 0x0A is inside.
Our IVI - COM drivers are written in C++ and use NI-VISA version is 4.4.1.
Last resort I tried to change the character of endpoints via interface IMessage for TerminationCharacter = 0 x 00 (NULL), but the ReadIEEEBlock always stops the character 0x0A?
Binary reading is performed inside the IVI - COM driver and if successful the full range of float data points is passed a potential customer request inside a SAFEARRAY * pData object passed as parameter to a public service of the IVI - COM. The problem is that I couldn't read to pass beyond hollow character 0x0A VISACOM interface.
Thank you
Sorin
Hi yytseng
Yes, I can confirm that the bug is from VXI-11 implementation on instrument LXI himself. Until binary reading all of the previous answers have been terminated by LF (0x0A) character who has the character to end on the device_write function. The VXI-11 specifications are very bad when talking about terminator on device_write then talk to the END indicator on device_read which is not necessarily the same for device_write and device_read. I talked to the guys implementing LXI instruments VXI-11 module and the two agreed to a lack of clarity about the nature of writing and reading processed stop. Ultimately our instrument for reading binary is only the form #41200ABCDABCDXXXXXX format the only character of termination to set TermCharEnabled = TRUE and TermChar = 0x0A, who could be the interface IMessage hollow of the VISACOM interface.
If the problem was not within the VISACOM, but inside the LXI, VXI instrument - 11 which has send the response of VISA as soon as detected a 0x0A byte value in the bit stream. Now after the BinaryRead change pass beyond 0x0A character but I find myself struggling to read in a ReadIEEEBlock appeal huge amount of float up to 100,000 points data, equivalent to 400,000 bytes for buffers used between instruments LXI and VISA are very small about 1 KB only.
In any case the solution to my original question was the poor implementation of the VXI-11 instrument on the treatment of device_read termination characters
Thanks for your help
Sorin
-
Web authentication Catalyst 2960
Hello
I am trying to configure Web authentication relief on a catalyst 2960 switch. The goal is to authenticate customers via web authentication that are consistent (the part of 802. 1 x works fine) not 802. 1 x and allow them access to the network. The problem is that the web authentication seems to fail.
The equipment about my question: switch catalyst 2960 (version: 122 - 37.SE) and a FreeRadius.
Here's what happens:
The authentication window will appear in my browser and the access request is sent to the RADIUS.
The term RADIUS replies with an Access-Accept. Debugging running on the switch show that all this information is coming properly authentication and switch outputs debug a 'status = PASS' and permission to debug outputs a 'status = PASS_ADD'. Despite this the browser on the client generates a message "authentication failure".
I have read the manual and the Cisco attribute value pairs are mentioned: ' priv-lvl = 15' and «proxyacl...»» ». They are required to make it work? Given that I'm not setting up any authentication switch connection via RADIUS.
Any suggestions?
Thanks in advance
Yes, they are mandatory.
If priv-lvl = 15 is not returned to the switch, the user will see? Authentication failed? and the access list will not apply. If the source in the statements of proxyacl field is not? everything? or there are other errors of syntax, the user will see? Successful authentication? but the access list will not apply and the user will be denied access to the network.
Not sure about the configuration of specific FreeRADIUS, but you need to set up the? [026\009\001] Cisco av pair VSA. It should look like:
Priv-lvl = 15
proxyacl #10 = ip permit a whole
Let me know if this lets you squared
-
Disconnection from the web browser
We have an ASA and ask users to authenticate HTTP via our ACS server. Is there a way to provide a link in the browser for the HTTP session logoff when the user finished? As it is now--when a user moves away from their PC - HTTP access is always possible with their credentials stil active - and I can't shorten the absolute or uauth inactivity on the SAA delay option. Thank you
Configure the controls "aaa authentication inside http listener" and "aaa authentication inside https listener" on the SAA. The ASA will serve a page to connect/disconnect to "http :// / netaccess/connstatus.html. Make sure you have a software version 7.2.2 or higher.
-
Hello
We always seem to have problems calling VCS VCS systems with endpoints via internet. We lack 7.2 on our VCS and remote society running 7.1 on the VCS. Calls connect ok but there are drops randomly during the session 3, session of 1 h 30. I get a busy error user (logged on TMS) when trying to reconnect and I finally pass after a few minutes by train. I checked the C20 error logs and you can find this error - can anyone explain highlights lines below? or explain why I get disconnected?
Thank you
Stem
(The appeal of VC is going through internet to the remote system)
21 Nov 07:32:41 (none) principal: 3150.48 MC I: RemoteParticipant::configureIncomingChannel: table of capacity:
21 Nov 07:32:41 (none) principal: 3150.48 i H323Call: h323_call_handler::handleH323IncMode: incoming mode
21 Nov 07:32:41 (none) principal: 3150.48 MC I: RemoteParticipant::configureIncomingChannel: table of capacity:
21 Nov 07:32:41 (none) principal: 3150.48 i H323Call: h323_call::configureIncomingChannelCnf (p = 6): don't send not openSessionCnf to receive the mode change
21 Nov 07:32:41 (none) principal: 3150.49 DataGateCfgReq (ig = 5) DATACTRL I: hdlc = yes
21 Nov 07:32:41 (none) principal: 3150.49 DataGateCfgReq (ig = 5) DATACTRL I: hdlc = yes
21 Nov 07:32:41 (none) principal: 3150.49 i H323Call: h323_call::configureIncomingChannelCnf (p = 6): don't send not openSessionCnf to receive the mode change
21 Nov 07:32:41 (none) principal: 3150.49 i H323Call: h323_call_handler::handleH323IncMode: incoming mode
21 Nov 07:32:41 (none) principal: 3150.50 MC I: RemoteParticipant::configureIncomingChannel: Capset(2) empty
21 Nov 07:32:41 (none) principal: 3150.50 i H323Call: h323_call_handler::handleH323IncMode: incoming mode
21 Nov 07:32:41 (none) principal: 3150.50 MC I: RemoteParticipant::configureIncomingChannel: Capset(2) empty
21 Nov 07:32:41 (none) principal: 3150.50 i H323Call: h323_call::configureIncomingChannelCnf (p = 6): don't send not openSessionCnf to receive the mode change
21 Nov 07:32:41 (none) principal: 3150.50 i H323Call: h323_call::configureIncomingChannelCnf (p = 6): don't send not openSessionCnf to receive the mode change
21 Nov 07:32:41 (none) principal: 3150,74 getOutputPortStatus MV::getVCSetting MediaStreamController I: initialized 1
21 Nov 07:32:41 (none) principal: 3150.74 i MediaStreamController: MV::getVCSetting localHwCookieHint_ 1 w 1920 1080 h
21 Nov 07:32:42 (no) principal: 3150.79 probe flow VIDEOCTRL-0 i: Reset for (outputvideo, 2).
21 Nov 07:32:42 (no) principal: 3150.80 i H323Call: h323_call::configureIncomingChannelCnf (p = 6): don't send not openSessionCnf to receive the mode change
21 Nov 07:32:42 (no) principal: 3151.35 I: RemoteInputGateImpl::setIncomingModeReport (ig = 60, p = 6) MC [Audio (1): aud-off stereo 0 k]
21 Nov 07:32:44 (none) principal: 3152.97 H323Call I: h323_call_handler::handleDiscInd (p = 6, s = 1) received disconnect indication (Cause: 11:55, h323 cause: 16:55)-RemoteRejected Q850
21 Nov 07:32:44 (none) principal: 3152.98 I: RemoteParticipant::reevalRefMode (p = 6, ch = 2) MC set Ref [Video (2): vid-off [email protected] / * / 0 k] q = auto, t60 = 6000
21 Nov 07:32:44 (none) principal: 3152.98 i: ModesController ModesController::resetRateLimit (ch = 2)
21 Nov 07:32:44 (none) principal: 3152.98 I: RemoteParticipant::modeChanged (p = 6, ch = 2) MC: ModesController wants to run mode: video (2): vid-off [email protected] / * / 0 k
21 Nov 07:32:44 (none) principal: 3152.99 i H323Call: h323_call::sendOutgoingModesToStack (p = 6): Modes sent to stack: audio: AAC - LD, video: vid-off, duo: vid, data: H.224 - HDLC
21 Nov 07:32:44 (none) principal: 3153.03 i H323Call: h323_call::affirmIncomingDisconnect (p = 6): incoming logout confirmed
21 Nov 07:32:44 (none) principal: call Tel: RemoteParticipant::disconnectTokenParticipant (p = 6) No. 3153,09 MC
21 Nov 07:32:44 (none) principal: 3153.09 MC I: Conference::updateCommonCapSet (c = 5)
21 Nov 07:32:44 (none) principal: 3153.10 I: IXUser iXController teardownIxChannel: not connected
21 Nov 07:32:44 (none) principal: 3153.11 MC I: CapabilityControllerImpl reduced::setCapset() = 0, waitForDuoGate = 1, hasLegacyVideo = 0
21 Nov 07:32:44 (none) principal: 3153.14 RTP I: TrafficCtrl: remove entry (hand): id: 34, dict: 65568
21 Nov 07:32:44 (none) principal: 3153.14 RTP I: TrafficCtrl: remove entry (Duet): id: 36, dict: 65568
21 Nov 07:32:44 (none) principal: 3153.15 CAMERA I: CamVisca::Ready_doCAMActionReq cameraId = 1 actionId = 20
21 Nov 07:32:44 (none) principal: 3153,16 getOutputPortStatus MV::getVCSetting MediaStreamController I: initialized 1
21 Nov 07:32:44 (none) principal: 3153.16 i MediaStreamController: MV::getVCSetting localHwCookieHint_ 1 w 1920 1080 h
21 Nov 07:32:44 (none) principal: 3153.18 i MediaStreamController: doAUDIOMIXERREMGATECNF(ms-ig=7) not found
21 Nov 07:32:44 (none) principal: 3153.19 i: DATACTRL DataGateRemReq (ig = 5)
21 Nov 07:32:44 (none) principal: 3153.20 i: DATACTRL DataGateRemReq (og = 2)
Hi Rod,
It is not easy to guide you to the first cause, why endpoint disconnects the call, with the information and the log summary above.
I recommend you open a support ticket with Cisco and also to join the journal of diagnosis (with DEBUG level) of two VCS, if possible, as well as newspapers for endpoints in the call. Then we should be able to find the cause of this problem.
Normally, the B2B calls are disconnected due to safety, for example incorrect firewall configurations or application layer, as correction active etc. H323 gateways.
It is also good to exclude scenarios; as this phenomenon happens with any point of termination? Of each location? At each location? Where registered endpoints, and firewall etc. does cross when it is a failure.
Hope this helps,
Arne
-
Hi Experts,
I installing Anyconnect point doubt:
We want to go for web-deployment of head of network device that is ISE for the assessment of posture, however I came across the document where its mentioned the installation with the three modules:
(1) VPN
(2) NAM
(3) module posture
I am only concerned to posture to check on enterprise wireless users until I have to configure all of the modules in customer provisioning?
There is no existing with Anyconnect client configuration. No ASA as n for my case. I have WLC acting as n.
so after that customer gets auth 802.1 x, customer must redirect to posture help control Anyconnect. and its new deployment where the customer is not having this agent software.
If please guide me with the right direction for Anyconnect deployment for single control of posture and how customers can get this downloaded automatically agent is my main concern.
For assessment of posture, just deploy the "Module of Posture". The "NAM" module is used only when you want to replace the native Windows supplicant. The "VPN" module is used for anyconnect VPN.
The posture can be hosted in the ISE and be put into service at the endpoints via a Client Provisioning rule. However, users must have the appropriate privilege to perform the installation of the package. In many organizations, users have NO such privileges. If this is your case, so you must deploy the Posture Module via GPO/System Center or another equivalent system.
I hope this helps!
Thank you for evaluating useful messages!
-
need for WPA2 Personal Mode CLI commands
I saw this example but I need the CLI generates the GUI. Can anyone help please?
That's what I have to do without the GUI on a 1142N 12.4 running
Configure in personal Mode
The term made personal mode refers to products that are tested to be interoperable in mode PSK only of operation for authentication. This mode requires manual configuration of a PSK on the AP and clients. PSK authenticates users via a password or code identification, both the client station and the AP. No server authentication is required. A client can access the network only if the client password matches the AP password. The password also provides the numbers that TKIP or AES uses to generate an encryption key for encrypting data packets. Personal mode is intended for SOHO environments and is not considered safe for enterprise environments. This section contains the configuration that you need to implement WPA 2 in personal mode.
/ * Style definitions * / table. MsoNormalTable {mso-style-name : « Table Normal » ; mso-tstyle-rowband-taille : 0 ; mso-tstyle-colband-taille : 0 ; mso-style-noshow:yes ; mso-style-priorité : 99 ; mso-style-qformat:yes ; mso-style-parent : » « ;" mso-rembourrage-alt : 0 à 5.4pt 0 à 5.4pt ; mso-para-marge-top : 0 ; mso-para-marge-droit : 0 ; mso-para-marge-bas : 10.0pt ; mso-para-marge-left : 0 ; ligne-hauteur : 115 % ; mso-pagination : widow-orphelin ; police-taille : 11.0pt ; famille de police : « Calibri », « sans-serif » ; mso-ascii-font-family : Calibri ; mso-ascii-theme-font : minor-latin ; mso-fareast-font-family : « Times New Roman » ; mso-fareast-theme-font : minor-fareast ; mso-hansi-font-family : Calibri ; mso-hansi-theme-font : minor-latin ;}
Hello
Here are the commands for WPA2 personal mode CLI
Configure the terminal
dot11Radio interface 0
encryption ciphers aes - ccm mode
or
encryption mode vlan ciphers aes - ccm< ---="" if="" you="" have="" multiple="">
output
dot11 ssid
open authentication
authentication-key wpa version2 management
WPA - psk ascii
Kind regards
Madhuri
-
Local VCS-E - Authentication for H323 failure
Hello
We have allowed Local DB authentication in our E - VCS and could not succeed to authenticate endpoints H323 behind the firewall. SIP devices register without problems.
Source on VCS - Local AUTH
VCS said "Request received from source not authenticated".
Under settings are pushed to the endpoint.
For example) EX60 performing TC4. X
H323 profile H323Alias ID: [email protected] / * /
H323 Profile H323Alias E164: 654321
Profile PortAllocation h323: Dynamics
H323 Profile CallSetup Mode: Gatekeeper
H.323 Gatekeeper profile address: XX. YY. ZZ. AA
H.323 profile Gatekeeper discovery: manual
H323 profile authentication LoginName: user name
H323 profile password: password
H323 profile Authentication Mode: on
Here's the application endpoint. anID VCS sends back a rejection stating the refusal of security.

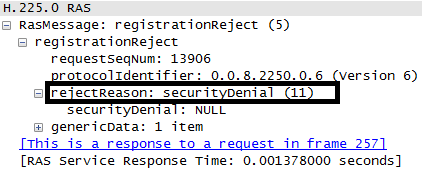
I would like to make a capture of work scenario, where I see the credentials going to VCS in the registration request.
For example) C40 TC4 running. X

and VCS confirms the request.
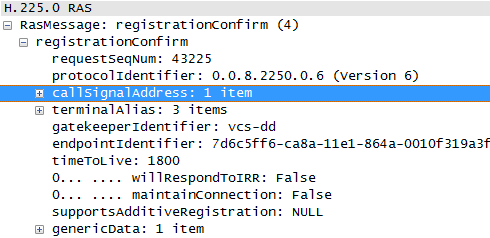
So, I want to know which prevents the end point to be authenticated.
One last thing to be noticed in the screenshot above is...
For the scenario to work the RAS has the full discovery of the true value. Whereas it is false for the other.
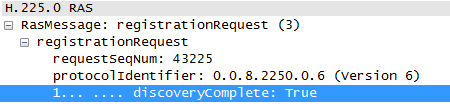
Could it be a problem of capability not shared sets properly.
Best regards / / Rio
Hi Rio,
a couple of things you can try:
S ' ensure that the endpoint has a configured NTP server
-On the verge of ending, try changing the configuration mode of appeal to 'Live' and then save again "Gatekeeper" and save again.
It should be I hope that endpoint are starting to send the RRQ with cryptographic tokens.
You could try restarting endpoint.
-Andreas
Maybe you are looking for
-
I am looking for a replacement facility for my parents in their late 60s. they previously shared a very old macbook pro (15 ", I think), who conked a few weeks ago. my mother uses it mainly for browsing the web, candy crush, email, view photos, watch
-
HI im being charged $ 11.99 per month on the Apple iTunes Store and would like to know what it is for. Thanks Berny
-
Is there a method to increase the capacity of a basic partition?
Original title: hard drive partitions are reversed - the OS is on drive H, and drive C is almost empty I did a system recovery (destrutive). I deleted a partition. C and D remain as choices on the recovery console. There are three choices. After rec
-
Lost all my icons on the desktop
Lost all my icons on the desk top and cannot get back them?
-
activate Bluetooth Message profile (access map) with Z5 compact for Audi MMI
Does anyone know if the Z5 Compact has the Protocol of card as I think to buy a Z5 to use with a new Audi A4 equipped Pack technology? My Aqua present M4 only accepts text messages to display.