For each function with a value of Concat
Hello:The scenario is, need us two elements unbounded concat and map it to an element target using for each feature.
For example
< bookStore >
< book >
Name1 < name > < / name >
author1 < author > < / author >
< ID > 1 < / BookId >
< quantity > 2 < / quantity >
< price > < price / >
< status > < / status >
< book >
< book >
name2 < name > < / name >
Author2 < author > < / author >
< ID > 2 < / BookId >
< quantity > 2 < / quantity >
< price > < price / >
< status > < / status >
< book >
< / book >
I need concat 'Name' and 'Author', which is under the element without terminals "Bookstore" and map it to a single element called "Sample" on the target side.
I am not able to use the XSLT "for-each" function to get the multiple value of the name and author, because the concat function is used. Y at - it another way to concat and get the different values of the element 'Name' and 'author '?
Concerning
RK
Maybe that's what you want...
See you soon,.
Vlad
Tags: Fusion Middleware
Similar Questions
-
count the number of targets, devices and paths by hba for each host with powercli 5.5
Hi all
I'm writing this Question again in the community, was not able to found the answer I was looking for in the nets:
https://communities.VMware.com/thread/516226?start=0 & tstart = 0
https://communities.VMware.com/thread/293531
I went through the scripts provided in the community, but seems that t not work on powercli 5.5.
///
# The target account, devices and paths for each host
Get-Cluster $cluster | Get-VMHost | Sort-Object-property name. {ForEach-Object
$VMHost = $_
$VMHost | Get-VMHostHba-type FibreChannel | Sort-Object-property device | {ForEach-Object
$VMHostHba = $_
$ScsiLun = $VMHostHba | Get-ScsiLun
If {($ScsiLun)
$ScsiLunPath = $ScsiLun | Get-ScsiLunPath | `
Where-Object {$_.} Name - like "$($VMHostHba.Device) *"} ".
$Targets = ($ScsiLunPath |) »
Group-object - property SanID | Measure - Object). County
$Devices = ($ScsiLun |) Measure - Object). County
$Paths = ($ScsiLunPath |) Measure - Object). County
}
Else {}
$Targets = 0
$Devices = 0
$Paths = 0
}
$Report = "" | Select-Object - property VMHost, HBA, target devices, paths
$Report.VMHost = $VMHost.Name
$Report.HBA = $VMHostHba.Device
$Report.Targets = $Targets
$Report.Devices = $Devices
$Report.Paths = $Paths
$Report
}
}
///
I went through the script LucD posted below: but it's not exactly what I'm looking for.
LucD : can you please change the same for me please. to count the number of paths per hba for each host with powercli 5.5, devices and targets.
//
$esx = get-VMHost < host name >
foreach ($hba to (VMHostHba Get - VMHost $esx - type "FibreChannel")) {}
$target = ((get - see $hba. VMhost). Config.StorageDevice.ScsiTopology.Adapter | where {$_.} Adapter - eq $hba. Key}). Goal
$luns = get-ScsiLun - Hba $hba - LunType 'disk '.
$nrPaths = ($target | % {$_.}) Lun.Count} | Measure - Object - sum). Sum
Write-Host $hba. Device ' target: ' $target. County "devices:" $luns. County ' path: ' $nrPaths
}
//
I'll be grateful for any help.
Tarun Gupta
Try something like this
{foreach ($esx in Get-VMHost)
foreach ($hba to (VMHostHba Get - VMHost $esx - type "FibreChannel")) {}
$target = ((get - see $hba. VMhost). Config.StorageDevice.ScsiTopology.Adapter | where {$_.} Adapter - eq $hba. Key}). Goal
$luns = get-ScsiLun - Hba $hba - LunType "disk" - ErrorAction SilentlyContinue
$nrPaths = ($target | % {$_.}) Lun.Count} | Measure - Object - sum). Sum
$props [ordered] = @ {}
VMHost = $esx.name
HBA = $hba. Name
Target = $target. County
Device = $luns. County
Path = $nrPaths
}
New-object PSObject-property $props
}
}
-
Check for multiple users with the value of the UID 0
Hi gurus,
The runclufvy.sh gives the warning below can I ignore this or need to fix for the installation of the 11202 RAC on RHEL 5?
Check for multiple users with the value of the UID 0
PRVF-4132: several users 'root, jnftsi0' with '0' the UID exists on "hwvpa6".
PRVF-4132: several users 'root, jnftsi0' with '0' the UID exists on "hwvpa2".
Thank youHello
The runclufvy.sh gives the warning below can I ignore this or need to fix for the installation of the 11202 RAC on RHEL 5?
Check for multiple users with the value of the UID 0
PRVF-4132: several users 'root, jnftsi0' with '0' the UID exists on "hwvpa6".
PRVF-4132: several users 'root, jnftsi0' with '0' the UID exists on "hwvpa2".User jnftsi0 cannot be used by the Oracle Installer or start the Oracle process, because what is the root group.
If the user jnftsi0 is used by Oracle install or start Oracle process should then be removed from the root group, otherwise you can ignore it.
Kind regards
Levi pereira -
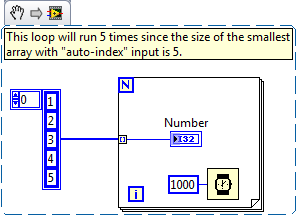
For loop runs with the value of N unwired
In this case will be a loop run connected to the loop N worthless? I have seen a few examples of the loop for run without a certain number of times set to be ran wired or for example a size of table or something like that.
PauldePaor wrote:
Here's a program I am and as you can see the image that the program runs without the loop N being wired. The program will run without problem
As everyone else has said, you don't have to plug something on N. If you wire up a table for loop for input "auto-index", the loop for will run automatically the smaller table size.
Perhaps an example will help:
This makes a loop on my table size (in this case, long of 5 elements). On the edge of the loop for which resembles [] brackets, indicates that it is auto-indexé. The loop should go through each item one at a time (1, then 2, then 3, then 4, then 5).
-
HELP for the string with the value of waste
Here, I have attached front and block diagrm and vi. Problem is im get required string displayed and with it, some is not required to chain appears also. Help me edit.
NOTE: If number: corresponds to 90610003 must be obtained. But in my code im getting
90610003
VLPN: KA - 01 I-2000
Dest ID: 100
Top speed: 15
Admin1: 9538991097
Admin2: 9538991096
Admin3: 9880899964 (NOT NECESSARY a "BOLD")Here is the text of program where I searched for string
IRU details.txt
Number: 90610003
VLPN: KA - 01 I-2000
Dest ID: 100
Top speed: 15
Admin1: 9538991097
Admin2: 9538991096
Admin3: 9880899964Note: It is also possible that you will get a \n (newline) or a \r\n (CRLF), but since you did not save the actual data you VI, I can't be sure.

-
LOV property for the 'return' with pragmatic value
Hi gurus,
I use
Forms [64 Bit] Version 11.1.2.2.0 (Production)
Database Oracle 12 c Enterprise Edition Release 12.1.0.2.0 - 64 bit Production
With the options of partitioning, OLAP, advanced analytics and Real Application Testing
How can I set property LOV to return the value of a column with pragmatism.

We're going on the basis of a State, I want Field2 value in any other column we will say that it is Control.attribute3
Dear Sir
You cannot change the name of checking back to a LOV. Instead, you can return the value of a dummy control, and then you can assign the value to different controls depending on the condition.
I hope this helps.
Manu.
-
Hello
I was wondering if I could get some information and opinions on the use of an array of type defined clusters to store configuration data. I am creating a program to test several EHR and wanted to have a control of type defined for each HAD with the information needed to create the DAQmx tasks for all signals for it must HAVE. I am eager to do so that the data are encoded in hard and not in a file that the user might spoil.
Controls of type def are then put into a Subvi who chooses as appropriate, one based on the enumeration of Type DUT connected to a case structure.
I have problems with the control of the defined type. I see issues when you try to save a configuration unique to each element of the array in the array of clusters. Somehow, it worked at first, but now by clicking on "Operations on the data--> default font of the current value ' on individual elements of the cluster or the entire cluster (array element) does not save data when I re - open the command def. What I am doing wrong? I'm trying to do something with the berries of the clusters that I shouldn't do?
I enclose one of the defined reference type controls. I tried to change it bare to see if that helped, but no luck.
To reproduce, change the resource string for the element 0 of the array and do the new value by default. Then close the def of type, and then reopen it. The old value is always present in this element. The VI is saved in LabVIEW 2012.
The values of a typedef are not proprigated to the instances of the control. They get if created WHEN data values have changed. They will be not updated with the changes to come. You must create a VI specifically to hardcode your values or to implement a file based initialization. The base file would be much better and more flexible. If you don't want users to change the data simply encryption. There is a wedding blowfish library that you can download.
-
Export PNG with the correct name, for each layer, script file frame foreach
Hello guys,.
I am trying to find a script that exports each separately from the layer in PNG, for each image, with the correct name. By example, if the layer is named snail and lies in a forest of group name and is like 6, export this layer as a PNG named forest.snail.06.png (recursion if possible) and this for each layer, for each image...
I found a software named Layerex, they speak here about layers export Flash | Global Facilitation network
But I could not find... If you guys know how to do, it would be so awesome...
Take care
Simon
Using jsfl.
-
TestStand blocks by "for each" loop
TestStand crashes from time to time for unknown reasons. We believe that 'foreach' loops could be the reason. By replacing the "for each" loop with a loop and iterate using the index, the problem is solved.
Is this a known problem in Teststand? Is it possible that this is resolved in Teststand 4.1 (we use 4.0.1)?
Kind regards
Jeroen Coulembier
This looks exactly like a previous problem (98902) report, which has been fixed in 4.1.
-
printer supported for XP sp3 with 32-bit
Have a laptop with XP Pro 32 bit SP3. In the search for printers many users said that they had problems with all the functions on HP, epson printers. You want to get an all in one printer wireless fax, prints, copies and scans which is supported by XP pro I on the laptop. Confused by the comments of the users and the lack of info online. If these comments are exaggerated or is there a printer in landscape of Home/office that works for all functions with fear?
first of all, if your laptop has xp on it, then it is likely, it can support wireless printing. Instead, wireless connectivity you have is dedicated to internetting.
but it does not mean that you can not buy a wireless print server to use for a wireless printer. but my recommendation is to avoid this high-tech stuff at the moment because you will incur costs and headaches.
Instead, you should be able to take advantage of the technology of usb hub. so, instead of buying a wireless print server, buy a usb hub. and instead of being fascinated with a wireless printer, opt for the usb printer.
regarding the printers are compatiable for what operating system? generally, all the boxes are clearly marked with the operating system, with which the printer is compatiable.
However, because you do due diligence, copy down the model number of the printer you are interested with and do a final check to their homesite. Then look on the homesite in the "downloads" section to see if the model has drivers and updates for xp.
also, you can do an internet search to find previous discussions and or questions about templates and and you can even post a follow-up question on this forum to check our recommendations.
Since you are interested in a landscape of Home/office of the derivation of printers color and go directly to a laser printer. in my personal experience, hp should be top of the list.
laser printing is the enterprise standard and cartridges laser last a good long time compared to cartridges color cheese and very expensive. In addition, buy a separate scanner and a separate fax machine. These three components are much better than an all in one device.
Finally, if you need color printing, then it is cheaper to get your color photos, prints by Wal-Mart online than using paper photo at home and expensive color cartridges.
DB·´¯'·.. ¸ >-))) º > ·´¯'·.. ¸ >-))) º > share nirvana mann
-
The FRA diskgroup separate for each prod database?
Hello
Env: Oracle 11 g 2 EE (11.2.0.3), 6.2 RHEL 64 bit
Storage: file system
Databses: ten databases on the PROD and 20 on the DEV
I have two existing servers with above configuration - a DEV and a single PROD. I have to move all of the databases from two servers to new servers.
I have two options. Configure the servers again exactly the same way (same software oracle, same mounts-points, directory structures, etc.) and move/copy the databases above. The other option is to use ASM for storage instead of file system.
Customer asks a diskgroup FRA separate for each DBA database. His reason is that if the FRA gets filled by archivelogs because of some process in the databases, all databases stops responding.
- It's a legitimate concern and what is the best way to deal with this kind of situation?
- Should I create a diskgroup FRA separate for each database?
The archivelogs are backed up every 20 minutes for each PROD database.
Please advise!
Best regards
You can limit FRA for each database with the parameter DB_RECOVERY_FILE_DEST_SIZE.
-
LINES in COLUMNS with different values for each column (after division)
Hello
I have a table called summary where I produced, month, value,.
When I used select * tab, I get months jan, Feb, mar, Apr. I wrote a query to get the months(jan,feb,...) columns
SELECTmax (DECODE(ROWNUM,1,month)) Column1
+ Max (decode(rowNum,2,month)) table Column2 +.
as this up to 12 months
After that, I want to get the NEWVALUE for each month.
I wrote a query to get the value, but I get the value only for the first month, and for the rest, I get NULL values.
Select max (DECODE(ROWNUM,2,vallue)) Column1, Column2 of max table (DECODE(ROWNUM,3,vallue))
Is it possible to get the newvalues for each month (in sql only) if so, please help me
Thank you
Chand
-
How to find the value max and min for each column in a table 2d?
How to find the value max and min for each column in a table 2d?
For example, in the table max/min for the first three columns would be 45/23, 14/10, 80/67.
Thank you
Chuck,
With color on your bars, you should have enough experience to understand this.

You're a loop in the table already. Now you just need a function like table Max and min. loop. And you may need to transpose the table 2D.
-
Cumulative total for each day - how to deal with nulls
I'm on 11.2.0.3. I want to write a query to calculate a running total of the incidents a day - this request will be used for an APEX line chart.
Sample table and data:create table sales ( id number primary key, time_of_sale date, item varchar2(20)); insert into sales values (1, to_date('02-JAN-2013','DD-MON-YYYY'), 'book'); insert into sales values (2, to_date('03-JAN-2013','DD-MON-YYYY'), 'candle'); insert into sales values (3, to_date('05-JAN-2013','DD-MON-YYYY'), 'bicycle'); insert into sales values (4, to_date('05-JAN-2013','DD-MON-YYYY'), 'football'); insert into sales values (5, to_date('07-JAN-2013','DD-MON-YYYY'), 'football'); insert into sales values (6, to_date('10-JAN-2013','DD-MON-YYYY'), 'elephant'); insert into sales values (7, to_date('10-JAN-2013','DD-MON-YYYY'), 'turtle'); insert into sales values (8, to_date('10-JAN-2013','DD-MON-YYYY'), 'book'); insert into sales values (9, to_date('10-JAN-2013','DD-MON-YYYY'), 'candle'); insert into sales values (10, to_date('10-JAN-2013','DD-MON-YYYY'), 'bicycle'); commit;For each of the days between 1 January and 10 Jan I want to get the total functioning of the number of sales.
So the output l would like is:
DAY ITEMS_PER_DAY
--------- -------------
1ST JANUARY 13 0
JANUARY 2, 13 1
JANUARY 3, 13 2
JANUARY 4, 13 2
5 JANUARY 13 4
JANUARY 6, 13 4
JANUARY 7, 13 5
JANUARY 8, 13 5
JANUARY 9, 13 5
10 JANUARY 13 10
So even if there is no sale on January 4, we show the total of the previous day.
If I can create a series of dates using the:
select trunc((to_date('01-JAN-2013','DD-MON-YYYY')-1) + rownum) day from dual connect by rownum <= 10And I can't the cumulative aid total:
select trunc(time_of_sale) as day, sum(count(*)) over (order by trunc(time_of_sale)) as items_per_day from sales group by trunc(time_of_sale)
Overall, it gives me:
SQL > select
2 a.day as the day,
3 b.items_per_day
4 of
5 (select trunc((to_date('01-JAN-2013','DD-MON-YYYY')-1) + rownum) as day
6 double
7 plug by rownum < = 10).
8 (select trunc (time_of_sale) day, sum (count (*)) (trunc (time_of_sale) order) as items_per_day
9 sales
10 group by trunc (time_of_sale)) b
11 where a.day = b.day [+] - replace by parentheses to avoid the formatting of the forum
12 order by a.day
13.
DAY ITEMS_PER_DAY
--------- -------------
1st January 13 null
JANUARY 2, 13 1
JANUARY 3, 13 2
Value null 4 January 13
5 JANUARY 13 4
Value null January 6, 13
JANUARY 7, 13 5
Value null January 8, 13
Value null January 9, 13
10 JANUARY 13 10
It's not exactly what I'm looking for. I played a bit with a lag, but had no success.
Any ideas?
Thank you
John
Hi, John,.
You want to do the SUM after the outer join, like this:
WITH days_wanted AS
(
SELECT TO_DATE (January 1, 2013 ', 'DD-MON-YYYY') + ROWNUM - 1 day YOU
OF the double
CONNECT BY ROWNUM<=>
)
SELECT d.day
SUM (COUNT (s.id)) OVER (ORDER BY d.day) AS items_to_date
OF days_wanted d
S sale LEFT OUTER JOIN ON TRUNC (s.time_of_sale) = d.day
GROUP BY d.day
ORDER BY d.day
;
Note that we must use COUNT (s.id) instead of COUNT (*) here, because, given that it is evaluated once the outer join, COUNT (*) would be taken into account less than $ 1 a day, because the outer join ensures there will be at least 1 row in the game for each row in days_wanted, whether or not it matches anything in sales.
It wouldn't work using the old join syntax, too, but I suggest to use the ANSI syntax, especially for outer joins. It reduces the amount and the complexity of the coding, and which allows to reduce the number of errors. (Also, it avoids the problem of the display of this site.)
-
How to reset the value of line number for each header
Hi all
I need to reset the line number for each header values.
create table header_table (header_value varchar2 (100));
create table line_table (header_value varchar2 (100), number line_number);
insert into header_table values ('ALAOF');
insert into header_table values ('ALAOO');
insert into line_table values('ALAOF',1);
insert into line_table values('ALAOF',2);
insert into line_table values('ALAOF',3);
insert into line_table values('ALAOF',4);
insert into line_table values('ALAOF',5);
insert into line_table values('ALAOO,6);
insert into line_table values('ALAOFO,7);
insert into line_table values('ALAOO',8);
insert into line_table values('ALAOO',9);
insert into line_table values('ALAOO',10);
insert into line_table values('ALAOO',11);
insert into line_table values('ALAOO',12);
Commit;
TABLE HEADER_:
header value
ALAOF
TRECYBEL
LINE TABLE:
header value line_number
ALAOF 1
ALAOF 2
ALAOF 3
ALAOF 4
ALAOF 5
TRECYBEL 6
TRECYBEL 7
TRECYBEL 8
TRECYBEL 9
TRECYBEL 10
TRECYBEL 11
TRECYBEL 12
But looks like I got out of line below table
LINE TABLE:
header value line_number
ALAOF 1
ALAOF 2
ALAOF 3
ALAOF 4
ALAOF 5
TRECYBEL 1 <-reset the beginning of line number with 1 with different header value
TRECYBEL 2
TRECYBEL 3
TRECYBEL 4
TRECYBEL 5
TRECYBEL 6
TRECYBEL 7
Please help me on this.
Thanks in advance.
Hello
It makes no sense to do it in PL/SQL when you can do it with SQL.
SQL is generally more efficient than PLSQL.
And can you explain why you don't want to use analytical functions?
This will update your table using a MERGE statement and an analytic function:
MERGE INTO line_table lt USING ( SELECT ROWID rid, header_value, row_number() OVER(PARTITION BY header_value ORDER BY ROWNUM) rn FROM line_table ) src ON (src.rid=lt.ROWID) WHEN MATCHED THEN UPDATE SET lt.line_number = src.rn;The result is less to:
HEADER_VAL LINE_NUMBER
---------- -----------
ALAOF 1
ALAOF 2
ALAOF 3
ALAOF 4
ALAOF 5
TRECYBEL 1
TRECYBEL 2
TRECYBEL 3
TRECYBEL 4
TRECYBEL 5
TRECYBEL 6
TRECYBEL 7
Kind regards.
Al

Maybe you are looking for
-
It is a relatively new problem. All the videos, if new castings, friends or U tube show nothing but a black screen is empty. I even took it to a repair shop. I can see everything on IE. I'm not particularly computer literate and I'm much more comfort
-
I bought my laptop Equium P200 on 18 months ago and updated upgraded the memory from 1 GB to 2 GB. Since just after Christmas, the performance of the machine has been terrible. It takes an age to start, is almost as if she gets to sleep when I try to
-
My computer has entered a view type safe mode?
I turned off my computer last night and it was fine and running windows 7 and could easily and quickly connect to the internet, however, I came home today about 20 hours later and I loaded my computer and I typed my password and it loaded to upward i
-
Why my got OEM Windows 7 windows isn't genuine watermark?
-
Printer HP 1120C range is listed as compatible with Windows 7, but impossible to install the driver
I have an old HP1120C printer. HP lists as compatible, and refers to the Microsoft site. List of Microsoft confirms that the printer is compatible and no new drivers are needed. I try to load the driver and Windows 7 says that the driver is not compa