Poor Oracle Performance consistency running concurrent queries
We have 600 million records in the cache must be retrieved on queries (filter or Multi Extractor, we tried both), but we are faced with poor performance when we increase concurrency, we use 5 son of job by node Manager representing a total of 300 sons, we are not able to get a rate higher than 400 records/s (that is, each node consistency to recover 6 records/s) It would take too long (nearly 20 days) to 600 M of process records. This means that consistent performance are poor until the database.
The improvements that we tried:
We have created the index (index simple and compound), implemented from POF, tunned shuts down the JVM to reduce the GC, configured network communication (doesn't any sense cause we run everything on the same machine, but we tried), increased coherence nets, implemented best practices and after all, we tried to run on Exalogic , and after all, we had the same problem.
The material on our tests, we used:
-Dell R910 with 1 TB of Ram and 80 processors;
-Oracle Exalogic X 3.
Each node consistency is using 16 GB of Ram, and we use a distributed Cache.
Before dropping out of coherence I would like to know if there is something more, we can try.
We opened the SR and after many tests, that we abandoned consistency, we changed the technology, and now the Solution works well. We understood that the consistency is just for the cache and not for intensive query.
Tags: Fusion Middleware
Similar Questions
-
Problems running SPARQL queries with Jena Oracle adapter
Hello
I am trying to run SPARQL queries using the adapter of Jena.
I use Jena 2.6.0 and all concerned pots (granules and ojdbc5) and running on Oracle 11 g 1 material.
I'm under theexample code provided with the adapter Jena:
' public void testOrderBy (String jdbcUrl, String user,
String password, String modelName,
PrintStream psOut)
throws SQLException, IOException
{
Oracle Oracle = new Oracle (jdbcUrl, user, password);
Chart GraphOracleSem = new GraphOracleSem (oracle, modelName);
Model ModelOracleSem = new ModelOracleSem (graph);
Void node = Node.createURI ("http://sub/a3");
Pred node = Node.createURI ("http://pred/p1-a3");
Node obj = Node.createLiteral("8888");
Graph.Add (Triple.create (pred, sub, obj));
void = Node.createURI ("http://sub/a2");
PRED = Node.createURI ("http://pred/p2-a2");
Graph.Add (Triple.create (pred, sub, obj));
void = Node.createURI ("http://sub/a4");
PRED = Node.createURI ("http://pred/p3-a4");
Graph.Add (Triple.create (pred, sub, obj));
Dim queryString As String = "SELECT? s? p? o"
+ "WHERE {?}" s? p? o.}"
+ "ORDER BY? s « ;
psOut.println ("testOrderBy: question 1");
runQuery (QueryFactory.create (queryString), model, psOut);
String queryString2 = "SELECT? s? p? o"
+ "WHERE {?}" s? p? o.}"
+ "ORDER BY DESC (?) p) « ;
psOut.println ("testOrderBy: request 2");
runQuery (QueryFactory.create (queryString2), model, psOut);
Graph.Close ();
Oracle.Dispose ();
}
I'm getting the following exception:
Exception in thread "main" java.lang.NoSuchMethodError: com.hp.hpl.jena.graph.query.Query.getTriples () mCol/hp/hpl/jena/graph/query/NamedTripleBunches;
at oracle.spatial.rdf.client.jena.OracleSemQueryPlan.getStatements(OracleSemQueryPlan.java:363)
at oracle.spatial.rdf.client.jena.OracleSemQueryPlan.executeBindings(OracleSemQueryPlan.java:182)
to com.hp.hpl.jena.sparql.engine.iterator.QueryIterBlockTriplesQH$ StagePattern. < init > (QueryIterBlockTriplesQH.java:90)
at com.hp.hpl.jena.sparql.engine.iterator.QueryIterBlockTriplesQH.nextStage(QueryIterBlockTriplesQH.java:56)
at com.hp.hpl.jena.sparql.engine.iterator.QueryIterRepeatApply.makeNextStage(QueryIterRepeatApply.java:87)
at com.hp.hpl.jena.sparql.engine.iterator.QueryIterRepeatApply.hasNextBinding(QueryIterRepeatApply.java:49)
at com.hp.hpl.jena.sparql.engine.iterator.QueryIteratorBase.hasNext(QueryIteratorBase.java:71)
at com.hp.hpl.jena.sparql.engine.iterator.QueryIterSort.sort(QueryIterSort.java:44)
to com.hp.hpl.jena.sparql.engine.iterator.QueryIterSort. < init > (QueryIterSort.java:36)
to com.hp.hpl.jena.sparql.engine.iterator.QueryIterSort. < init > (QueryIterSort.java:31)
at com.hp.hpl.jena.sparql.engine.main.OpCompiler.compile(OpCompiler.java:292)
at com.hp.hpl.jena.sparql.engine.main.CompilerDispatch.visit(CompilerDispatch.java:142)
at com.hp.hpl.jena.sparql.algebra.op.OpOrder.visit(OpOrder.java:28)
at com.hp.hpl.jena.sparql.engine.main.CompilerDispatch.compile(CompilerDispatch.java:33)
at com.hp.hpl.jena.sparql.engine.main.OpCompiler.compileOp(OpCompiler.java:71)
at com.hp.hpl.jena.sparql.engine.main.OpCompiler.compile(OpCompiler.java:298)
at com.hp.hpl.jena.sparql.engine.main.CompilerDispatch.visit(CompilerDispatch.java:149)
at com.hp.hpl.jena.sparql.algebra.op.OpProject.visit(OpProject.java:47)
at com.hp.hpl.jena.sparql.engine.main.CompilerDispatch.compile(CompilerDispatch.java:33)
at com.hp.hpl.jena.sparql.engine.main.OpCompiler.compileOp(OpCompiler.java:71)
at com.hp.hpl.jena.sparql.engine.main.OpCompiler.compile(OpCompiler.java:49)
at com.hp.hpl.jena.sparql.engine.main.QueryEngineMain.eval(QueryEngineMain.java:43)
at com.hp.hpl.jena.sparql.engine.QueryEngineBase.createPlan(QueryEngineBase.java:81)
at com.hp.hpl.jena.sparql.engine.QueryEngineBase.getPlan(QueryEngineBase.java:70)
to com.hp.hpl.jena.sparql.engine.main.QueryEngineMain$ 1.create(QueryEngineMain.java:59)
at com.hp.hpl.jena.sparql.engine.QueryExecutionBase.getPlan(QueryExecutionBase.java:262)
at com.hp.hpl.jena.sparql.engine.QueryExecutionBase.startQueryIterator(QueryExecutionBase.java:239)
at com.hp.hpl.jena.sparql.engine.QueryExecutionBase.execResultSet(QueryExecutionBase.java:244)
at com.hp.hpl.jena.sparql.engine.QueryExecutionBase.execSelect(QueryExecutionBase.java:77)
in the example. Examples.runQuery (Examples.java:1748)
in the example. Examples.testOrderBy (Examples.java:1035)
in the example. Test.main (test.) Java:23)
Someone has an idea what is the problem? Am I guilty of?
Doron,There was some interface with Jena itself changes.
As a result, the Oracle Jena 2.0 adapter does not work with Jena 2.5.7 or Jena 2.6.0. Please try 2.5.6.
We are working on a new version of the adapter of Jena and this restriction has been lifted.See you soon,.
Zhe Wu
-
Hello
There are several versions Oracle has removed the requirement of performance and tuning in what concerns OCP.
You can get a separate ECO - Oracle Certified Expert for the performance and tuning.
However, databases there include performance and tuning in the basic DBA certification.
I understand there is an OCP (for DBA) and a separate OCÉ (performance and tuning),
but could it be considered as an additional symbol combining the OCP and OCE (such as OCP * or OCPE or OCP2).
We could always get and OCP for DBA and a separate ECA for the performance and tuning.
If there was an an additional symbol, then maybe selftest software would also create reviews of preparation for the performance and tuning.
Perhaps more people write books on their performance and tuning of certification.
Maybe Oracle would provide Web seminar Exam Prep for the performance and tuning.
Thank you Roger
If there was an an additional symbol, then maybe selftest software would also create reviews of preparation for the performance and tuning.
Perhaps more people write books on their performance and tuning of certification.
That hangs high hopes on a couple of letters. The problem, however, is not perception, but the economy. Traditional publishers must sell a lot of books to make return on investment in the costs of creating a new. Until they beat X-thousand books, they are in the red. STS and transcend do not have publication costs, but they still have to pay someone (probably a very expensive one) to go through the mind-numbing task of creating a bunch of questions / answers that are enough like the real exam to be useful, but different enough to not be do not cheat. They should sell enough copies of the review of the practice of paying for that person, and then more overhead before making a profit.
The main reason that I was able to create guides to study at the best prices is because they are printed on demand. I don't have to recover the costs of printing a large number of copies in the hope they will sell. In addition, as I do all of the writing to editing to marketing of myself - it has no salaries to pay someone else. Despite this - I could easily do more initial money by running Oracle contract/work councils for the same number of hours that I put in my books and practice tests. I was called to joke with my wife I could do more by night shifts working underground, asking people if they want fries with that.
The problem with an author or an editor of creating a book especially for an Oracle performance certification (say 1Z0-064 or 1Z0-117), is that there is so much work involved in this than the creation of a book of generic performance Oracle or Oracle SQL Tuning book, but the very act of this direct to the test severely limits the people who can buy it. Those who study for 1Z0 - 064 could well but a generic performance Oracle 12 c book. However, people in the market for a book of performance 12 c but * not * intended to take certification 064 are not likely to buy this book even though she 1Z0 - 064 on the lid.
There are not many hug of people with the knowledge and the ability to create these materials. This relatively small pool, it is there not much with the desire to do. This further reduced pool, there not much time for her - or at least of time they are willing to take more lucrative projects requiring their skills.
-
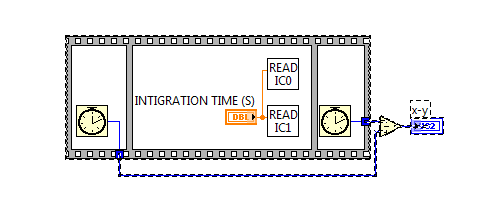
two loop running concurrently, but double length
Hi guys,.
I try to read at the same time both ion Chamber. IC0 IC1 reading and reading have a loop of each.
These two Subvi can run concurrently, but by the time the cost doubled again.
Why?
Thank you very much!
Hi guys,.
Thanks for your reply.
I found the problem. I put the delay between write and read the com see the following figure. The timer was implemented with Resp.vi of IC101. After I moved out, my code can work well.
It's the job
-
* Original title: TO RUN FASTER, IN PERFORMANCE OPTIONS
in the properties of systems, performance parameters, run FASTER, the OPTIONS of PERFORMANCE IN == ADVANCE = run FASTER, * it TOLD me TO DISABLE SOME SETTINGS, could you TELL ME WHAT SETTINGS I CAN UNCHECK.
When and where your computer is slow? Is the time required to start-up or after the reboot is complete? Browse the internet or work on files offline?
Select Start, run, type msconfigand press the ENTER key or click on the Startup tab. You will see a window like the image below. What elements are there?
In Windows 7, use Ctrl + Shift + Esc instead of Ctrl + Alt + Delete. It lets you in the Manager of tasks more quickly. Select Task Manager, performance, resource monitor tab and tab memory. What are the numbers for reserved equipment, in use, modification, sleep and free?
Is your Windows 7 32-bit or 64-bit? The amount of RAM is installed?
THE IMPACT OF THE COMPUTER ON THE PERFORMANCE SPECIFICATION
http://www.gerryscomputertips.co.UK/performance1.htm -
Oracle performance management system
Hi all
Can someone help me on the implementation, the scope and assumptions about the Oracle performance management system?
Hello
If you want to learn the whole thing... go to this URL for R12.
http://docs.Oracle.com/CD/B34956_01/current/HTML/docset.ht..findml
Human resources, search for pl
"Oracle HRMS effective Sourcing, deployment, and Talent Management Guide.
with doc not. B31620-02.
You can go through the talent management (which is up to 11i Performance management system).
Is it to 11i... Click on the following link.
http://docs.Oracle.com/CD/B25284_01/current/HTML/docset.html
The study guide thoroughly and then ask specific questions.
Kind regards
Siva -
Intel SRCS16 on ESX4 - poor write performance
Hello world!
I need to change HD on one of my ESX hosts that have only 250 GB of total space, while we buy 5 HD 1 TB.
This weekend, I put another control (Intel SRCS16) Raid and connect a 1 TB just to copy a VM of old HD to the new.
Matrix Raid took less than 1 min.
Creation of partition on the raid drive took less than 1 min. (with fdisk)
Partition formatting took more than 3 hours (with mkfs.ext3)
Test write performance with: time dd if = / dev/zero of=/mnt/share/test.test bs = 1 M count = 1024
And took approximately 18 min. (1 Mb/s)
Research on google, I find some useful links.
On the Vmware communities, I found this: http://communities.VMware.com/thread/105552?start=0 & tstart = 0
But it does not work.
Someone has an idea?
Thanks for your help
SRCS16 Intel has some extremely poor write performance without cache enabled writable. For normal operations with write cache, you should have BBWC (battery backup). Enabling write without BBWC cache may lead to the loss of data in case of power failure.
UPD. See http://www.intel.com/support/motherboards/server/srcs16/sb/cs-020502.htm.
-
script to run several queries to find/replace
Working on a big book of ID document (* .indb), I saved dozens of queries to search/replace (named "col01', 'col02' etc.) that I run on 'all documents '. For some reason, I have to run these queries several times a day.
So I'm wondering if he has, or if someone out there will write: a script that runs these queries one after another. Given the size of the book, it may be necessary to provide the script to pause after each query (before it turns on with the next), but I'm just guessing.
Any help is very appreciated!
- Pre-installed FindChangeByList script (in the folder "Scripts Panel > Samples")
- Script to change by queries to find
- Multi-find/change script (commercial)
-
Hi all
Can someone give me a good article explaining oracle performance, given gurd, rman and RAC.
Although I worked on this subjects I am unable to answer a question in interview as
How do you analyze your database? / How give you your DB... etc.
First response would be appreciated.
Thank you.
Kind regards
Rajini.Hi me;
Please also check Learning Library for your documents need question
http://Apex.Oracle.com/pls/Apex/f?p=44785:2:0:2:P2_GROUP_ID:1000Respect of
HELIOS -
Oracle instance is running but sqlplus "virtue sysdba" says connected to idle.
Hello
Oracle RAC is running (started the CARS with "srvctl start database hacmp - d") but when I am trying to connect to the database using sqlplus 'virtue sysdba' he says 'connected to an idle instance.
No idea what could be the problem here?
I have exported ORACLE_SID.
bash-3. $00 ps - ef | grep pmon
Oracle 507946 798870 0 17:23:42 pts/0 0:00 grep pmon
Oracle 872584 1 0 17:03:16 - 0:00 ora_pmon_hacmp1
bash-3. $00 echo $ORACLE_HOME
/ u01/app/oracle /.
bash-3. $ 00
bash-3. $00 echo $ORACLE_SID
hacmp1
bash-3. $ 00
bash-3. $ 00
bash-3. $00 sqlplus "virtue sysdba".
SQL * more: Release 10.2.0.4.0 - Production on Mon Sep 14 17:24:43 2009
Copyright (c) 1982, 2007, Oracle. All rights reserved.
Connect to an instance is idle.
SQLTry to remove the ending ' / ' the ORACLE_HOME environment variable.
-
Problem with Oracle performance
Hi all
I use Oracle database 11 g 2.
I am facing a problem with one of my queries.
Scenario is:
I associate myself with 3 tables.
The engine is saa_hist.saa_rep_product_activity (70 million lines).
The second table is scmsa_hist.scmsa_sub_feature_trueup (900 million lines).
The third table is saa_hist.saa_rep_subscriber_activity (35 million lines).
The output of the query will be only about 120K.
I'm majoriy of the columns in the first table. On the other hand, we get 2 columns and in table 3, we get a single column.
When I join all 3 tables as it appears in the query runs for 6 hours. (The
SELECT / * + PARALLEL_INDEX(R,SAA_REP_PRODUCT_ACTIVITY_BI,12)
PARALLEL(SUB,24)
PARALLEL_INDEX(RR,SAA_REP_SUBSCRIBER_ACTIVITY_I1,8)
*/
R.*, sub.mrc, sub. RATEPLANCODE, rr.measure_group_id
Saa_hist.saa_rep_product_activity r
JOIN scmsa_hist.scmsa_sub_feature_trueup sub
ON sub.job_log_id = r.job_log_id
AND sub.service_number = r.msisdn
AND sub.ban = r.account_number
AND sub.soc_code = r.product_id_code
LEFT OUTER JOIN saa_hist.saa_rep_subscriber_activity rr
ON rr.quantity = 1
AND rr.service_universal_id = r.service_universal_id
AND rr.msisdn = r.msisdn
AND rr.account_number = r.account_number
WHERE r.billing_subsystem_id = 1
AND 1 = 1
AND r.batch_key BETWEEN 674 AND 675;
The explain command plan looks good for this one and the cost is also okay(222K). I don't see any S-> data flow in the Section of IN-OUT of the explain plan P.
-----------------------------------------------------------------------------------------------------------------
| ID | Operation | Name | TQ | IN-OUT | PQ Distrib.
-----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT |
| 1. COORDINATOR PX |
| 2. PX SEND QC (RANDOM). : TQ10001 | Q1, 01 | P > S | QC (RAND) |
| 3. NESTED EXTERNAL LOOPS | Q1, 01 | SVCP |
| 4. HASH JOIN | Q1, 01 | SVCP |
| 5. JOIN FILTER PART CREATE | : BF0000 | Q1, 01 | SVCP |
| RECEIVE 8 2 PX | Q1, 01 | SVCP |
| 7. PX SEND LOCAL BROADCAST | : TQ10000 | Q1 00 | P > P | BCST LOCAL |
| 8. PX HASH PARTITION ALL | Q1 00 | ISSUE |
| 9. TABLE ACCESS BY LOCAL INDEX ROWID | SAA_REP_PRODUCT_ACTIVITY | Q1 00 | SVCP |
| 10. CONVERSION OF BITMAP IN ROWID | Q1 00 | SVCP |
| 11. BITMAP INDEX RANGE SCAN | SAA_REP_PRODUCT_ACTIVITY_BI | Q1 00 | SVCP |
| 12. FILTER-HASH PARTITION PX JOIN | Q1, 01 | ISSUE |
| 13. TABLE ACCESS FULL | SCMSA_SUB_FEATURE_TRUEUP | Q1, 01 | SVCP |
| 14. RANGE OF PARTITION ALL THE | Q1, 01 | SVCP |
| 15. HASH PARTITION ALL | Q1, 01 | SVCP |
| 16. TABLE ACCESS BY LOCAL INDEX ROWID | SAA_REP_SUBSCRIBER_ACTIVITY | Q1, 01 | SVCP |
| 17. INDEX RANGE SCAN | SAA_REP_SUBSCRIBER_ACTIVITY_I1 | Q1, 01 | SVCP |
-----------------------------------------------------------------------------------------------------------------
But when I joined the first two tables and run as shown below, the request is get executed in 13 Minutes.
SELECT / * + PARALLEL_INDEX(R,SAA_REP_PRODUCT_ACTIVITY_BI,12)
PARALLEL(SUB,24)
*/
R.*, sub.mrc, sub. RATEPLANCODE, rr.measure_group_id
Saa_hist.saa_rep_product_activity r
JOIN scmsa_hist.scmsa_sub_feature_trueup sub
ON sub.job_log_id = r.job_log_id
AND sub.service_number = r.msisdn
AND sub.ban = r.account_number
AND sub.soc_code = r.product_id_code;
Therefore, I created a temporary table with this data and made a left outer join with the other 3 table. It runs a few seconds and I can say all the data I am able to take less than 15 minutes to 6 hours.
So my question is that why Oracle is a strange behavior.
I tried all approaches to avoid this kind of behavior methods but unable to produce the same thing as how I did in the second approach.
For example, I joined the first two tables and use NO_MERGE hint with the third table and always NO_MERGE, PUSH_PRED's not going anywhere. I tried Inline view and it doesn't give me any improvement in performance.
I'm tempted to do it using WITH Clause with two tables and then joined the data set with the third table. But still does not.
I tried hint ORDINATE and yet so big difference.
I even tried to force some clues which are presentm, but the 50Million cost ranges from 200K.
I think I'm exhausted all the possibilities.
I'd appreciate any Oracle guru can help me what is the issue.
Thank you
NKMYou could start trying to impose (with extensive predicates) what you discover or believe work better.
In this case I usually found the ansi syntax not useful and often the optimizer ignore my intentions:(mais il n'y a pas de mal essayer)select x.*, rr.measure_group_id from (select r.* sub.mrc, sub.rateplancode, from (select * from saa_hist.saa_rep_product_activity where billing_subsystem_id = 1 and batch_key between 674 and 675 ) r, scmsa_hist.scmsa_sub_feature_trueup sub where sub.job_log_id = r.job_log_id and sub.service_number = r.msisdn and sub.ban = r.account_number and sub.soc_code = r.product_id_code ) x, (select service_universal_id, account_number, msisdn, measure_group_id from saa_hist.saa_rep_subscriber_activity where quantity = 1 ) rr where x.service_universal_id = rr.service_universal_id(+) and x.msisdn = rr.msisdn(+) and x.account_number = rr.account_number(+)Concerning
Etbin
-
Poor search performance clustered with table of singles (100 k)
In a data entry project, I created a data type to store regular data. I have a cluster (see photo) which consists of a name, StringData, Numericaldata and ArrayOfSinglesData (predefined 100points k). Thus, every piece of data can be a scalar string, scalar number or an array of numbers.
I then do a picture of this for all of my variables, maybe 150 or more.
Works well, but the performance when adding new data (search for the exact name) is pretty poor. Very high CPU and many even page faults for the slow connection like 1 to 10 times per second.
The entrance to the data add method is an array of (stringname, DataString). So for each new data I loop over all the variables, find the one with the correct name string and add new data (replce the scalar chain and the number, add to arrayOfSingles).
Given that I have 150 variable, as I thought a linear search should be ok, but probably the program moves also around 100 k singles for each comparison, or it's my idea at least.
Can you suggest which is a good thing to do to improve performance?
I added a search binary smarter, but it was necessary to sort variables, and since I have two names for each variable (called internal and external) that I use when you add, it helped only for half of the research.
If I find the time I would like to divide the cluster so that all ArrayOfSingles are separated, but maybe you can tell me immediately if it is useful?
(Labview, 2012sp1)
Like Gerds link watch I suppose you're looping in the table looking for your name?
I just tested, and using DVR to extract only the ID and grabbing then a single element are fast enough. I will attach my test so you can try it for yourself.
/Y
-
Running parallel queries in 11 GR 2
I'm a little confused about parallel execution in GR 11, 2.
Lets say I have the Setup below.
parallel_servers_target = 4;
PARALLEL_MAX_SERVERS = 16;
parallel_degree_limit = CPU
parallel_threads_per_cpu = 2
parallel_adaptive_multi_user = TRUE
N ° of UC = 16 CPU, 2 cores each.
The Test table degree = DEFAULT
Example query:
Select * from Test by 1,2,3;
Lets say I want to run 5 in parallel sql statements that require 4 parallel workers each.
PARALLEL_DEGREE_POLICY = AUTO:
What of her below happen?
(a) a statement was going to be executed and the rest four would be queued because the first statement itself uses 4 parllel workers what amounts to our parameter of parallel_servers_target.
or
(b) four statements would be carried out using 4 workers each and the fifth would be queued because it exceeds the parallel_max_servers setting if it were to be executed.
or
Please explain what could happen if not a) or b).
PARALLEL_DEGREE_POLICY = MANUAL:
What of her below happen?
(a) four statements would be managed (using 4 parallel slaves each) and the fifth will be held in the series.
or
(b) all five would be using parallel workers. If so, please explain how the No. parallel to each statement slaves were to be distributed.
or
(c) it would first try to allocate 16 sons in the first statement. Later it will adjust accordingly and reduce parallel workers allocated to each statement and end up running two 4 statements with parallel workers or all the five workers parallel.
I appreciate really all of your answers on this.
UC = 60 (perhaps CPU_COUNT = 60), the number of cores = 15 - so you have four hardware threads by heart.
The DOP default value is calculated as PARALLEL_THREADS_PER_CPU * CPU_COUNT (in the single instance databases) - in your case, the DOP default is 2 * 60 = 120.
See this page 20 (http://www.oracle.com/technetwork/database/bi-datawarehousing/twp-parallel-execution-fundamentals-133639.pdf) :
Manually set the degree of parallelism
With PARALLEL_DEGREE_POLICY set to MANUAL Auto DOP feature is disabled and the end user must manage the use of parallel execution in the system.
You can either apply the default value of the so-called DOP or a specific fixed value for the declaration of principles on a session, statement or object level.
LACK of parallelism
...
Fixed degree of parallelism (DOP)
Unlike the LACK of parallelism, a specific DOP can be asked to the Oracle database. You can use one of the following ways to get a fixed DOP.
1. define a fixed DOP for objects. ALTER TABLE 8 PARALLELS customers. ALTER TABLE 16 PARALLELS sales;
2. use the suspicion level parallel (integer) statement. SELECT / * + parallel (8) * / COUNT (*) OF customers.
3. use the level indicator parallel (table_name, whole) object. SELECT / * + parallel (8 customers) * / COUNT (*) OF customers.
Note that the parameters in the table on the #1 above give you only the fixed DOP in manual mode and mode limited, namely when PARALLEL_DEGREE_POLICY is set to MANUAL or LIMITED.
All table decoration will be ignored in mode (AUTO or ADAPTIVE) AutoDOP.
Also note that for example # 1 parameters, Oracle will choose the DOP requested as follows:
-The queries accessing the CUSTOMERS table use a DOP asked 8.
-Accessing the SALES table queries ask a DOP of 16.
-Queries accessing both the SALES and the CUSTOMERS table will be processed with a DOP of 16. Oracle uses the upper DOP2.
The number of allocated PX servers can become always twice the requested DOP in the case of parallel processing requires two sets of PX server for treatment of producer/consumer.
And see on page 25:
Parameter: PARALLEL_MAX_SERVERS
Default value: PARALLEL_THREADS_PER_CPU * CPU_COUNT * concurrent_parallel_users * 5
Suggested value: default
Explanations: Sets the maximum number of servers in parallel execution that can allocate an instance of database. This is a hard limit and cannot be exceeded.
So, put PARALLEL_MAX_SERVERS > 120.
In fact, it would be better to change the PARALLEL_THREADS_PER_CPU = 1 parameter (default is 2). See this page 25:
Parameter: PARALLEL_THREADS_ PER_CPU
Default value: 2
Suggested value: 1 for platforms with hyperthreading enabled, 2 for other platforms
Explanations: Number of parallel processes that a processor can handle in parallel execution
Then the default DOP would be PARALLEL_THREADS_PER_CPU * CPU_COUNT = 1 * 60 = 60.
In this case, set PARALLEL_MAX_SERVERS > 60.
Kind regards
Zlatko
-
Hi all
I am facing a weird problem in the SQL query. Taken, I wrote the request with the spaces, tabs and line breaks after execution it slows down the database and finally, I have to restart the database again. But after removing the spaces the application went very well. I don't know what the problem causing this slow run, but after the removal of whitespace to query everything works fine. I've also confirmed plans to explain the two after the removal of whitespace and previously had the same results.
I use the TOOL of DEVLOPER PL/SQL, SQL developer, Toad and Oracle 11 g.
***************************************************************
For example. (in reference to my original query):
Select
*
Of
Double;
****************************************************************
(After removing whitespace)
Select * twice;
*****************************************************************
What would be the reason for white spaces causing slow performance?
Please let me know if you need additional information on my question.
Thanks in advance,
HP
If you make the first request without spaces and the second by spaces you will see, the second is even faster...
The reason why are cached revenge...
HTH
-
Oracle OpenScript cannot run more than 3 Scripts in a session
Dear,
After you create the function of Web test scripts and fusion in a Script to help run the Script tool, Oracle openscript run only 2 or three scripts and display of the browser the message below:
OpenScript: slowed the mouse position:
and does not perform the remaining scripts
The details of my Machine are:
OpenScript Version: 12.2.0.1 Build 288
Windows 7 32 bit
Processor I5
2 GB of RAM
Internet explore 8
Waiting for your comments
work after the replacement of the browser.close () to close a session with the web.window("path").close option.
Maybe you are looking for
-
How to unlock my iphone 6 s forgotten pascode
How can I unlock my forgotten password locking?
-
All attempts to install update KB2659262 result in 0x800736cc error code. How is it resolved?
When I had automatic updates on, MS would try repeatedly to make this update. After many attempts, I never realized that accused had failed in each attempt. When I disabled automatic updates, I finally saw that these attempts had failed. I have no
-
Pavilion dv7... How to block programs requesting access to the computer (updater.exe)
The HP firewall intervenes and asks if I want to accept or deny programs requesting access to the laptop... it's good... but a Trojan horse (updater.exe) after I deny access, comes back every 15 minutes... 5 or 6 active applications if ignored... tir
-
Cannot install the full features HP Photosmart and Officejet software
Product: HP Officejet 7210 all-in-one Printer Windows 7 64 bit The system cannot find the file specified... hpzprl40.exe The printer has a connection wired ethernet to the router. The laptop is connected wireless to the router.
-
Help in CS6 search function has stopped working for me.
When I try to get something of what follows is an example of a research on the forms of draw:When I click on more information, it shows the following Ajax error: