without regular expression
Hello experts;What happens if I have the sample data below
create table t1
(id number(30),
n_id varchar2(4000));insert into t1 values (1, '1.2.333');
insert into t1 values (111, '1.2');
insert into t1 values (1111, '4.3.2.1.2');
insert into t1 values (1222, '3.22222');
insert into t1 values (1222, 'A');
insert into t1 values (1333, 'C');
insert into t1 values (144, 'DDDDD');
insert into t1 values (15555, '4.3.3.3.3.3.3.3.');111 1.2
1222 3.22222
select *
from t1
where ltrim(rtrim(n_id,'0123456789'),'0123456789') = '.'
/
ID N_ID
---------- --------------------
111 1.2
1222 3.22222
SQL>
SY.
Tags: Database
Similar Questions
-
regular expression: an integer in the range 0.100
What is the best regular expression to satisfy the need:
(1) input string must be whole, the minimum value is 0, the maximum value is 100, no other symbols are allowed in the channel, no comma without a space.
The example data:with T as (select '-1' str from dual --not ok union select '0' str from dual --ok union select '1' str from dual --ok union select '100' str from dua --ok union select '1000' str from dual-- --not ok union select '101' str from dual --not ok union select '10.1' str from dual --not ok union select '10,1' str from dual --not ok union select 'a' str from dual --not ok) select * from T where regexp_like(str,'^[[:digit:]]{0,3}$');Hello
I think you hit the key to this solution; using regular expressions, it is better to make a special case of '100'.
You accept the numbers 1 and 2 digits that begin with '0'. would be unwise to accept 3 digit like '007' numbers, too?
Here's a regex solution that makes and also an inelegant way to achieve the same results without regular expressions:SELECT ROWNUM , str , CASE WHEN REGEXP_LIKE ( str , '^' || -- Beginning of string '(' || -- number, which is either '(100)' || -- 100 '|' || -- or '(0?' || -- optional leading 0 '\d{1,2})'|| -- 2 digits ')' || -- end number '$' -- End of string ) THEN 'Okay' END AS regexp , CASE WHEN LENGTH (str) <= 3 AND TRANSLATE ( str , 'X0123456789' , 'X' ) IS NULL AND LPAD ( str , 3 , '0' ) <= '100' THEN 'Okay' END AS non_regexp FROM t ;Output:
ROWNUM STR REGE NON_ ---------- ---- ---- ---- 1 -1 2 0 Okay Okay 3 007 Okay Okay 4 08 Okay Okay 5 1 Okay Okay 6 10.1 7 100 Okay Okay 8 1000 9 101 10 999 11 a 12I added these lines to the sample data:
union select null str from dual union select '007' str from dual union select '08' str from dual -
Complex regular expressions without multiple passes
Does anyone know of a tool that can handle more complex regular expressions without chaining of multiple copies of the VI regular expressions?
For example, if I have a XML string as
Power supply error has occurred.
Sorensen SGA166/188 and I am interested in the tag method to retry only, I could write a regular expression something like
.*
.* to parse the string inside the tag.
kc64 wrote:
For example, if I have a string like
My email address is [email protected]. Please no spamming not me.
and I am interested in the domain name of the email only address, I could write a regular expression something like
@(\w)*\. (com: net | org)
to parse the string 'gmail '.
Forgive me if I am away from base, but I'm flying blind at the moment (not LV to test what I say). You can add to the power of a regular expression using submatches or capture groups. The regular expression you wrote will grab (I think) @gmail.com for the entire game. Let's say you want to get 'gmail' without a second function call. You can do the first group of a little dishonest selection by moving the * inside the parentheses. Then, on the BD pull down on the bottom of the function of regular expression matching to expose a variable number of submatches (both should be in this case). The first should be 'gmail '. The second one should be "com."
In summary, @(\w*)\.) (com: net | org) should give you gmail in the first submatch. Of course, my Perl is a little rusty and LV cannot apply in the same way.
-
Validation of attribute text WITHOUT using regular expressions
Hello world
I'm working on a few validation rules for a text attribute and one of the conditions is that the text string can contain only alphanumeric characters.
Because of the requirements that I can't use a regular expression here (the output should be a Boolean value confirming if the text is valid or not), so I need to find a way to write this in the rules...
Yes, is there an easier way of writing this rule that the use of the ' Contains (< text >, < substring >)' function? Like this:

[Etc. for all the non alpha numeric characters]
If not, is it possible to write a rule that States that the text contains ONLY the following characters

[Etc for all alphanumberic characters]
Or is there some other function I could use it here?
Appreciate any thoughts or input about how this could be solved, thank you in advance for your help.
Unfortunately, regular expressions are the ideal solution for exactly the scenario you are exhibitor. The only alternative other than a broad 'or' statements is regular expressions, or write a custom function.
-
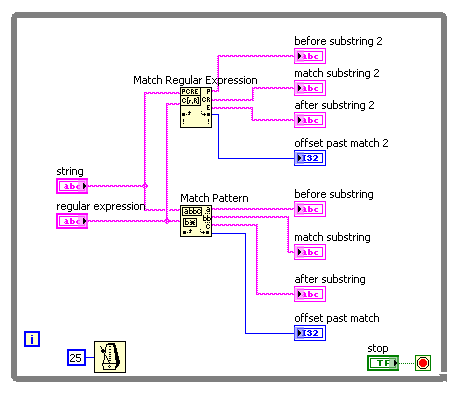
"Matches regular Expression" and "Model match" vi behaves differently
Hello
I need a simple matching chain and experimenting that found the "Regular Expression Match' and 'Correspondence model' vi behave a little differently. I guess that the entries of the regular expression on the two the same behavior. It's a difference that I discovered that the "|" character ("vertical" character, commonly used as an operator 'or') is recognized as such in the regex to Match vi, but not in the match vi model (where it is taken to the letter). Furthermore, I can't find any document using (online or in LabVIEW) on the ' | ' usage in regular expressions of character. Is - this documented anywhere?
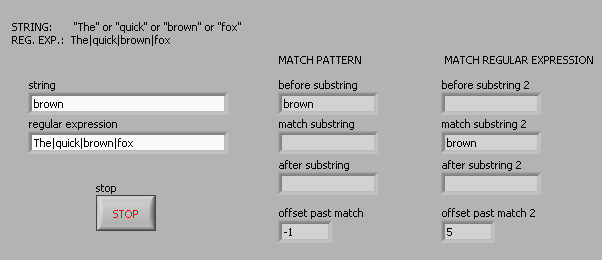
For example, suppose I want corresponding to one of the following 4 words: 'The' or 'fast' or 'brown' or 'fox '. The regular expression ' the | fast | Brown | Fox' (without the quotes) works for the vi Regular Expression Match but not the match pattern vi. Here is a photo of the block diagram and the results of the façade:
The Help explains that the vi Regular Expression Match performs a little more slowly the match vi pattern, so I started with the latter. But since he does not work for me, I'll use the old. But does anyone have an idea of the speed difference? I guess that's negligible in a simple example.
Thank you!

Thank you, Jeff. That's what I was looking for. BUT my version of LabVIEW 8.5, does NOT say "functionfor example, the Match model does not support the parenthesis or vertical bars (|) characters.«» !
See: http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_pattern/
and http://zone.ni.com/reference/en-XX/help/371361D-01/glang/match_regular_expression/
It is not mentioned in the help of special characters used for the match pattern : http://zone.ni.com/reference/en-XX/help/371361D-01/lvhowto/specialcharformatchpatt/
The only place | has 'talked', it is in the sentence: "some regular expressions that use alternating (such as (. |))". \s)*) require significant resources to deal with when it is applied to the large input strings. "But I'm not processing a large chain.
It seems that NEITHER fixed this omission. What version is your help?
Ed
-
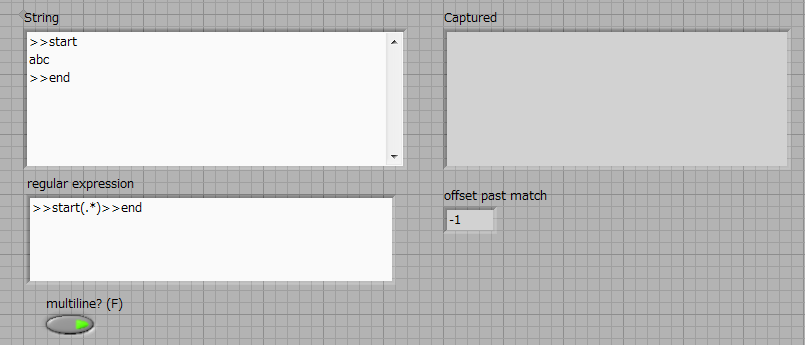
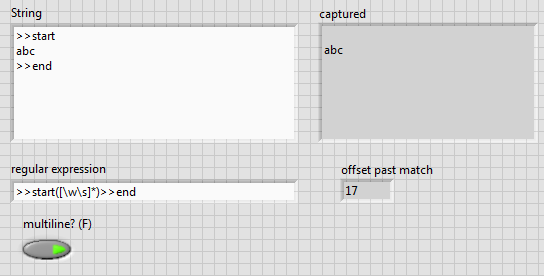
How to capture multiple line String using regular expressions?
Hello
I have a simple program like this:
What I want to accomplish is to capture everything between > start and > to end with a single regular expression matching node. It seems that the definition of multiples? true or False does not help.
I'm using LabVIEW 2012.
If it is impossible to capture using a single node, that's fine. But I want to assure you that I can make full use of this node without combining several others.
Thank you!
> start([\w\s]*) > end
A point matches any character except line break characters. You have two of them.
-
regular expression for the xml tags
Dear smart people of the labview world.
I have a question about how to match the names of xml text elements.
The image that I have some xml, for example:
Peter 13 and I want to match all of the names of elements, that is to say: no, son, grandson, age, regardless of any attribute have these items. There is a regular expression, I can loop, that can do this? (Something like "\<.+\> ". "") It is no good because it matches the entire xml string.) I'd really only two different expressions, one for the match start elements, e.g.
and one for the correspondence of the elements, for example. Thanks for your help in advance!
Paul.
The site Of regular Expressions will be very convenient.
They have some good tutorials on regexp with a demo of the XML tags:
Here is a small excerpt:
The regular expression <\i\c*\s*>matches an opening of the XML without the attributes tag corresponds to a closing tag. <\i\c*(\s+\i\c*\s*=\s*("[^"]*"|'[^']*'))*\s*>corresponds to an opening with a number any attributes. Put all together, <(\i\c*(\s+\i\c*\s*=\s*("[^"]*"|'[^']*'))*| i\c*)\s*="">corresponds to an opening with attributes or a closing tag. (source)
If you want advanced XML analysis I suggest JKI XML toolkit.
Tone
-
Regular expression - get longer channel number
I think it's easy, but I can't get it. Lets say I have a string "A1_1000", I would like to remove the 1000 using regular expressions. When I fed regular expression Match I get '1', which is not the longest number. I know other ways to do it, but I want to clean the solution in one step. Anyone know the regular expression to the right to achieve this? Thank you!
ceties wrote:
It is the best solution I've been able to come. I wonder if there are "more smooth way" without the cycle of.Since several checks are needed, I would tend to beieve we must travel opportunities. in this example

I start to check at '0' offset in the string to a number. Provided that I have find a number, I check if it is longer that any previous number, I found and if so, store the new number more in the shift register.
Have fun!
Ben
-
Regular expression breaks script
I have the following statement of regular expressions in my JSX file:
var regex = /[^/]*(?=\.[^.]+($|\?))/; // Doesn't work while this does: var regex = /[\u0400-\u04FF]+/;
.. .and it breaks execution of my script for unknown reasons. What's not here? I thought the syntax / theRegEx.
(comment to the statement of regex solves the problem and the script runs normally)I tested the regex here:
RegExr: Learn, build, & Test of RegEx.. .on this string: "c:/Users/martin.dahlin/Desktop/Test/lolFile.lol".
gives me "lolFile" without the quotes.xbytor is right, there is really no "regex-standard/compliance. Basic things work quite universally, but there are the specifics of the platform and conventions and you just test & work around them.
That said, get into your regular expression to Tester online regex and a debugger: JavaScript, Python, PHP, and PCRE gives and error "/ separator unescaped ', i.e. must be ' / [^\/] * (?)» = \. [ ^.] +($|\?)) /". Also the use of the explicit constructor is a tad safer, typos lead more reasonable errors.
-
Regular Expressions of Drivng me crazy!
Oracle Version 11 GR 2
Scripts of test data
CREATE TABLE REGEX_TEST
(ID NUMBER 4,
VARCHAR2 (50) COMMENTS
);
Insert into REGEX_TEST (ID, COMMENTS) values (1, "< Little Red Riding Hood > #title");
Insert into REGEX_TEST (ID, COMMENTS) values (2, "#title < Little Red Riding Hood > #publisher < Penguin >");
Insert into REGEX_TEST (ID, COMMENTS) values (3, ' #title < Little Red Riding Hood > #publisher < Penguin > #pages < 30 > ");
Congratulations to Frank Kulash to provide the following SQL to clean the field of comments only properly marked the text in the field
Properly tagged text is defined as
Start by #.
then nameOfHashTag
then < valueOfHashTag >
The number or name of hashtags is variable and is not known at design time
The Frank provided SQL is (with a slight mod)
Original, SELECT comments
REGEXP_REPLACE (comments
, '(^|>)[^#.*<]*'
"\1") that cleaned
of REGEX_TEST;
Source language CLEANED #title < little Red Riding Hood > #title < little Red Riding Hood > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > FIRST QUESTION: I understand the [^ #. * <] * component - search for zero or more occurrences of anything that is not a # tracking of zero or more characters, then a < and I understand the () sets a capturing group, but I don't understand how it works - 1 is probably a reference to the Group?
Now, I add a few more - lines to see how he treats badly marked text that is
void <>
text that is not marked
text is not enclosed by sharp hooks
Insert into REGEX_TEST (ID, COMMENTS) values ('4, #title <>");
Insert into REGEX_TEST (ID, COMMENTS) values (5, "#title <>#publisher < Penguin >");
Insert into REGEX_TEST (ID, COMMENTS) values (6, "#title < Little Red Riding Hood > text that isn't marked < Penguin > #publisher");
Insert into REGEX_TEST (ID, COMMENTS) values (7, "#title oops I forgot #publisher < Penguin > rafters").
Original, SELECT comments
REGEXP_REPLACE (comments
, '(^|>)[^#.*<]*'
"\1") that cleaned
of REGEX_TEST;
Source language CLEANED #title < little Red Riding Hood > #title < little Red Riding Hood > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > #title < little Red Riding Hood > #publisher < Penguin > #pages < 30 > #title <> #title <> #title <>#publisher < penguin > #title <>#publisher < penguin > #title < little Red Riding Hood > text that is not signposted #publisher < Penguin > #title < little Red Riding Hood > #publisher < Penguin > #title oops I forgot the #publisher < Penguin > rafters #title oops I forgot the #publisher < Penguin > rafters SECOND QUESTION: Is there any way I can specify that the <>cannot be empty - I played a bit with the +? but impossible to get what I want. Similarly, the latter (without text no sharp hooks)-I guess this would be impossible because you don't know if it was wong, until you have met the # next date you would be somehow to follow back and ignore the whole group.
I learned two things in this
1. regular expressions are extremely powerful
2. but they will drive you crazy?
Once again thanks a lot for the help
BTW - I managed to do what I had to do it using a lot of PL/SQL code, but not very fast!
Hello
So, you want only the substrings that are well-formed attribute/value pairs (attribute or value may be missing). You want to ignore anything in the comments that is not part of a well-formed pair.
It is not very difficult to get a single well-formed pair. The problem is that there is no good way to say 'everything that is not part of a well-formed pair '. One solution is to extract from each pair trained well on a separate line and then re - combine them into a single string by id, like this:
WITH split_data AS
(
SELECT id
comments
REGEXP_SUBSTR (comments,
, '#' || -sign #.
'[^<]+' || ="" --="" 1="" or="" more="" of="" any="" characters="" except="">
'<' || ="" --=""><>
'[^>]+' || -1 or several characters any except >
'>' -- > sign
1
LEVEL
) AS well_formed_pair
LEVEL AS pair_num
OF regex_test
([LEVEL CONNECTION <= regexp_count="" (comments,=""> <> <[^>] + > ')
AND PRIOR id = id
AND PRIOR SYS_GUID () IS NOT NULL
)
SELECT id
commented THAT the original
LISTAGG (well_formed_pair) WITHIN GROUP (ORDER BY pair_num)
THAT cleaned
OF split_data
GROUP BY id, comments
ORDER BY id
;
The 2nd argument of REGEXP_SUBSTR above is actually the same as the 2nd argument of REGEXP_COUNT. I wrote one of them in a more detailed form, hoping to make it clear what happens if has been done. You can write an expression so be it.
The result is just what you asked:
ID CLEANED ORIGINAL
--- ---------------------------------------- ---------------------------------
1 #title#title 2 #title
#publisher #title #pu
blisher 3 #title
#publisher #title #pu
#pages<30> blisher #pages<30> 4 #title<>
5 #title<>#publisher
#publisher 6 #title
#title #pu text
is not marked #publisherblisher 7 #title oops I forgot that the rafters whoops # #title forgotten angle br
Editorackets #publisher -
pattern by using regular expressions match
I'm playing (and wrong) with regular expressions
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + > ') twice;
give < PSN > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.2 ') twice;
give < 231 > - I understand that
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' < [[: alnum:]] + >, 1.3 ') twice;
give < ABc > which confused me until I realized that < 3 25 > has not been matched, because it has a space inside
so I changed it to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ', 1.3) twice;
who gave a syntax error, so I changed it again to
Select regexp_substr (1 < PSN > / # < 231 > # < 3 25 3 > / < ABc > ',' <. * + > ') twice;
that works, but gives < PSN > / # < 231 > # < 3 25 3 > / < ABc >
I guess because the. * corresponds to anyting that all but the last closure >
The question I have is how can I retrieve the text of mounting bracket included (even if it has multiple spaces)?
Hello
9c5dfde3-EAAE-45A7-80a1-bba8a71c826c wrote:
Thanks for that - is there a way to return all 4 surrounded by extracts of <> without resorting to PL/SQL?
Of course;
REGEXP_REPLACE (str
, '(^|>)[^<>
, '\1'
)
Returns a copy of str with all outside rafters removed, for example
<231><3 25=""> . It doesn't matter how many pairs of sharp hooks - there is.
-
regular expression replacement
Hi gurus,I have a requirement where I have to replace some characters in duplicate and retain the values of this column in order of alphabatic and digital control. Please find below examples of data
Thanks in advance
sample data:
SELECT 'ZZYYXXAAABBBDDDCCC' DOUBLE COL1
UNION ALL
SELECT 'DDDCCCAAA' OF THE DOUBLE
UNION ALL
SELECT 'SDBBACCCC' OF THE DOUBLE
UNION ALL
SELECT "99988866332154" DOUBLE
UNION ALL
SELECT "77663322996" DOUBLE
Expected:
ABCDXYZ
ADC
ABCD
12345689
23679
Hello
I don't think that regular expressions will help with that.
Here's a way to do it:
WITH single_characters AS
(
SELECT DISTINCT
col1
, SUBSTR (col1, LEVEL 1) AS a_char
OF sample_data
CONNECT BY LEVEL<= length="">
AND PRIOR col1 = col1
AND PRIOR SYS_GUID () IS NOT NULL
)
SELECT LISTAGG (a_char) WITHIN GROUP (ORDER BY a_char) AS expected
OF single_characters
GROUP BY col1
;
This assumes that col1 is unique. If this is not the case, use all that is unique, even something drift of ROWID or ROWNUM, in CONNECT BY and GROUP BY clauses.
The output I get is exactly what you posted:
EXPECTED
--------------------------------------------------------------------------------
23679
12345689
ACD
ABCD
ABCDXYZ
I guess that's what you really want.
Regular expressions can not re - organize a string so that the characters are in order; you need to split the string into pieces, order parts and then put back together them. Given that you have to do it just to get the characters in order, it's simple remove duplicates without problem with regular expressions.
-
Hello
Can you help me how to replace all the commad located on a string between double quotes 2?
for example, I have a text file that contains data such as as follows
A, "-16,12","178,245", "-15,506"
B, "-16,12","178,245", "-15,506"
C, 0, 0.1
I need a result like this:
A, "-16.12", "-178.245", "-15.506".
B, "-16.12", "-178.245", "-15.506".
C, 0, 0.1
I did this, but without the regular expression. It seems to me that a regular expression, it is more elegant to parse each line and replace it.
Thank you
in which case you can be sure that all the change always are enclosed in doublequotes the regex would be like this:
line.replaceAll("(\"-?\\d*),(\\d*\")","$1.$2");Good bye
DPT
-
Regular expression to remove the space in the HTML tag
Hi all
My HTML string is as below.
Select ' < CityName > RICHMOND < / Nom_ville > < StateCd > ABCD CDE < StateCd / > < CtryCd > CAN < / CtryCd > < CtrySubDivCd > BC < / CtrySubDivCd > ' double Str Output desired is
< CityName > RICHMOND < / Nom_ville > < StateCd > ABCD CDE < StateCd / > < CtryCd > CAN < / CtryCd > < CtrySubDivCd > BC < / CtrySubDivCd > I want to remove these spaces of the tag value box with only spaces otherwise leave it as what. Please help to implement the same using regular expressions.
Hello
We don't know what you want. This site seems to be formatting your message in a weird way.
As the statement
SELECT «...» "THE DOUBLE;
without formatting, to show your entry and after the exact output desired friom as, with as little in shape as possible. It might be useful if you use some character like ~ instead of spaces (just for viewing; we will find a solution that works for spaces).
To remove the text which consists of spaces and nothing else between the tags, you can say
REGEXP_REPLACE (str
, '> +<>
, '><>
)
How is this string generated? Maybe there is an easier and more effective way to keep the bad wrtings sub off the chain in the first place.
-
ADF Email of Validation using regular expressions
Hello
Wanted to add search Email Validation VO.
It works if I put
However, this requires identification of email to be entered in capital letters.<af:validateRegExp pattern="[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}" messageDetailNoMatch="The value {1} is not a valid email address:"/>
I tried with below the option does not work.
I got over information of<af:inputText value="#{bindings.xxEmail.inputValue}" label="Email" required="#{bindings.xxEmail.hints.mandatory}" columns="#{bindings.xxEmail.hints.displayWidth}" maximumLength="#{bindings.xxEmail.hints.precision}" shortDesc="#{bindings.xxEmail.hints.tooltip}" id="it5"> <f:validator binding="#{bindings.xxEmail.validator}"/> <f:validateLength minimum="6"/> <af:validateRegExp pattern="[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}" messageDetailNoMatch="The value {1} is not a valid email address:"/> </af:inputText>
ADF Email of Validation using regular expressions
The user enter email id without @.
Please suggest this model to reach.
Thank you
JIT
Published by: appsjit on January 25, 2013 19:08Hello.
My English is not very good.I use below format and it works
"^ [_A-Za-z0 - 9-] + (\.). [_A-Za-z0-9-]+)*@[A-Za-z0-9][A-Za-z0-9-]+ (-.)] ([A Za-z0-9] +) * (-.) [A-Za - z] {2,}) $»
messageDetailNoMatch = "the value {1} is not a valid email address" / >Habib
Published by: Habib Eslami on January 26, 2013 01:22


Maybe you are looking for
-
I have trouble turning on computer. I have to switch up to 4 times, until the computer starts. Usually nothing happens, so I press the switch to stop and start again and again, usually up to four times Advice please solve this problem?
-
Photosmart 6520 does not print the new black ink cartridge
My new black ink no longer works on the printer. This seems to be a problem throughout all of the printers HP no matter what model. Did someone with similar problems had success getting their black to print despite all recommendations of manufactur
-
Failures of the L50 - B PSKSQA - 01000M Satellite screen
I have a client with 3 x portable Satellite L50 - B all bought at the same time in the same place. All three have failed the screens during the last 4 months a thick unequal horizontal line extending from 75% of the width of the screen does not turn
-
I am looking for the location of the graphic buttons (images as you press the volume controls, FN keys). I'll try to replace them with my own images, but I have no idea where I can find them on my computer? I have IdeaPad Y530 Windows 7 64 bit. Thank
-
I'm still in version 5.0.0 motorcycle, I throw the maps and the market, even with active wifi and wait a lot and is not updated itself. Since I am outside the United States, I'm guessing it is something related to the carrier. Is there a way to force