VCS CLUSTER PROBLEM
Need an idea to fix a few alarms on my cluster configuration two VCS.
VCS are running X8.5.1
Had five alarms on the my resume
1. the replication is no longer available. Systems have 4ms between them.
2 lost all Admin user accounts less? Strange... Newspapers reported that no one was in the VCS
3. admin VCS Master on the master account was returned to the TANDBERG default? (Alarm has stated that this was the case).
Changed the admin password and recreated my admin on the master account.
4 approves. it 2 (slave) lost all VCS user account, but the admin password reset not and does not have that I have listed.
My partner has been able to connect to the peer 2 VCS, even if his account is not listed in the list of users?
------------------------------------------------------------------------------
After the captain restart now, I have three alarms
a. unexpected software error has been detected in ClusterDB: unknown reason on the slave?
b. There is a port conflict between the media (36000-47999) port range and the range of ports UDP ephermeral (40000-49999) on Master
c. Core dump mode has been changed, but a reboot is required before this takes effect on Master
1. any ideas what could have caused the user accounts to disappear on the page? I think that they are still in the VCS configured just cannot see them.
2 will be restarting on the master clear alarms b and c?
3. a reboot on the peer 2 (slave) would open the ClusterDB alarm?
I can't restart until later tonight that calls are up on both.
Oh finally where one or even any changes a core dump mode?
Thank you
Connect to the VCS via Telnet/SSH/series and log in as 'root '.
use the command 'selectsw' to see what partition software he's using now, then, if image1 is active, allows the command "selectsw image2" switch to the other, or vice versa, and then restart your computer.
Wayne
--
Remember the frequency responses and mark your question as answered as appropriate.
Tags: Cisco Support
Similar Questions
-
Hello
I have created a DNS SRV to configure in the FULL of the VCS Cluster domain name.
The problem is when devices try to enroll in the VCS Cluster; I put in the endpoints, in Gatekeeper registration DNS or IP address of the DNS SRV but the always end points will never reach the cluster of VCS.
I check the logs in DNS SRV and I don't see any request from devices.
I think I need to create a virtual IP address with DNS with load balancing, I mean: IP/DNS (FQDN) for the Cluster with load and balance when devices trying to connect to the cluster's IP/DNS it transmits the request to an IP or host name of a host in the cluster.
DNS cLuster
23.1.0.201 (vcs.xxx)
The peer of the cluster:
23.1.0.32 (vcscontroltc.xxx) Master
23.1.0.33 (vcscontrolvag.xxx) slave
XXX--> field
Is this right?
Thanks in advance.
Best regards.
Hello
then 23.1.0.201 is the IP address of your DNS server?
How you need to configure is:
FULL of the cluster domain name: vcscluster.domain.local
VCS counterpart A: vcscontroltc.domain.local
VCS counterpart B: vcscontrolvag.domain.local
With the above assumptions, that's what you create in DNS:
-For the FULL domain name cluster, create two A records for vcscluster.domain.local one pointing to 23.1.0.32 and the other pointing to 23.1.0.33. With that, I recommend that you enable alternate on your DNS server.
-For each peer, create a record, so vcscontroltc.domain.local points to the points 23.1.0.32 and vcscontrolvag.domain.local to 23.0.1.33.
-Create SRV H323 and SIP records for vcscluster.domain.local. With that, I recommend that you create two SRV records for each service, pointing A Exchange and showing a B counterpart, with a weight and priority. For example:
_sips._tcp.vcscluster.domain.local-> vcscontroltc.domain.local, priority 1, weight 50
_sips._tcp.vcscluster.domain.local-> vcscontrolvag.domain.local, priority 1, weight 50
If you follow the advice above, you should be able to configure all of your interior SIP and H323 endpoints with a h.323 gatekeeper address/SIP proxy address, of vcscluster.domain.local and endpoints must enroll in one of the peers, regardless of whether endpoints supports DNS SRV.
If the domain that you use is public, you also want to add the SRV records for that domain name. These SRV records must point to your VCS Expressway, to ensure that incoming calls from URI function as it should. For example:
_sips._tcp.domain.local-> vcse.domain.local, priority 1, weight 100
If you have several VCS-E you can adjust the SRV records accordingly.
Hope this helps,
Andreas
-
I'll put up a cluster between VCS - 02c in version 8.x and one of them will be the captain. I will put all endpoints in the VCS - C Master points, what would happen if the master of VCS - C problems? My end points would be automatically transferred to another VCS - C (backup)?
Hello
Setup is a cluster of VCS VCS a set up a Master and others as a slave.
Your points of termination/Codec must register to the VCS cluster (you need to update your DNS with VCS cluster name i.e. clustervcs.domain.com with the ip addresses of two VCS. You can use SRV records to do a primary and the other back). If your CODEC does not support the SRV record then you can put the IP of master VCS and the registration, the VCS Master will provide the idec with its ip address and ip address of the slave VCS.
A good link:
http://www.netcraftsmen.NET/blogs/entry/Cisco-VCs-clustering-configuration.html
I hope this helps.
Kind regards
Ahmed
-
Hello
We intend to deploy VCS Cluster consisting of two expressway Expressway. The two highway will be activated with Dual Interface. Need some clarification regarding the ip and dns address. Here is an example of setting.
for example
Highway of VCS A: 192.168.10.2 for the first interface. 192,168.20.2 assigned to the second interface and nattted to 77.100.42.23
Highway of VCS B: 192.168.10.3 assigned to the first interface. 192.168.20.3 assigned to second iinterface and natted to 77.100.42.24
name of the cluster: video.exampledomain.com
FULL domain name: video.exampledomain.com will be be mapped both the public ip address 77.100.42.23 and 77.100.42.24 with the required SRV records.
When customer movi connect to video, exampledomain.com traffic will be routed to 77.100.42.23 and 77.100.42.24 in "round robin" mode.
Well confirm the above is the correct way to deployment and what will happen if A vcsexpressway is down. always the first call will fail because the rqurest will be sent to 77.100.42.23 and the second appeal attempt will succeed.
Krishna.
Hello Krishna,
your deployment plan looks good, assuming that 192.168.10.x and 192.168.20.x are different subnets. Please be sure to set up clustering on LAN1 (the interface non-translated) which seems to be part of your plan.
Concerning the behavior of call when one of the VCS is down, assuming that your SRV records were properly implemented and that the remote caller has good DNS SRV support for its implementation H323 and SIP, the appealing party must switch to VCS work in case of failure of the initial connection to the slaughtered VCS. In any case the result will depend greatly on the conduct of the appellant and his ability to switch to other VCS during his attempt to connect through the slaughtered VCS fails.
Hope this helps,
Andreas
-
Maximum non-traversal calls from VCS Cluster
Hi all
As mentioned in the CV data sheet, I know that a VCS can accommodate up to 500 calls from nontraversal.
But VCS cluster which consists of 6 VCS can treat 2,000, steps 3 000 (6 x 500).
I wonder how many calls each VCS cluster can handle.
Is this correct?
2 VCS cluster
=> Registratrions up to 5,000?
Up to 1,000 calls in nontraversal?
Up to 200 calls course?
VCS cluster 3
=> Registratrions to 7 500?
Up to 1,500 calls to nontraversal?
Up to 200 calls course?
4 VCS cluster
=> Registratrions up to 10,000?
Up to 2,000 calls in nontraversal?
Up to 300 calls course?
5 VCS cluster
=> Registratrions up to 10,000?
Up to 2,000 calls in nontraversal?
Up to 400 calls course?
6 VCS cluster
=> Up to 10 000 registratrions
Up to 2,000 calls from nontraversal
Up to 400 calls course
Best regards
Kotaro Hashimoto
Hi Kotaro,
even if the 6 servers are taken in charge by vcs cluster however only 4 will be active. So 4 * 500 is 2000 license.
https://supportforums.Cisco.com/docs/doc-19215
check the above document.
Rgds
Alok
-
Hi all
We have a VS Cluster and would like to register 2 MCU´s and a gateway with H.323 on it.
-Inscription on the first not peer very well - no prob. record of 2. Peer - does not (source unauthenticated received fron)
VCS Trace... no this crypto token / / invalid cryptographic tokens.
Its allways happened on 2. peer.
Restart the MCU, restart Cluster, see time servers, disabling / enabling H.323 in VCS and MCU - all done, always the same failure.
VCS Cluster / MCU / ISDN are all in the same subnet, but in another location. RTD between the location is less than 10 ms.
BTW: SIP with tls runs without any risks.
Does anyone have an idea?
Thank you much for your helping hands
/Dirk
In general this should not happen.
You said you checked the time servers, but have you also checked the actual time on the
VCS and the endpoint? (for example the login as root and check with the date).
Try to use the same NTP server on all VCS and endpoints.
Is the group itself ok (see configuration / clustering)?
Something not ok with the zone configurations?
You have any local specific or server based CPLs on VCS?
No matter what firewall/nat/alg between VCS and the endpoint?
Do you have a xconfig on two VCS and compare the config of the differences?
Your sure it's the right vcs you hit?
Do you still review log files and compare what's happening the first relative to each other?
A tcpdump and check on the VCS of debugging can be interesting as well.
Please remember useful frequency responses and identify useful or correct answers.
-
Status of VCS Cluster through CLI
Hello
Is it possible to check the status of the Cluster of CLI VCS Cluster?
I have found that a single command:
XStatus external 1 Applications
* Applications (s):
1 external:
Status:
ClusterStatus:
ClusterState: "enabled."
ClusterLastSyncDate: '2013-04-02 08:39:19.
ClusterNextSyncDate: '2013-04-02 08:40:19.
ClusterLastSyncResult: "SUCCESSFUL."
* s/end
Ok
But if I disconnect one of the peers of the bunch, fruit of xstatus external 1 Applications is the same.
Is it possible to check the status of the Cluster via CLI database?
-What happens when the cluster breaks down?
-What command can I use to check the status of the Cluster, Cluster database state, the State of the communication with other peers? What are the States of possible failure?
Thanx.
Marek.
Do not find them as documented, so use at your own risk :-)
In any case, I like web access https better for information of status and then to misuse the root account.
Create an account with api read access and get:
https:///api/management/status/clusterpeer
the output may differ with different versions
(that one was a X6.1 but X6.1 seem to show that the other peers see as well)
[{"peer":"192.168.0.91","num_recs":2,"records":[{"uuid":"54c4b972-0d5f-4748-90f6-3203d5eae693","peer":"192.168.0.91","state":"up"},{"uuid":"8939f6d5-77d8-4ec0-b275-19cd95b905d5","peer":"192.168.0.90","state":"up"}]}] -
VCS 'OLD' device and device New VCS cluster "(CE500)" ""
Hello.
An easy question, can you do a VCS cluster between the 'old' and the 'new' device? is there a limitation?
In the prerequisites, I saw some VM 8 hearts, but do not understand a lot.
Thancks! An optimal day
Hello Alex.
As long as the VCS platform is the same (physical or virtual) and running the same versions of software and complete you the prerequisites. See Maintenance and creation of VCS Cluster Deployment Guide for more information.
The part on the cores is related to your virtual deployments, so if you use virtual VCS, he wants to make sure that you use the same size of deployment noticed on pg 4 of the installation Guide for the VCS VM. You don't have to worry about this with the hardware appliance.
-
Question about unique to the VCS cluster driver
I'm just configuration conductor for the first time according to the guide found here:
http://www.Cisco.com/c/dam/en/us/TD/docs/Telepresence/infrastructure/con...
Because I need to connect to a VCS cluster with two counterparts, each counterpart must be configured as a separate with its own appointment IP address location, (in which case I guess I would add two IPs Rendezvous in the nearby area of VCS Configuration) or should I point to the VCS Cluster FULL domain name and I have an IP to unique appointment for all of the VCS cluster?
I can't see anything in the guide on this subject...
Thanks in advance!
Hi Nick,
Unique location pointing to the VCS cluster FQDN. You are right the guide lacks details, will focus on opening a defect in the documentation for this.
-Jonathan
-
Hey all,.
We have two VCS highways in a cluster. A VCS is on a tour of the Internet and the other is on a circuit separate from another provider. The Internet provider for one sucks VCS for video, its only necessary as a backup circuit. I put this VCS in maintenance mode until the circuit feeding the other VCS fails? In this way, all records are forced to the VCS with the best circuit of the Internet.
If a VCS is in maintenance mode, will always be synchronized across the cluster?
Thank you
Justin Ferello
Technical Support Specialist
KBZ, a Cisco authorized dealer
http://www.KBZ.com
e/v: [email protected] / * /Justin-
I went forward a sale of our peers CV in maintenance mode earlier today to work around a problem, and it is always on at this point. Check the page clustering on the mask of the VCS, it shows that the peer is still active. Having the status of the replication of successful, even up to present any minute. It seems that everything is going well, but like you if it would be good to hear from someone official. Even if we force a counterpart basically be in a passive state until get us out maintenance ourselves to become active. Unlike a cluster of 6 peers where the last two automatically become active when one of the 4 main counterparts breaks down.
-
can someone explain the status of vcs on a cluster configuration?
My question is if the condition of the assets must be crossed between peers?, or there must be a single vcs active on the cluster?
Please your help
PS: version 7.1 of the vcs
Peer 1 master:

counterpart 2

Thank you very much
Hello Cristian,
This looks ok. On the master, it will show the peer as active whice means that the peer is accessible... and even homologous way it shows control as active who once again even an indication that she is available.
If you restart any server, and then refresh the page... Then it will show uknown or unreachanble or failed.
imprtant part lies on the State of the cluster when you scroll down... It should show success and show you the next time both resync.
Thank you
Alok
-
I have assistance who need the situation on VCS running X7.2 version.
I can't kill a call that was for days... When I try to disconnect there. When I look at details is States 'cancellation', but does not die.
Any ideas... The call comes from a neighbor, I put in place with other VCS.
I haven't restarted the system in more than 196 days. I have a few other calls via the old 20hours and they specify also (cancellation).
I also called the site hosting the other VCS and without registration it has do with the information I have on my VCS.
Ideas also if I SSH in the area what is the command line syntax to perhaps force disconnection it?
We saw the problem similar and same weird outdated records. A reboot of the VCS solved the question - of course, this is not ideal, but it only a computer!
-
Mapping of LUNS ESX - id scsi is not consistent across the cluster - problem or not?
Hello
as a parenthesis in an associated storage workshop, the instructor said that on some site of the client, there was silence damaged metadata vmfs happening and the reason for it was locking issues that concerned the fact that the SAN LUNS Hat different scsi id on different Cluster nodes.
I asked for references for this, but I got information on the verification of metadata etc.
now, the reason why I'm asking here is, I found that some in our environment vmfs data warehouses do not have compatible scsi-id numbering on the Cluster. I thought it was just mostly a cosmetic problem...
Two questions:
1 are warehouses of VMFS data really at risk with this? Any reference to a KB or some experience on site? We have never had a problem with the warehouses of data so far.
2. about the setting of this (we do it anyway), which is the recommended best practices to do? Shouldn't a data store with a different ID Scsi remapping result in the data store that is detected as a snapshot? Think we need to do some additional precautionary measures to avoid what is happening
Thank you!
regads
Roland
Take a look at this article for possible problems: VMware KB: can not see some or all VMware vCenter Server or VirtualCenter storage devices
A requirement is to have uniform or a coherent presentation of the LUNS across managed VMware ESX servers. More specifically, must match the LUN ID for each respective LUN between all of the VMware ESX servers.
-
All hell
I am trying to troubleshoot a weblogic clustering issue and am hoping that I get help here.
Basically, I have properly configured a cluster between 2 managed server nodes. After you have configured node 1, I used the pack/unpack to build node 2. The combination seems to work and I'm able to start two managed servers. However the deployments fail on node 2 and succeed on node 1
The error is due to a missing class file. WebLogic is able to locate this class on node 1, but for node 2, it returns an error "class not found". The jar file exist on both nodes at the same place
After further investigation, I noticed that there is a difference between how node 1 and node 2 are started i.e. different class paths. The node Manager allows us to launch the two servers.
How can I make sure that the Manager of the nodes on both nodes use the same startup for the respective nodes script so that class paths are the same
Thank you
ShivaI was able to understand the question. StartScriptEnabled = true on node 2, fixed the problem. Nodemanager using scripts separated on both nodes that was causing the server to be different properties
StartScriptEnabled = real forces NodeManager to use the script startManagedWeblogic on both nodes -
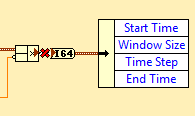
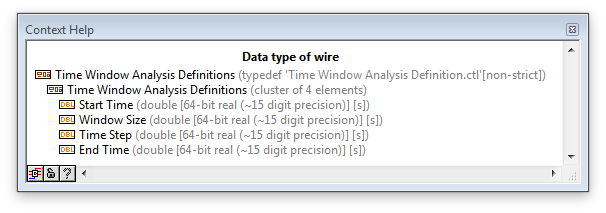
Conversion of digital cluster problem
Here's the situation:
The wire from the source to the left corresponds to this description:
It is a perfectly legitimate group of numeric values.
Therefore, detailed help service "for whole Quad", the conversion should not damage the cable.
However, it does.
What gives?
Tested in LV 2015 64 bit
Note: Unplug the Typedef doesn't help, or no arrow Ctrl + Run.
Answer: Unity, stupid!
Maybe you are looking for
-
Satellite A60: error messages on blue screen appears all the time
Hello I had a Toshiba A60 satellite for awhile. It has been great so far, but I'm constantly getting blue screens of death, with millions of stop error different etc, I have read everywhere and updated to the latest BIOS, but still no luck. I don't k
-
So I have a Lenovo g500 (win 8.1 pre-installed, 64-bit) and I just installed the latest update of windows, and now does not work my camera. The updates were the 14 and 15 and I installed this morning, and I KNOW my web cam worked the 14th. I checked,
-
iPhone 5 s still says connect to itunes after restoration. And he repeats after a month
iPhone 5 s still says connect to itunes after restoration. And he repeats after a month
-
My gateway computer is 6 years old. It came with a CD - DVD drive, HL-DT-ST DVDRAM gma - 4020B. It has worked perfectly until today. In Device Manager it has a yelllow exclamation point. I tried to update the driver and I get the message Windows
-
Cannot paste in an email from Windows Mail
Cannot paste into Windows Mail (version 6.0.6000) processor Microsoft Works. No problems for the first 2 weeks of owning the computer. Once I try to paste it into the e-mail, it says windows mail has stopped working and closed to email